1 La evolución de los contenedores concurrentes
Seguridad de subprocesos de conversión de clases de herramientas
Collections.synchronizedList (lista) adopta la forma de bloques de código sincronizados internamente y se bloquea para garantizar la seguridad de subprocesos.
public E get(int index) { synchronized (mutex) {return list.get(index);}}
Vectior y HashTable usan un método sincrónico para bloquear.
En la mayoría de los casos, ConcurrentHashMap y CopyOnWriteArrayList funcionan mejor. CopyOnWriteArrayList es adecuado para leer más y escribir menos, si la lista ha sido modificada, puede ser en forma de Colecciones.
- ConcurrentHashMap: HashMap seguro para subprocesos
- CopyOnWriteArrayList: Lista segura para subprocesos
- BlockingQueue: interfaz, cola de bloqueo, muy adecuada para canales de intercambio de datos
- ConCurrentLinkedQueue: una cola concurrente sin bloqueo eficiente, implementada mediante una lista enlazada. Puede considerarse como una LinkedList segura para subprocesos
2 ConnrentHashMap
2.1 HashMap
¿Por qué no es seguro el hilo de HashMap?
- Los subprocesos chocan con las operaciones de venta al mismo tiempo, lo que resulta en la pérdida de datos;
- La pérdida de datos ocurre cuando los hilos se colocan y expanden al mismo tiempo.
- El bucle infinito provoca el 100% de la CPU. Porque en la expansión concurrente de subprocesos múltiples, el método de cambio de tamaño transer puede generar una lista enlazada circular, lo que conduce a un bucle sin fin. https://coolshell.cn/articles/9606.html
2.2 El principio de realización de ConcurrentHashMap
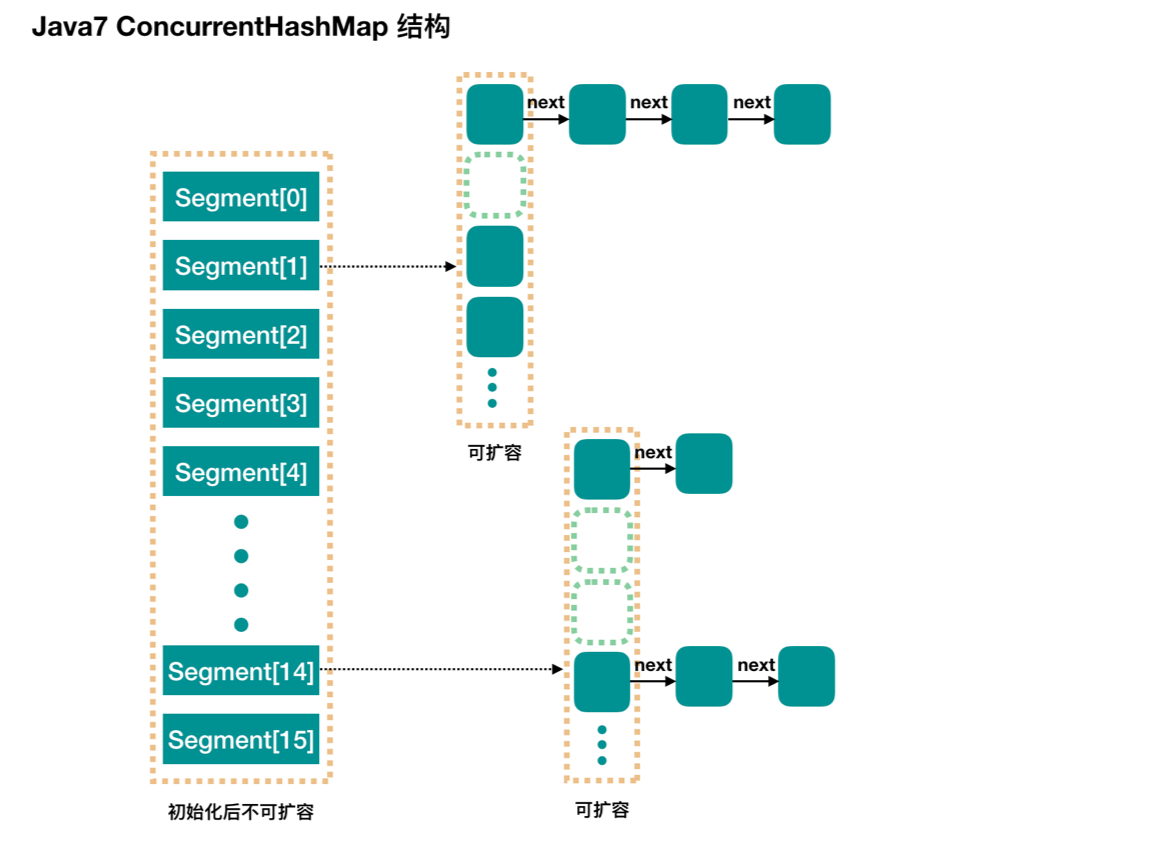
