Preste atención a la cuenta oficial : [ Xiao Zhang Python ], he preparado más de 50 libros electrónicos de Python y materiales de aprendizaje en video de alta calidad de 50G + para usted. La palabra clave de respuesta de back-end: 1024 se puede obtener; si tiene Si tiene alguna pregunta sobre el contenido de la publicación del blog, utilice el back-end de la cuenta oficial. Agregue el autor [WeChat personal], puede comunicarse directamente con el autor.
Este artículo usa Python para hacer un video de imagen de nube de palabras. La mitad izquierda del video es un video de baile de la joven y la mitad derecha es un video de nube de palabras generado en base a acciones. Echemos un vistazo al efecto.
Python hizo un video de nube de palabras para ver a una joven bailando desde otro ángulo
El proceso de producción se divide en las siguientes partes
1. Descarga de video
Primero, necesitas descargar un video de una jovencita bailando. Aquí uso la herramienta you-get, que se puede instalar con la ayuda del comando pip de Python
pip install you-get
You-get admite plataformas de descarga que incluyen: Youtube, Blili, TED, Tencent, Youku, iQiyi (que cubre todos los enlaces de descarga de la plataforma de video),
Tome el video de youtube como ejemplo, obtiene el comando de descarga
you-get -o ~/Videos(存放视频路径) -O zoo.webm(视频命名) 'https://www.youtube.com/watch?v=jNQXAC9IVRw'
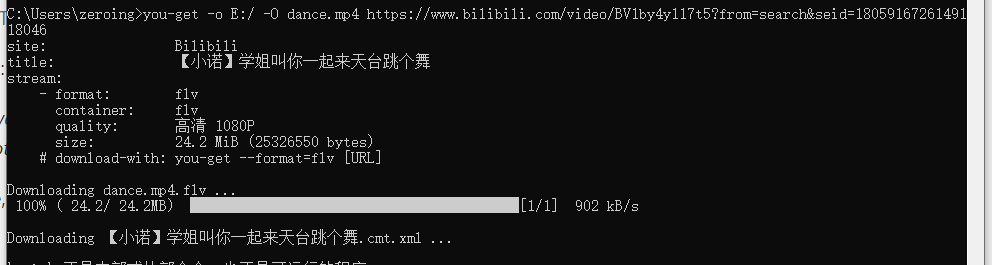
Aquí, el comando you-get download se implementa a través del módulo os, y se pueden pasar tres parámetros al usarlo: 1, el enlace del video, 2, la ruta del archivo para almacenar el video; 3, el nombre del video;
def download(video_url,save_path,video_name):
'''
youget 下载视频
:param video_url:视频链接
:param save_path: 保存路径
:param video_name: 视频命名
:return:
'''
cmd = 'you-get -o {} -O {} {}'.format(save_path,video_name,video_url)
res = os.popen(cmd,)
res.encoding = 'utf-8'
print(res.read())# 打印输出
Para obtener más información sobre el uso de you-get, consulte el sitio web oficial. La introducción de uso es muy detallada:
https://you-get.org/#getting-started
2. Descarga de barrera desde la estación B;
Se requiere soporte de datos de texto para crear imágenes de nube de palabras. Aquí seleccionamos la pantalla de viñetas de la estación B como material; con respecto al método de descarga de la pantalla de viñetas de video de la estación B, aquí hay un método de acceso directo. Utilice solicitudes para acceder a la interfaz API del video especificado para obtener todas las viñetas debajo de la pantalla de video.
http://comment.bilibili.com/{cid}.xml # cid 为B站视频的cid 编号
Pero la estructura de la interfaz API necesita conocer el número cid del video.
