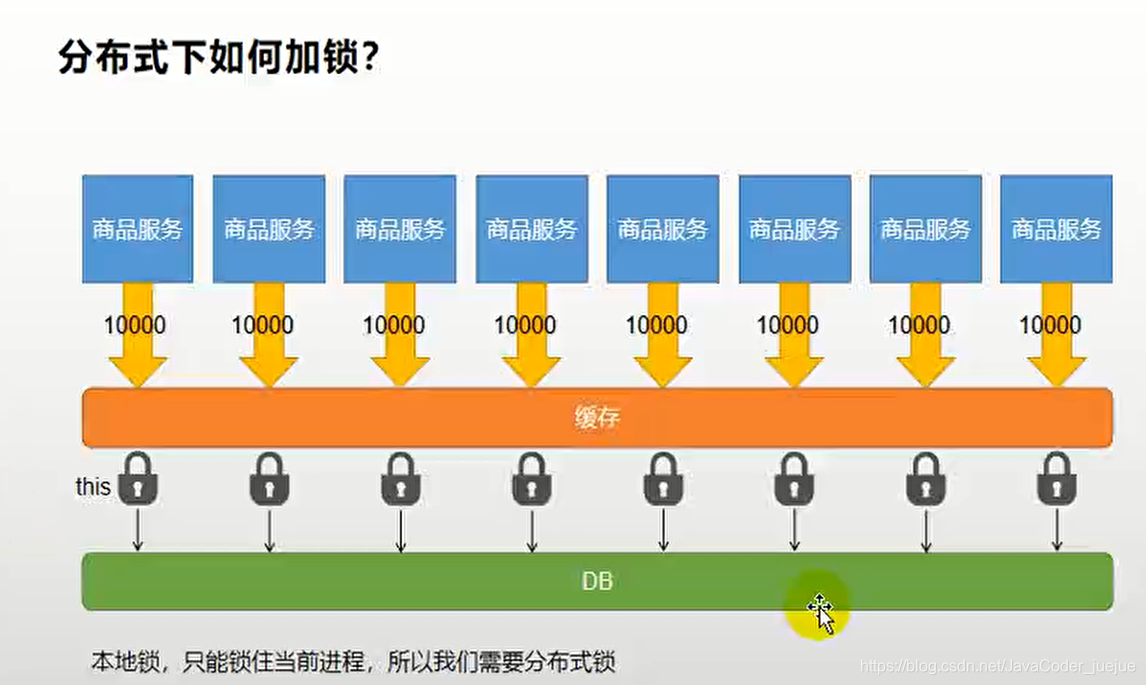
1. Principio
Un principio básico de los bloqueos distribuidos es que cuando varios subprocesos en varios servicios acceden a un recurso, todos van al mismo lugar para ocupar el pozo. Este lugar es el caché, que es compartido por todos los servicios. El primer subproceso para acceder irá a la caché. Configuración intermedia
Una caché de valor clave, debido a que es una operación atómica, la caché falla cuando el subproceso siguiente establece la misma clave, realizando así un bloqueo distribuido
2. Cómo implementar comandos de Linux
Referencia de comando
http://www.redis.cn/commands/set.html

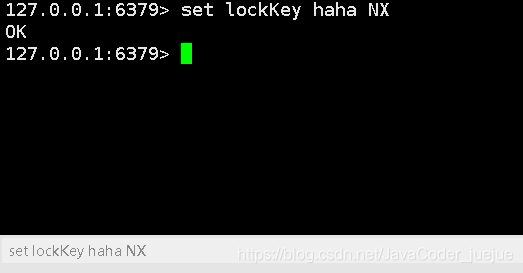
Desde el enlace anterior, podemos ver que cuando se agrega la opción NX a la instrucción establecida, los datos se pueden almacenar en caché solo cuando la clave no existe
(1) Copie cuatro enlaces

(2) Envíe el mismo comando para conectarse al cliente (recuerde cambiar primero los privilegios de root)
(3) Después de conectarse, envíe el comando de caché nuevamente al mismo tiempo
Conexión 1
Las conexiones 2, 3 y 4 son todas las siguientes interfaces, y todas devuelven nil, que es nulo
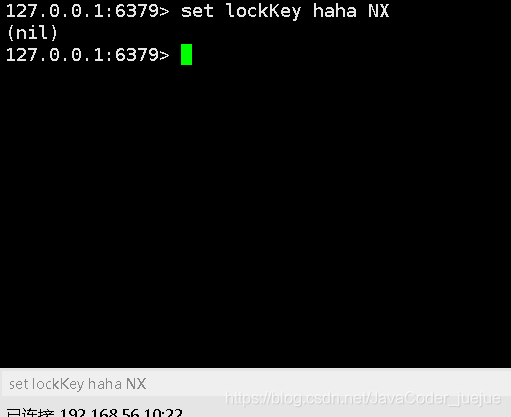
Se puede ver que en el modo de caché NX, cuando el valor de la clave es el mismo, solo la primera caché tendrá éxito, este es el principio básico de los bloqueos distribuidos.

