Cuenta pública personal de WeChat

código fuente de keras-yolov3
git clone https://github.com/qqwweee/keras-yolo3.git
Tabla de contenido
- Preparación de imágenes de prueba
- Conversión de formato de archivos de etiquetas de datos (conversión de formato XML a txt)
- Detección de modelos de imágenes de prueba y generación de archivos de coordenadas de resultados de prueba
- Prueba MAP
- resultado
Descripción:
- En este experimento, la prueba del mapa utiliza datos de imágenes faciales;
- En este experimento, la prueba de entrenamiento / MAP del modelo solo usó parte de los datos experimentales, por lo que el valor de MAP final no es alto y es solo de referencia;
1. Preparación de la imagen de prueba
1: Primero, descargue el código relevante de GitHub y guárdelo en la carpeta del proyecto keras_yolo;
git clone https://github.com/Cartucho/mAP
2: Ingrese al subdirectorio mAP, y coloque la imagen a probar y el archivo XML correspondiente a la
imagen en la carpeta correspondiente; el directorio donde se ubica la imagen de prueba es: mAP / input / images-optional
El directorio donde se encuentra el XML correspondiente a la imagen se coloca es: mAP / input / ground-truth
En segundo lugar, la conversión del formato de etiqueta de la imagen de prueba (.txt)
En esta prueba, el formato de datos es el formato VOC. Léame en el archivo de consulta encontró que hay códigos listos para usar disponibles sin modificación;
abra la terminal, ingrese el subdirectorio y ejecute el código:
cd mAP/scripts/extra
python convert_gt_xml.py
Después de ejecutar el código, las coordenadas GT de los datos de prueba se guardarán en el archivo txt correspondiente y el archivo XML se almacenará en la carpeta de respaldo en el directorio;
3. El modelo prueba las imágenes de prueba y genera la información de coordenadas del resultado y la guarda en un archivo txt.
1. El código de prueba es el siguiente, que debe colocarse en la carpeta keras_yolo / project, al mismo nivel que yolo_video.py;
2. Ejecute el código, los resultados de la prueba correspondiente se generarán y guardarán en el directorio especificado;
python yolo_detect.py
# -*- coding: utf-8 -*-
"""
Class definition of YOLO_v3 style detection model on image and video
"""
import colorsys
import os
import sys
from timeit import default_timer as timer
import numpy as np
from keras import backend as K
from keras.models import load_model
from keras.layers import Input
from PIL import Image, ImageFont, ImageDraw
from yolo3.model import yolo_eval, yolo_body, tiny_yolo_body
from yolo3.utils import letterbox_image
import os
from keras.utils import multi_gpu_model
class YOLO(object):
_defaults = {
"model_path": '/your/path/to/keras-yolo3/model_data/face_h5/face.h5', ##训练好的模型的路径
"anchors_path": 'model_data/tiny_yolo_anchors.txt',
"classes_path": 'model_data/face.txt',
"score" : 0.3,
"iou" : 0.45,
"model_image_size" : (416, 416),
"gpu_num" : 0
}
@classmethod
def get_defaults(cls, n):
if n in cls._defaults:
return cls._defaults[n]
else:
return "Unrecognized attribute name '" + n + "'"
def __init__(self, **kwargs):
self.__dict__.update(self._defaults) # set up default values
self.__dict__.update(kwargs) # and update with user overrides
self.class_names = self._get_class()
self.anchors = self._get_anchors()
self.sess = K.get_session()
self.boxes, self.scores, self.classes = self.generate()
def _get_class(self):
classes_path = os.path.expanduser(self.classes_path)
with open(classes_path) as f:
class_names = f.readlines()
class_names = [c.strip() for c in class_names]
return class_names
def _get_anchors(self):
anchors_path = os.path.expanduser(self.anchors_path)
with open(anchors_path) as f:
anchors = f.readline()
anchors = [float(x) for x in anchors.split(',')]
return np.array(anchors).reshape(-1, 2)
def generate(self):
model_path = os.path.expanduser(self.model_path)
assert model_path.endswith('.h5'), 'Keras model or weights must be a .h5 file.'
# Load model, or construct model and load weights.
num_anchors = len(self.anchors)
num_classes = len(self.class_names)
is_tiny_version = num_anchors==6 # default setting
try:
self.yolo_model = load_model(model_path, compile=False)
except:
self.yolo_model = tiny_yolo_body(Input(shape=(None,None,3)), num_anchors//2, num_classes) \
if is_tiny_version else yolo_body(Input(shape=(None,None,3)), num_anchors//3, num_classes)
self.yolo_model.load_weights(self.model_path) # make sure model, anchors and classes match
else:
assert self.yolo_model.layers[-1].output_shape[-1] == \
num_anchors/len(self.yolo_model.output) * (num_classes + 5), \
'Mismatch between model and given anchor and class sizes'
print('{} model, anchors, and classes loaded.'.format(model_path))
# Generate colors for drawing bounding boxes.
hsv_tuples = [(x / len(self.class_names), 1., 1.)
for x in range(len(self.class_names))]
self.colors = list(map(lambda x: colorsys.hsv_to_rgb(*x), hsv_tuples))
self.colors = list(
map(lambda x: (int(x[0] * 255), int(x[1] * 255), int(x[2] * 255)),
self.colors))
np.random.seed(10101) # Fixed seed for consistent colors across runs.
np.random.shuffle(self.colors) # Shuffle colors to decorrelate adjacent classes.
np.random.seed(None) # Reset seed to default.
# Generate output tensor targets for filtered bounding boxes.
self.input_image_shape = K.placeholder(shape=(2, ))
if self.gpu_num>=2:
self.yolo_model = multi_gpu_model(self.yolo_model, gpus=self.gpu_num)
boxes, scores, classes = yolo_eval(self.yolo_model.output, self.anchors,
len(self.class_names), self.input_image_shape,
score_threshold=self.score, iou_threshold=self.iou)
return boxes, scores, classes
def detect_image(self, image):
start = timer()
if self.model_image_size != (None, None):
assert self.model_image_size[0]%32 == 0, 'Multiples of 32 required'
assert self.model_image_size[1]%32 == 0, 'Multiples of 32 required'
boxed_image = letterbox_image(image, tuple(reversed(self.model_image_size)))
else:
new_image_size = (image.width - (image.width % 32),
image.height - (image.height % 32))
boxed_image = letterbox_image(image, new_image_size)
image_data = np.array(boxed_image, dtype='float32')
print(image_data.shape)
image_data /= 255.
image_data = np.expand_dims(image_data, 0) # Add batch dimension.
out_boxes, out_scores, out_classes = self.sess.run(
[self.boxes, self.scores, self.classes],
feed_dict={
self.yolo_model.input: image_data,
self.input_image_shape: [image.size[1], image.size[0]],
K.learning_phase(): 0
})
print('Found {} boxes for {}'.format(len(out_boxes), 'img'))
font = ImageFont.truetype(font='font/FiraMono-Medium.otf',
size=np.floor(3e-2 * image.size[1] + 0.5).astype('int32'))
thickness = (image.size[0] + image.size[1]) // 300
for i, c in reversed(list(enumerate(out_classes))):
predicted_class = self.class_names[c]
box = out_boxes[i]
score = out_scores[i]
label = '{} {:.2f}'.format(predicted_class, score)
draw = ImageDraw.Draw(image)
label_size = draw.textsize(label, font)
top, left, bottom, right = box
top = max(0, np.floor(top + 0.5).astype('int32'))
left = max(0, np.floor(left + 0.5).astype('int32'))
bottom = min(image.size[1], np.floor(bottom + 0.5).astype('int32'))
right = min(image.size[0], np.floor(right + 0.5).astype('int32'))
print(label, (left, top), (right, bottom))
#new_f=open("/home/shan/xws/pro/keras-yolo3/detection-results/"+tmp_file.replace(".jpg", ".txt"), "a")
new_f.write("%s %s %s %s %s\n" % (label, left, top, right, bottom))
if top - label_size[1] >= 0:
text_origin = np.array([left, top - label_size[1]])
else:
text_origin = np.array([left, top + 1])
# My kingdom for a good redistributable image drawing library.
for i in range(thickness):
draw.rectangle(
[left + i, top + i, right - i, bottom - i],
outline=self.colors[c])
draw.rectangle(
[tuple(text_origin), tuple(text_origin + label_size)],
fill=self.colors[c])
draw.text(text_origin, label, fill=(0, 0, 0), font=font)
del draw
end = timer()
print(end - start)
return image
def close_session(self):
self.sess.close()
if __name__ == '__main__':
# yolo=YOLO()
# path = '1.jpg'
# try:
# image = Image.open(path)
# except:
# print('Open Error! Try again!')
# else:
# r_image = yolo.detect_image(image)
# r_image.show()
# yolo.close_session()
#strat1=timer()
dirname="/your/path/to/map/input/image-optional/" ##该目录为测试照片的存储路径,每次测试照片的数量可以自己设定
path=os.path.join(dirname)
pic_list=os.listdir(path)
count=0
yolo=YOLO()
for filename in pic_list:
tmp_file=pic_list[count]
new_f=open("/your/path/to/map/input/detection-results/"+tmp_file.replace(".jpg", ".txt"), "a") #预测坐标生成txt文件保存的路径
abs_path=path+pic_list[count]
image = Image.open(abs_path)
r_image = yolo.detect_image(image)
count=count+1
#end1=timer()
print(count)
yolo.close_session()
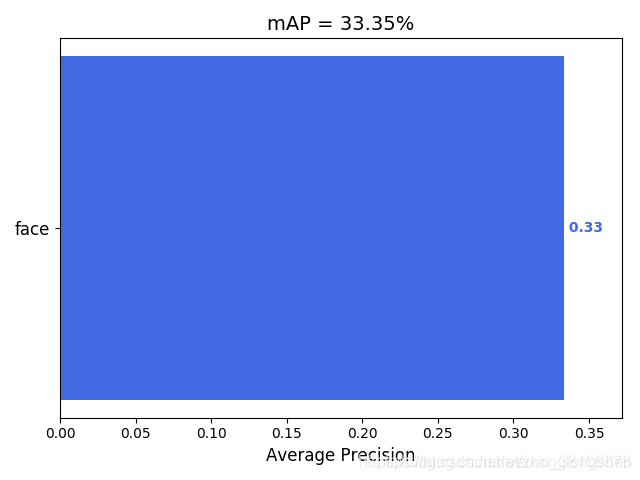
Cuatro, prueba de resultado de MAP
python main.py
5. Resultados de MAP (un tipo / parte de una pequeña cantidad de resultados de pruebas de datos)