Cómo obtener el número cid del video de la estación B: F12 para abrir el modo desarrollador-> NetWork-> XHR-> v2? Cid = ... link , hay una cadena de "cid = una cadena de números" en el enlace de la página web, y el que sigue al signo igual Los números consecutivos son el número cid del video
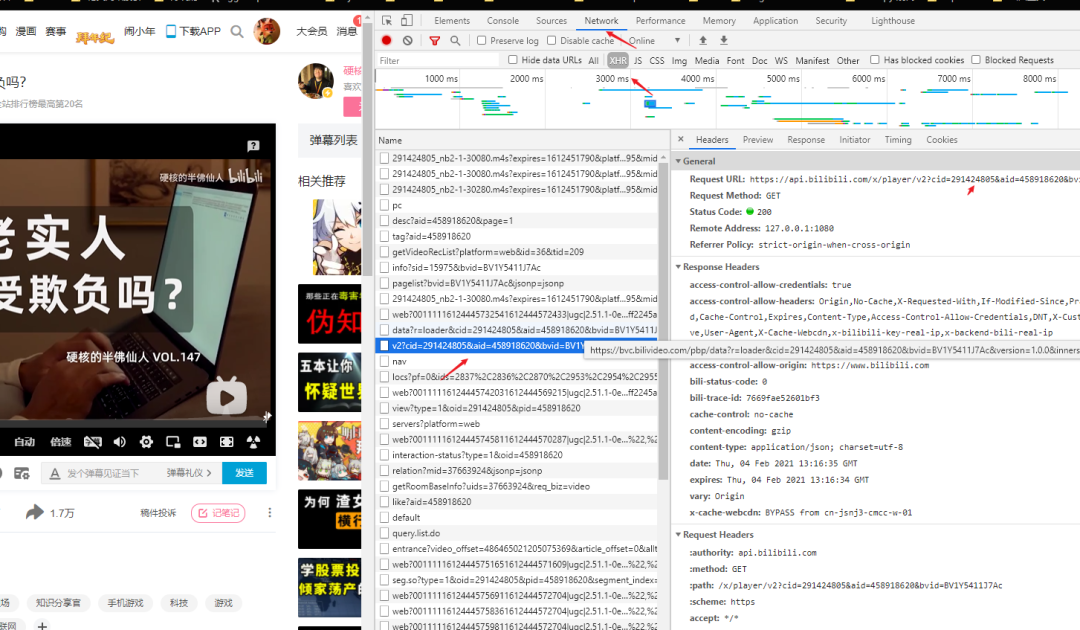
Tome el video anterior como ejemplo, 291424805 es el número cid de este video,
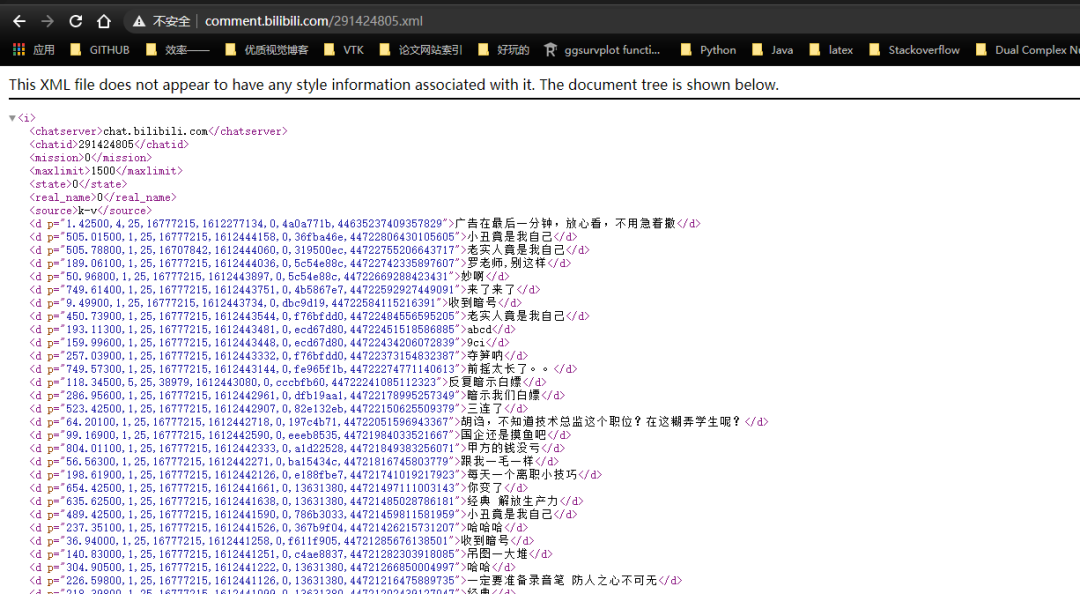
Después de tener cid, a través de la interfaz API de solicitud de solicitudes, puede obtener los datos del bombardeo dentro
http://comment.bilibili.com/291424805.xml
def download_danmu():
'''弹幕下载并存储'''
cid = '141367679'# video_id
url = 'http://comment.bilibili.com/{}.xml'.format(cid)
f = open('danmu.txt','w+',encoding='utf-8') #打开 txt 文件
res = requests.get(url)
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text,'lxml')
items = soup.find_all('d')# 找到 d 标签