3. Implementación de código y optimización perfecta
La implementación inicial, el código central es el siguiente, cuando accedemos a un hilo (consultamos la base de datos y guardamos los datos en el caché), le agregamos un candado distribuido, es decir, configuramos un caché con clave como candado en modo NX en redis.Cuando acceden otros subprocesos, si falla la configuración de la caché, significa que no se puede obtener el bloqueo distribuido, y girar, es decir, llamar a este método repetidamente para volver a intentarlo, por supuesto, para no intentarlo demasiado. con frecuencia, puede configurar el tiempo de reposo
@Override
public Map<String, List<Catelog2Vo>> getCatalogJson() {
//先从缓存中尝试获取,若为空则从数据库中获取然后放入缓存
String catalogJson;
synchronized (this) {
ValueOperations<String, String> opsForValue = stringRedisTemplate.opsForValue();
catalogJson = opsForValue.get("catalogJson");
System.out.println("从缓存内查询...");
if (StringUtils.isEmpty(catalogJson)) {
Map<String, List<Catelog2Vo>> catalogJsonFromDb = null;
try {
catalogJsonFromDb = getCatalogJsonFromDbWithRedisLock();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("从数据库内查询...");
return catalogJsonFromDb;
}
}
Map<String, List<Catelog2Vo>> catalogJsonFromCache = JSON.parseObject(catalogJson, new TypeReference<Map<String, List<Catelog2Vo>>>() {
});
return catalogJsonFromCache;
}
public Map<String, List<Catelog2Vo>> getCatalogJsonFromDbWithRedisLock() throws InterruptedException {
Boolean lock = stringRedisTemplate.opsForValue().setIfAbsent("lock", "111");
if(lock){
Map<String, List<Catelog2Vo>> dataFromDb = getDataFromDb();
//删除锁
stringRedisTemplate.delete("lock");
return dataFromDb;
}else{
Thread.sleep(100);
return getCatalogJsonFromDbWithRedisLock();
}
}Analice los problemas en las implementaciones anteriores Antes de eliminar el bloqueo, una anomalía, un corte de energía o un tiempo de inactividad provocarán un punto muerto.