La estructura de la versión 1.7, la capa más externa está configurada con múltiples segmentos, y la estructura subyacente de cada segmento es similar a HashMap, que sigue siendo un método de cremallera compuesto por matrices y listas vinculadas. Cada segmento tiene un bloqueo ReentrantLock independiente, que no se afecta entre sí y mejora la eficiencia de la concurrencia. El valor predeterminado es 16 segmentos, lo que significa que se admiten 16 subprocesos para escritura simultánea. Se establece cuando se inicializa el segmento y no se puede modificar una vez establecido.
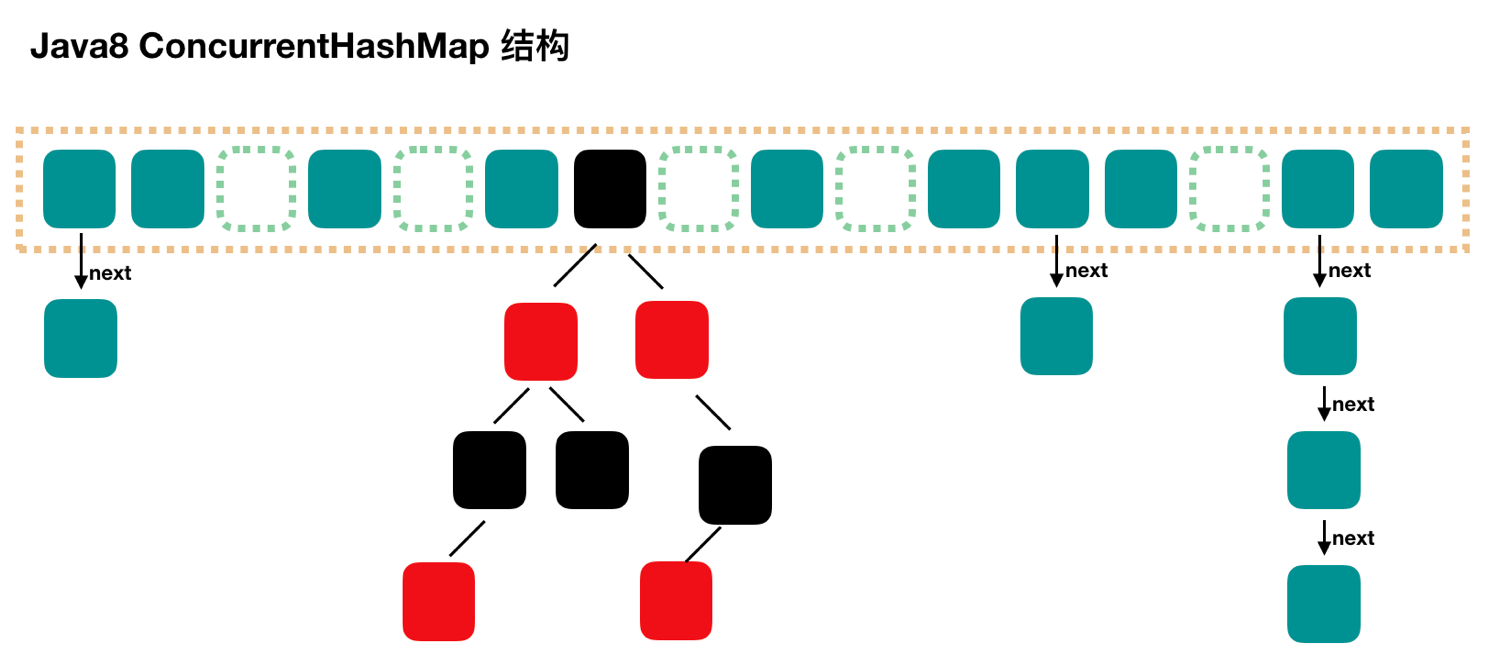
Versión 1.8, la capa inferior adopta la implementación sincronizada de nodo + CAS +. La estructura es similar al HashMap de la versión JDK1.8 En comparación con la versión 1.7, la granularidad del bloqueo es menor y cada nodo tiene la capacidad de concurrencia.
El análisis del código fuente se refiere principalmente al método put / get.
final V putVal(K key, V value, boolean onlyIfAbsent) {
// key和value不允许为空
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
// 记录链表长度
int binCount = 0;
// 循环遍历数组
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh; K fk; V fv;
// 数组为空,初始化数组
if (tab == null || (n = tab.length) == 0)
tab = initTable();
// 数组索引位置桶为空,CAS初始化Node
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value)))
break; // no lock when adding to empty bin
}
// 数组正在resize扩容,则帮助扩容
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
// 找到值并且相同,则直接返回
else if (onlyIfAbsent // check first node without acquiring lock
&& fh == hash
&& ((fk = f.key) == key || (fk != null && key.equals(fk)))
&& (fv = f.val) != null)
return fv;
else {
// 采用synchronized内置锁写入数据
V oldVal = null;
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key, value);
