
El artículo anterior introdujo el uso de las funciones básicas de Pandas. Este artículo presenta principalmente las funciones de filtrado y clasificación condicional de Pandas, ¡también con la ayuda de una pequeña caja!
1. Leer los datos
Primero use la función read_csv () para ingresar los datos. Estos datos son los datos de una categoría de producto, que tiene varios atributos como cantidad (clase), nombre (nombre), descripción (descripción), precio (precio), etc. .:
import pandas as pd
url = "https://raw.githubusercontent.com/justmarkham/DAT8/master/data/chipotle.tsv"
chipo = pd.read_csv(url,sep = '\t')
chipo
2. Cambiar el tipo de datos y el nombre de carácter de una columna.
Hay un carácter "$" en la columna de precio en los datos leídos. Al procesar datos, este símbolo debe eliminarse. A continuación, se muestran dos formas:
1. Reemplazar lista y serie, primero formatee cada dato en una determinada columna para obtener la lista, y luego asigne la lista a la columna que necesita ser reemplazada;
prices = [float(value[1:-1]) for value in chipo.item_price]
chipo.item_price = prices2. Utilice las funciones apply () y lambda para reemplazar;
chipo['item_price'] = chipo['item_price'].apply(lambda x:float(x[1:-1]))
3. Elimina los datos repetidos en varias columnas.
La redundancia de datos a menudo ocurre cuando se procesan datos. En este momento, es necesario eliminar los datos redundantes en los datos de antemano (el fenómeno de la duplicación de datos en varias columnas en una fila). La función utilizada es drop_duplicates (['nombre de columna 1' , 'nombre de columna 2']) función
Lo que se elimina aquí son los datos duplicados en las tres columnas de item_name, amount y choice_description:
chipo_filtered = chipo.drop_duplicates(['item_name','quantity','choice_description'])
chipo_filtered
4. Examen condicional
1. Filtra los datos cuyo valor de cantidad es 1:
chipo_one_prod = chipo_filtered[chipo_filtered.quantity==1]
chipo_one_prod
2. Sobre la base de 1, filtre los datos cuyo item_price sea mayor que 10 y use nunique para verificar el número de elementos únicos de item_name:
chipo_one_prod[chipo_one_prod['item_price']>10].item_name.nunique()
# 输出结果
# 25 El filtrado condicional en 3, 2 también se puede utilizar para filtrar:
chipo.query("item_price>10")
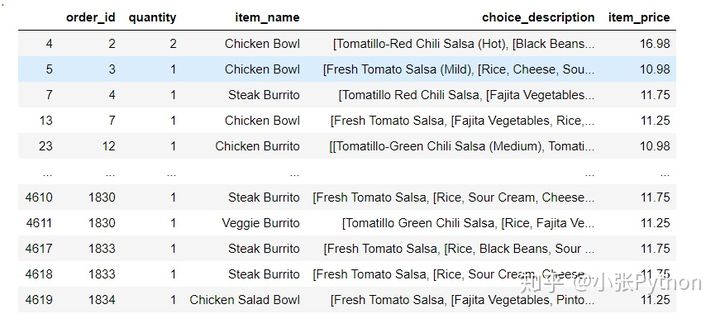
4. Filtre datos con varias condiciones y filtre los datos que satisfagan item_name como Chicken Bowl y cantidad como 1
chipo[(chipo['item_name']=='Chicken Bowl')&(chipo['quantity']==1)]
El & (y) usado en 5, 4 para conectar declaraciones condicionales, aquí están los siguientes | (o):
Necesita cumplir con los datos cuyo item_name no es Chicken Bowl o la cantidad es 1
chipo[(chipo['item_name']!='Chicken Bowl')|(chipo['quantity']!=1)]

