Debido a que las computadoras no pueden entender palabras, necesitamos usar vectores de palabras para representar una palabra.
La palabra vector tiene un proceso de desarrollo.
1
bolsa de palabras one-hot 2
-
tf-idf
-
ponderación binaria
-
Ventajas de b-gram y n-gram : Se considera el orden de las palabras.
Desventajas: El vocabulario está inflado y no se puede medir la similitud entre los vectores.
3 Representación distribuida -
saltear gramo
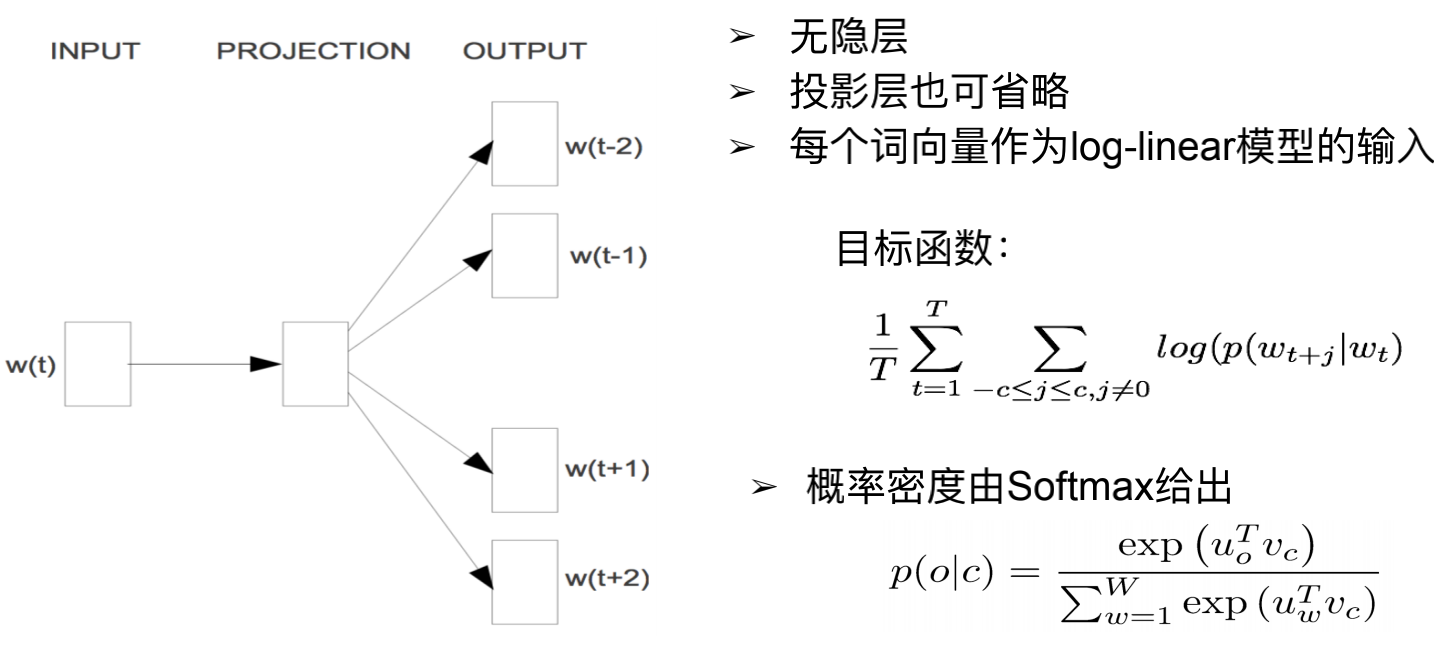
Ingrese la palabra t-ésima y use una capa de red neuronal para predecir las palabras circundantes, es decir, t-2, t-1, t + 1, t + 2 ...
Esta tarea en sí no tiene sentido, el significado de hacer esto es obtener la palabra vector. El vector de palabra obtenido se puede utilizar para encontrar las palabras vecinas de una palabra, realizar tareas de analogía de palabras y utilizarse para el reconocimiento de entidades con nombre.
El principio es: una palabra se puede representar con palabras cercanas.