break;
}
}
}
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
else if (f instanceof ReservationNode)
throw new IllegalStateException("Recursive update");
}
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}
la diferencia:
- Estructura de datos: reflejada principalmente en el grado de concurrencia
- Colisión de hash: 1.7 adopta el método de cremallera y 1.8 adopta la forma de conversión de árbol rojo-negro de HashMap.
- Herramientas de concurrencia: 1.7 usa ReentrantLock, 1.8 usa sincronizado y CAS.
2.3 Problemas a los que se debe prestar atención al usar
El uso de ConcurrentHashMap solo puede garantizar que las operaciones put y get del mapa sean seguras para subprocesos, mientras que las operaciones combinadas no pueden garantizar la seguridad para subprocesos, como a ++.
public class OptionsNotSafe implements Runnable {
/**
* map容器
*/
private static ConcurrentHashMap<String, Integer> map = new ConcurrentHashMap<>();
public static void main(String[] args) throws InterruptedException {
map.put("sum", 0);
Thread thread1 = new Thread(new OptionsNotSafe());
Thread thread2 = new Thread(new OptionsNotSafe());
thread1.start();
thread2.start();
}
@Override
public void run() {
for (int i = 0; i < 10000; i++) {
Integer old = map.get("sum");
map.put("sum", old + 1);
}
}
}
Se puede resolver mediante un bloque de código de sincronización sincronizado, pero destruirá la idea de ConcurrentHashMap.
public void run() {
for (int i = 0; i < 10000; i++) {
while (true){
Integer old = map.get("sum");
Integer newVal = old + 1;
if (map.replace("sum", old, newVal)) {
break;
}
}
}
}
Reemplazar usa la idea de giro y devuelve verdadero solo cuando la actualización es exitosa.