for item in items:
text = item.text
print('---------------------------------'*10)
print(text)
seg_list = jieba.cut(text,cut_all =True)# 对字符串进行分词处理,方便后面制作词云图
for j in seg_list:
print(j)
f.write(j)
f.write('\n')
f.close()
3. Corte de fotogramas de video, segmentación vertical
Después de descargar el video, primero divida el video en un cuadro de imagen;
vc = cv2.VideoCapture(video_path)
c =0
if vc.isOpened():
rval,frame = vc.read()# 读取视频帧
else:
rval=False
while rval:
rval,frame = vc.read()# 读取每一视频帧,并保存至图片中
cv2.imwrite(os.path.join(Pic_path,'{}.jpg'.format(c)),frame)
c += 1
print('第 {} 张图片存放成功!'.format(c))

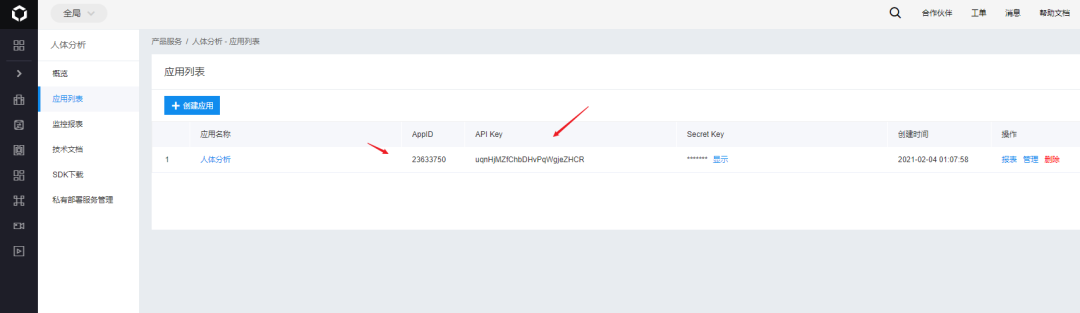
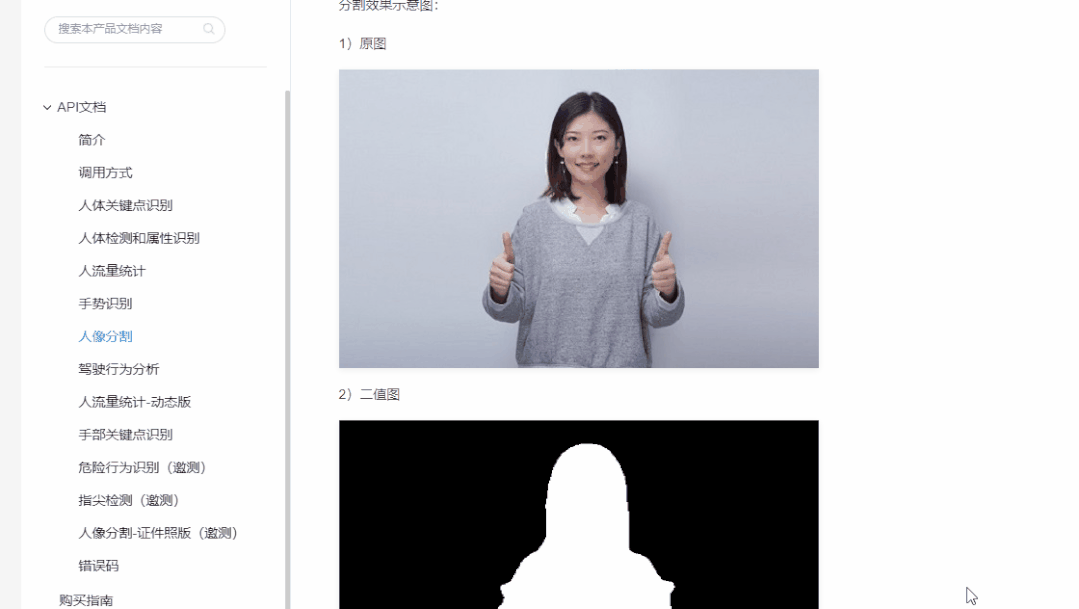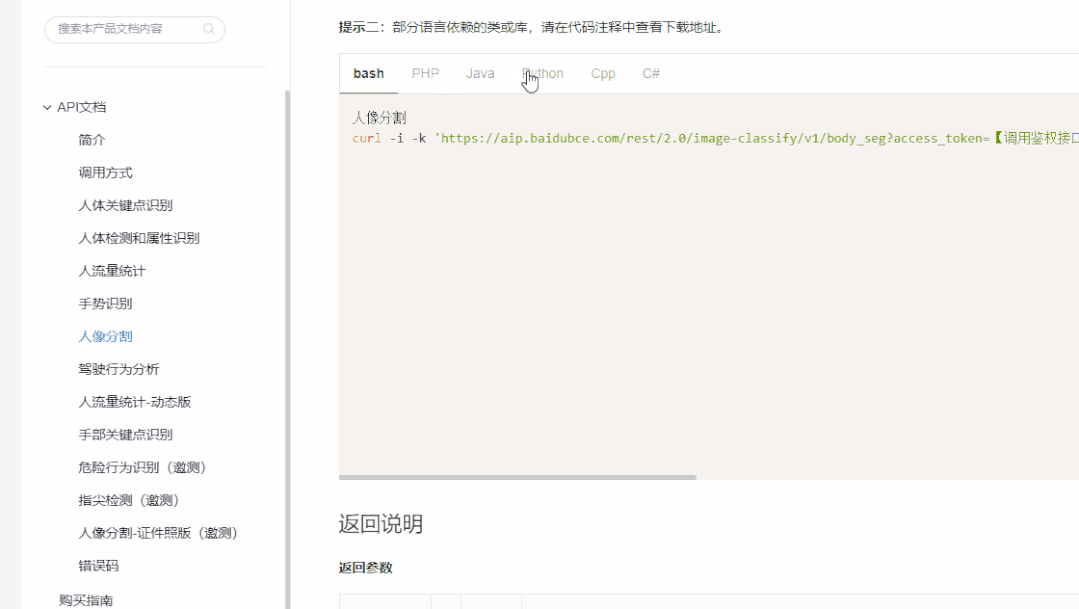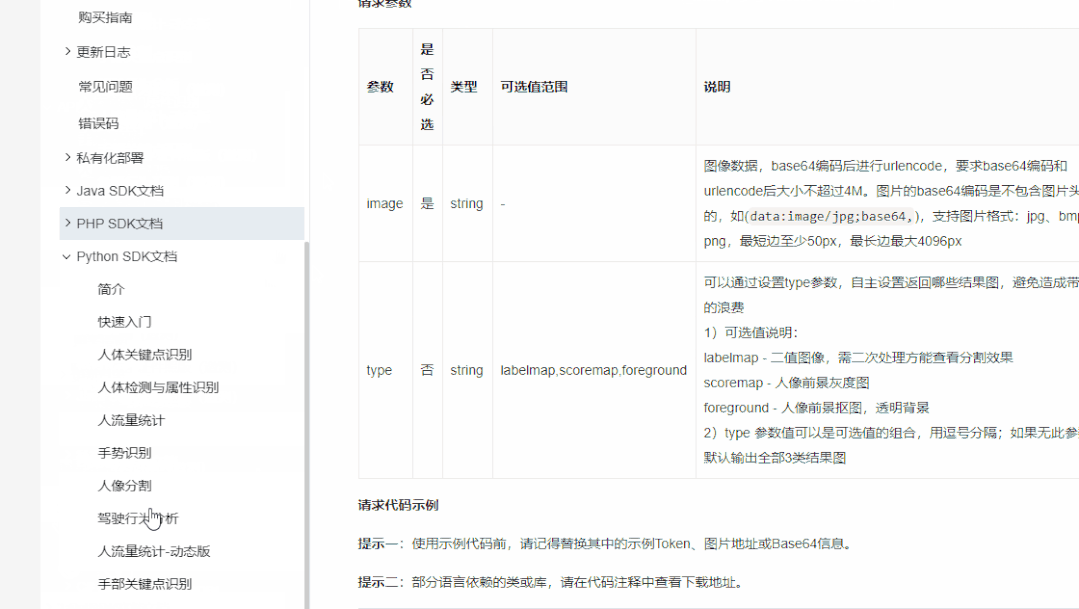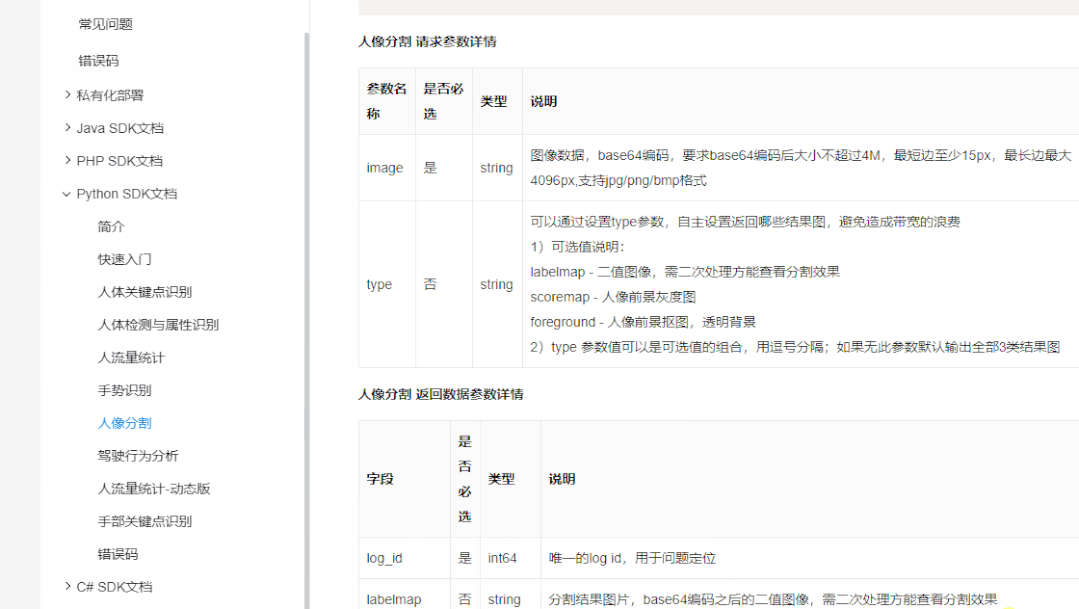
Identifique y extraiga a la joven en cada fotograma, es decir, segmentación de retrato , aquí con la ayuda de la interfaz API de Baidu,