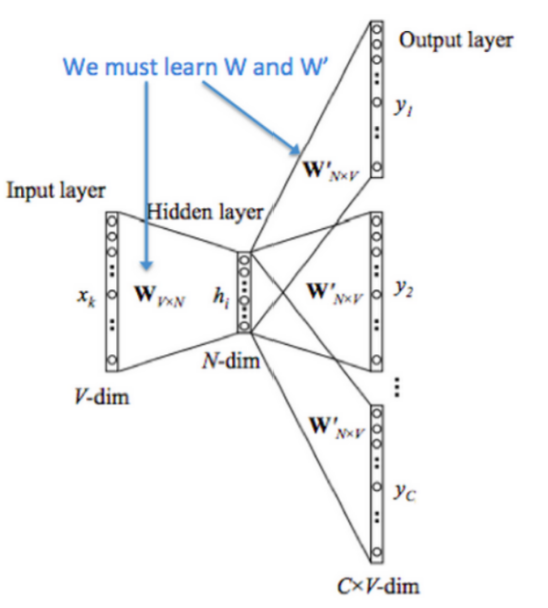
La red de entrenamiento general se muestra arriba. El tamaño del vocabulario es N.
La entrada X es una representación one-hot. Su forma es NxN.
La primera capa es una transformación lineal h = XxW (W es una matriz de Nx100), y se obtiene una matriz de capa oculta de Nx100 dimensiones.
Finalmente, agregue una transformación lineal en la capa oculta: hxW 'La salida es la probabilidad de que aquí (una posición alrededor de X) deba ser una determinada palabra. Es una matriz Nx100.
Lo que es útil en sentido descendente es W, que se utiliza como vector de palabra. Generalmente, W se denomina vector de entrada y W se denomina vector de salida.
(Aquí vemos que las dimensiones del modelo no son correctas, por lo que no se puede realizar la multiplicación de pruebas y puede haber una operación de transposición).
Función objetiva: encontrar el wt w_t dadowtEn el caso de wt + j w_ {t + j}wt + jProbabilidad de aparición: p (wt + j ∣ wt) p (w_ {t + j} | w_t)p ( wt + j∣ wt) y luego registre esta probabilidad. Tome el valor máximo de la suma logarítmica de las probabilidades en todas las ventanas. t es de 1 a T, y luego sume todos y obtenga la suma.
El método de cálculo de probabilidad específico esuo u_otulaEs el vector de palabra de salida, vc v_cvcEs el vector de palabra de entrada.
p (o ∣ c) = exp (uo T vc) ∑ w = 1 W exp (uw T vc) p (o | c) = \ dfrac {exp (u_o ^ Tv_c)} {\ sum_ {w = 1} ^ W exp (u_w ^ Tv_c)}p ( o ∣ c )=∑w = 1We x p ( uwTvc)e x p ( uOTvc)
Función de pérdida:
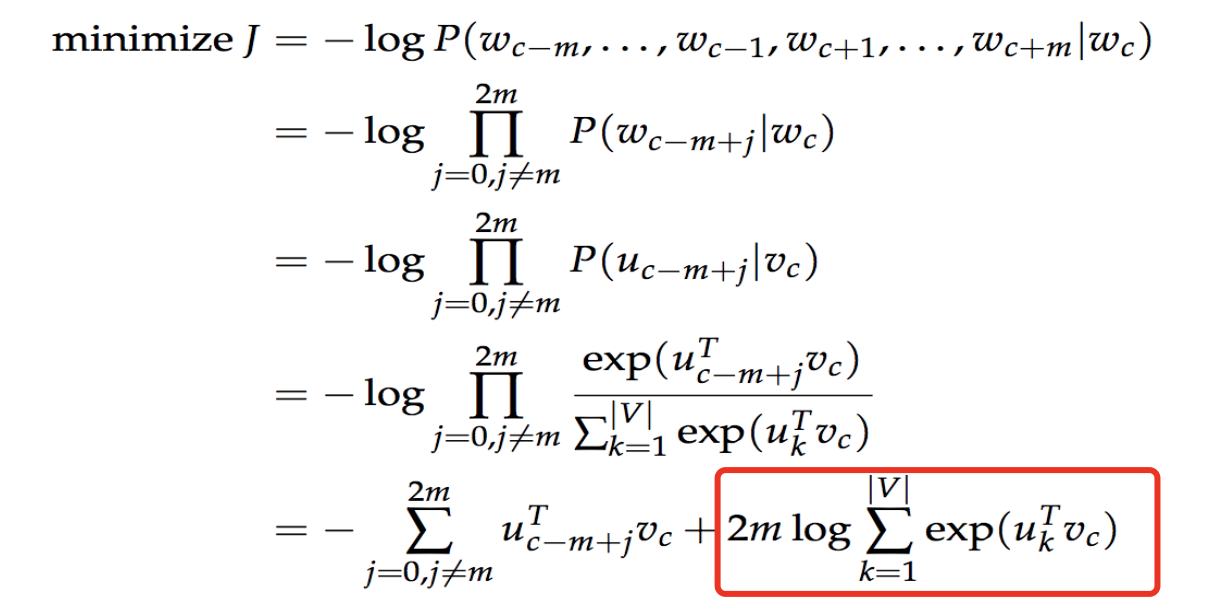
El mayor problema aquí es que el denominador de p (o | c) es muy grande. Para calcular vc v_cvcSuma con el vector de palabras de cada palabra del diccionario de sinónimos. Si el diccionario de sinónimos tiene 500.000 palabras, se calculará 500.000 veces. La cantidad de cálculo es enorme. Mire el último elemento de la función de pérdida, lo mismo es cierto.
