Uno, el grupo de búferes de InnoDB
El sistema operativo tendrá un mecanismo de grupo de búfer para evitar el acceso al disco cada vez para acelerar el acceso a los datos.
Como sistema de almacenamiento, MySQL también tiene un mecanismo de grupo de búfer para evitar E / S del disco cada vez que se consultan datos.
El grupo de búfer es almacenar en caché los datos de la tabla y los datos de índice, y cargar los datos del disco en el grupo de búfer para evitar E / S de disco para cada acceso, lo que juega un papel en la aceleración del acceso.
La velocidad es rápida, entonces, ¿por qué no poner todos los datos en el grupo de búferes?
Todo tiene dos caras. Independientemente de la volatilidad de los datos, lo opuesto al acceso rápido es la pequeña capacidad de almacenamiento:
(1) El acceso a la caché es rápido, pero la capacidad es pequeña. La base de datos almacena datos de 200G y la capacidad de la caché solo puede ser de 64G;
(2) El acceso a la memoria es rápido, pero la capacidad es pequeña. Si compra un disco portátil con 2T, es posible que la memoria solo sea de 16G;
Por lo tanto, solo los datos "más calientes" se pueden colocar en el lugar "reciente" para reducir el acceso al disco al nivel "máximo".
¿Cómo administrar y eliminar el grupo de búferes para maximizar el rendimiento?
Antes de introducir los detalles específicos, introduzcamos el concepto de "lectura previa".
¿Qué es la lectura previa?
La lectura y escritura del disco no se lee a pedido, sino que se lee por página. Se lee al menos una página de datos (generalmente 16K) a la vez. Si los datos que se leerán en el futuro están en la página, la E / S de disco posterior se puede omitido, mejorar la eficiencia.
¿Por qué es eficaz la lectura previa?
El acceso a los datos generalmente sigue el principio de "lectura y escritura centralizada". Cuando se utilizan algunos datos, existe una alta probabilidad de que se utilicen datos cercanos. Este es el llamado "principio de localidad", que muestra que la carga temprana es efectiva y de hecho, puede reducir la E / S del disco.
¿Qué algoritmo utiliza InnoDB para administrar estas páginas de búfer?
Lo más fácil de pensar es LRU (el menos utilizado recientemente). (Memcache y OS usarán LRU para la administración de reemplazo de páginas, pero MySQL usa una variante de LRU).
En segundo lugar, el LRU tradicional (el menos utilizado recientemente)
Coloque la página en el grupo de búferes en la cabecera de la LRU como el elemento al que se accedió más recientemente y, por lo tanto, será eliminado a más tardar. Hay dos situaciones:
- La página ya está en el grupo de búfer , entonces solo se realiza la acción de "mover al" encabezado LRU y no se elimina ninguna página;
- Si la página no está en el grupo de búfer , además de la acción de "poner" el encabezado de la LRU, también se requiere la acción de "eliminar" la página de cola de la LRU;
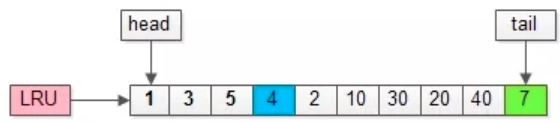
Como se muestra en la figura anterior, si la longitud de LRU del grupo de búfer de administración es 10, las páginas con números de página 1, 3, 5 ..., 40, 7 se almacenan en búfer.
Supongamos que los datos a los que se accederá a continuación se encuentran en la página con el número de página 4:
La página con el número de página 4 está originalmente en el grupo de búfer. Coloque la página con el número de página 4 al comienzo de la LRU y no se eliminará ninguna página.
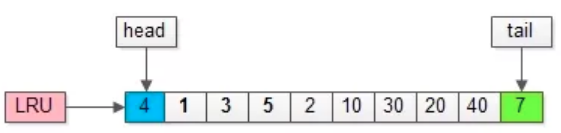
Supongamos que los datos a los que se accederá a continuación se encuentran en la página con el número de página 50:

La página con el número de página 50 no estaba originalmente en el grupo de búfer. La página con el número de página 50 se colocó al principio de la LRU y la página con el número de página 7 al final se eliminó.
Para reducir el movimiento de datos, LRU generalmente se implementa con una lista vinculada
El algoritmo tradicional del grupo de búfer de LRU es muy intuitivo . Se utilizan muchos software como OS y Memcache. ¿Por qué no se puede usar MySQL directamente?
Hay dos problemas aquí:
- Invalidación de lectura anticipada: debido a la lectura anticipada, la página se coloca en el grupo de búfer por adelantado, pero al final MySQL no lee los datos de la página, lo que se denomina invalidación de lectura anticipada.
- Contaminación del grupo de búfer: cuando se escanea una gran cantidad de datos en busca de una determinada instrucción SQL en lotes, es posible que se reemplacen todas las páginas del grupo de búfer, lo que hace que se intercambien una gran cantidad de datos activos y el rendimiento de MySQL se reduzca drásticamente Esta situación se denomina contaminación de la reserva de amortiguación.
Tres, optimización del error de lectura previa
¿Qué es el error de lectura anticipada?
Debido a Read-Ahead, la página se coloca en el búfer de antemano, pero al final MySQL no lee los datos de la página, lo que se denomina error de lectura anticipada.
Para optimizar el error de lectura anticipada, la idea es:
- Deje que las páginas que no se puedan leer con anticipación permanezcan en la LRU del grupo de búferes lo más breve posible;
- Las páginas que se leen realmente se mueven al encabezado de la LRU del grupo de almacenamientos intermedios.
Para garantizar que los datos activos que se leen realmente permanezcan en el grupo de búferes el mayor tiempo posible.
El método específico es:
- La LRU se divide en dos partes: la nueva generación (nueva sublista) y la generación anterior (antigua sublista).
- Las viejas y las nuevas generaciones están conectadas de un extremo a otro, es decir: la cola de la nueva generación está conectada a la cabeza de la vieja generación;
- Cuando se agregan páginas nuevas (como páginas leídas previamente) al grupo de búfer, solo se agregan al encabezado de la generación anterior:
- Si los datos se leen realmente (la lectura previa es exitosa), se agregarán al encabezado de la nueva generación
- Si los datos no se leen, se eliminarán del grupo de búferes antes que las "páginas de datos calientes" de la nueva generación.

Por ejemplo, toda la LRU del grupo de almacenamientos intermedios es como se muestra en la figura anterior:
La longitud de todo el LRU es 10, el primer 70% son la nueva generación, el último 30% son la generación anterior y las generaciones antiguas y nuevas están conectadas de un extremo a otro.

Si una nueva página con la página número 50 se lee previamente y se agrega al grupo de búferes:
- 50 solo se insertarán desde el encabezado de la generación anterior, y las páginas al final de la generación anterior (y también la cola general) se eliminarán
- Suponiendo que la página 50 no se leerá realmente, es decir, la lectura anticipada falla, se eliminará del grupo de búferes antes que la nueva generación de datos;

Si la página 50 se lee inmediatamente, por ejemplo, SQL accede a los datos de la fila en la página:
- Se agregará inmediatamente a la cabeza de la nueva generación;
- Las páginas de la nueva generación se exprimirán en la generación anterior, y ninguna página se eliminará realmente en este momento;
El grupo de búfer mejorado LRU puede resolver el problema del "error de lectura anticipada".
En cuarto lugar, la optimización de la contaminación de la reserva de amortiguación.
¿Qué es la contaminación del grupo de búfer de MySQL?
Cuando una determinada instrucción SQL necesita escanear una gran cantidad de datos en lotes, puede hacer que se reemplacen todas las páginas del grupo de búfer, lo que hace que se intercambie una gran cantidad de datos activos y el rendimiento de MySQL disminuya drásticamente. Esta situación es llamada contaminación de la piscina de amortiguamiento.
Por ejemplo, si hay una tabla de usuario con una gran cantidad de datos, al ejecutar:
select * from user where name like "%abcd%";
Aunque el conjunto de resultados puede tener solo una pequeña cantidad de datos, este tipo de me gusta no puede llegar al índice. Se requiere un escaneo completo de la tabla y se debe acceder a una gran cantidad de páginas:
- Agregue la página al grupo de búfer (inserte el encabezado de la generación anterior);
- Lea la fila relacionada de la página (inserte el encabezado de la nueva generación);
- El campo de nombre en la fila se compara con la cadena abcd y, si cumple las condiciones, se agrega al conjunto de resultados;
- ... Hasta que se escaneen todas las filas de todas las páginas ...
De esta manera, todas las páginas de datos se cargarán en el cabezal de la nueva generación, pero solo se accederá una vez, y los datos calientes reales se intercambiarán en grandes cantidades.
¿Cómo resolver el problema de la contaminación de la reserva intermedia causada por el escaneo de una gran cantidad de datos?
El grupo de búfer de MySQL ha agregado un mecanismo de "la ventana de tiempo de residencia de la generación anterior":
- Suponga que T = la ventana de tiempo de residencia de la generación anterior;
- Las páginas insertadas en el encabezado de la generación anterior, incluso si se accede a ellas inmediatamente, no se colocarán en el encabezado de la nueva generación inmediatamente;
- Solo cuando se satisfaga “visitado” y el “tiempo de permanencia en la generación anterior” sea mayor que T, se le pondrá en la cabeza a la nueva generación;