APP_ID = "23633750"
API_KEY = 'uqnHjMZfChbDHvPqWgjeZHCR'
SECRET_KEY = '************************************'
client = AipBodyAnalysis(APP_ID, API_KEY, SECRET_KEY)
# 文件夹
jpg_file = os.listdir(jpg_path)
# 要保存的文件夹
for i in jpg_file:
open_file = os.path.join(jpg_path,i)
save_file = os.path.join(save_path,i)
if not os.path.exists(save_file):#文件不存在时,进行下步操作
img = cv2.imread(open_file) # 获取图像尺寸
height, width, _ = img.shape
if crop_path:# 若Crop_path 不为 None,则不进行裁剪
crop_file = os.path.join(crop_path,i)
img = img[100:-1,300:-400] #图片太大,对图像进行裁剪里面参数根据自己情况设定
cv2.imwrite(crop_file,img)
image= get_file_content(crop_file)
else:
image = get_file_content(open_file)
res = client.bodySeg(image)#调用百度API 对人像进行分割
labelmap = base64.b64decode(res['labelmap'])
labelimg = np.frombuffer(labelmap,np.uint8)# 转化为np数组 0-255
labelimg = cv2.imdecode(labelimg,1)
labelimg = cv2.resize(labelimg,(width,height),interpolation=cv2.INTER_NEAREST)
img_new = np.where(labelimg==1,255,labelimg)# 将 1 转化为 255
cv2.imwrite(save_file,img_new)
print(save_file,'save successfully')
Convierta la imagen que contiene el retrato en una imagen binaria, el primer plano es el personaje y el resto es el fondo.

Antes de usar la API, debe crear una aplicación de análisis del cuerpo humano en Baidu Smart Cloud Platform con su propia cuenta, que requiere tres parámetros: ID, AK, SK
Para saber cómo utilizar la API de Baidu, consulte la documentación oficial.
4.Haga una imagen de nube de palabras de la imagen segmentada.
Según la máscara del retrato de la joven obtenida en el paso 3,

Con la ayuda de la base de datos de nube de palabras de wordcloud y la información de aluvión recopilada, dibuje una imagen de nube de palabras para cada imagen binaria (antes de hacer, asegúrese de que cada imagen sea una imagen binaria, todas las imágenes de píxeles negros deben eliminarse)
