Reidentificación de peatones basada en video-02
1. Introducción
Esta sección explica principalmente la importación de datos. El entrenamiento del modelo requiere soporte de datos, por lo que necesitamos preprocesar los datos e ingresarlos.
Cuando la cantidad de datos es relativamente pequeña, podemos utilizar la forma de entrada manual, pero cuando la cantidad de datos es grande, este método es demasiado ineficaz.
Cuando necesitamos usar shuffle, dividir en mini lotes y otras operaciones, podemos usar la API de PyTorch para completar rápidamente estas operaciones (Dataloader).
DataLoader es una herramienta proporcionada por Torch para empaquetar datos. Necesitamos cargar nuestro propio formulario de datos (matriz numérica u otro) en Tensor, y luego ponerlo en este contenedor.
El conjunto de datos es una clase de empaquetado, que se usa para empaquetar datos en una clase de conjunto de datos y luego se pasa al DataLoader, luego usamos la clase DataLoader para operar con los datos más rápidamente.
En la sección anterior, hemos implementado la encapsulación del conjunto de datos de mars en el conjunto de datos, y luego tenemos que reescribir el método del conjunto de datos para pasar los datos al Dataloader de la forma que deseamos.
2 Reescribir el conjunto de datos
Hay una diferencia entre la reidentificación de peatones y el ReID de base de video en esta parte.
2.1 Importar paquete
from __future__ import print_function, absolute_import
import os
from PIL import Image
import numpy as np
import torch
from torch.utils.data import Dataset
import random
# import data_manager
# import torchvision.transforms as T
# from torch.utils.data import DataLoader
# from torch.autograd import Variable
2.2 Cómo leer imágenes
def read_image(img_path):
"""Keep reading image until succeed.
This can avoid IOError incurred by heavy IO process."""
got_img = False
while not got_img:
try:
img = Image.open(img_path).convert('RGB')
got_img = True
except IOError:
print("IOError incurred when reading '{}'. Will redo. Don't worry. Just chill.".format(img_path))
pass
return img
2.3 Reescribir el conjunto de datos
Después de integrar una clase de conjunto de datos, necesitamos reescribir los métodos init, len y getitem,
- init es principalmente para obtener algunos parámetros necesarios
- El método len proporciona el tamaño del conjunto de datos;
- método getitem, este método admite índices de 0 a len (self)
# 这个方法可以用于常见的基于视频重识别的数据集
class VideoDataset(Dataset):
"""Video Person ReID Dataset.
Note batch data has shape (batch, seq_len, channel, height, width).
"""
# 枚举读取方法
sample_methods = ['evenly', 'random', 'all']
# 重写init 在创建类对象时调用
def __init__(self, dataset, seq_len=15, sample='evenly', transform=None):
# dataset为上一节mars对象
self.dataset = dataset
# seq——len 默认为15 项目中一般为4
self.seq_len = seq_len
# 采样方式
self.sample = sample
# 数据增强方式
self.transform = transform
# 返回dataset的大小
def __len__(self):
return len(self.dataset)
# 从 0 到 len(self)的索引
def __getitem__(self, index):
#print(index, len(self.dataset))
img_paths, pid, camid = self.dataset[index]
num = len(img_paths)
# 训练集 输入
if self.sample == 'random':
"""
Randomly sample seq_len consecutive frames from num frames,
if num is smaller than seq_len, then replicate items.
This sampling strategy is used in training phase.
"""
# 从n帧里挑出连续的seq帧作为样本
frame_indices = list(range(num))
rand_end = max(0, len(frame_indices) - self.seq_len - 1)
begin_index = random.randint(0, rand_end)
end_index = min(begin_index + self.seq_len, len(frame_indices))
indices = frame_indices[begin_index:end_index]
# 如果indices帧数不足seq,使用indices补全
for index in indices:
if len(indices) >= self.seq_len:
break
indices.append(index)
indices=np.array(indices)
# 这里准备数组 就是要把img拼接在一起
imgs = []
for index in indices:
index=int(index)
img_path = img_paths[index]
img = read_image(img_path)
if self.transform is not None:
img = self.transform(img)
img = img.unsqueeze(0)
imgs.append(img)
# imgs = [s,c,h,w]
imgs = torch.cat(imgs, dim=0)
#imgs=imgs.permute(1,0,2,3)
return imgs, pid, camid
# 测试集输入
elif self.sample == 'dense':
"""
Sample all frames in a video into a list of clips, each clip contains seq_len frames, batch_size needs to be set to 1.
This sampling strategy is used in test phase.