Continuando con el ejemplo, si se escanean datos por lotes, se visitarán en secuencia cinco páginas, como 51, 52, 53, 54, 55.

Si no existe una estrategia de "ventana de tiempo de residencia de la vieja generación", estas páginas a las que se accede en lotes intercambiarán una gran cantidad de datos importantes.

Después de agregar la estrategia de "ventana de tiempo de residencia de la vieja generación", las páginas que se cargan en una gran cantidad en poco tiempo no se insertarán inmediatamente en el encabezado de la nueva generación, sino aquellas páginas a las que se ha accedido solo una vez en un período corto. de tiempo se eliminan preferentemente.

Y solo si la generación anterior se queda el tiempo suficiente y el tiempo de permanencia es mayor que T, se insertará en la cabeza de la generación joven.
Cinco, los principios anteriores corresponden a los parámetros en InnoDB
Hay tres parámetros más importantes.
mysql> show variables like '%innodb_buffer_pool_size%';
+-------------------------+-----------+
| Variable_name | Value |
+-------------------------+-----------+
| innodb_buffer_pool_size | 134217728 |
+-------------------------+-----------+
1 row in set (0.03 sec)
mysql> show variables like '%innodb_old_blocks_pct%';
+-----------------------+-------+
| Variable_name | Value |
+-----------------------+-------+
| innodb_old_blocks_pct | 37 |
+-----------------------+-------+
1 row in set (0.00 sec)
mysql> show variables like '%innodb_old_blocks_time%';
+------------------------+-------+
| Variable_name | Value |
+------------------------+-------+
| innodb_old_blocks_time | 1000 |
+------------------------+-------+
1 row in set (0.01 sec)
- innodb_buffer_pool_size: Configure el tamaño del grupo de búfer. Cuando la memoria está permitida, el DBA a menudo recomienda aumentar este parámetro. Cuantos más datos e índices se pongan en la memoria, mejor será el rendimiento de la base de datos.
- innodb_old_blocks_pct: La relación entre la generación anterior y la longitud de toda la cadena LRU. El valor predeterminado es 37, es decir, la relación entre la duración de la generación joven y la generación anterior en toda la LRU es 63:37.
- innodb_old_blocks_time: La ventana de tiempo de permanencia de la generación anterior, en milisegundos, el valor predeterminado es 1000, es decir, se insertará en el encabezado de la nueva generación si cumple con las condiciones de "visitado" y "permanecer en la generación anterior durante más de 1 segundo ".
Seis, resumen
- El grupo de búfer (grupo de búfer) es un mecanismo común para reducir el acceso al disco;
- El grupo de búferes generalmente almacena datos en caché en páginas (página);
- El algoritmo de administración común del grupo de búfer es LRU, Memcache, OS, InnoDB, todos usan este algoritmo;
- InnoDB optimiza LRU ordinario:
- El grupo de búfer se divide en la generación anterior y la generación joven . Las páginas que ingresan al grupo de búfer ingresan primero a la generación anterior, y se accede a la página antes de ingresar a la nueva generación para resolver el problema de la falla previa a la lectura.
- Se accede a las páginas y el tiempo empleado en la generación anterior supera el umbral configurado antes de ingresar a la nueva generación para resolver el problema del acceso a los datos por lotes y la eliminación de grandes cantidades de datos calientes.