El texto tiene una longitud indefinida y el método de representar el texto como un número o vector que se puede calcular se llama incrustación de palabras. La incrustación de palabras consiste en convertir texto de longitud variable en un espacio de longitud fija. Para resolver el problema de convertir el texto original en un vector de características de longitud fija, scikit-learn proporciona los siguientes métodos:
-
Tokenización: Divida cada token posible en una cadena y asigne una identificación en forma de número entero, utilizando espacios y puntuación como separadores de token.
-
Contando el número de apariciones de cada token de palabra en el documento.
-
La normalización es un peso que reduce el número de apariciones de tokens de palabras importantes.
Utilice métodos tradicionales de aprendizaje automático para la clasificación de texto. Las ideas incluyen Count Vectores + algoritmo de clasificación (LR / SVM / XGBoost, etc.), TF-IDF + algoritmo de clasificación (LR / SVM / XGBoost, etc.)
1 conteo de vectores + algoritmo de clasificación
1.1 contar vectores
La clase countVectorizer implementa la tokenización (segmentación de palabras) y el conteo de ocurrencias (conteo de ocurrencias) en una sola clase:
La función es:

Parámetros detallados:
entrada: cadena {'nombre de archivo', 'archivo', 'contenido'}, predeterminado = 'contenido'
Defina el formato de los datos de entrada. Si es nombre de archivo, lea la lista de nombres de archivo para obtener el contenido original a analizar; si es 'archivo', el elemento de secuencia debe tener un método read '(objeto similar a archivo ), que es Call para obtener los bytes en la memoria; si es 'contenido', la entrada debe ser una cadena o un elemento de secuencia de tipo byte.
codificación: cadena, predeterminado = 'utf-8'
Al analizar, utilice este tipo para decodificar.
minúsculas: bool, predeterminado = verdadero
Antes de tokenizar, convierta los caracteres a minúsculas
ngram_range: tupla (min_n, max_n), predeterminado = (1, 1)
Los límites superior e inferior del rango de valores n de diferentes n-gramas de palabras o n-gramas de caracteres que se van a extraer.
analizador: cadena, {'palabra', 'char', 'char_wb'} o invocable, predeterminado = 'palabra'
Ya sea que el análisis esté compuesto por n-gramas de palabras o n-gramas de caracteres, 'char_wb' es un estado mixto.
max_df: flotante en el rango [0.0, 1.0] o int, predeterminado = 1.0
Al construir el vocabulario, ignore los términos cuya frecuencia de documento sea estrictamente superior a un umbral determinado (palabras vacías específicas del corpus). Si es un flotante, este parámetro representa la proporción del documento, un número entero absoluto. Si el vocabulario no es ninguno, este parámetro se ignora.
min_df: flotante en el rango [0.0, 1.0] o int, predeterminado = 1
Al construir el vocabulario, ignore los términos cuya frecuencia de documento esté estrictamente por debajo del umbral dado. Este valor también se denomina valor de corte en la literatura. Si es un flotante, este parámetro representa la proporción del documento, un número entero absoluto. Si el vocabulario no es ninguno, este parámetro se ignora.
ejemplo:
from sklearn.feature_extraction.text import CountVectorizer
corpus = [
'This is the first document.',
'This document is the second document.',
'And this is the third one.',
'Is this the first document?'
]
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(corpus)
print(vectorizer.get_feature_names())
print(X.toarray())
vectorizer2 = CountVectorizer(analyzer='word', ngram_range=(2, 2))
X2 = vectorizer2.fit_transform(corpus)
print(vectorizer2.get_feature_names())
print(X2.toarray())
1.2 Algoritmo de clasificación
Aquí, la regresión de cresta en el modelo lineal se usa para la clasificación, y también se pueden usar modelos de algoritmos de clasificación como SVM, LR, XGBoost, etc. Posteriormente, se usará para el recorrido de parámetros con búsqueda de cuadrícula (GridSearchCV).
Análisis comprensivo:
import pandas as pd
import xgboost as xgb
import lightgbm as lgb
import catboost as cat
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.linear_model import RidgeClassifier
from sklearn.model_selection import GridSearchCV
from sklearn.svm import SVC
from sklearn.metrics import f1_score
from sklearn.pipeline import Pipeline
train_df = pd.read_csv('data/data45216/train_set.csv',sep='\t',nrows=15000)
print(train_df.shape)
vectorizer = CountVectorizer(max_features=3000)
train_test = vectorizer.fit_transform(train_df['text'])
clf = RidgeClassifier()
clf.fit(train_test[:10000],train_df['label'].values[:10000])
val_pred = clf.predict(train_test[10000:])
print(f1_score(train_df['label'].values[10000:],val_pred,average='macro'))
El resultado de salida es: 0,65441877581244
2 algoritmo de clasificación TF-IDF +
2.1 TF-IDF
TF-IDF es el término frecuencia inversa de la frecuencia del documento, lo que significa que si una palabra o frase aparece en un artículo con una alta frecuencia de TF y rara vez aparece en otros artículos, se considera que la palabra o frase tiene una buena distinción de categoría. apto para clasificación. El supuesto de TF-IDF es que las palabras de alta frecuencia deben tener un peso alto, a menos que también sea una frecuencia de documentos alta. La frecuencia inversa del miedo al documento consiste en utilizar la frecuencia del documento del término para compensar la influencia de la frecuencia del término de la palabra en el peso y obtener un peso menor.
