ISR (réplica en sincronización) es un conjunto de conjuntos de sincronización mantenidos por Kafka para una determinada partición, es decir, cada partición tiene su propio conjunto de ISR. La copia en el conjunto de ISR significa que la copia del seguidor y la copia del líder se mantienen en Sincronización. Solo las réplicas del conjunto de ISR son elegibles para ser elegidas como líderes. Un mensaje de Kafka se considera "sincronizado" solo si lo reciben todas las réplicas del ISR. Esto es diferente del mecanismo de sincronización de zk, zk solo necesita más de la mitad de los nodos para escribir, entonces se puede considerar como escrito con éxito.
El proceso de sincronización de datos entre la réplica siguiente y la réplica líder es el siguiente:
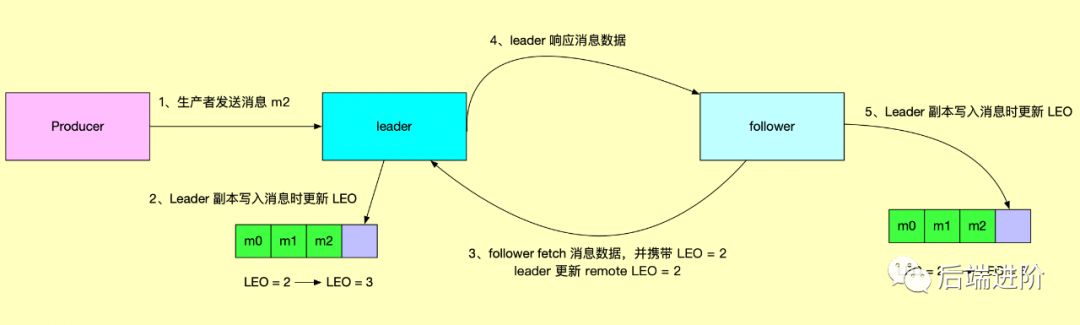
Como se puede ver en la figura anterior, el valor LEO remoto del líder es relativo al valor LEO del seguidor, quedando atrás una solicitud de RPC del seguidor, y el LEO remoto determina el tamaño del valor HW del líder. Para obtener más detalles, consulte " Ilustración: Marca de agua de Kafka Mecanismo de respaldo ".
Esto también significa que la copia del líder siempre lleva a la copia del seguidor, y el último desplazamiento de la noticia entre cada copia de un seguidor no es el mismo. Kafka debe definir un rango de desplazamiento de la copia del líder rezagado, de modo que el seguidor copie dentro de este rango es Se considera que la réplica con el líder se encuentra en un estado sincronizado, es decir, en el conjunto ISR.
(1) Diseño anterior a la versión 0.9.0.0
Antes de la versión 0.9.0.0, si las réplicas están sincronizadas se determina principalmente por el parámetro replica.lag.max.messages, es decir, la cantidad de mensajes que permiten que la réplica seguidora se quede atrás de la réplica líder. Una vez superado este número, el seguidor será expulsado del ISR.
Replica.lag.max.messages también es difícil de dar un valor razonable en la producción. Si el valor es pequeño, hará que el seguidor sea expulsado con frecuencia del ISR. Si el valor es grande, el corredor colapsará y liderará al cambio de líder Se produjo un truncamiento del registro, lo que resultó en una pérdida grave de mensajes.
Puede preguntar, ¿no es suficiente con dar un valor moderado? La clave aquí es ¿qué es moderado? ¿Cómo definir?
Suponiendo que un clúster de Kafka persigue un alto rendimiento, el tamaño del lote del productor se configurará para que sea muy grande y la cantidad de mensajes contenidos en cada transmisión sea grande, lo que mejora enormemente el rendimiento de la transmisión de mensajes. Si min.insync . réplicas = 1, como se puede ver en la figura anterior, el productor responderá exitosamente después de enviar un mensaje y lo guardará en la réplica líder, lo que significa que se ha cumplido con el requisito de prometer al usuario guardar al menos una réplica y el mensaje ha sido enviado con éxito. Ese es el problema. Dado que la réplica del seguidor sincroniza el mensaje de la réplica del líder enviando continuamente solicitudes de búsqueda, si el líder recibe muchos mensajes a la vez, la cantidad de mensajes entre la réplica del líder y la réplica del seguidor será muy diferente. La diferencia es mayor que el valor de replica.lag.max.messages, la réplica del seguidor será expulsada del ISR. Por lo tanto, el clúster debe establecer el valor de replica.lag.max.messages en un valor alto para evitar frecuentes réplicas de seguidores que se expulsan ISR.
Por lo tanto, el diseño de replica.lag.max.messages es defectuoso. Cuando el productor envía una gran cantidad de mensajes, el valor debe aumentarse en consecuencia, pero se corre el riesgo de una pérdida grave de mensajes.
¿Existe una solución mejor?
(2) Diseño posterior a la versión 0.9.0.0
Después de la versión 0.9.0.0, Kafka ofreció una solución mejor, eliminando replica.lag.max.messages y reemplazándolo con el parámetro replica.lag.time.max.ms, lo que significa el valor de tiempo máximo que la réplica seguidora tiene permitido sincronizar mensajes, es decir, siempre que el seguidor tenga un mensaje de sincronización dentro del tiempo replica.lag.time.max.ms, se considera que el seguidor está en el ISR, lo cual es una buena forma de evitar la producción en un momento determinado El usuario envía una gran cantidad de mensajes a la réplica líder a la vez, provocando el problema de contracción y expansión frecuentes de la partición ISR.