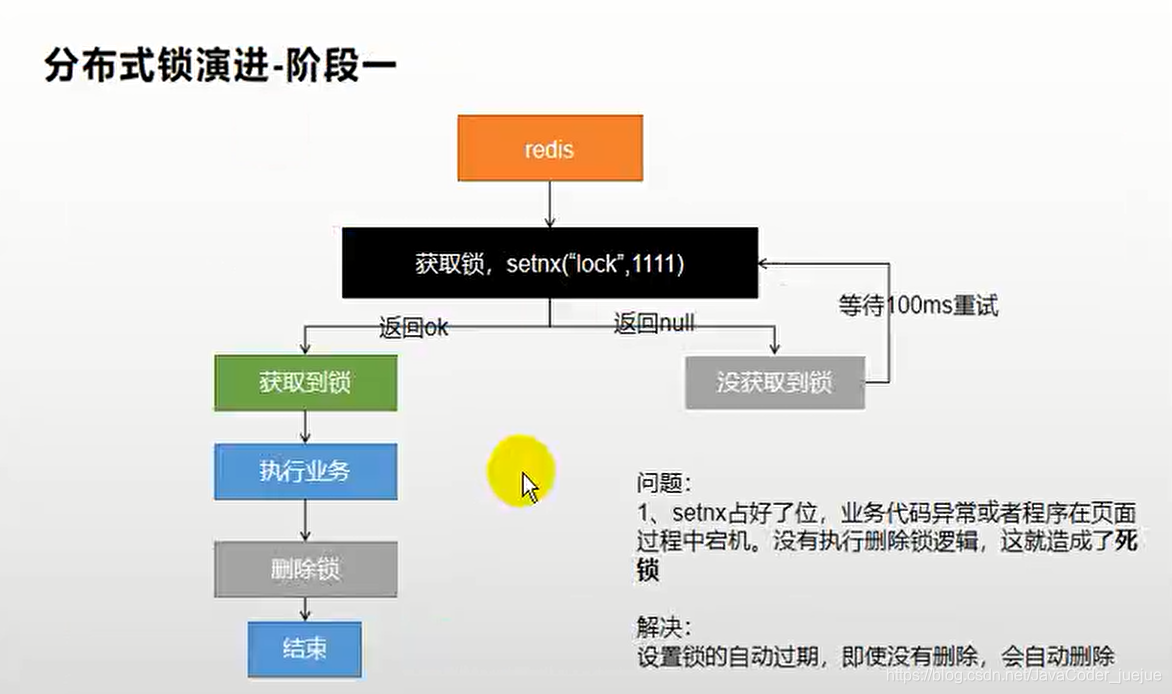
, Por lo que establecemos un tiempo de vencimiento para la llave (bloqueo)
Esta vez, debido a que lo configuramos por separado, si se corta la energía antes de que se establezca el tiempo de vencimiento después de que se adquiere el bloqueo, también causará un interbloqueo.
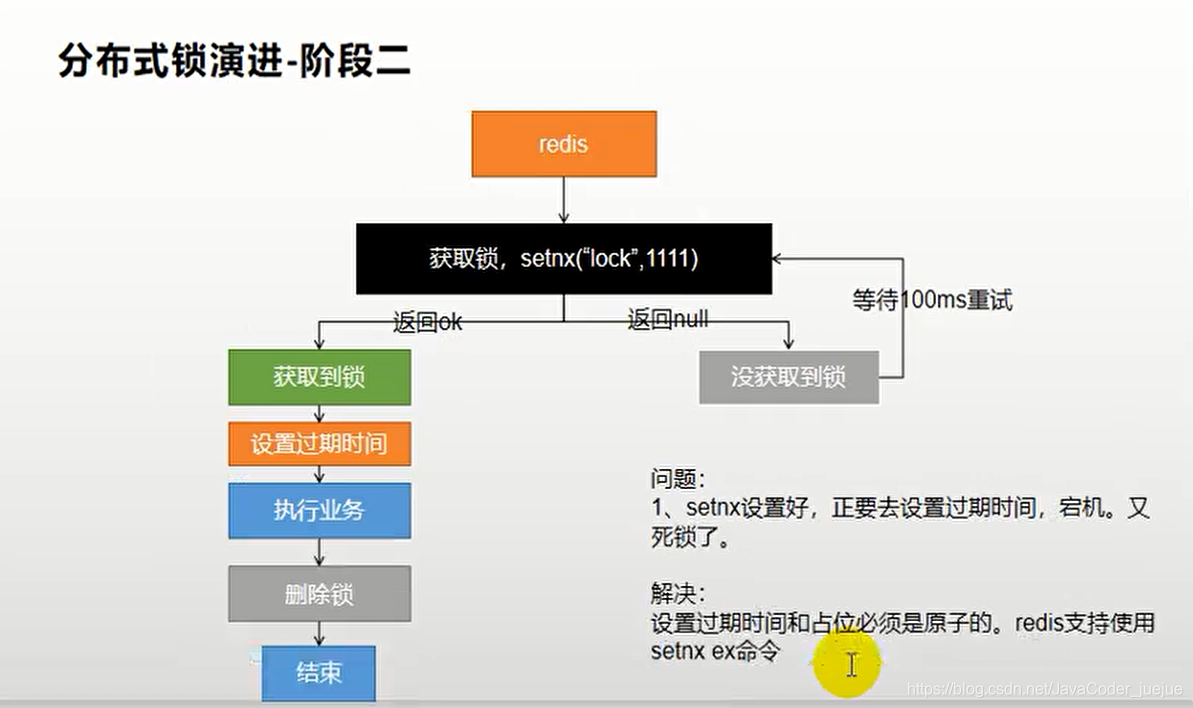
Solución: el tiempo de caducidad de la caché y los datos almacenados en caché deben configurarse de forma atómica, y redis lo admite, así que cámbielo al siguiente código
Boolean lock = stringRedisTemplate.opsForValue().setIfAbsent("lock", "111",30,TimeUnit.SECONDS);
Pero todavía hay un problema. Cuando consultamos la base de datos y la agregamos a la caché o procesamos la lógica empresarial durante demasiado tiempo, excede el tiempo de vencimiento que establecimos. En este momento, si el bloqueo se elimina después de que se ejecuta la lógica, será eliminado por otros hilos.
