Práctica de regresión del algoritmo de regresión de la cresta de Python
concepto basico
Regularización
La regularización se refiere a hacer restricciones explícitas en el modelo para evitar el sobreajuste. La regresión de la cresta utilizada en este artículo es la regularización L2. (Desde un punto de vista matemático, la regresión de crestas penaliza la norma L2 del coeficiente o la longitud euclidiana de w)
Los principios específicos de regularización no se describen aquí. Quienes estén interesados pueden leer este artículo: Comprensión intuitiva de los términos de regularización L1 y L2 en el aprendizaje automático .
Introducción al algoritmo
Regresión de crestas
La regresión de crestas también es un modelo lineal utilizado para la regresión, por lo que su fórmula de modelo es la misma que la del método de mínimos cuadrados, como se muestra en la siguiente fórmula:
y = w [0] * x [0] + w [1] * x [1] + w [2] x [2] +… + w [p] x [p] + b
Pero en la regresión de crestas, la elección del coeficiente w no solo debe obtener un buen resultado de predicción en los datos de entrenamiento, sino que también debe ajustarse a restricciones adicionales. En otras palabras, todos los elementos de w deberían estar cerca de cero. Intuitivamente, esto significa que el impacto de cada característica en la salida debe ser lo más pequeño posible (es decir, la pendiente es pequeña), sin dejar de ofrecer buenos resultados de predicción. Esta restricción también es la regularización .
Fuentes de datos
Precios de la vivienda en Boston: https://www.kaggle.com/altavish/boston-housing-dataset
también es un dato muy clásico
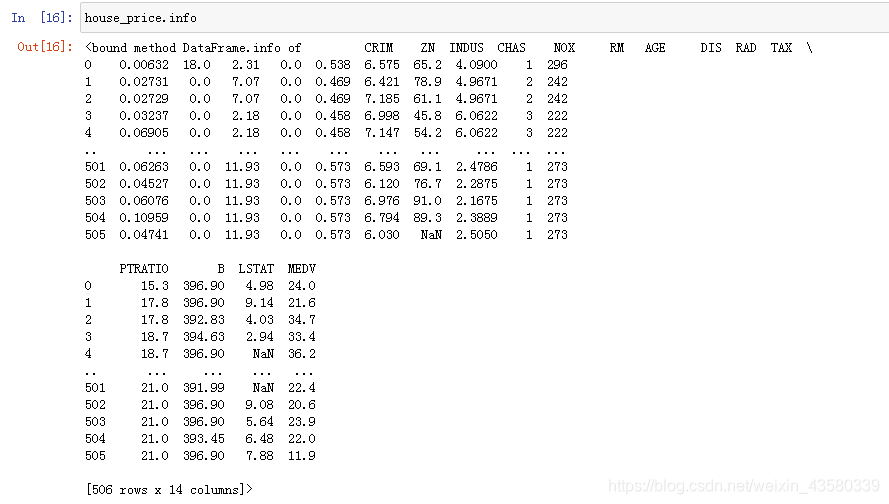
Explique brevemente los principales indicadores de estos datos:
ZN: La proporción de terreno por encima de los 25,000 pies cuadrados que se divide en zonas como terreno residencial.
RM: El número medio de habitaciones por residencia.
EDAD: Proporción de casas propias construidas antes de 1940
CHAS: Si pasa un río (si es igual a 1, significa sí, igual a 0 significa no)
CRIM: tasa de criminalidad
MEDV: precio de la vivienda
otros indicadores no hace falta decir que son todos algunos otros indicadores de vivienda, los amigos interesados pueden comprobarlo por sí mismos.
