1. El controlador MySQL del cliente:
Antes de que nuestro sistema se comunique con la base de datos MySQL, necesita establecer una conexión con la base de datos. Esta función la realiza la capa inferior del controlador MySQL por nosotros. Una vez establecida la conexión, solo necesitamos enviar sentencias SQL para ejecutar CRUD . Como se muestra abajo:
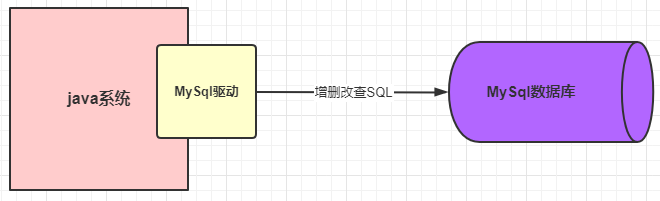
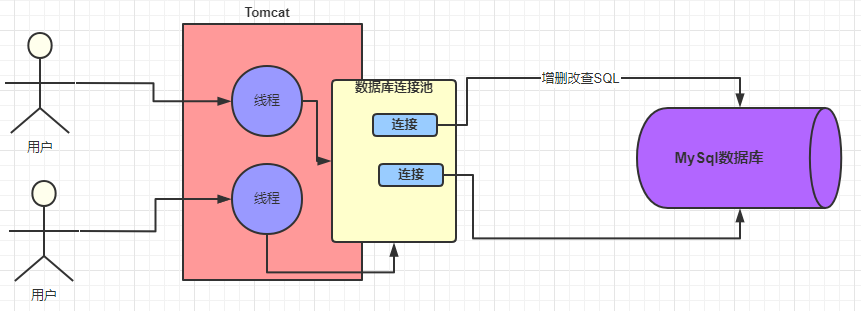
Una solicitud SQL establecerá una conexión y varias solicitudes establecerán múltiples conexiones. Suponiendo que nuestro sistema está implementado en un contenedor Tomcat, Tomcat puede procesar múltiples solicitudes al mismo tiempo, lo que hará que múltiples solicitudes establezcan múltiples conexiones y luego las cierre después de su uso. ¿Qué pasará con este problema? El sistema Java se basa en el protocolo TCP / IP cuando se conecta a la base de datos MySQL a través del controlador MySQL, por lo que si cada solicitud es para crear y destruir una conexión, la creación y destrucción de conexiones tan frecuente reducirá inevitablemente en gran medida el rendimiento de nuestro sistema. .
Para resolver los problemas anteriores, se adopta la idea de "agrupación" para mantener un cierto número de subprocesos de conexión a través del grupo de conexiones. Cuando se necesita una conexión, se obtiene directamente del grupo de subprocesos y luego se devuelve a el grupo de subprocesos después de su uso. El grupo de subprocesos reduce en gran medida la sobrecarga de crear y destruir constantemente subprocesos, y no necesitamos preocuparnos por la creación y destrucción de conexiones, y cómo el grupo de subprocesos mantiene estas conexiones. Los grupos de conexión de bases de datos comunes son Druid, C3P0, DBCP。
2. Capa de servidor de la arquitectura MySql:
Antes de presentar los pasos de ejecución de las declaraciones SQL en la base de datos MySQL en el servidor, primero comprendamos la estructura general de MySQL:
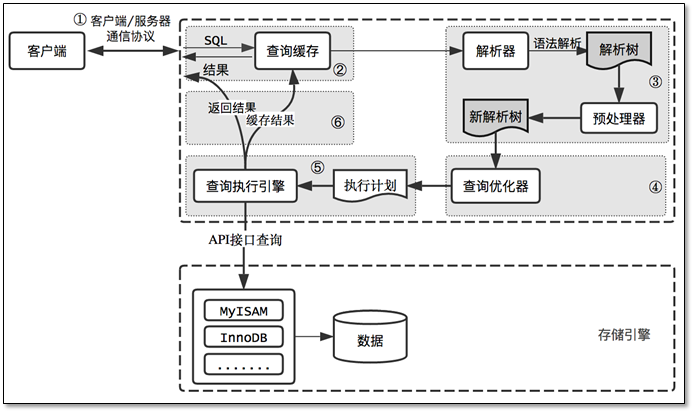
Si la imagen de arriba no es clara, puede volver a mirar la siguiente imagen:
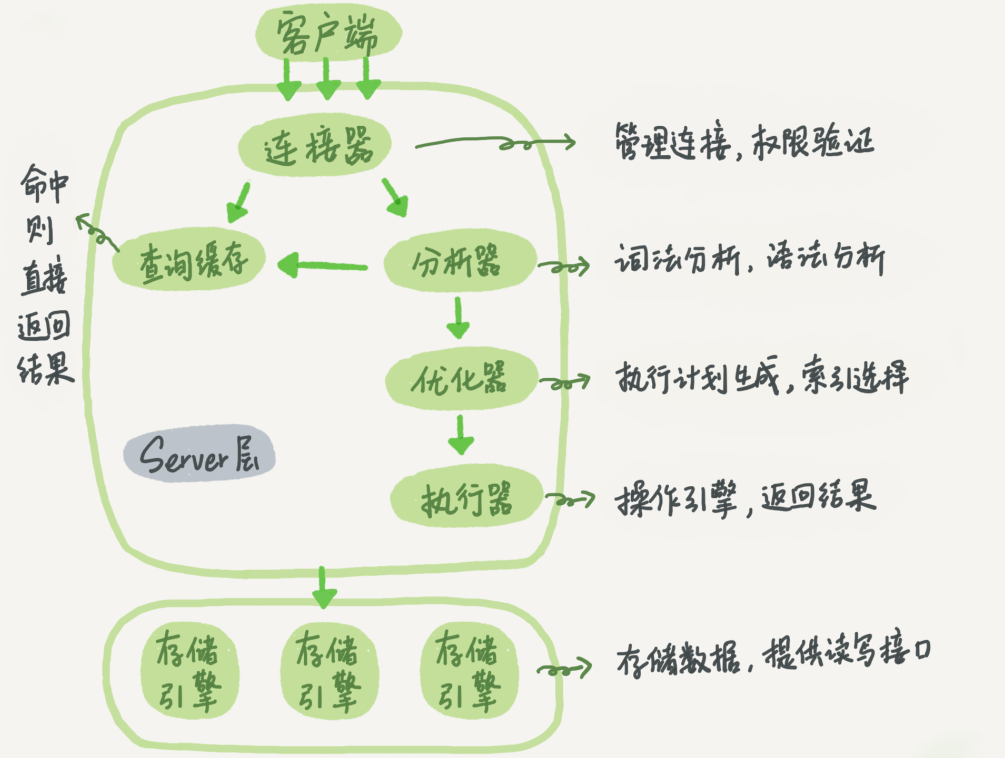
En el diagrama de arquitectura anterior, se puede ver que la capa del servidor se compone principalmente de conectores, cachés de consultas, resolutores / analizadores, optimizadores y ejecutores. Estas partes se describirán principalmente a continuación.
1. Conector:
Cuando el cliente quiere operar la base de datos, la premisa es establecer una conexión con la base de datos; y el conector se utiliza para establecer una conexión con el cliente, obtener permisos, mantener y administrar la conexión.
(1) Método de conexión:
MySQL admite conexiones cortas y largas. La conexión corta se cerrará inmediatamente después de que se complete la operación. La conexión larga se puede mantener abierta, reduciendo el consumo del servidor para crear y liberar la conexión Esta conexión también se puede utilizar durante el acceso posterior al programa.
(2) Grupo de conexiones:
Al igual que el grupo de conexiones del cliente, para reducir la pérdida de rendimiento innecesaria causada por la creación y destrucción frecuentes de conexiones, la idea de "agrupación" también se adopta aquí para administrar las conexiones a través del grupo de conexiones de la base de datos. Generalmente usaremos conexiones largas en el grupo de conexiones, por ejemplo: druid, c3p0, dbcp, etc.
2. Caché de consultas:
La caché de MySQL está desactivada de forma predeterminada, lo que significa que no se recomienda el uso de la caché, y toda la función de la caché de consultas se elimina directamente en la versión MySQL 8.0
(1) ¿Por qué MySql no habilita el almacenamiento en caché de forma predeterminada?