Una de las medidas adoptadas es el muestreo negativo.
Nuestra incrustación de entrada de entrada es una matriz de 500.000 x 100 dimensiones. (Suponga que usamos un vector de 100 dimensiones para representar una palabra). La incrustación de salida es una matriz de 500.000 x 100 dimensiones.
Cambiamos la tarea desde otro ángulo. Por wt w_twtNo calcule la probabilidad de que aparezcan palabras circundantes en todo el vocabulario. Dividimos las palabras del diccionario de sinónimos en dos categorías: palabras circundantes y palabras no circundantes. Esto convierte un problema de clasificación de 500.000 en un problema de clasificación 2. Si la palabra reino unido u_ktukEs wt w_twtLas palabras circundantes de, entonces la probabilidad es mayor. De lo contrario, la probabilidad es menor.
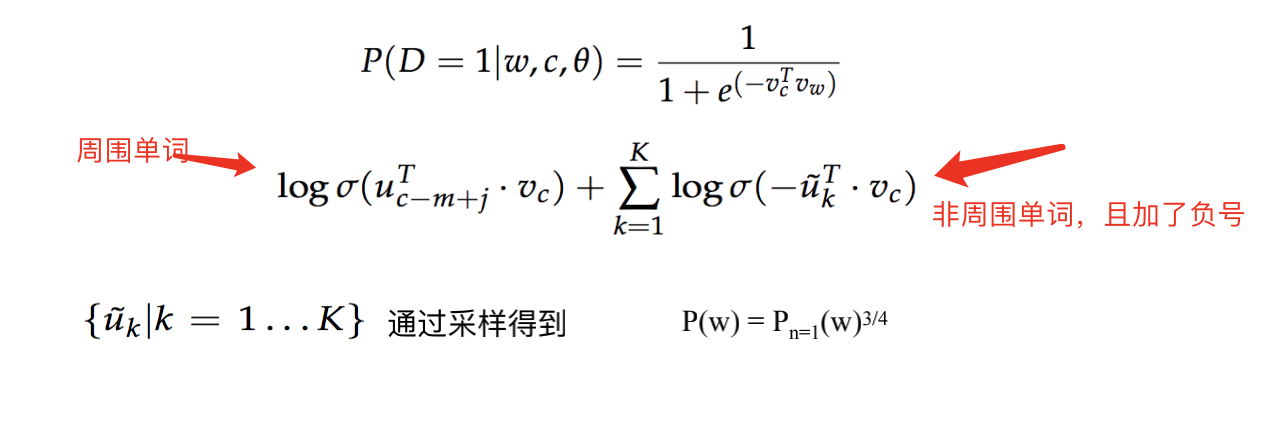
Esperamos que cuanto mayor sea la función objetivo, mejor.
Para obtener una ganancia negativa, podemos probar una parte de las palabras del léxico. Después del muestreo, la probabilidad se transforma para participar en el cálculo.
El último dato útil para nosotros es la inserción de entrada, que es un vector denso de palabras. Puede expresar muy bien la relevancia entre palabras.
Finalmente, se implementa el código del modelo.