Término Frecuencia (Término Frecuencia, TF) se refiere a la frecuencia con la que una palabra determinada aparece en el archivo. Este número es la normalización del recuento de términos (Term Count) para evitar que esté sesgado hacia documentos largos. Para una palabra en un documento en particular, su importancia se puede expresar como:
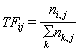
Entre ellos, el numerador es el número de apariciones de la palabra en el documento y el denominador es la suma del número de apariciones de todas las palabras en el documento.
La frecuencia inversa de documentos (IDF) es una medida de la importancia universal de las palabras. El IDF de una palabra en particular se puede obtener dividiendo el número total de documentos por el número de documentos que contienen la palabra y luego tomando el logaritmo del cociente obtenido:
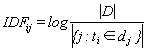
Entre ellos ![]() ,: el número total de documentos en el corpus; j: el número de documentos que contienen una palabra. Si la palabra no está en el corpus, el denominador será 0. Por lo tanto, a menudo se usa
,: el número total de documentos en el corpus; j: el número de documentos que contienen una palabra. Si la palabra no está en el corpus, el denominador será 0. Por lo tanto, a menudo se usa ![]() como denominador, y luego se calcula el producto de TF y IDF.
como denominador, y luego se calcula el producto de TF y IDF.
La función es:

Parámetros detallados:
entrada: cadena {'nombre de archivo', 'archivo', 'contenido'}, predeterminado = 'contenido'
Defina el formato de los datos de entrada. Si es nombre de archivo, lea la lista de nombres de archivo para obtener el contenido original a analizar; si es 'archivo', el elemento de secuencia debe tener un método read '(objeto similar a archivo ), que es Call para obtener los bytes en la memoria; si es 'contenido', la entrada debe ser una cadena o un elemento de secuencia de tipo byte.
codificación: cadena, predeterminado = 'utf-8'
Al analizar, utilice este tipo para decodificar.
minúsculas: bool, predeterminado = verdadero
Antes de tokenizar, convierta los caracteres a minúsculas
ngram_range: tupla (min_n, max_n), predeterminado = (1, 1)
Los límites superior e inferior del rango de valores n de diferentes n-gramas de palabras o n-gramas de caracteres que se van a extraer.
analizador: cadena, {'palabra', 'char', 'char_wb'} o invocable, predeterminado = 'palabra'
Ya sea que el análisis esté compuesto por n-gramas de palabras o n-gramas de caracteres, 'char_wb' es un estado mixto.
max_df: flotante en el rango [0.0, 1.0] o int, predeterminado = 1.0
Al construir el vocabulario, ignore los términos cuya frecuencia de documento sea estrictamente superior a un umbral determinado (palabras vacías específicas del corpus). Si es un flotante, este parámetro representa la proporción del documento, un número entero absoluto. Si el vocabulario no es ninguno, este parámetro se ignora.
min_df: flotante en el rango [0.0, 1.0] o int, predeterminado = 1
Al construir el vocabulario, ignore los términos cuya frecuencia de documento esté estrictamente por debajo del umbral dado. Este valor también se denomina valor de corte en la literatura. Si es un flotante, este parámetro representa la proporción del documento, un número entero absoluto. Si el vocabulario no es ninguno, este parámetro se ignora.
norma: {'l1', 'l2'}, predeterminado = 'l2'
Regularización, 'l2' es el valor cuadrado, 'l1' es el valor absoluto
use_idf : bool, default = True
Habilitar la reponderación inversa de la frecuencia de los documentos
smooth_idf : bool, predeterminado = True
Los pesos de idf se suavizan agregando uno a la frecuencia del documento, como si un documento adicional contuviera cada término de la colección exactamente una vez. Evitar la división por cero
sublinear_tf : bool, default = False
Aplique una escala tf sublineal, es decir, reemplace tf por 1 + log (tf).
ejemplo:
from sklearn.feature_extraction.text import TfidfVectorizer
corpus = [
'This is the first document.',
'This document is the second document.',
'And this is the third one.',
'Is this the first document?'
]
vectorizer = TfidfVectorizer()
x = vectorizer.fit_transform(corpus)
print(vectorizer.get_feature_names)2.2 Algoritmo de clasificación
Aquí, la regresión de cresta en el modelo lineal se usa para la clasificación, y también se pueden usar modelos de algoritmos de clasificación como SVM, LR, XGBoost, etc. Posteriormente, se usará para el recorrido de parámetros con búsqueda de cuadrícula (GridSearchCV).