Principalmente debido a sus escenarios de uso:
① Permítanme hablar sobre el formato de almacenamiento de datos en la caché: clave (declaración SQL) -valor (valor de datos), por lo que si la declaración SQL (clave) tiene una pequeña diferencia, consultará directamente la base de datos;
② Dado que los datos de la tabla no son estáticos, la mayoría cambia con frecuencia, y cuando los datos de la base de datos cambian, es necesario eliminar los datos de caché correspondientes relacionados con esta tabla;
3. Análisis / analizador:
El trabajo del analizador es principalmente analizar la instrucción SQL que se ejecutará y finalmente obtener el árbol de sintaxis abstracta, y luego usar el preprocesador para determinar si la tabla en el árbol de sintaxis abstracta existe, si existe, luego determinar si la selección El campo de la columna de proyección está en Exist en la tabla y así sucesivamente.
(1) Análisis léxico:
El análisis léxico se utiliza para desensamblar SQL en símbolos atómicos indivisibles, llamados Tokens. Y de acuerdo con los diccionarios proporcionados por los diferentes dialectos de la base de datos, se clasifican en palabras clave, expresiones, literales y operadores.
(2) Análisis de sintaxis:
El análisis de sintaxis consiste en convertir declaraciones SQL en árboles de sintaxis abstractos basados en el Token (símbolo atómico) que se desmonta mediante análisis léxico.
El siguiente es un ejemplo directo para ilustrar cómo se ve un libro de sintaxis abstracta de SQL:
SELECT id, name FROM t_user WHERE status = 'ACTIVE' AND age > 18
Entonces, el libro de gramática abstracta obtenido después del análisis léxico y el análisis gramatical de la declaración SQL anterior es el siguiente:
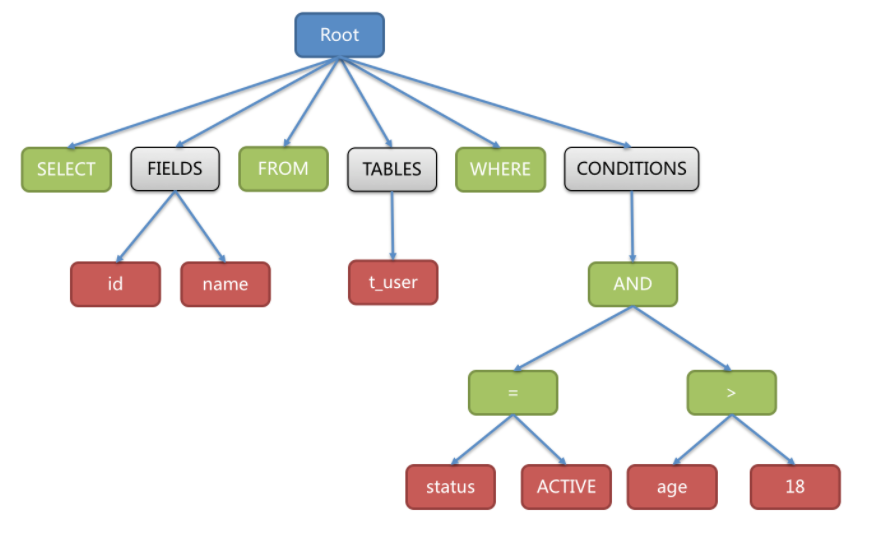
Tenga en cuenta que para facilitar la comprensión, el Token de la palabra clave en el árbol de sintaxis abstracta se representa en verde, el Token de la variable se representa en rojo y el gris indica que debe dividirse más.
(3) Preprocesador:
El preprocesamiento se utiliza para realizar la verificación semántica en el árbol de sintaxis abstracta generado . La verificación semántica consiste en verificar la tabla de consulta y seleccionar los campos de la columna de proyección para determinar si la tabla y el campo existen o no;
4. Optimizador:
La función del optimizador es principalmente tomar el árbol gramatical obtenido tras el análisis léxico / análisis sintáctico de SQL, mediante una serie de cálculos a través del contenido del diccionario de datos MySQL e información estadística, y finalmente obtener un plan de ejecución , incluyendo la elección de qué índice utilizar.
En el proceso de optimización, ¿cuál es la serie de cálculos?
(1) Transformación lógica: por ejemplo, hay 8> 9 en la condición SQL where. La transformación lógica es simplificar directamente la expresión constante en el árbol de sintaxis a falso; además de la simplificación, también hay expresiones constantes. Cálculo etc.
