Computación en la nube Wang Xigang 360
Declaración de heroína
Kubernetes Serivce es una abstracción con la misma etiqueta Colección de Pod (puede entenderse simplemente como el LB en el clúster). Los servicios dentro y fuera del clúster pueden comunicarse entre sí a través del Servicio. Sin embargo, hay muchos tipos de Servicio. En qué tipo de escenario es adecuado cada tipo de Servicio y cómo kube-proxy implementa el equilibrio de carga del Servicio será el tema central de este artículo.
PD: tecnología de primera línea rica, una amplia gama de formas, todo en " 3 60 cloud computing " punto de preocupación ¡Oh!
1
El principio de funcionamiento de Service y kube-proxy en kubernetes cluster
Antes de presentar Service y kube-proxy, hablemos de su función en un clúster de Kubernetes.
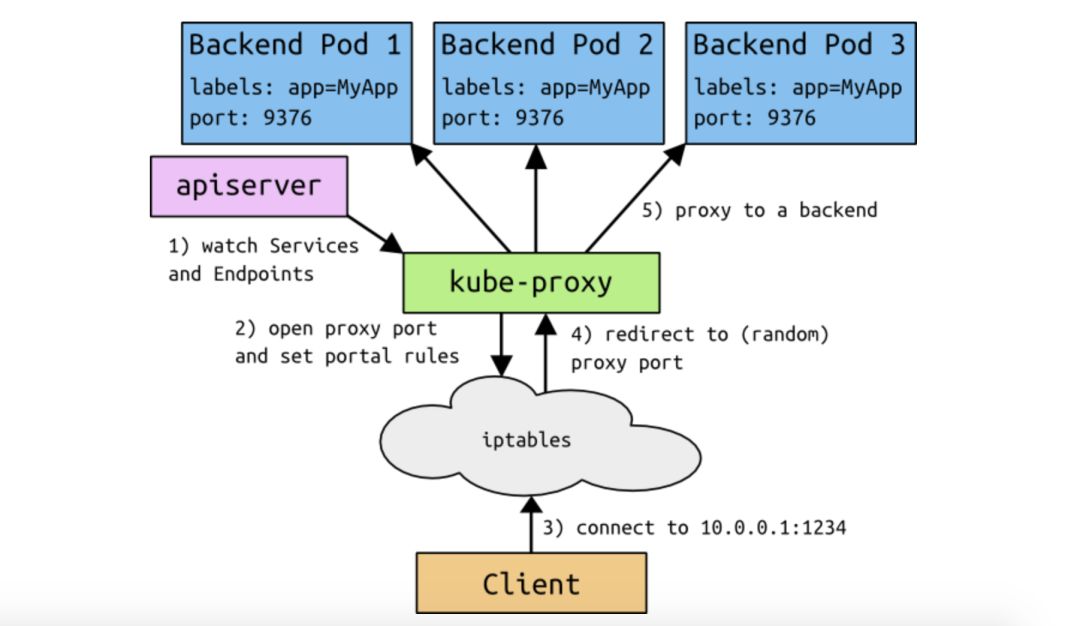
Analicemos la imagen de arriba:
1. El proxy de kube que se ejecuta en cada nodo de nodo observará los objetos de servicios y puntos finales en tiempo real.
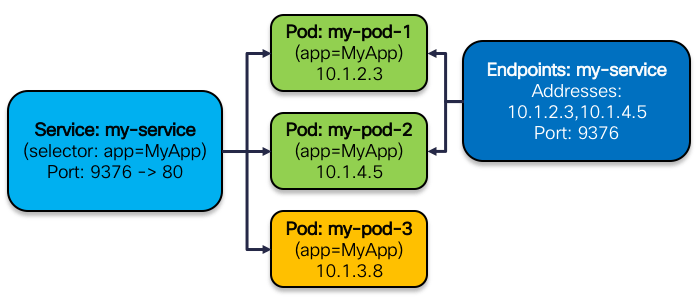
Cuando el usuario crea un servicio con una etiqueta en el clúster de kubernetes, se creará un objeto Endpoints con el mismo nombre en el clúster al mismo tiempo para almacenar la IP del pod en el servicio. Su relación se muestra en la siguiente figura:
2. Después de que cada kube-proxy que se ejecuta en el nodo Node perciba los cambios en los Servicios y los Endpoints, establecerá las iptables o reglas IPVS relevantes en el nodo Node respectivo para que los usuarios posteriores accedan a los servicios del Servicio a través de la ClusterIP del Servicio. .
3. Una vez que kube-proxy ha establecido las reglas requeridas, los usuarios pueden enrutar y reenviar las reglas establecidas por iptables o IPVS a través de ClusterIP en el nodo o pod cliente en el clúster, y finalmente enviar la solicitud del cliente al real.
Hablaré sobre cómo kube-proxy configura las políticas de Iptables e IPVS más adelante. A continuación, presentemos primero los escenarios de uso de cada tipo diferente de servicio.
2
Tipo de servicio
El servicio de Kubernetes actual admite los siguientes tipos y, al presentar los tipos, puede comprender los escenarios de uso específicos de cada tipo de servicio.
ClusterIP
El servicio del tipo ClusterIP es el servicio predeterminado del clúster de Kubernetes, que solo se puede usar para la comunicación dentro del clúster. No se puede utilizar para comunicaciones externas.
La estructura del tipo de servicio ClusterIP se muestra en la siguiente figura:

NodePort
Si desea acceder a servicios dentro del clúster fuera del clúster, puede utilizar este tipo de servicio. Un servicio del tipo NodePort abrirá un puerto específico en todos los nodos Node del clúster. Una vez que todo el tráfico se envía directamente a este puerto, el Servicio reenviado accederá al servicio real.
La estructura del tipo de servicio NodePort se muestra en la siguiente figura:

LoadBalancer
El tipo de servicio LoadBalancer generalmente se usa en combinación con el LB del proveedor de la nube para exponer los servicios dentro del clúster a la red externa. El LoadBalancer del proveedor de la nube asignará una IP al usuario y luego el tráfico a través de la IP será reenviado a su Servicio.
La estructura del tipo de servicio LoadBalancer se muestra en la siguiente figura:
Ingreso
Ingress no es en realidad un tipo de Servicio, pero puede actuar en múltiples Servicios y servir como entrada a los servicios internos del clúster.
Ingress puede hacer muchas cosas diferentes, como reenviar solicitudes a diferentes servicios en función de diferentes rutas.
La estructura de Ingress se muestra en la siguiente figura:
3
Descubrimiento de servicios
Actualmente, el servicio admite dos tipos de mecanismos de descubrimiento de servicios, uno a través de variables de entorno y el otro a través de DNS. En estos dos escenarios, se recomienda el último.
Variable ambiental
Cuando se crea un pod, kubelet registrará todas las variables de entorno relacionadas con el servicio que el clúster ha creado en el pod, pero debe tenerse en cuenta que todos los POD antes de la creación del servicio no registrarán las variables de entorno del servicio. Por lo tanto, en el uso normal, se recomienda realizar el descubrimiento de servicios entre servicios a través de DNS.
DNS
El servicio CoreDNS se puede implementar en el clúster (la versión anterior del clúster de kubernetes usa kubeDNS), de modo que el Pod dentro del clúster se comunique entre varios servicios dentro del clúster a través de DNS.
El clúster de Kubernetes actual usa CoreDNS como el servicio DNS predeterminado de forma predeterminada. La razón principal es que CoreDNS es simple y flexible para la extensión basada en Plugin. Y no está completamente vinculado a Kubernetes.
4
Equilibrio de carga de servicio
Al comienzo de este artículo, presenté cómo el servicio y el proxy kube cooperan en un clúster para lograr el equilibrio de carga del servicio. kube-proxy juega un papel clave en él.Como controlador, kube-proxy actúa como un centro para la interacción entre k8s y el kernel Netfilter de Linux. Supervise los cambios de los objetos de Endpoints y Servicios de clúster de kubernetes, y establezca diferentes reglas para el kernel según los diferentes modos de kube-proxy (iptables o ipvs) para implementar el enrutamiento y el reenvío. A continuación, presentaremos el mecanismo de trabajo de kube-proxy basado en los dos modos de Iptables e IPVS para lograr el equilibrio de carga del Servicio.
Iptables para balanceo de carga
Iptables es un programa en modo de usuario que crea un firewall del kernel de Linux configurando las reglas de Netfilter. Netfilter es el marco de gestión de paquetes de red del kernel de Linux. Proporciona un conjunto completo de mecanismos de gestión de funciones de enlace, lo que hace posible el filtrado de paquetes, la traducción de direcciones de red (NAT) y el seguimiento de conexiones según los tipos de protocolo. La posición de Netfilter en el kernel como se muestra a continuación.

A continuación, presentaré cómo kube-proxy usa Iptables para el equilibrio de carga. El proceso de coincidencia de paquetes de datos en Iptables se muestra en la siguiente figura:

En el modo Iptables, kube-proxy crea una serie de cadenas personalizadas en las cadenas PREROUTIN y POSTROUTING de la tabla NAT en las Iptables en el nodo de destino (estas cadenas personalizadas son principalmente cadenas "KUBE-SERVICE", cadena "KUBE-POSTROUTING", la cadena "KUBE-SVC-XXXXXX" y la cadena "KUBE-SEP-XXXX" correspondiente a cada servicio), y luego realizar operaciones DNAT y SNAT en los paquetes de datos que fluyen al Nodo a través de estas cadenas personalizadas para lograr enrutamiento, balanceo de carga y conversión de dirección, como se muestra en la siguiente figura:

En kube-proxy, el proceso de coincidencia específico del paquete de solicitud del cliente en la regla Iptables es:
1. Cadena PREROUTING o cadena OUTPUT (el Pod en el clúster pasa a través de la cadena OUTPUT cuando accede al Servicio a través de clusterIP, y cuando el host fuera del clúster accede al Servicio a través del método NodePort, a través de la cadena PREROUTING, ambas cadenas saltarán al Cadena KUBE-SERVICE)

2. Cadena KUBE-SERVICES (cada puerto expuesto por cada Servicio corresponderá a una regla correspondiente en la cadena KUBE-SERVICES. Cuando el número de servicios alcance una determinada escala, los datos de las reglas en la cadena KUBE-SERVICES serán muy Es grande e Iptables es una búsqueda lineal al buscar y comparar, lo que llevará mucho tiempo, y la complejidad del tiempo es O (n))
3. La cadena KUBE-SVC-XXXXX (en la cadena KUBE-SVC-XXXXX (la siguiente serie de valores hash son generados por la IP virtual del Servicio), coincidirá con una de las siguientes reglas con cierta probabilidad ejecutar, a través del módulo de estadísticas para cada El back-end establece el peso para lograr el propósito de balanceo de carga. Cada cadena KUBE-SEP-XXXXX representa un Pod específico detrás del Servicio (el valor hash detrás es generado por la IP real de el Pod de back-end), logrando así el propósito de equilibrio de carga)
4. Cadena KUBE-SEP-XXXX (a través de DNAT, modificar la IP de destino del paquete de datos a la IP del Pod del servidor)  5.Cadena de POSTROUTING
5.Cadena de POSTROUTING

6.cadena KUBE_POSTROUTING (hacer SNAT para paquetes marcados)
A través de la configuración anterior, se realiza el equilibrio de carga basado en Iptables. Sin embargo, Iptbles tiene algunos problemas con el equilibrio de carga:
Retardo de coincidencia lineal de reglas: La
cadena KUBE-SERVICES cuelga de una larga cadena KUBE-SVC- *. Para acceder a cada servicio, es necesario atravesar cada cadena hasta que coincida. La complejidad del tiempo es O (N)Retraso de actualización de reglas:
no incremental, primero debe copiar el estado de Iptables mediante iptables-save, luego actualizar algunas reglas y finalmente escribir en el kernel a través de iptables-restore. Cuando el número de reglas alcanza un cierto nivel, el proceso se vuelve muy lento.Escalabilidad:
cuando hay una gran cantidad de cadenas de reglas Iptables en el sistema, el bloqueo del kernel aparecerá al agregar / eliminar reglas, y solo puede esperar.Disponibilidad: cuando el servicio se expande / reduce, la actualización de las reglas de Iptables hará que la conexión se desconecte y el servicio no esté disponible.
Para resolver estos problemas que existen actualmente en Iptables, los estudiantes del equipo de código abierto de Huawei aportaron el modelo IPVS a la comunidad A continuación, presentaré cómo IPVS logra el equilibrio de carga.
IPVS logra el equilibrio de carga
IPVS es parte del proyecto LVS, es un balanceador de carga de 4 capas que se ejecuta en el kernel de Linux con un rendimiento excepcional. Usando el kernel ajustado, puede manejar fácilmente más de 100,000 solicitudes de reenvío por segundo.
IPVS tiene las siguientes características:
Implementación de Load Balancer y LVS Load Balancer en la capa de transporte.
También se basa en Netfilter como Iptables, pero usa tablas hash.
Admite protocolo TCP, UDP, SCTP, admite IPV4, IPV6.
Admite múltiples estrategias de equilibrio de carga:
rr: round-robin
lc: conexión mínima
dh: hash de destino
sh: hash de origen
sed: retraso esperado más corto
nq: nunca hacer cola
Retención de sesiones de soporte
El principio de funcionamiento de LVS se muestra en la siguiente figura:

1. Cuando la solicitud del cliente llega al espacio del kernel del balanceador de carga, primero llegará a la cadena PREROUTING.
2. Cuando el núcleo encuentra que la dirección de destino del paquete de datos solicitado es la máquina local, envía el paquete de datos a la cadena INPUT.
3. Cuando el paquete de datos llega a la cadena de ENTRADA, IPVS lo verificará primero Si la dirección de destino y el puerto en el paquete de datos no están en las reglas de IPVS, el paquete de datos se liberará al espacio del usuario.
4. Si la dirección de destino y el puerto en el paquete de datos están en las reglas de IPVS, entonces la dirección de destino de este paquete de datos se modificará al servidor back-end (DNAT) seleccionado por el algoritmo de equilibrio y enviado a la cadena POSROUTING.
5. Finalmente, se envía al servidor back-end a través de la cadena POSTROUTING.
LVS tiene principalmente tres modos de trabajo, a saber, NAT, DR y modo Túnel. En kube-proxy, IPVS funciona en modo NAT, por lo que lo siguiente presenta principalmente el modo NAT:
O analiza la imagen de arriba:
1. El cliente envía la solicitud al balanceador de carga de front-end, la dirección de origen del mensaje de solicitud es CIP (IP del cliente) y la dirección de destino es VIP (dirección de front-end del balanceador de carga)
2. Después de recibir el mensaje, el equilibrador de carga encuentra que la solicitud es una dirección que existe en la regla, luego cambia la dirección de destino del mensaje solicitado a la dirección RIP del servidor backend y equilibra el mensaje de acuerdo con la respuesta. . Estrategia enviada
3. Después de que el mensaje se envía a Real Server, dado que la dirección de destino del mensaje es ella misma, todos responderán a la solicitud y devolverán el mensaje de respuesta a LVS.
4. Luego, LVS cambia la dirección de origen de este mensaje a la dirección IP de la máquina y la envía al cliente.
Después de presentar el principio de funcionamiento básico, echemos un vistazo a cómo utilizar el modo IPVS para el equilibrio de carga en kube-proxy. Primero, debe especificar los siguientes parámetros en los parámetros para iniciar kube-proxy:
--proxy-mode = ipvs // Establecer el modo de kube-proxy en IPVS - ipvs-planificador = rr // Establecer el algoritmo de equilibrio de carga de ipvs, el valor predeterminado es rr - ipvs-min-sync-period = 5s // El intervalo de tiempo mínimo para actualizar las reglas de IPVS - ipvs-sync-period = 30s // El intervalo de tiempo máximo para actualizar las reglas de IPVS
Después de configurar estos parámetros, reinicie el servicio kube-proxy. Al crear un Servicio de tipo ClusterIP, kube-proxy en modo IPVS hará lo siguiente:
Cree una tarjeta de red virtual, la predeterminada es kube-ipvs0
Vincular la dirección IP del servicio a la tarjeta de red virtual kube-ipvs0

Cree un servidor virtual IPVS para cada dirección IP de servicio

Al mismo tiempo, IPVS también admite la función de retención de sesión. Al especificar el parámetro service.spec.sessionAffinity como ClusterIP, el valor predeterminado es None y el parámetro service.spec.sessionAffinityConfig.clientIP.timeoutSeconds como el tiempo requerido al crear el objeto Srevice , el valor predeterminado es 10800s.
El siguiente es un ejemplo específico de cómo crear un Servicio y especificar la retención de la sesión:
kind: ServiceapiVersion: v1metadata: name: nginx-servicespec: type: ClusterIP selector: app: nginx sessionAffinity: ClientIP sessionAffinityConfig: clientIP: timeoutSeconds: 50 puertos: -nombre: protocolo http: puerto TCP: 80 targetPort: 80
Luego, puede usar ipvsadm -L para verificar si la función de persistencia de la sesión está configurada correctamente. De esta manera, kube-proxy puede lograr el equilibrio de carga a través del modo IPVS.
5
para resumir
Kube-proxy está utilizando iptables e ipvs para lograr el equilibrio de carga del Servicio, pero a través de la implementación de iptables, debido a las características de Iptables en sí, se agregan las nuevas reglas y las reglas de actualización no son incrementales. -Guardar primero y luego actualizar en la memoria Reglas, modificar las reglas en el kernel, en iptables-restore, e Iptables es una búsqueda lineal durante la búsqueda y coincidencia de reglas, que llevará mucho tiempo y la complejidad del tiempo es O (n). Con la implementación de IPVS, la complejidad temporal del proceso de conexión es O (1). Básicamente, la eficiencia de la conexión no tiene nada que ver con la cantidad de servicios de clúster. Por lo tanto, con el aumento continuo de servicios dentro del clúster, se reflejan las ventajas de rendimiento de IPVS.
Artículos relacionados
https://zhuanlan.zhihu.com/p/37230013
https://zhuanlan.zhihu.com/p/39909011
https://www.projectcalico.org/comparing-kube-proxy-modes-iptables-or-ipvs/
https://medium.com/google-cloud/kubernetes-nodeport-vs-loadbalancer-vs-ingress-when-should-i-use-what-922f010849e0
https://wiki.archlinux.org/index.php/Iptables_(%E7%AE%80%E4%BD%93%E4%B8%AD%E6%96%87)
https://kubernetes.io/docs/concepts/services-networking/service/
http://blog.chinaunix.net/uid-23069658-id-3160506.html
https://tonydeng.github.io/sdn-handbook/linux/loadbalance.html
https://www.josedomingo.org/pledin/2018/11/recursos-de-kubernetes-services/