4. Ordena los datos en la columna especificada.
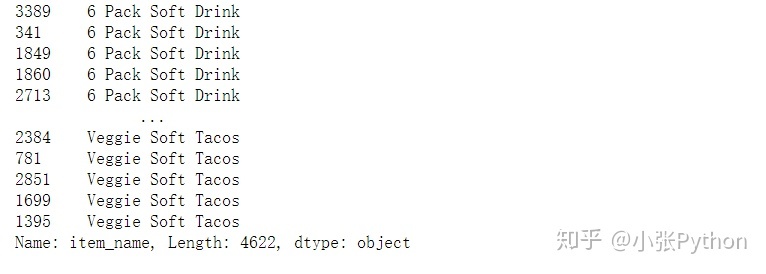
1. Ordene una determinada columna de datos, y el resultado final solo mostrará el resultado de esta columna después de ordenar. Instrucción de comando: data.column name.sort_values (), por ejemplo, aquí está ordenando con la columna de item_name:
chipo.item_name.sort_values()# Sorting the values
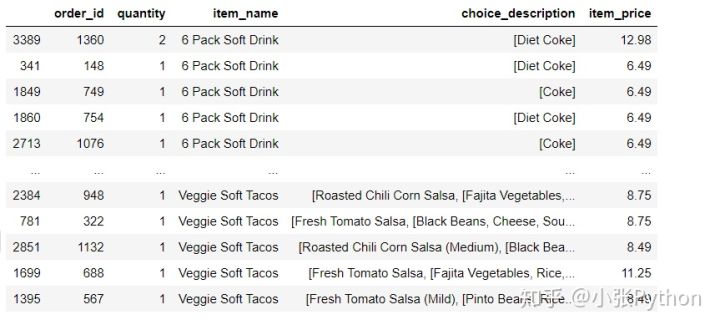
2. Data.sort_values (por = nombre de columna) se ordena por una determinada columna de datos, correspondiente a otros datos de columna, la posición debe cambiarse y todos los datos ordenados finalmente se muestran
chipo.sort_values(by = 'item_name')
La aplicación avanzada en 3, 2. Por ejemplo, aquí quiero ver el nombre del producto más caro en los datos . Aquí, utilizo el método de 2 para invertir el item_price, y luego extraigo el item_name de la primera fila del ordenado datos.
chipo.sort_values(by = 'item_price',ascending = False).head(1).item_name
# 打印结果
# 3598 Chips and Fresh Tomato Salsa
Name: item_name, dtype: object5. Método Data.loc para filtrar datos
Nota: cuando se usa el método data.loc para filtrar datos, solo los nombres de fila y columna se pueden usar como condiciones de filtrado
1. Filtre los datos con los nombres de fila 2, 3 y los nombres de columna cantidad, nombre_del_artículo, precio_del artículo
chipo.loc[[2,3],['quantity','item_name','item_price']]

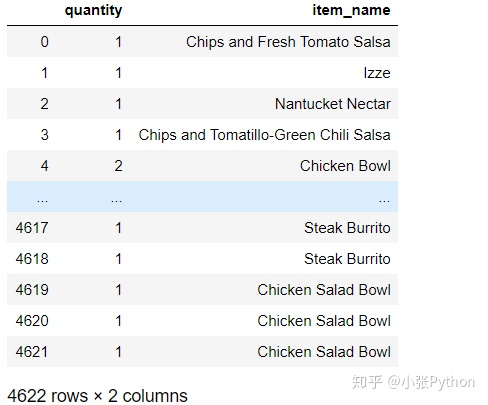
2. No hay restricciones en el nombre de la fila, solo se filtran la cantidad del nombre de la columna y los datos del nombre del artículo.
chipo.loc[:,['quantity','item_name']]
3. No hay restricciones en los nombres de las columnas, solo se filtran los datos con los nombres de las filas 5 y 6.
chipo.loc[[5,6],:]

4. La aplicación completa filtra: dos columnas de datos cuyo nombre de fila puede ser divisible por 8 y nombres de columna item_price y item_name
chipo.loc[chipo.index%8==0,['item_name','item_price']]
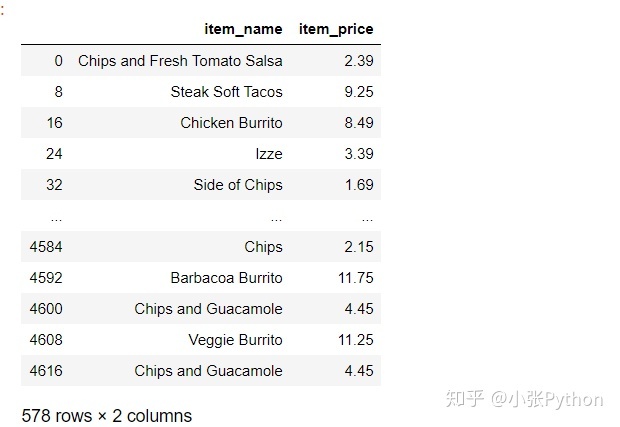
6, método data.iloc para filtrar datos
La idea de los métodos data.iloc y data.loc solo se puede seleccionar en función de los valores de índice, no los nombres de columna y los nombres de fila como condiciones de filtro
1. Filtre los datos en las filas 5-8 y columnas 2-3
chipo.iloc[4:8,1:3]

2. Filtre los datos en las filas 2-4;
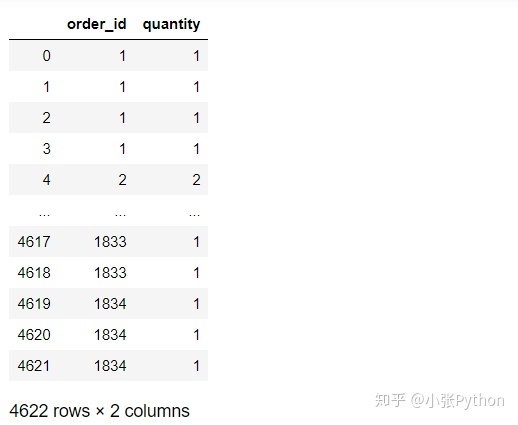
chipo.iloc[1:4,:]

3. Filtre las dos primeras columnas de datos:
chipo.iloc[:,:2]
Lo anterior es el contenido completo de este artículo. Amigos que no estén familiarizados con la aplicación de algunos de los métodos en él, recuerden seguir el código y escribirlo nuevamente para profundizar su comprensión.