(2) Optimización de costos: pagando el costo del análisis estadístico de los datos, para saber si la ejecución de SQL se puede indexar y qué índices ir; además, en la consulta relacionada con múltiples tablas, determine el orden de la tabla final unirse, etc. ;
Al analizar si se debe utilizar la consulta de índice, se obtiene realizando un muestreo dinámico de datos y análisis estadístico ; mientras se analice estadísticamente, puede haber errores de análisis. Por lo tanto, este aspecto debe ser considerado cuando la ejecución de SQL no utiliza el índice. .los elementos de
¿Cómo verificar el plan de ejecución de MySql? Simplemente agregue la palabra clave explicar antes de la instrucción SQL ejecutada;
5. Actuador:
MySQL sabe lo que quiere hacer a través del analizador y sabe qué hacer a través del optimizador, por lo que ingresa a la etapa de ejecutor y comienza a ejecutar la instrucción. El ejecutor finalmente llama a la interfaz API proporcionada por el motor de almacenamiento para llamar a los datos operativos de acuerdo con una serie de planes de ejecución para completar la ejecución de SQL.
Al comenzar a ejecutar, primero debe determinar si el objeto conectado tiene permiso para realizar operaciones en esta tabla, si no, devolverá un error de no permiso, si es así, ejecútelo de acuerdo con el plan de ejecución generado.
Tres, motor de almacenamiento InnoDB:
El motor de almacenamiento es un componente que realiza operaciones reales en los datos físicos subyacentes y proporciona varias API para los datos operativos de la capa del servidor. Los datos se almacenan en la memoria o en el disco. MySQL admite motores de almacenamiento enchufables, incluidos InnoDB, MyISAM, Memory, etc. En general, el motor de almacenamiento utilizado por MySQL es InnoDB por defecto. Como se muestra en la figura siguiente, el motor de almacenamiento InnoDB se divide en estructura de memoria (estructuras de memoria) y estructura de disco (estructuras de disco) en su conjunto.
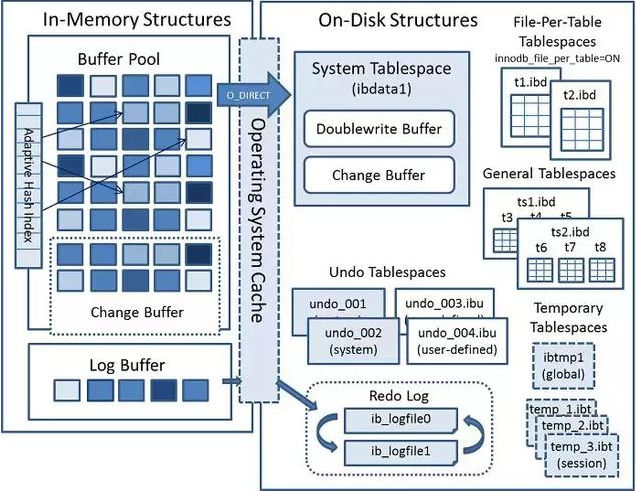
1 、 Grupo de búfer:
Buffer Pool (grupo de búfer) es una estructura de memoria muy importante en el motor de almacenamiento InnoDB, funciona como Redis y actúa como caché. Los datos de MySQL se almacenan en última instancia en el disco. Si no hay Buffer Pool, todas las solicitudes de base de datos se buscarán en el disco, por lo que inevitablemente habrá operaciones IO. Pero con el grupo de búfer, solo la primera consulta almacenará los resultados de la consulta en el grupo de búfer, de modo que cuando haya solicitudes posteriores, primero consultará desde el grupo de búfer. Si no lo encuentra en el disco, Luego colóquelo en el Buffer Pool, como se muestra a continuación
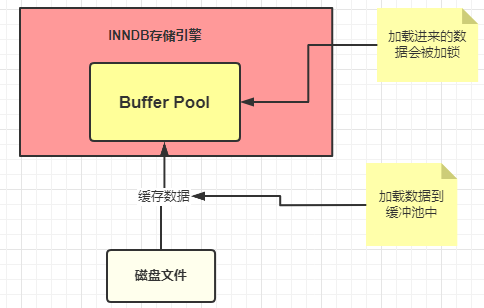
UPDATE students SET stuName = '小强' WHERE id = 1
Por ejemplo, para este SQL, de acuerdo con la imagen de arriba, los pasos de ejecución de la declaración SQL son más o menos así:
- (1) El motor de almacenamiento innodb busca primero en el grupo de búferes la existencia de los datos con id = 1
- (2) Si el caché no existe, cárguelo en el disco y guárdelo en el grupo de búfer
- (3) Se agregará un candado exclusivo al registro
Observaciones:
La diferencia entre el grupo de búferes y la caché de consultas:
(1) Caché de consultas: El caché de consultas se encuentra en la capa del servidor. MySQL Server primero verificará si el SQL se ha ejecutado desde el caché de consultas. Si se ha ejecutado, los resultados de la consulta ejecutados previamente se almacenarán en el caché de consultas. en forma de valor-clave en. La clave es la declaración SQL y el valor es el resultado de la consulta. ¡A este proceso lo llamamos caché de consultas!