Procesamiento de datos
1. Importar bibliotecas de terceros
import pandas as pd
import numpy as np
import winreg
from sklearn.model_selection import train_test_split
from sklearn.linear_model import Ridge###导入岭回归算法
from sklearn.metrics import r2_score
Las reglas antiguas aparecen primero para importar cada módulo necesario para el modelado a su vez
2. Leer el archivo
import winreg
real_address = winreg.OpenKey(winreg.HKEY_CURRENT_USER,r'Software\Microsoft\Windows\CurrentVersion\Explorer\Shell Folders',)
file_address=winreg.QueryValueEx(real_address, "Desktop")[0]
file_address+='\\'
file_origin=file_address+"\\源数据-分析\\HousingData.csv"#设立源数据文件的桌面绝对路径
house_price=pd.read_csv(file_origin)#https://www.kaggle.com/altavish/boston-housing-dataset
Porque cada vez que descarga datos, debe transferir el archivo al directorio raíz de Python o leerlo en la carpeta de descarga, lo cual es muy problemático. Así que configuré una ruta de escritorio absoluta a través de la biblioteca winreg, de modo que solo necesito descargar los datos al escritorio o pegarlos en una carpeta específica en el escritorio para leerlos, y no se confundirán con otros datos.
De hecho, hasta este paso, estamos pasando por el proceso, básicamente cada minería de datos tiene que hacerse nuevamente, no hay nada que decir.
3. Limpiar los datos
1. Encontrar los valores faltantes
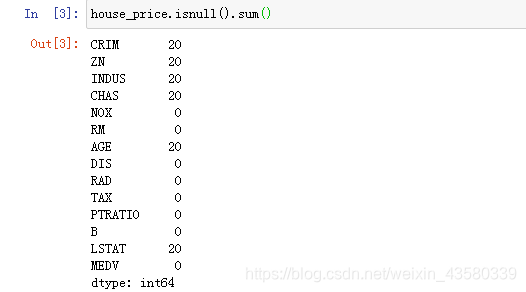
Puede ver que estos datos no incluyen muchos valores faltantes, así que elimínelos.
house_price1=house_price.dropna().reset_index()
del house_price1["index"]
2. Encuentra el valor de la mutación
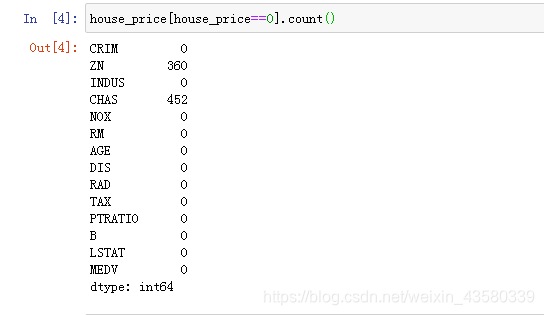
Generalmente, es para ver si el valor propio contiene datos iguales a cero. De hecho, lo más sencillo es ver si los datos contienen valores poco realistas, como la tasa de criminalidad. En la práctica, no existe un área con una tasa de criminalidad igual a 0. De los resultados anteriores, no hay otros problemas con estos datos.
Tanto ZN como CHAS en estos datos usan 0 y 1 como indicador, por lo que es normal incluir 0.
4. Modelado
train=house_price1.drop(["MEDV"],axis=1)
X_train,X_test,y_train,y_test=train_test_split(train,house_price1["MEDV"],random_state=1)
#将MEDV划分为预测值,其它的属性划分为特征值,并将数据划分成训练集和测试集。
ridge=Ridge(alpha=10)#确定约束参数
ridge.fit(X_train,y_train)
print("岭回归训练模型得分:"+str(r2_score(y_train,ridge.predict(X_train))))#训练集
print("岭回归待测模型得分:"+str(r2_score(y_test,ridge.predict(X_test))))#待测集
Después de introducir el algoritmo de cresta, después del modelado, se puntúa la precisión del conjunto de prueba y los resultados obtenidos son los siguientes:

Se puede ver que la precisión de entrenamiento del modelo es de aproximadamente el 79%, y para los nuevos datos, la precisión del modelo es de aproximadamente el 63%.