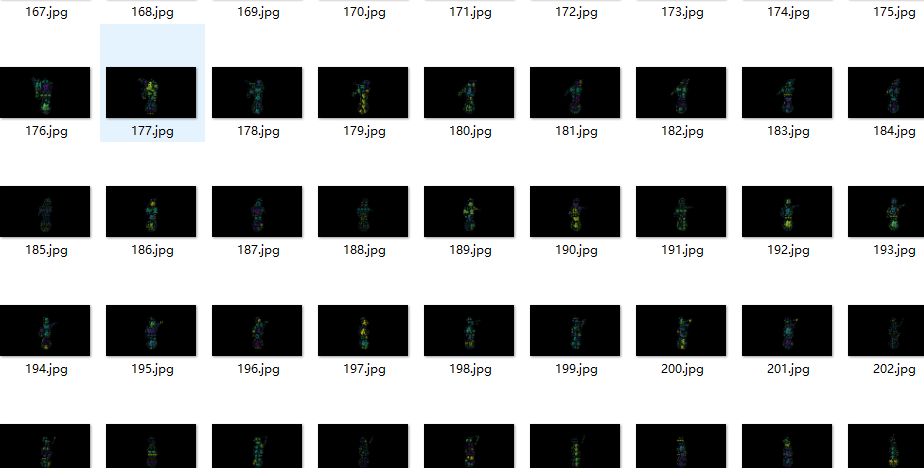
word_list = []
with open('danmu.txt',encoding='utf-8') as f:
con = f.read().split('\n')# 读取txt文本词云文本
for i in con:
if re.findall('[\u4e00-\u9fa5]+', str(i), re.S): #去除无中文的词频
word_list.append(i)
for i in os.listdir(mask_path):
open_file = os.path.join(mask_path,i)
save_file = os.path.join(cloud_path,i)
if not os.path.exists(save_file):
# 随机索引前 start 频率词
start = random.randint(0, 15)
word_counts = collections.Counter(word_list)
word_counts = dict(word_counts.most_common()[start:])
background = 255- np.array(Image.open(open_file))
wc =WordCloud(
background_color='black',
max_words=500,
mask=background,
mode = 'RGB',
font_path ="D:/Data/fonts/HGXK_CNKI.ttf",# 设置字体路径,用于设置中文,
).generate_from_frequencies(word_counts)
wc.to_file(save_file)
print(save_file,'Save Sucessfully!')
