Debido a problemas de derechos de autor, el sitio web no se indica temporalmente.
Normalmente use xpath para gatear, sin medidas anti-escalada
El rastreo utiliza una barra de progreso. Explique el uso de la barra de progreso y los problemas encontrados al rastrear:
-
\ r significa mover el cursor hacia atrás al principio de la línea
\ b significa mover el cursor hacia atrás un lugar -
print ("\ r", end = "") end = "" significa que la siguiente impresión no se ajustará, y porque \ r significa que la posición del cursor volverá al principio de la línea, por lo que significa que la impresión anterior se sobrescribirá Drop
-
"/" Significa división de números de punto flotante y devuelve un resultado de punto flotante; "//" significa división de números enteros.
-
Aparecen caracteres ilegibles cuando xpath obtiene un texto de etiqueta: use .encode ('ISO-8859-1'). Decode ("gbk") para el texto
-
Cómo actualizar el búfer:
flush () Actualiza el área del búfer. Cuando el
búfer esté lleno, se actualizará automáticamente cuando el
archivo se cierre o cuando el programa finalice.import time import sys for i in range(5): print(i,end='') # sys.stdout.flush() time.sleep(0.001) #注释打开和关闭效果不同Cuando imprimimos algunos caracteres, no se imprimen inmediatamente después de llamar a la función de impresión. Generalmente, los caracteres se envían primero al búfer y luego se imprimen. Hay un problema: si desea imprimir algunos caracteres a intervalos iguales, pero debido a que el búfer no está lleno, no se imprimirán. Necesitas tomar algunas medidas. Por ejemplo, el búfer se actualiza a la fuerza después de cada impresión.
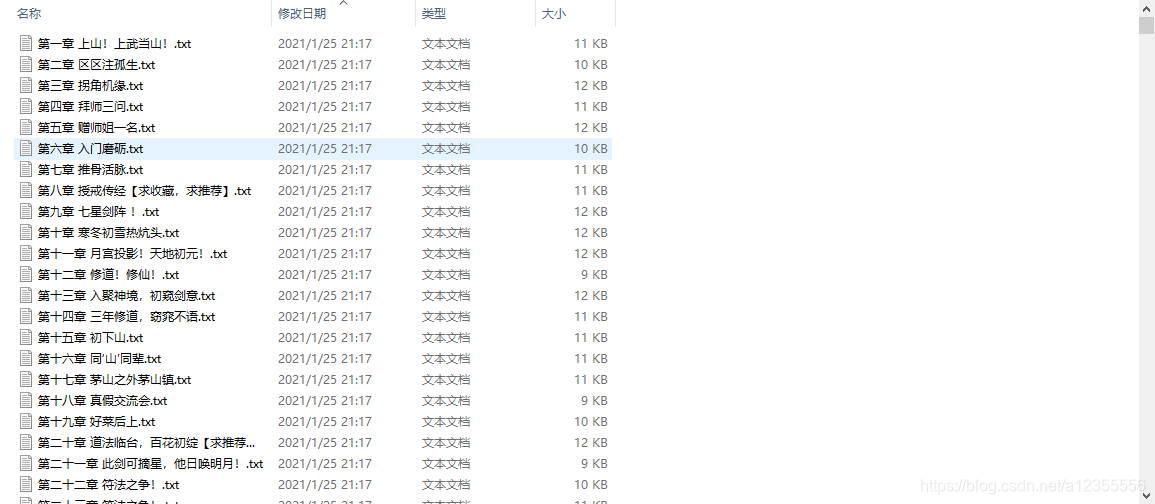
Resultados de rastreo:

Código
import requests
from lxml import etree
import re,os,time,sys
m=0
k=0
#解析小说正文页面
def parse_page(url):
r = requests.get(url).text
html = etree.HTML(r)
title = html.xpath('//div[@class="content"]/h1/text()')[0]
text = html.xpath('//div[@id="content"]/text()')
if len(text)==0:
pass
new_text = []
for te in text[:-4]:
new_text.append(te)
err = ['?', '?','\"', '“','|',':','(','*','(']
#判断小说章节名是否合法
if len([True for er in err if er in title])!=0:
y = re.findall('[((\??"“”|:/\*].*',title)[0]
new_title = title.replace(y,'')
save(new_title,new_text)
else:
save(title,new_text)
#使用进度条
def down_progress(len_url):
global m
global k
if k!=0 and m<=99 and k%(int)(len_url/100)==0:
m=m+1
print("\r", end="")
print("Download progress: {}%: ".format(m), "▋" * (m // 2), end="")
sys.stdout.flush()
k+=1
#获取小说的所有正文Url
def get_url(url):
global novel_name
global len_url
r = requests.get(url).text
html = etree.HTML(r)
novel_name = html.xpath('//div[@class="info"]/h2/text()')[0].encode('ISO-8859-1').decode("gbk")
if not os.path.exists(novel_name):
os.mkdir(novel_name)
dd = html.xpath('//div[@class="listmain"]/dl//dd')
len_url = len(dd)-12
print("下载的小说名为:"+novel_name)
print("共需要下载{}章".format(len_url))
print("保存地址为:"+os.getcwd()+"\\"+ novel_name)
print("下载大概需"+str('%.2f'%(len_url*1.1/60))+"分钟")
print("*"*30+'下载开始'+"*"*30)
for d in dd[12:]:
#使用进度条
down_progress(len_url)
url = "https://www.bqkan.com/" + d.xpath('./a/@href')[0]
parse_page(url)
time.sleep(0.05)
#将小说正文写入文本文件中
def save(title,text):
f = open(novel_name+"/"+title+'.txt','a',encoding='utf-8')
for te in text:
f.write(te)
f.write('\n')
def main():
url = input("请输入小说目录下载地址:")
get_url(url)
if __name__ == '__main__':
start = time.time()
main()
end = time.time()
print()
print("*"*30+'下载已完成'+"*"*30)
print("下载耗费时间:{}分钟".format(str('%.2f'%((end-start)/60))))