En este punto, el modelado de este conjunto de datos está completo.
discutir
1. Discusión de los parámetros
Dado que la fórmula del modelo de regresión de crestas y regresión lineal (método de mínimos cuadrados) es la misma, aquí haremos una comparación con la regresión lineal. Los amigos que no entienden la regresión lineal pueden leer otro artículo mío: Práctica de regresión del algoritmo de mínimos cuadrados

El parámetro de restricción que configuramos antes es 10, y el parámetro del modelo anterior se establece en 0. Se puede ver que la precisión de entrenamiento del modelo se ha mejorado, pero la capacidad de generalización se ha reducido. Al mismo tiempo, en comparación con el modelo de regresión lineal, las puntuaciones de los dos son exactamente las mismas. Por lo tanto, cuando el parámetro de restricción de la regresión de cresta se establece en 0, la regresión de cresta sin restricción es el mismo algoritmo que el método ordinario de mínimos cuadrados.
2. Comparación con mínimos cuadrados ordinarios
Echemos un vistazo a las ventajas y desventajas de la regresión de crestas y los mínimos cuadrados ordinarios cambiando los valores de los parámetros de restricción.
result_b=pd.DataFrame(columns=["参数","岭回归训练模型得分","岭回归待测模型得分","线性回归训练模型得分","线性回归待测模型得分"])
train=house_price1.drop(["MEDV"],axis=1)
X_train,X_test,y_train,y_test=train_test_split(train,house_price1["MEDV"],random_state=23)
for i in range(21):
alpha=i/10#约定参数可以选定为小数
ridge=Ridge(alpha=alpha)
ridge.fit(X_train,y_train)
linear=LinearRegression()
linear.fit(X_train,y_train)
result_b=result_b.append([{
"参数":alpha,"岭回归训练模型得分":r2_score(y_train,ridge.predict(X_train)),"岭回归待测模型得分":r2_score(y_test,ridge.predict(X_test)),"线性回归训练模型得分":r2_score(y_train,linear.predict(X_train)),"线性回归待测模型得分":r2_score(y_test,linear.predict(X_test))}])
Los resultados son los siguientes: Se
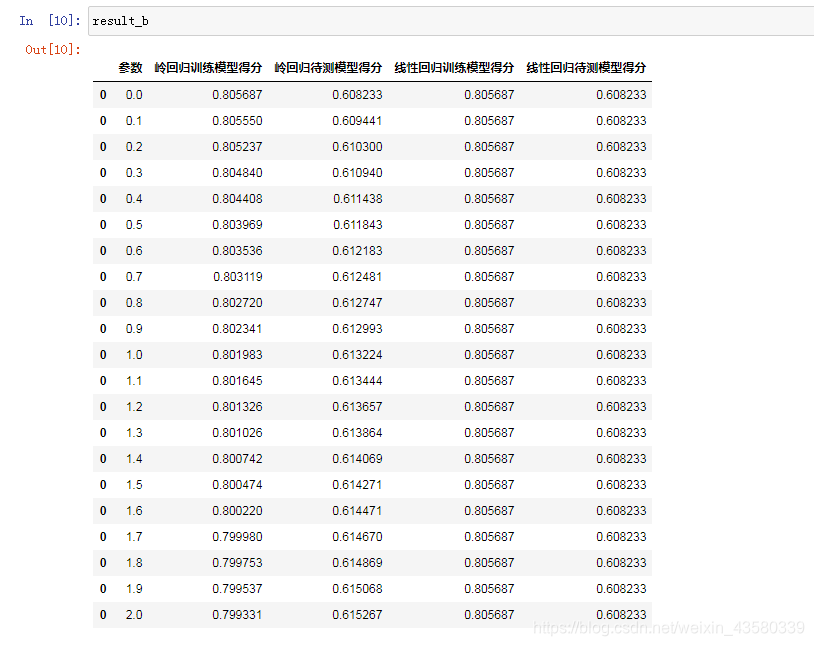
puede ver que si es solo por la precisión del modelo de entrenamiento, el método de mínimos cuadrados es mejor que la regresión de crestas, pero al hacer predicciones sobre nuevos datos, es decir, considerando la capacidad de generalización de la modelo, se puede ver que cresta La puntuación del modelo de regresión es mejor que el método de mínimos cuadrados.