5. Unión de imágenes y síntesis de video
Después de que se generen todas las imágenes de la nube de palabras, si miras las imágenes una por una, será aburrido. Si sintetizas las imágenes de la nube de palabras procesadas en un video, ¡será aún mejor!
Para comparar el efecto del video antes y después, agregué un paso más. Antes de fusionar la imagen original y la imagen de nube de palabras, el efecto de síntesis es el siguiente:
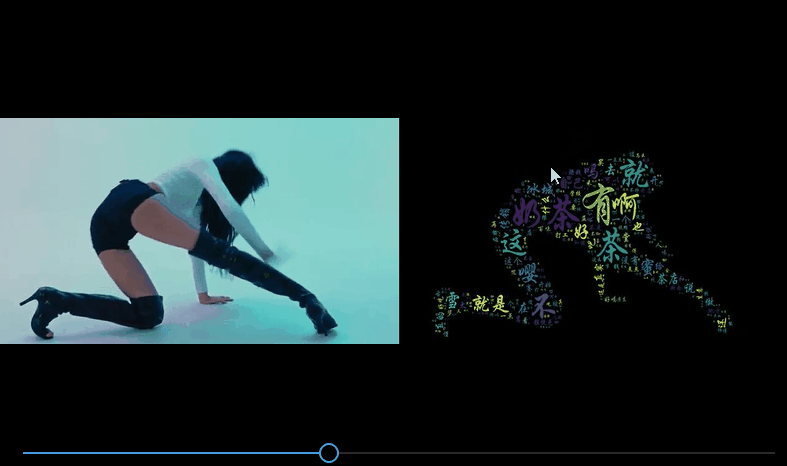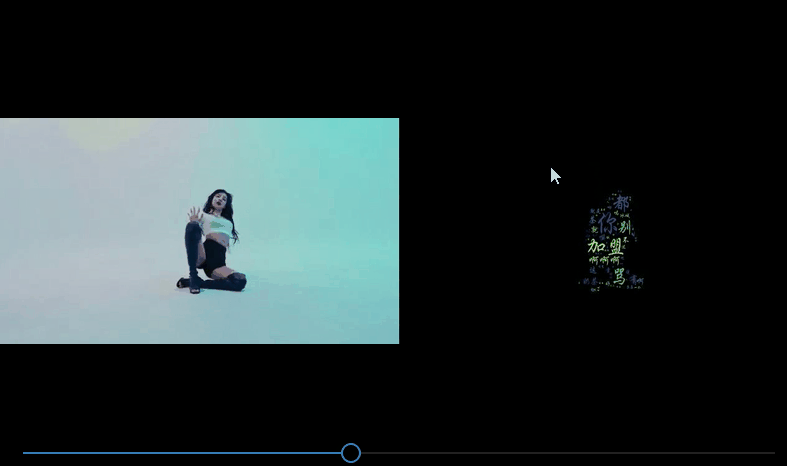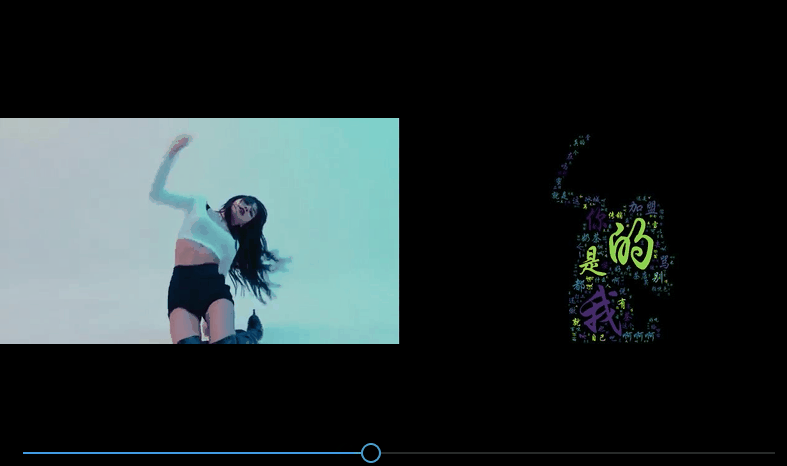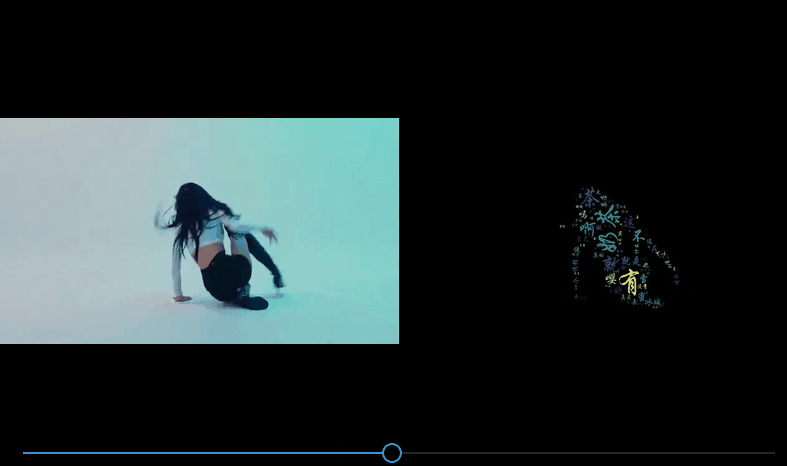
num_list = [int(str(i).split('.')[0]) for i in os.listdir(origin_path)]
fps = 24# 视频帧率,越大越流畅
height,width,_=cv2.imread(os.path.join(origin_path,'{}.jpg'.format(num_list[0]))).shape # 视频高度和宽度
width = width*2
# 创建一个写入操作;
video_writer = cv2.VideoWriter(video_path,cv2.VideoWriter_fourcc(*'mp4v'),fps,(width,height))
for i in sorted(num_list):
i = '{}.jpg'.format(i)
ori_jpg = os.path.join(origin_path,str(i))
word_jpg = os.path.join(wordart_path,str(i))
# com_jpg = os.path.join(Composite_path,str(i))
ori_arr = cv2.imread(ori_jpg)
word_arr = cv2.imread(word_jpg)
# 利用 Numpy 进行拼接
com_arr = np.hstack((ori_arr,word_arr))
# cv2.imwrite(com_jpg,com_arr)# 合成图保存
video_writer.write(com_arr) # 将每一帧画面写入视频流中
print("{} Save Sucessfully---------".format(ori_jpg))
Junto con la música de fondo, el video se puede actualizar a otro nivel ~
Al final
Para todos los métodos de adquisición de código utilizados en este artículo, siga la cuenta pública de WeChat: Xiao Zhang Python y responda a la palabra clave 210204 en segundo plano para obtenerlo.
Con respecto al material del video, declaramos
Hasta el aluvión de la estación principal B Buda semi-inmortal "[Buda] medio té que se une al final, ¿sabes lo engañoso que es? 》
El video de baile de mi hermana pequeña fue tomado del Canal de Youtube Lilifilm Oficial "LILI's FILM # 3-LISA Dance Performance Video"
Finalmente, gracias a todos por leer, ¡nos vemos en el próximo número!