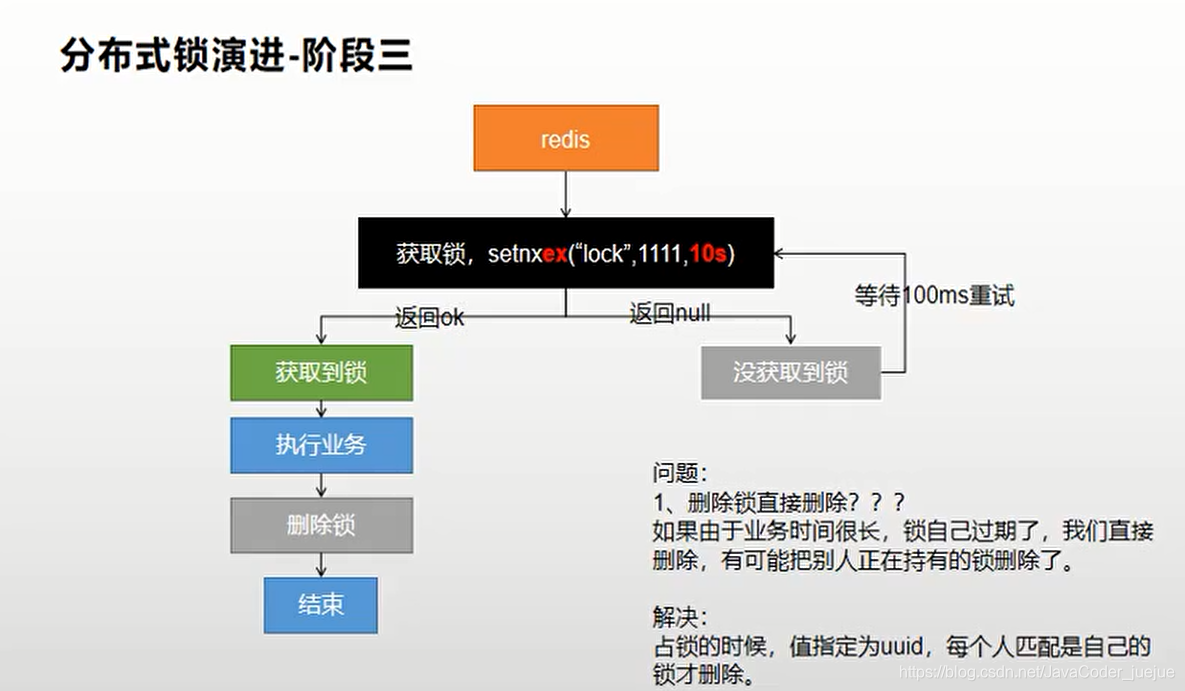
Código principal, el valor se establece en uuid para facilitar la identificación del bloqueo de hilo actual al eliminar
public Map<String, List<Catelog2Vo>> getCatalogJsonFromDbWithRedisLock() throws InterruptedException {
Boolean lock = stringRedisTemplate.opsForValue().setIfAbsent("lock", "111",30,TimeUnit.SECONDS);
String uuid = UUID.randomUUID().toString();
if(lock){
Map<String, List<Catelog2Vo>> dataFromDb = getDataFromDb();
//删除锁 如果是当前线程的才删除 不然可能删的是线程的锁
String value = stringRedisTemplate.opsForValue().get("lock");
if(uuid.equals(value)){
stringRedisTemplate.delete("lock");
}
return dataFromDb;
}else{
Thread.sleep(100);
return getCatalogJsonFromDbWithRedisLock();
}
}Sin embargo, todavía hay un problema. Dado que la comparación entre obtener valor y borrar caché no es una operación atómica, si hay un corte de energía después de obtener el valor y antes de borrar el caché, también hará que se elimine el bloqueo de otros. , lo que equivale a no estar bloqueado.
