Programación de Kubernetes
1. El programador utiliza el mecanismo de observación de kubernetes para descubrir los pods recién creados en el clúster que no se han programado en el nodo. El programador programará cada Pod no programado encontrado en un Nodo apropiado para que se ejecute.
2. kube-Scheduler es el planificador predeterminado del clúster de Kubernetes y forma parte del plano de control del clúster. Si realmente desea o tiene necesidades en este sentido, kube-Scheduler está diseñado para permitirle escribir un componente de programación usted mismo y reemplazar el kube-Scheduler original
. Los factores que deben considerarse al tomar decisiones de programación incluyen: Recursos individuales y generales solicitudes, hardware / software / restricciones de políticas, requisitos de afinidad y antiafinidad, localidad de datos, interferencia entre cargas, etc.
La estrategia predeterminada puede referirse al
marco de programación
(1) Selección de nodo
1.nodeName es el método más simple para las restricciones de selección de nodos
(1) Pero generalmente no se recomienda. Si nodeName se especifica en PodSpec, tiene prioridad sobre otros métodos de selección de nodos.
(2) Algunas restricciones sobre el uso de nodeName para seleccionar nodos:
si el nodo especificado no existe.
Si el nodo especificado no tiene los recursos para acomodar el pod, la programación del pod falla.
Los nombres de los nodos en un entorno de nube no siempre son predecibles o estables.
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx
image: myapp:v1
nodeName: server3

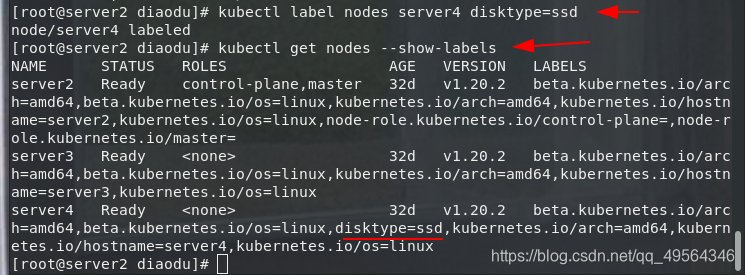
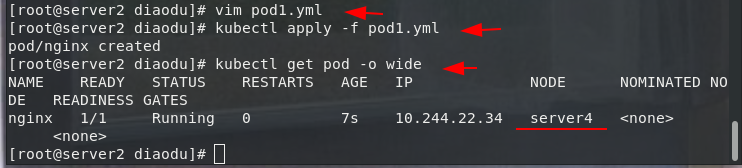
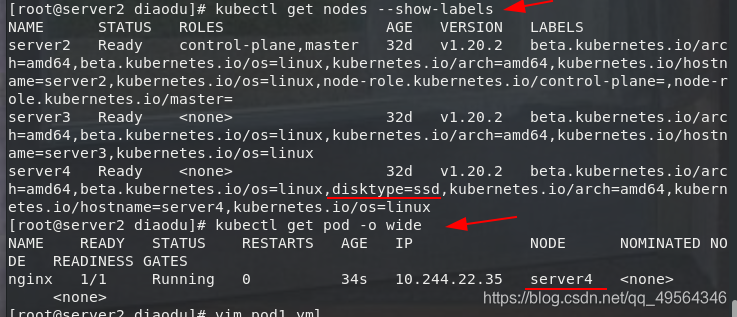
2. nodeSelector es la forma recomendada más simple de restricción de selección de nodos
En las mismas condiciones, en qué nodo está programado el pod por primera vez, la próxima vez que se ejecute también se programará primero.
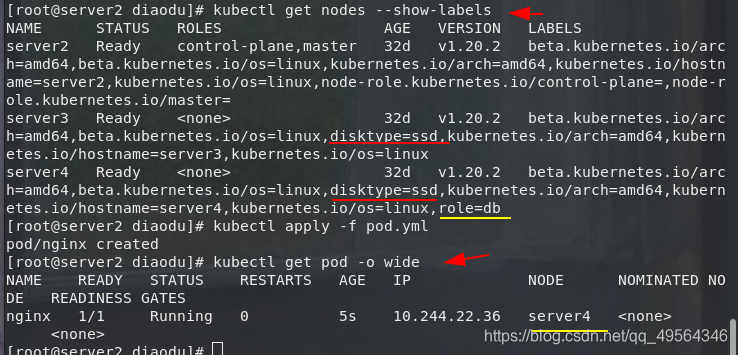
kubectl label nodes server4 disktype=ssd #给节点打标签
kubectl get nodes --show-labels
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx
image: myapp:v1
imagePullPolicy: IfNotPresent
nodeSelector: #标签选择
disktype: ssd
(2) Afinidad y antiafinidad
nodeSelector proporciona una forma muy sencilla de restringir pods a nodos con etiquetas específicas. La función de afinidad / antiafinidad amplía en gran medida los tipos de restricciones que puede expresar.
