En "Spark Fast Big Data Analysis", hay un fragmento de código Scala poco claro que implementa el algoritmo PageRank de Google en solo unas pocas líneas, así que hice un pequeño experimento para verificarlo.
1. Ambiente experimental
chispa 1.5.0
2. Introducción al algoritmo PageRank (tomado de "Spark Fast Big Data Analysis")
PageRank es un algoritmo iterativo que realiza múltiples conexiones, por lo que es un buen caso de uso para operaciones de partición RDD. El algoritmo mantiene dos conjuntos de datos: uno está compuesto por elementos (pageID, linkList) y contiene una lista de páginas adyacentes de cada página; el otro está compuesto por elementos (pageID, ranking) y contiene el valor de clasificación actual de cada página. Se calcula de la siguiente manera.
Inicialice el valor de clasificación de cada página en 1.0.
En cada iteración, para la página p, se envía un valor de contribución de rank (p) / numNeighbors (p) a cada una de sus páginas adyacentes (páginas con enlaces directos).
Establezca el valor de clasificación de cada página en 0,15 + 0,85 * contribuciones recibidas.
Los dos últimos pasos se repetirán en varios ciclos Durante este proceso, el algoritmo convergerá gradualmente al valor real de PageRank de cada página. En la práctica, la convergencia suele requerir unas 10 iteraciones.
3. Datos de simulación
Suponga un pequeño grupo que consta de 4 páginas: A, B, C y D. Las páginas adyacentes son las siguientes:
A: BC
B: AC
C: ABD
D: C
Cuatro, código de prueba
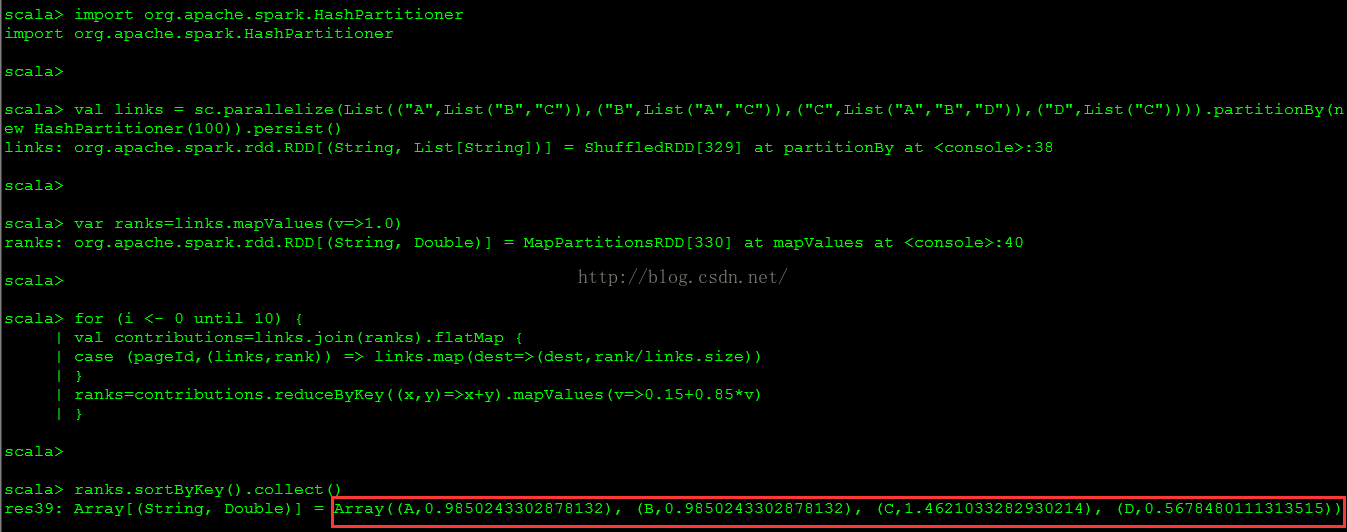
import org.apache.spark.HashPartitioner
val links = sc.parallelize(List(("A",List("B","C")),("B",List("A","C")),("C",List("A","B","D")),("D",List("C")))).partitionBy(new HashPartitioner(100)).persist()
var ranks=links.mapValues(v=>1.0)
for (i <- 0 until 10) {
val contributions=links.join(ranks).flatMap {
case (pageId,(links,rank)) => links.map(dest=>(dest,rank/links.size))
}
ranks=contributions.reduceByKey((x,y)=>x+y).mapValues(v=>0.15+0.85*v)
}
ranks.sortByKey().collect()El resultado de la ejecución se muestra en la siguiente figura.