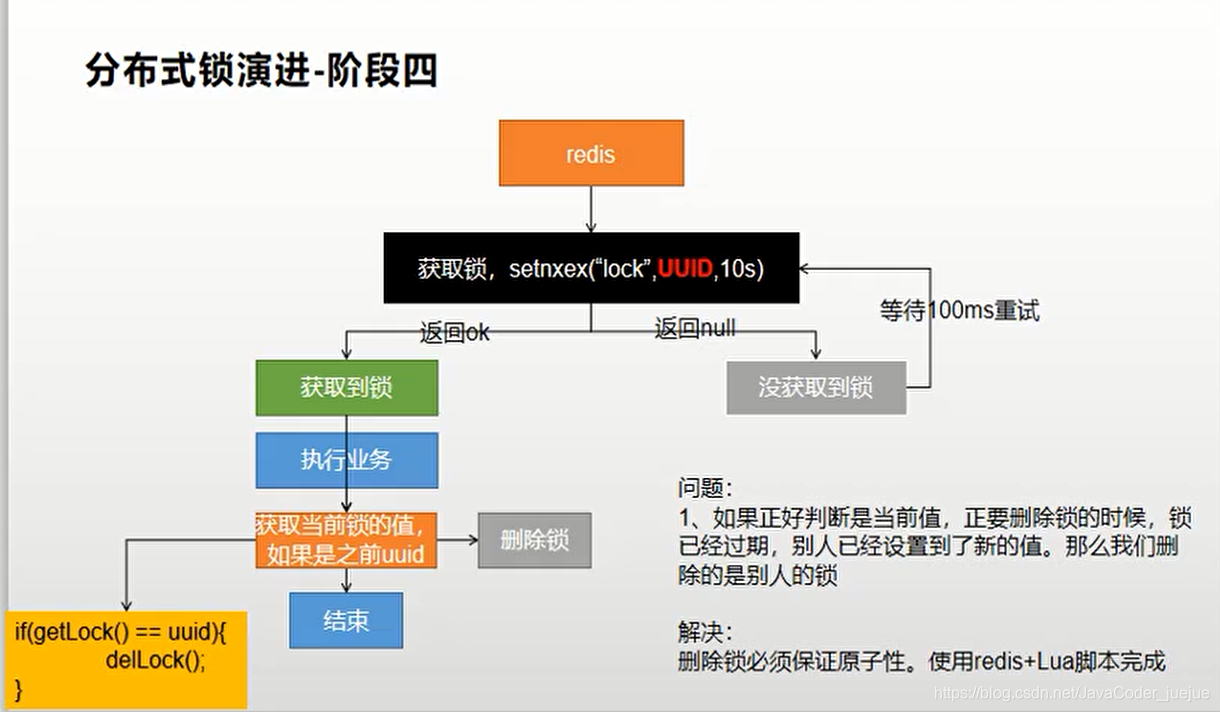
Entonces, el código se modifica nuevamente, utilizando el método de bloqueo de eliminación de script proporcionado por redis para garantizar la atomicidad
public Map<String, List<Catelog2Vo>> getCatalogJsonFromDbWithRedisLock() throws InterruptedException {
Boolean lock = stringRedisTemplate.opsForValue().setIfAbsent("lock", "111",300,TimeUnit.SECONDS);
String uuid = UUID.randomUUID().toString();
if(lock){
Map<String, List<Catelog2Vo>> dataFromDb;
try {
dataFromDb = getDataFromDb();
}finally {
String script = "if redis.call(\"get\",KEYS[1]) == ARGV[1]\n" +
"then\n" +
" return redis.call(\"del\",KEYS[1])\n" +
"else\n" +
" return 0\n" +
"end";
//保证获取value对比与删除缓存是原子操作,这里采用redis提供的执行脚本方式
Long lock1 = stringRedisTemplate.execute(new DefaultRedisScript<Long>(), Arrays.asList("lock"), uuid);
}
return dataFromDb;
}else{
Thread.sleep(200);
return getCatalogJsonFromDbWithRedisLock();
}
}En este momento ha evolucionado a la forma final de la etapa cinco.