Usamos un gráfico de líneas para mostrar los datos anteriores de manera más intuitiva:
import matplotlib.pyplot as plt
import seaborn as sns
plt.style.use("fivethirtyeight")
sns.set_style({
'font.sans-serif':['SimHei','Arial']})#设定汉字字体,防止出现方框
%matplotlib inline
#在jupyter notebook上直接显示图表
fig= plt.subplots(figsize=(15,5))
plt.plot(result_b["参数"],result_b["岭回归训练模型得分"],label="岭回归训练模型得分")#画折线图
plt.plot(result_b["参数"],result_b["岭回归待测模型得分"],label="岭回归待测模型得分")
plt.plot(result_b["参数"],result_b["线性回归训练模型得分"],label="线性回归训练模型得分")
plt.plot(result_b["参数"],result_b["线性回归待测模型得分"],label="线性回归待测模型得分")
plt.rcParams.update({
'font.size': 12})
plt.legend()
plt.xticks(fontsize=15)#设置坐标轴上的刻度字体大小
plt.yticks(fontsize=15)
plt.xlabel("参数",fontsize=15)#设置坐标轴上的标签内容和字体
plt.ylabel("得分",fontsize=15)
Los resultados son los siguientes: Se
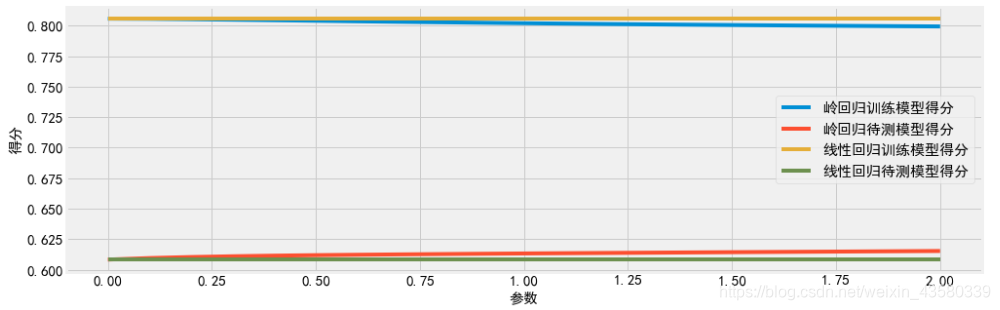
puede ver que el modelo de regresión de la cresta hace un compromiso entre la simplicidad del modelo (todos los coeficientes están cerca de 0) y el rendimiento del conjunto de entrenamiento. El usuario puede determinar la importancia de la simplicidad y el rendimiento del entrenamiento para el modelo configurando los parámetros de aplha. El aumento de alfa hará que los coeficientes se acerquen más a 0, lo que reducirá el rendimiento del conjunto de entrenamiento, pero mejorará el rendimiento de generalización.
Y ya se trate de regresión de crestas o regresión lineal, las puntuaciones de entrenamiento correspondientes a todos los tamaños de conjuntos de datos son más altas que las puntuaciones previstas. Dado que la regresión de crestas está regularizada, su puntuación de entrenamiento es menor que la de la regresión lineal en su conjunto. Pero los puntajes de las pruebas de regresión de crestas son altos, especialmente para conjuntos de datos más pequeños. Si la cantidad de datos es menor que un cierto nivel, la regresión lineal no aprenderá nada. A medida que hay más y más datos disponibles para el modelo, el rendimiento de los dos modelos está mejorando y el rendimiento de la regresión lineal finalmente se pone al día con el regresión de la cresta. Entonces, si hay suficiente contenido de entrenamiento, la regularización se vuelve menos importante y la regresión de crestas y la regresión lineal tendrán el mismo rendimiento.
Lo anterior es sobre el funcionamiento real y las opiniones de Ling Hui. Hay muchos lugares que no son muy buenos. Los internautas son bienvenidos a hacer sugerencias, y espero poder reunirme con algunos amigos para discutir juntos.