Puede encontrar que las reglas son "suaves" / "preferencias" en lugar de requisitos estrictos. Por lo tanto, si el programador no puede cumplir con los requisitos, aún
puede programar el pod. Puede usar la etiqueta del pod en el nodo para restringir en lugar de usar el nodo en sí. Etiquetas para permitir qué pods se pueden colocar juntos o no
1. Afinidad de nodo
(1) requiredDuringSchedulingIgnoredDuringExecution debe satisfacerse
(2) preferidoDuringSchedulingIgnoredDuringExecution tiende a satisfacerse
(3) IgnoreDuringExecution significa que si la etiqueta del Nodo cambia durante la operación del Pod, la estrategia de afinidad no se puede satisfacer, luego continúe ejecutando la referencia del Pod actual
(1)必须满足
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx
image: myapp:v1
imagePullPolicy: IfNotPresent
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution: #必须满足
nodeSelectorTerms:
- matchExpressions:
- key: disktype
operator: In
values:
- ssd
(2)倾向满足
metadata:
name: nginx
spec:
containers:
- name: nginx
image: myapp:v1
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: disktype
operator: In
values:
- ssd
preferredDuringSchedulingIgnoredDuringExecution: #倾向满足
- weight: 1
preference:
matchExpressions:
- key: role
operator: In
values:
- db
2. nodeaffinity también admite la configuración de varias condiciones de coincidencia de reglas, como
En: el valor de la etiqueta está en la lista
NotIn: el valor de la etiqueta no está en la lista
Gt: el valor de la etiqueta es mayor que el valor establecido, no es compatible con la afinidad de Pod
Lt: el valor de la etiqueta es menor que el conjunto valor, no es compatible con la afinidad del pod
Existe: la etiqueta del conjunto existe
DoesNotExist: la etiqueta del conjunto no existe
3.pod afinidad y antiafinidad
podAffinity resuelve principalmente el problema de qué POD se pueden implementar en el mismo dominio de topología con el que se pueden implementar POD (los dominios de topología se implementan mediante etiquetas de host, que pueden ser un solo host o un clúster, zona compuesta por múltiples hosts, etc. )
podAntiAffinity resuelve principalmente qué POD no se pueden implementar con El problema de la implementación de POD en el mismo dominio topológico. Se ocupan de la relación entre POD y POD dentro del clúster de Kubernetes.
La afinidad y antiafinidad entre pods puede ser más útil cuando se usa con colecciones de nivel superior (como ReplicaSets, StatefulSets, Deployments, etc.). Es fácil configurar un conjunto de cargas de trabajo que deben estar en la misma topología definida (por ejemplo, nodos).
La afinidad y antiafinidad entre pods requieren mucho procesamiento, lo que puede ralentizar significativamente la programación en clústeres a gran escala
(1)pod亲和
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx
image: myapp:v1
affinity:
podAffinity: #pod亲和
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: run
operator: In
values:
- demo
topologyKey: kubernetes.io/hostname

(2)pod反亲和
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx
image: myapp:v1
affinity:
podAntiAffinity: #pod反亲和
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: run
operator: In
values:
- demo
topologyKey: kubernetes.io/hostname

(3) Manchas (mancha)
1. La afinidad de nodo de NodeAffinity es un atributo definido en Pod, que permite que Pod se programe en un Nodo de acuerdo con nuestros requisitos, mientras que Taints es todo lo contrario. Puede hacer que Node se niegue a ejecutar Pod o incluso expulsar Pod.
2.Taints (taint) es un atributo de Node. Después de configurar Taints, Kubernetes no programará Pod en este Nodo, por lo que Kubernetes establece un atributo Tolerations para Pod, siempre que Pod pueda tolerar Node Taint en el nodo, entonces Kubernetes ignorará la mancha en Node y puede (no necesariamente) programar el Pod.