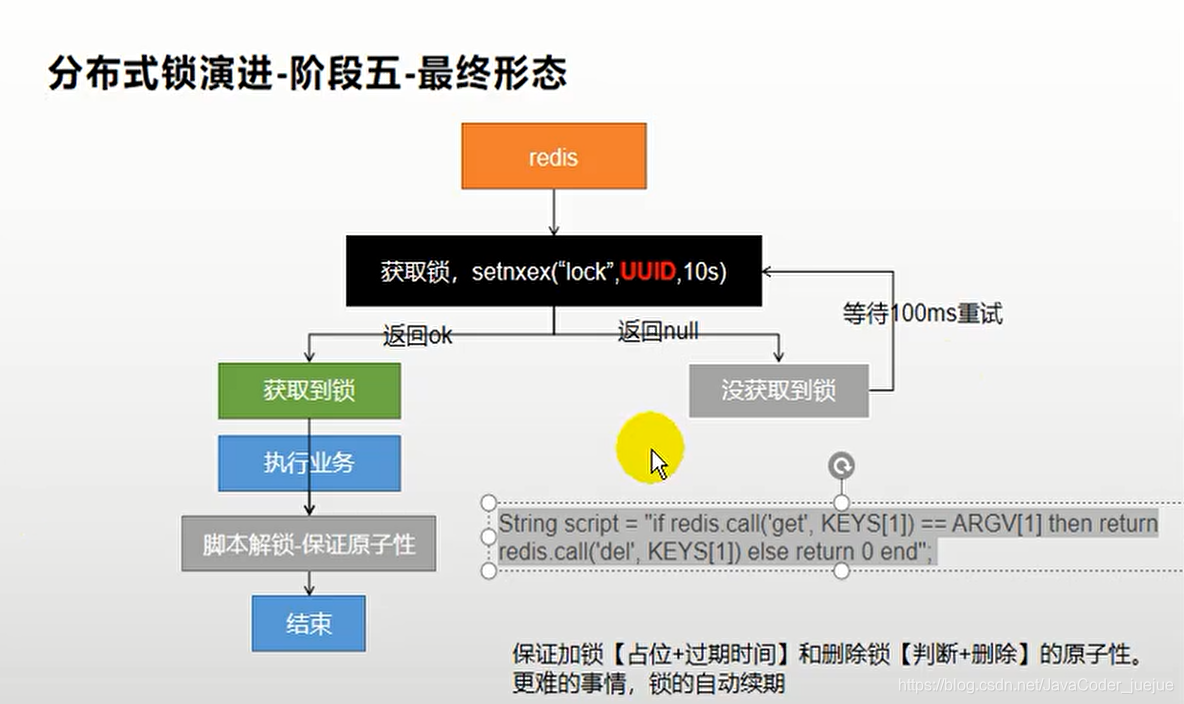
Hasta ahora, el bloqueo distribuido se ha implementado y mejorado básicamente. No haré aquí la prueba de esfuerzo. Se espera que el resultado sea exitoso.
Debido a la repetitividad del código, se puede encapsular. Por supuesto, otros ya lo han hecho. Más adelante, aprenderemos sobre el framework más profesional de las cerraduras distribuidas-Redisson
Principales enlaces de referencia para este artículo:
http://www.redis.cn/commands/set.html