(2) Buffer Pool se encuentra en la capa del motor de almacenamiento. Buffer Pool es un mecanismo de almacenamiento en búfer diseñado por el motor de almacenamiento MySQL para acelerar la velocidad de lectura de datos.
2. Deshacer archivo de registro: registre cómo se ven los datos antes de modificarlos.
La característica más importante del motor de almacenamiento Innodb es admitir transacciones. Si la transacción no se confirma, todas las operaciones de la transacción deben revertirse al estado anterior a la ejecución, y esta operación de reversión se realiza mediante el archivo de registro de deshacer.
deshacer, como su nombre lo indica, significa que no pasó nada, no pasó nada. deshacer el registro son algunos registros donde no pasó nada (lo que era lo original)
Acabamos de presentar que cuando se prepara para actualizar una declaración SQL, los datos correspondientes a la declaración se han cargado en el grupo de búfer. De hecho, existe una operación de este tipo aquí, que consiste en cargar la declaración en el grupo de búfer. Al mismo tiempo, se inserta un registro en el archivo de registro de deshacer, es decir, se registra el valor original del registro con id = 1, de modo que se pueda deshacer después de que falle la transacción.
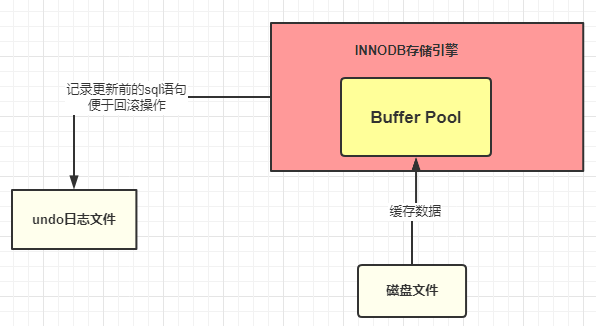
En este punto, los datos correspondientes a la declaración SQL que ejecutamos se han cargado en el Buffer Pool, y luego comenzamos a actualizar esta declaración. La operación de actualización se ejecuta realmente en el Buffer Pool. El problema es que, después de actualizar los datos, los datos del Buffer Pool serán inconsistentes con la base de datos en la base de datos, es decir, ¿los datos del Buffer Pool se convertirán en datos sucios? Así es, los datos actuales son datos sucios. El registro en el Buffer Pool es "Xiaoqiang" y el registro en la base de datos es "Wangcai". ¿Cómo maneja MySQL esta situación? Miremos hacia abajo
3. Rehacer archivo de registro: registre la apariencia de los datos después de que se hayan modificado
Prefacio: El archivo de registro de rehacer es exclusivo de InnoDB, se encuentra en el nivel del motor de almacenamiento, no en el nivel de MySQL.