El motivo por el que server2 no participa en la programación

# 用命令 kubectl taint 给节点增加一个 taint
kubectl taint nodes server3 key=value:NoSchedule #创建
kubectl describe nodes server2 |grep Taints #查询
kubectl taint nodes server3 key:NoSchedule- #删除
3. Donde [efecto] puede ser un valor
[NoSchedule | PreferNoSchedule | NoExecute]
NoSchedule: POkD no se programará en los nodos marcados como taints.
PreferNoSchedule: la versión de estrategia blanda de NoSchedule.
NoExecute: esta opción significa que una vez que Taint surta efecto, si el POD que se ejecuta en el nodo no corresponde a la configuración de Tolerar, se expulsará directamente.
4.toleraciones
La clave, el valor y el efecto definidos en las tolerancias deben ser coherentes con el conjunto de taint en el nodo:
si el operador es Exists, el valor se puede omitir.
Si el operador es Igual, la relación entre la clave y el valor debe ser igual.
Si no se especifica el atributo de operador, el valor predeterminado es Igual.
También hay dos valores especiales:
cuando no se especifica ninguna clave, todas las claves y valores pueden coincidir con Exists, y se pueden tolerar todas las taints.
Cuando no se especifica ningún efecto, todos los efectos coinciden.
5. Aléjate
apiVersion: apps/v1
kind: Deployment
metadata:
name: web-server
spec:
selector:
matchLabels:
app: nginx
replicas: 2
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: myapp:v1
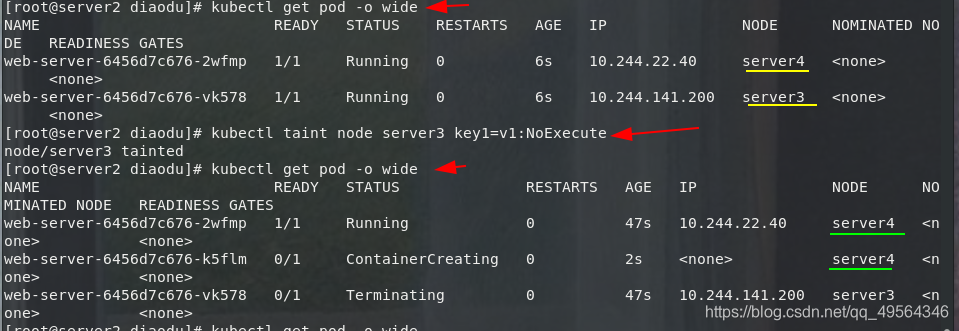
kubectl apply -f pod3.yml
kubectl get pod -o wide
kubectl taint node server3 key1=v1:NoExecute #Taint 生效,如该节点内正在运行的 POD 没有对应 Tolerate 设置,会直接被逐出
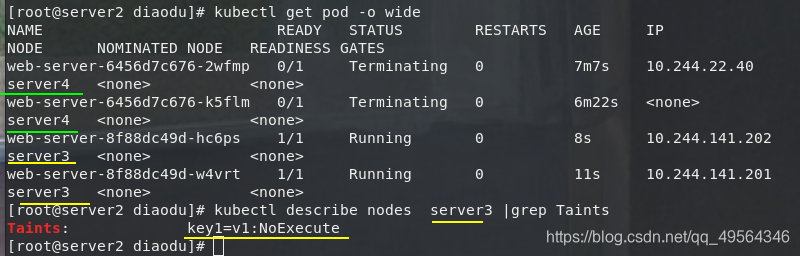
kubectl describe nodes server3 |grep Taints
6. Tolerancia
apiVersion: apps/v1
kind: Deployment
metadata:
name: web-server
