La razón principal de la distinción entre el modo de usuario y el modo de kernel es que, para el funcionamiento normal y seguro del sistema informático, algunos recursos de hardware (como dispositivos de interrupción) e instrucciones privilegiadas no se pueden abrir a procesos de usuario, por lo que los dos modos son distinguido.
Modo kernel y modo de usuario
El espacio del kernel almacena el código y los datos del kernel del sistema operativo, que son compartidos por todos los programas . La modificación de los datos en el espacio del kernel en un programa no solo afectará la estabilidad del sistema operativo, sino que también afectará a otros programas. comportamiento muy peligroso. Por lo tanto, el sistema operativo prohíbe que los programas de usuario accedan directamente al espacio del kernel.
Para acceder al espacio del kernel, debe utilizar las funciones API proporcionadas por el sistema operativo para ejecutar el código proporcionado por el kernel y permitir que el kernel acceda a él por sí mismo, a fin de garantizar que los datos en el espacio del kernel no sean arbitrariamente modificado para garantizar la estabilidad del propio sistema operativo y otros programas Sex.
Modo Kernel : El programa de usuario que llama a las funciones de la API del sistema se denomina Llamada al sistema; cuando se produce una llamada al sistema, el programa de usuario se suspenderá y el código del kernel se ejecutará (el kernel también es un programa) para acceder al espacio del kernel, que se llama kernel Modo Kernel.
Las tareas pueden ejecutar instrucciones privilegiadas, tener acceso completo a cualquier dispositivo de E / S y también pueden acceder a cualquier dirección virtual y controlar el hardware de la memoria virtual.
Modo de usuario : el espacio de usuario guarda el código y los datos del programa de aplicación, que es privado para el programa y, por lo general, no pueden acceder otros programas. Cuando se ejecuta el propio código de la aplicación, se denomina Modo de usuario.
El hardware evita la ejecución de instrucciones privilegiadas y verifica las operaciones de acceso de la memoria y el espacio de E / S, y puede ingresar al modo de acceso del kernel a través de un cierto mecanismo de puerta en el sistema operativo.
Cambiar entre modo kernel y modo usuario
Cuando una aplicación que se ejecuta en modo de usuario requiere operaciones de nivel inferior, como entrada y salida, aplicación de memoria, etc., debe llamar a la función API proporcionada por el sistema operativo para ingresar al modo kernel; una vez completada la operación, continúe ejecutándose el código de la aplicación y luego volver al modo de usuario.
El modo de usuario es para ejecutar código de nivel de aplicación y acceder al espacio de usuario; el modo de kernel es para ejecutar código de kernel y acceder al espacio de kernel (por supuesto, también tiene permiso para acceder al espacio de usuario).
La siguiente tabla muestra el proceso de cambio entre los dos modos:
| Modo de usuario a modo kernel | Modo kernel a modo usuario |
|---|---|
| Activado por interrupción / excepción / llamada al sistema que interrumpe la ejecución del proceso del usuario. 1. El modo del procesador se cambia al modo kernel. 2. Guarde el valor de PC / PSW del proceso actual en la pila principal. 3. Gire al manejador de llamadas de interrupción / anormal / sistema. |
El sistema operativo ejecuta la instrucción de retorno de interrupción para devolver el derecho de control al proceso del usuario para que lo active. 1. Extraiga el valor de PC / PSW de la pila principal del proceso que se ejecutará. 2. El modo de procesador se cambia al modo de usuario. |
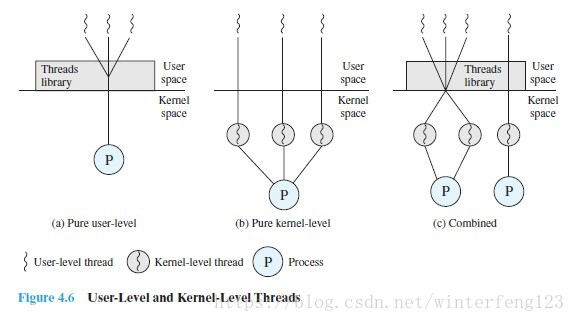
Subprocesos a nivel de kernel (KLT) y subprocesos a nivel de usuario (ULT)
El proceso es la unidad básica de propiedad de los recursos. La conmutación de procesos necesita guardar el estado del proceso, lo que provocará el consumo de recursos. Los subprocesos en el mismo proceso comparten parte de los recursos adquiridos por el proceso. En el mismo proceso, la conmutación de subprocesos no provoca la conmutación de procesos, y la conmutación de subprocesos requiere menos recursos que la conmutación de procesos, lo que puede mejorar la eficiencia.
Subprocesos a nivel de kernel (subprocesos a nivel de kernel), KLT también tiene subprocesos denominados soporte de kernel.
- Todo el trabajo (creación y cancelación) de la gestión de subprocesos lo realiza el kernel del sistema operativo
- El kernel del sistema operativo proporciona una API de interfaz de programación de aplicaciones para que los desarrolladores utilicen KLT
Hilos de nivel de usuario ULT
- El espacio de usuario ejecuta la biblioteca de subprocesos y cualquier aplicación se puede diseñar como un programa de subprocesos múltiples utilizando la biblioteca de subprocesos. La biblioteca de subprocesos es un paquete de rutina para la gestión de subprocesos a nivel de usuario. Proporciona un entorno de apoyo para el desarrollo y funcionamiento de aplicaciones de subprocesos múltiples. Incluye: código para crear y destruir subprocesos, código para transferir datos y mensajes entre subprocesos, y programación El código ejecutado por el hilo y el código para guardar y restaurar el contexto del hilo.
- Por lo tanto, la biblioteca de hilos completa la creación de hilos, el paso de mensajes, la programación y el almacenamiento / restauración del contexto. El kernel no percibe la existencia de subprocesos múltiples. El kernel continúa utilizando el proceso como unidad de programación y asigna un estado de ejecución (listo, en ejecución, bloqueado, etc.) al proceso.
| Características del hilo a nivel de kernel | Características de los hilos a nivel de usuario |
|---|---|
| 1. Un subproceso en el proceso está bloqueado y el kernel puede programar otros subprocesos del mismo proceso (estado listo) para que ocupen la ejecución del procesador. 2. En un entorno multiprocesador, el kernel puede programar varios subprocesos del mismo proceso al mismo tiempo y asignar estos subprocesos a diferentes núcleos de procesador para mejorar la eficiencia de ejecución del proceso. 3. El subproceso de la aplicación se ejecuta en modo de usuario y la programación y gestión de subprocesos se implementan en el kernel. Durante la programación de subprocesos, la potencia de control se cambia de un subproceso a otro subproceso, lo que requiere un cambio de modo, y la sobrecarga del sistema es relativamente alta. |
1. La conmutación de subprocesos no requiere el modo kernel, que puede ahorrar la sobrecarga de conmutación de modo y los recursos del kernel. 2. Permita que el proceso seleccione diferentes algoritmos de programación para programar subprocesos de acuerdo con necesidades específicas. El algoritmo de programación debe implementarse por sí mismo. 3. Dado que no necesita compatibilidad con el kernel, puede ejecutarse en todo el sistema operativo. 4. No se pueden utilizar procesadores de varios núcleos. El sistema operativo programa procesos y cada proceso tiene solo un ULT que se puede ejecutar. 5. Un bloqueo de ULT hará que todo el proceso se bloquee. |
La tecnología de revestimiento puede resolver el subproceso ULT a nivel de usuario. El bloqueo de un subproceso hace que todo el proceso se bloquee.
El objetivo del encamisado es convertir una llamada al sistema de bloqueo en una llamada al sistema sin bloqueo. Por ejemplo, cuando un subproceso en el proceso llama a IO para interrumpir el dinero, primero llame a una rutina de chaqueta de E / S a nivel de aplicación en lugar de llamar directamente a una E / S del sistema. Deje que esta rutina de chaqueta verifique y determine si el dispositivo de E / S está ocupado. Si está ocupado, el encamisado transfiere el control al programador de subprocesos del proceso, determina que el subproceso entra en el estado de bloqueo y transfiere el control a otro subproceso (si no hay un estado listo, el subproceso puede realizar la conmutación del proceso).
Estrategia de combinación para implementación de subprocesos
Se puede ver que los subprocesos a nivel de usuario y los subprocesos a nivel de kernel tienen sus propias ventajas y desventajas, que se manifiestan principalmente en las aplicaciones:
- El subproceso múltiple a nivel de usuario tiene un efecto muy bueno en el manejo del paralelismo lógico. No es bueno para resolver problemas de simultaneidad física.
- El subproceso múltiple a nivel de kernel es adecuado para resolver problemas de paralelismo físico.
Estrategia de combinación: el
subproceso múltiple a nivel de kernel es compatible con el kernel del sistema operativo, el subproceso múltiple a nivel de usuario es compatible con la biblioteca del sistema operativo, la creación de subprocesos se crea completamente en el espacio del usuario, la programación preparada también se realiza dentro de la aplicación y luego el usuario -nivel de subprocesos múltiples Mapeado a (o enlazado a) algunos subprocesos múltiples a nivel de kernel.
Los programadores pueden ajustar el número de subprocesos a nivel de kernel para diferentes características de la aplicación para lograr la mejor solución para el paralelismo físico y lógico.
Articulo de referencia
- https://blog.csdn.net/winterfeng123/article/details/79788714
- https://blog.csdn.net/sinat_38104725/article/details/98474760
- https://blog.csdn.net/winterfeng123/article/details/79784430
- https://docs.microsoft.com/zh-cn/windows-hardware/drivers/gettingstarted/user-mode-and-kernel-mode
- https://www.kanzhun.com/msh/post/1691.html
¡Preste atención a la cuenta pública y concéntrese en los productos secos técnicos en tiempo real y fuera de línea en el campo de los macrodatos de Java para compartir con regularidad! Sitio web personal www.lllpan.top