Análisis comprensivo:
tfidf = TfidfVectorizer(ngram_range=(1,3),max_features=3000)
train_test = tfidf.fit_transform(train_df['text'])
clf = RidgeClassifier()
clf.fit(train_test[:10000],train_df['label'].values[:10000])
val_pred = clf.predict(train_test[10000:])
print(f1_score(train_df['label'].values[10000:],val_pred,average='macro'))El resultado de salida es: 0,8719098297954606
Tarea en este capítulo:
Para ajustar los parámetros, considere usar la búsqueda de cuadrícula para el recorrido de hiperparámetros y recorra el método de procesamiento de texto y el algoritmo de clasificación, respectivamente. Los hiperparámetros son parámetros que no se aprenden directamente en el estimador. Se pasan como parámetros del constructor en la clase del estimador. Se busca en el espacio de hiperparámetros para obtener la mejor "validación cruzada". La búsqueda incluye:
- Estimador (regresor o clasificador)
- Espacio de parámetros
- Métodos de búsqueda o muestreo de candidatos
- Esquema de validación cruzada
- Función de puntuación
El paquete scikit-learn proporciona dos métodos generales para muestrear candidatos de búsqueda. GridSearchCV considera todas las combinaciones de parámetros. RandomizedSearchCV puede extraer un número determinado de candidatos de un espacio de parámetros con una distribución específica. A continuación, se muestra un ejemplo del uso de GridSearchCV:
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import RidgeClassifier
from sklearn.model_selection import GridSearchCV
from sklearn.svm import SVC
from sklearn.metrics import f1_score
from sklearn.pipeline import Pipeline
#遍历TF-IDF的参数
pipeline = Pipeline([
('tfidf', TfidfVectorizer()),
('clf', SGDClassifier()),
])
parameters = {
#'tfidf__max_df': (0.5, 0.75, 1.0),
'tfidf__max_features': (None, 5000, 10000, 50000),
'tfidf__ngram_range': ((1, 1), (1, 2),(1,3)), # unigrams or bigrams
'tfidf__norm': ('l1', 'l2'),
'clf__max_iter': (20,),
'clf__alpha': (0.00001, 0.000001),
'clf__penalty': ('l2', 'elasticnet'),
# 'clf__max_iter': (10, 50, 80),
}
grid_search = GridSearchCV(pipeline, parameters, verbose=1)
print("Performing grid search...")
print("pipeline:", [name for name, _ in pipeline.steps])
print("parameters:")
pprint(parameters)
grid_search.fit(train_df['text'].tolist()[:10000],train_df['label'].values[:10000])
print("Best score: %0.3f" % grid_search.best_score_)
print("Best parameters set:")
best_parameters = grid_search.best_estimator_.get_params()
for param_name in sorted(parameters.keys()):
print("\t%s: %r" % (param_name, best_parameters[param_name]))
Atraviesa el clasificador:
import pandas as pd
import xgboost as xgb
import lightgbm as lgb
import catboost as cat
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import RidgeClassifier
from sklearn.model_selection import GridSearchCV
from sklearn.svm import SVC
from sklearn.metrics import f1_score
from sklearn.pipeline import Pipeline
tfidf = TfidfVectorizer(ngram_range=(1,3),max_features=3000)
train_test = tfidf.fit_transform(train_df['text'])
#定义多个分类函数
classifiers = [('xgb',xgb.XGBClassifier(),{
'max_depth': [5, 10, 15, 20, 25],
'learning_rate': [0.01, 0.02, 0.05, 0.1, 0.15],
'n_estimators': [50, 100, 200, 300, 500],
}),
('lgb',lgb.LGBMClassifier(),{
'max_depth': [5, 10, 15, 20, 25],
'learning_rate': [0.01, 0.02, 0.05, 0.1, 0.15],
'n_estimators': [50, 100, 200, 300, 500],
}),
('cat',cat.CatBoostClassifier(),{
'max_depth': [5, 10, 15, 20, 25],
'learning_rate': [0.01, 0.02, 0.05, 0.1, 0.15],
'n_estimators': [50, 100, 200, 300, 500],
}),
('svc',SVC(),{'kernel': ['rbf'], 'gamma': [1e-3, 1e-4],
'C': [1, 10, 100, 1000]})]
for name,clf,params in classifiers:
grid_search = GridSearchCV(clf,params,n_jobs=1,verbose=1)
grid_search.fit(train_test[:10000],train_df['label'].values[:10000])
Pensando: El resultado de la verificación de mi clasificador TF-IDF + es 0,87, el resultado del envío es 0,1773, el resultado de la verificación con Fasttext es 0,82 y el resultado del envío es 0,833. ¿Cuál es el motivo?