spec:
selector:
matchLabels:
app: nginx
replicas: 2
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: myapp:v1
tolerations:
- key: "key1"
operator: "Equal" #污点
value: "v1"
effect: "NoExecute" #容忍
为Pod设置容忍后会,server3又可以运行Pod了
(4) También hay instrucciones que afectan la programación de Pod
Acordonar, drenar, eliminar, las cápsulas creadas más tarde no se programarán en el nodo, pero el grado de violencia es diferente
1. Cordon deja de programar:
El impacto es mínimo, solo el nodo se ajustará a SchedulingDisabled, el pod recién creado no se programará en el nodo, el pod original del nodo no se verá afectado y el servicio externo seguirá proporcionándose normalmente
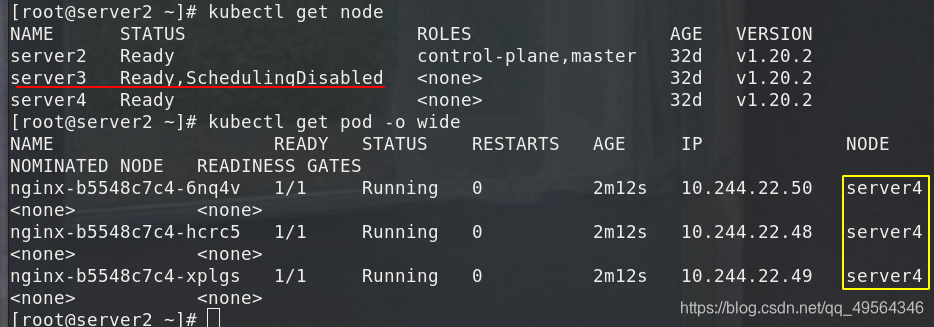
kubectl cordon server3
kubectl get node
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
namespace: default
spec:
replicas: 3
selector:
matchLabels:
run: nginx
template:
metadata:
labels:
run: nginx
spec:
containers:
- name: nginx
image: myapp:v1
imagePullPolicy: IfNotPresent
kubectl get pod -o wide
kubectl uncordon server3 #恢复
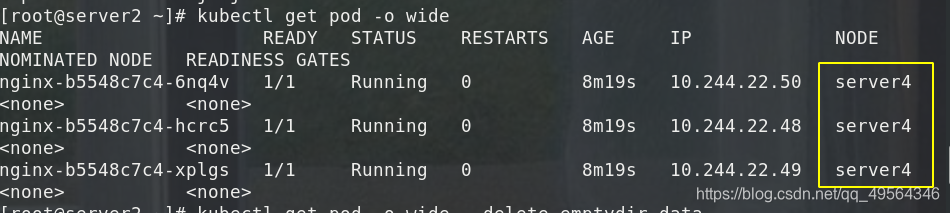
2.drenaje del nodo de expulsión:
Primero expulse el pod en el nodo, vuelva a crearlo en otros nodos y luego ajuste el nodo a SchedulingDisabled
kubectl drain server4
kubectl uncordon server4

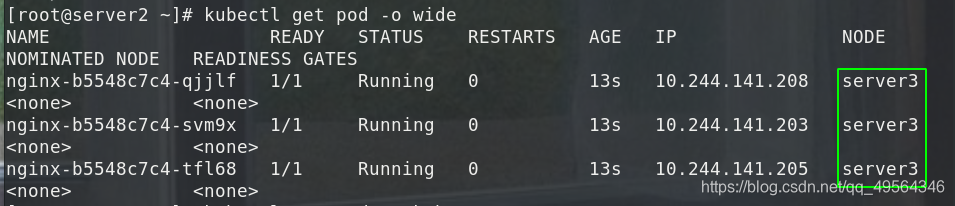
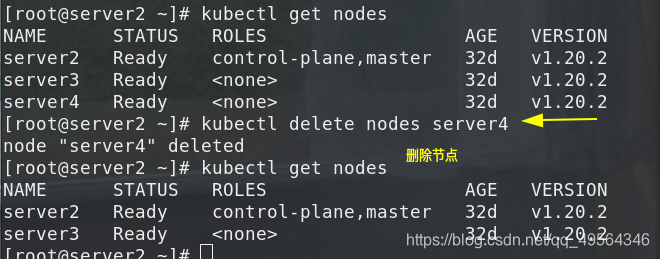
3.eliminar eliminar nodo
El más violento es primero expulsar el pod en el nodo y volver a crearlo en otros nodos. Luego, elimine el nodo del nodo maestro y el maestro pierde su control. Si desea reanudar la programación, debe ingresar al nodo nodo y reinicie el servicio kubelet.
kubectl delete nodes server4
kubectl get nodes
[root@server4 ~]# systemctl restart kubelet #基于node的自注册功能,恢复使用