Además de cargar archivos desde el disco y guardar los registros antes de la operación en el archivo de registro de deshacer, se completan otras operaciones en la memoria.Las características de los datos en la memoria son: pérdida de energía. Si el servidor donde MySQL está inactivo en este momento, se perderán todos los datos del Buffer Pool. En este momento, el archivo de registro de rehacer debe mostrar su magia
Rehacer significa listo para hacer y listo para hacer. El registro de rehacer registra algunas operaciones que se realizarán. Por ejemplo, lo que se hará en este momento es actualizar el conjunto de estudiantes stuName = 'Xiaoqiang' donde id = 1; Luego, esta operación se registrará en el búfer de registro de rehacer. El búfer de registro de rehacer es MySQL para mejorar la eficiencia, por lo que estas operaciones se ponen primero en memoria para completar
Suponiendo que el servidor está inactivo en este momento, los datos en la caché aún se pierden. ¿Se puede guardar directamente en el disco en lugar de en la memoria? Obviamente no, porque también se ha introducido anteriormente que el propósito de las operaciones en la memoria es mejorar la eficiencia. En este punto, si MySQL realmente falla, no importa, porque MySQL considerará que esta transacción es un error, por lo que los datos siguen siendo los mismos que antes de la actualización y no habrá ningún impacto.
En este punto, la declaración SQL también se actualiza, luego se debe enviar el valor actualizado, es decir, se debe enviar la transacción. Siempre que la transacción se envíe correctamente, el último cambio se guardará en la base de datos. Para Mantener los datos en el búfer de registro de rehacer en el disco es escribir los datos en el búfer de registro de rehacer en el archivo de disco de registro de rehacer.
Si el servidor de la base de datos deja de funcionar después de que el búfer de registro de rehacer se descargue en el disco, ¿qué debemos hacer con los datos actualizados? En este momento, los datos están en la memoria, ¿no se pierden los datos? No, los datos no se perderán esta vez, porque los datos en el búfer de registro de rehacer se han escrito en el disco y se han conservado. Incluso si la base de datos está inactiva, MySQL rehacerá el archivo de registro la próxima vez que se reinicie. el contenido se restaura en el Buffer Pool
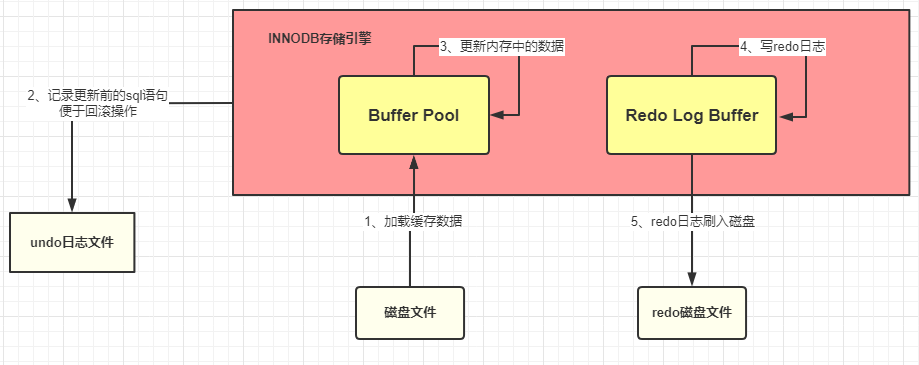
- (1) Prepárese para actualizar una declaración SQL
- (2) MySQL (innodb) primero irá al grupo de búfer (Grupo de búfer) para encontrar los datos, si no los encuentra, irá al disco para encontrarlos, si los encuentra, cargará los datos en el búfer pool (Buffer Pool)
- (3) Mientras se carga en el Buffer Pool, el registro original de estos datos se guardará en el archivo de registro de deshacer.