Los enlaces iniciales RDD y ranksRDD son los siguientes:
linksRDD:
Array [(String, List [String])] = Array ((A, List (B, C)), (B, List (A, C)), (C, List (A, B, D)), (D, List (C)))
ranksRDD:
Array [(String, Double)] = Array ((A, 1.0), (B, 1.0), (C, 1.0), (D, 1.0))
Las contribucionesRDD y ranksRDD después de la primera iteración son las siguientes:
contribucionesRDD:
Array [(String, Double)] = Array ((A, 0.5), (A, 0.3333333333333333), (B, 0.5), ( B, 0.3333333333333333), (C, 0.5), (C, 0.5), (C, 1.0), (D, 0.3333333333333333))
ranksRDD:
Array [(String, Double)] = Array ((A, 0.8583333333333333), (B , 0.8583333333333333), (C, 1.8499999999999999), (D, 0.43333333333333335))
Datos de verificación: La
primera iteración:
PR (A) = 0.15 + 0.85 * (1/2 + 1/3) = 0.858333
PR (B) = 0.15 + 0,85 * (1/2 + 1/3) = 0,858333
PR (C) = 0.15 + 0.85 * (1/2 + 1/2 + 1/1) = 1.85
PR (D) = 0.15 + 0.85 * (1/3) = 0.433333
第 2 次 迭代 :
PR (A) = 0.15 + 0.85 * (0.858333 / 2 + 1.85 / 3) = 1.038958191100
PR (B) = 0.15 + 0.85 * (0.858333 / 2 + 1.85 / 3) = 1.038958191100
PR (C) = 0.15 + 0.85 * (0.858333 / 2 + 0.858333 / 2 + 0.433333 / 1) = 1.247916100000
PR (D) = 0.15 + 0.85 * (1.85 / 3) = 0.67416667
第 3 次 迭代 :
PR (A) = 0.15 + 0.85 * (1.038958191100 / 2 + 1.247916100000 / 3) = 0.945133459550833333
PR (B) = 0.15 + 0.85 * (1.038958191100 / 2 + 1.247916100000 / 3) = 0.945133459550833333
PR (C) = 0.15 + 0.85 * (1.038958191100 / 2 + 1.038958191100 / 2 + 0.67416667 / 1) = 1.60615613 01935000000
D ( 0,85 * (1,247916100000 / 3) = 0,503576228333333333
5. Descripción del código (tomado de "Spark Fast Big Data Analysis") ¡
Eso es! El algoritmo comienza inicializando el valor de cada elemento de ranksRDD a 1.0, y luego actualiza continuamente la variable de ranks en cada iteración. Escribir el cuerpo principal de PageRank en Spark es bastante simple: primero realice una operación join () en los ranksRDD actuales y el linkRDD estático para obtener la lista de páginas adyacentes correspondiente a cada ID de página y el valor de clasificación actual, y luego use flatMap para crear un "Contribuciones" para registrar la contribución de cada página a cada página adyacente. Luego sume estos valores de contribución de acuerdo con el ID de la página (de acuerdo con la página compartida) y establezca el valor de clasificación de la página en 0.15 + 0.85 * contribuciones recibidas.
Aunque el código en sí es muy simple, este programa de muestra hace muchas cosas para garantizar que el RDD esté particionado de una manera más eficiente para minimizar la sobrecarga de comunicación:
(1) Tenga en cuenta que linksRDD se conectará a rangos en cada iteración. Dado que los enlaces son un conjunto de datos estáticos, los dividimos al comienzo del programa, por lo que no es necesario mezclarlos a través de la red. De hecho, el número de bytes de linksRDD es generalmente mucho mayor que los rangos. Después de todo, contiene una lista de páginas adyacentes de cada página (que consta de ID de página), no solo un valor Double, por lo que esta optimización se compara relativamente con el implementación original de PageRank (como MapReduce ordinario), ahorra una considerable sobrecarga de comunicación de red.
(2) Por la misma razón, llamamos al método de enlaces persist () y lo guardamos en la memoria para cada iteración.
(3) Cuando creamos rangos por primera vez, usamos mapValues () en lugar de map () para preservar el método de partición del RDD principal (enlaces), de modo que la primera operación de conexión tenga una pequeña sobrecarga.
(4) En el cuerpo del bucle, usamos mapValues () después de reduceByKey (); debido a que el resultado de reduceByKey () ya tiene particiones hash, de esta manera, el resultado de la operación de mapeo se realizará con enlaces nuevamente en el siguiente ciclo Será más eficiente cuando esté conectado.
El lenguaje de scala es realmente conciso. El programa de ejemplo general de recuento de palabras en big data se puede hacer escribiendo una línea en scala, como se muestra en la siguiente figura:
var input = sc.textFile("/NOTICE.txt")
input.flatMap(x=>x.split(" ")).countByValue()