"""
cur_index=0
frame_indices = list(range(num))
indices_list=[]
# 训练和测试的不同就在于测试需要分析每一张图片
while num-cur_index > self.seq_len:
# 每次向list中添加seq长度的list
indices_list.append(frame_indices[cur_index:cur_index+self.seq_len])
cur_index+=self.seq_len
last_seq=frame_indices[cur_index:]
# 最后不足4个 补全
for index in last_seq:
if len(last_seq) >= self.seq_len:
break
last_seq.append(index)
# imdices——list = [(0,4),(4,8),...]
indices_list.append(last_seq)
imgs_list=[]
for indices in indices_list:
imgs = []
for index in indices:
index=int(index)
img_path = img_paths[index]
img = read_image(img_path)
if self.transform is not None:
img = self.transform(img)
img = img.unsqueeze(0)
imgs.append(img)
# imgs =[s,c,h,w]
imgs = torch.cat(imgs, dim=0)
#imgs=imgs.permute(1,0,2,3)
# imgs_list = [1,s,c,h,w]
imgs_list.append(imgs)
imgs_array = torch.stack(imgs_list)
return imgs_array, pid, camid
else:
raise KeyError("Unknown sample method: {}. Expected one of {}".format(self.sample, self.sample_methods))
Interpretación de la prueba de 3 resultados
3.1 Importación del conjunto de entrenamiento
# test
if __name__ == "__main__":
dataset =data_manager.init_dataset(name="mars")
transform_train = T.Compose([
T.Resize((224, 112)),
T.ToTensor(),
T.Normalize(mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225]),
])
trainloader = DataLoader(
VideoDataset(dataset.train, seq_len=4, sample='random', transform=transform_train),
batch_size=32, shuffle=True, num_workers=1,
pin_memory=False, drop_last=False,
)
# queryloader = VideoDataset(dataset.query,sample='dense',seq_len=16,transform=transform_test)
for batch_idx, (imgs, pids, camids) in enumerate(trainloader):
imgs = Variable(imgs, volatile=True)
print(imgs.size())
# b=1, n=number of clips, s=seq
b, s, c, h, w = imgs.size()
print(b,s,c,h,w)
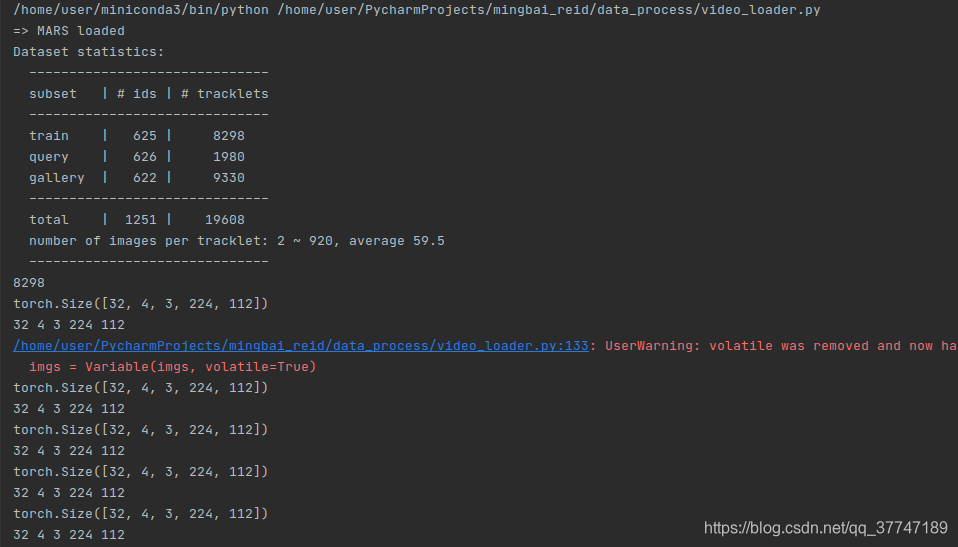
- La longitud del conjunto de datos es 8298, que corresponde al número de tracklets en el conjunto de entrenamiento.
- El tamaño de las imágenes es imgs. El tamaño ([32, 4, 3, 224, 112]) corresponde a [b, s, c, h, w]
3.2 importación de conjuntos de datos de consulta
# test
if __name__ == "__main__":
dataset =data_manager.init_dataset(name="mars")
transform_test = T.Compose([
T.Resize((224, 112)),
T.ToTensor(),
T.Normalize(mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225]),
])
trainloader = DataLoader(
VideoDataset(dataset.query, seq_len=4, sample='dense', transform=transform_test),
batch_size=1, shuffle=False, num_workers=4,
pin_memory=False, drop_last=False,
)
# queryloader = VideoDataset(dataset.query,sample='dense',seq_len=16,transform=transform_test)
for batch_idx, (imgs, pids, camids) in enumerate(trainloader):
imgs = Variable(imgs, volatile=True)
print(imgs.size())
# b=1, n=number of clips, s=seq
b,n, s, c, h, w = imgs.size()
print(b,s,c,h,w)
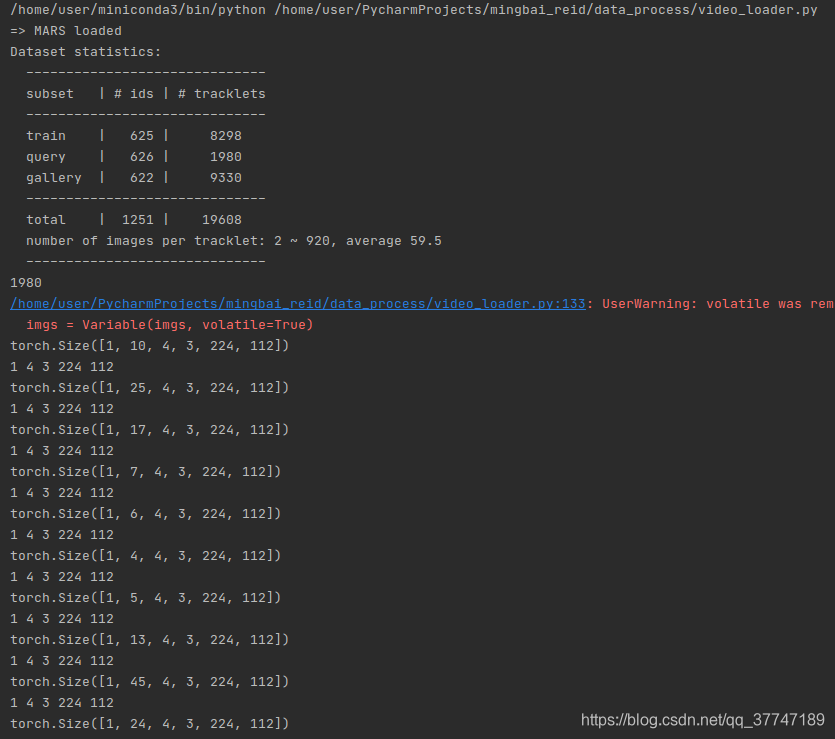
- 1980 es tracklets de consulta
- imgs_arrays.size () = [1,10,4,3,224,112] # [b, n, s, c, h, w]
- La primera pista contiene 39 imágenes, cada 4 imágenes son una secuencia, por lo que n = 10
3.3 Importación del conjunto de datos de la galería
# test
if __name__ == "__main__":
dataset =data_manager.init_dataset(name="mars")
transform_test = T.Compose([
T.Resize((224, 112)),
T.ToTensor(),
T.Normalize(mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225]),
])
trainloader = DataLoader(
VideoDataset(dataset.gallery, seq_len=4, sample='dense', transform=transform_test),
batch_size=1, shuffle=False, num_workers=1,
pin_memory=False, drop_last=False,
)
# queryloader = VideoDataset(dataset.query,sample='dense',seq_len=16,transform=transform_test)
for batch_idx, (imgs, pids, camids) in enumerate(trainloader):
imgs = Variable(imgs, volatile=True)
print(imgs.size())
# b=1, n=number of clips, s=seq
b,n, s, c, h, w = imgs.size()
print(b,n,s,c,h,w)
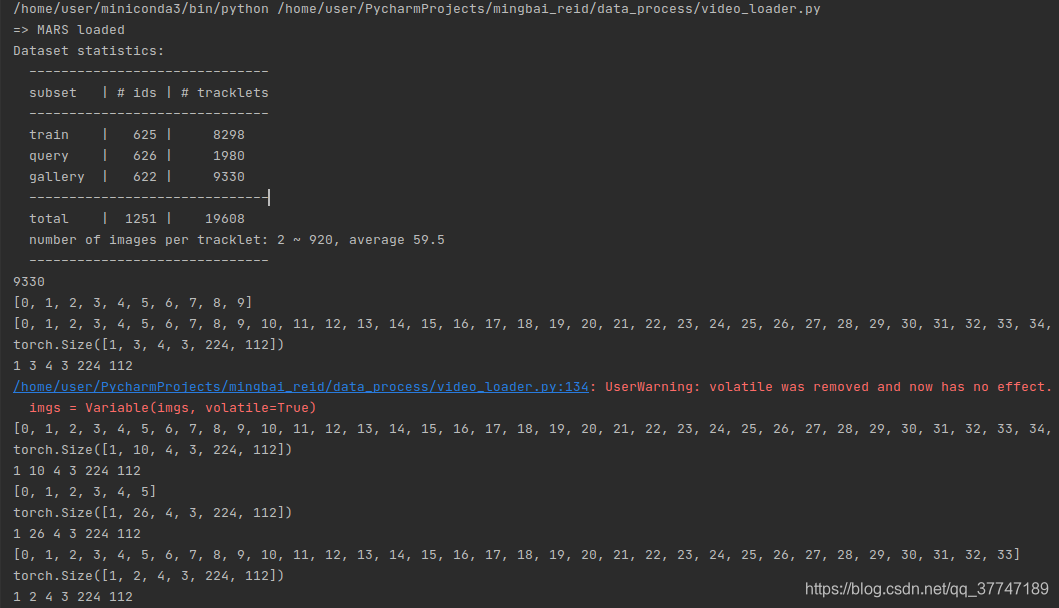
- Hay 9330 tracklets en el conjunto de datos de la galería
- imgs.size () = [1,3,4,3,224,112] ## [b, n, s, c, h, w]
- Básicamente coherente con el conjunto de datos de la consulta