- (4) Innodb realizará operaciones de actualización en el Buffer Pool
- (5) Los datos actualizados se registrarán en el búfer de registro de rehacer
- (6) Cuando MySQL confirma la transacción, escribirá los datos en el búfer de registro de rehacer en el archivo de registro de rehacer. El vaciado del disco se puede establecer mediante el parámetro innodb_flush_log_at_trx_commit, un valor de 0 significa que no se va a vaciar el disco, un valor de 1 significa vaciar inmediatamente el disco, un valor de 2 significa flashear primero al caché del sistema operativo. En circunstancias normales, actualice el disco inmediatamente
- (7) Cuando se reinicia myslq, el registro de rehacer se restaurará en el grupo de búferes
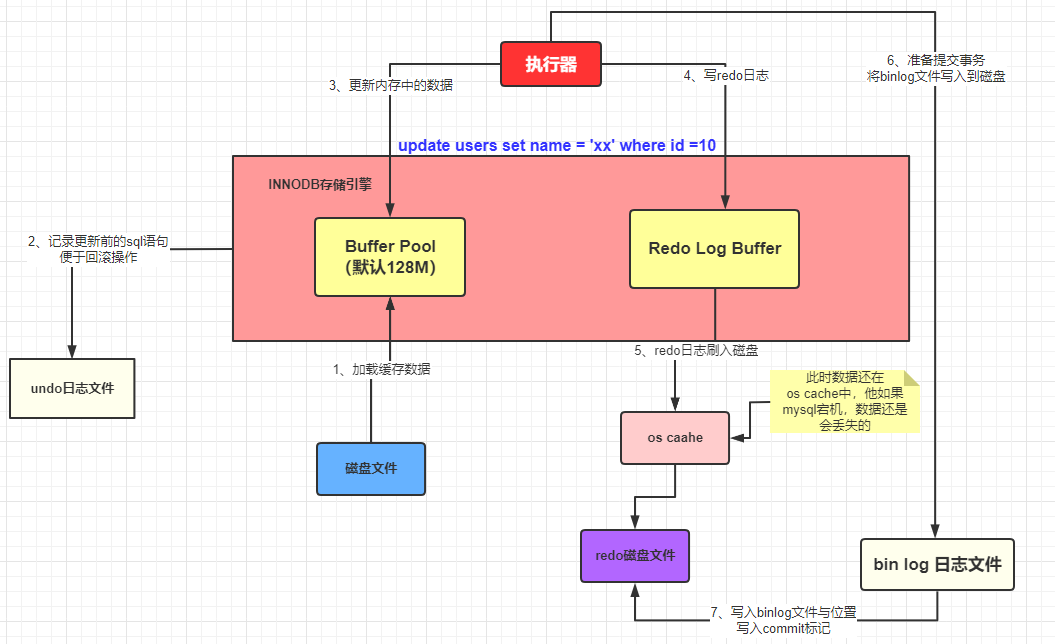
4. Archivo de registro de bin: registra todo el proceso de operación
Prefacio: Bin log y redo log son algo similares, las principales diferencias entre los dos son:
(1) El registro de rehacer es un archivo de registro exclusivo del motor de almacenamiento InnoDB, y el registro bin es un registro de nivel MySQL
(2) El registro de rehacer es adecuado para la recuperación de fallos, y el registro de la bandeja es adecuado para la replicación maestro-esclavo y la recuperación de datos
Las cosas registradas en el registro de rehacer están sesgadas hacia propiedades físicas, como: "qué datos y qué cambios se han realizado". El bin log está sesgado hacia la naturaleza lógica, similar a: "La operación de actualización se alquila al registro con id 1 en la tabla de estudiantes".
¿Cómo se descarga el archivo de registro bin en el disco? La estrategia de descarga del registro bin se puede modificar mediante sync_bin log. El valor predeterminado es 0, lo que significa que se escribe primero en la caché del sistema operativo, lo que significa que cuando se realiza la transacción confirmado, los datos no se enviarán directamente al disco. Por lo tanto, si los datos del registro de la bandeja están inactivos, los datos aún se perderán. Por lo tanto, se recomienda establecer sync_bin log en 1, lo que significa escribir datos directamente en el archivo de disco.
Dado que bin log también es un archivo de registro, ¿dónde registra los datos? De hecho, cuando MySQL confirma una transacción, no solo escribirá los datos en el búfer del registro de rehacer en el archivo de registro de rehacer, sino que también registrará los datos modificados en el archivo de registro bin, y esta vez también registrará el bin modificado. La ubicación del nombre del archivo de registro y el contenido modificado en el registro bin se registra en el registro de rehacer y, finalmente, se escribe una marca de confirmación al final del registro de rehacer, lo que significa que la transacción se comprometió con éxito.
Cuando los datos se escriben en el archivo de registro bin, si la base de datos está inactiva justo después de que se completa la escritura, ¿se perderán los datos?
Lo primero que hay que asegurarse es que mientras no haya una marca de confirmación al final del registro de rehacer, significa que esta transacción debe haber fallado. Pero los datos no se pierden, porque se han registrado en el archivo de disco del registro de rehacer. Cuando MySQL se reinicia, los datos del registro de rehacer se restaurarán (cargarán) en el Buffer Pool.
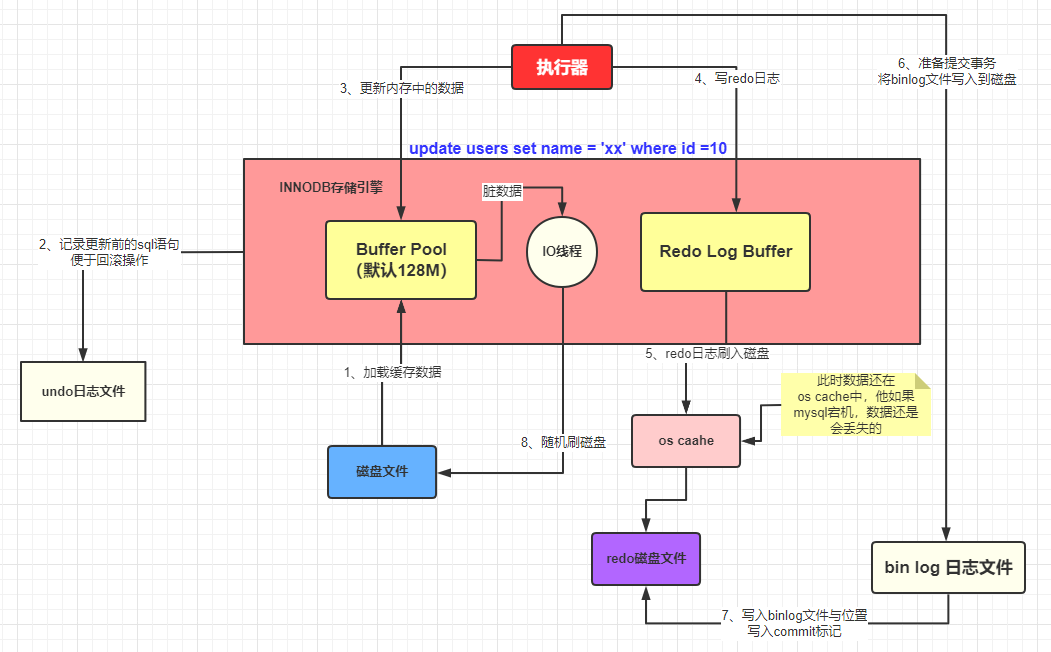
Bueno, hasta ahora, básicamente hemos introducido una operación de actualización básicamente, pero ¿sientes que falta algo que no se ha hecho? ¿También encontró que el registro actualizado en este momento solo se ejecuta en la memoria, incluso si la máquina está inactiva y reanudada, solo está cargando el registro actualizado en el Buffer Pool? En este momento, el registro en la base de datos MySQL todavía es El valor antiguo, es decir, los datos en la memoria siguen siendo datos sucios en nuestra opinión, ¿qué debemos hacer en este momento?
De hecho, MySQL tendrá un subproceso en segundo plano, que descargará los datos sucios en nuestro Buffer Pool a la base de datos MySQL en un momento determinado, de modo que la memoria y los datos de la base de datos se unificarán.
5. Resumen:
- (1) Primero, el ejecutor de MySQL llama a la API del motor de almacenamiento para consultar los datos de acuerdo con el plan de ejecución.
- (2) El motor de almacenamiento consulta primero los datos del grupo de búfer del grupo de búfer; de lo contrario, irá al disco para consultar y, si se consulta, se colocará en el grupo de búfer.
- (3) Cuando los datos se cargan en el Buffer Pool, el registro original de estos datos se guardará en el archivo de registro de deshacer.
- (4) Innodb realizará operaciones de actualización en el Buffer Pool
- (5) Los datos actualizados se registrarán en el búfer de registro de rehacer
- (6) La transacción de confirmación hará las siguientes tres cosas mientras se confirma
- (7) (Lo primero) vaciar los datos del búfer de registro de rehacer en el archivo de registro de rehacer
- (8) (Segunda cosa) Escriba este registro de operación en el archivo de registro bin
- (9) (La tercera cosa) Registre el nombre del archivo de registro bin y la ubicación del contenido actualizado en el registro bin en el registro de rehacer, y agregue una marca de confirmación al final del registro de rehacer
- (10) Usando un hilo en segundo plano, vaciará los datos actualizados en nuestro Buffer Pool a la base de datos MySQL en un momento determinado, de modo que los datos de la memoria y la base de datos se unificarán
Articulo de referencia: