Explicación detallada del principio volátil
Volátil es un mecanismo de sincronización ligero proporcionado por la máquina virtual Java
La palabra clave volátil tiene las siguientes dos funciones
-
Asegúrese de que la variable compartida modificada por volátil sea visible para el número total de todos los subprocesos, es decir, cuando un subproceso modifica el valor de una variable compartida modificada por volátil, el nuevo valor siempre puede ser conocido inmediatamente por otros subprocesos.
-
Prohibir la optimización de reordenamiento de instrucciones.
Visibilidad de volátiles
public class VolatileVisibilitySample {
private boolean initFlag = false;
static Object object = new Object();
public void refresh(){
this.initFlag = true; //普通写操作,(volatile写)
String threadname = Thread.currentThread().getName();
System.out.println("线程:"+threadname+":修改共享变量initFlag");
}
public void load(){
String threadname = Thread.currentThread().getName();
int i = 0;
while (!initFlag){
synchronized (object){
i++;
}
//i++;
}
System.out.println("线程:"+threadname+"当前线程嗅探到initFlag的状态的改变"+i);
}
public static void main(String[] args){
VolatileVisibilitySample sample = new VolatileVisibilitySample();
Thread threadA = new Thread(()->{
sample.refresh();
},"threadA");
Thread threadB = new Thread(()->{
sample.load();
},"threadB");
threadB.start();
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
threadA.start();
}
}
Después de que el hilo A cambia el atributo initFlag, el hilo B percibe inmediatamente
Volátil no puede garantizar la atomicidad
public class VolatileAtomicSample {
private static volatile int counter = 0;
public static void main(String[] args) {
for (int i = 0; i < 10; i++) {
Thread thread = new Thread(()->{
for (int j = 0; j < 1000; j++) {
counter++; //不是一个原子操作,第一轮循环结果是没有刷入主存,这一轮循环已经无效
//1 load counter 到工作内存
//2 add counter 执行自加
//其他的代码段?
}
});
thread.start();
}
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(counter);
}
}
Puedes ejecutarlo, el resultado final no será 10000
Volátil prohíbe la optimización del reordenamiento
Reordenamiento de pedidos
El reordenamiento se refiere a un medio por el cual el compilador y el procesador reordenan la secuencia de instrucciones para optimizar el rendimiento del programa. La especificación del lenguaje Java estipula que la semántica secuencial se mantiene dentro del subproceso JVM. Es decir, siempre que el resultado final del programa sea igual al resultado de su secuencialización, entonces el orden de ejecución de las instrucciones puede ser inconsistente con el orden del código.Este proceso se denomina reordenamiento de instrucciones. ¿Cuál es el significado de reordenamiento de instrucciones? JVM puede reordenar adecuadamente las instrucciones de la máquina de acuerdo con las características del procesador (sistema de caché de varios niveles de la CPU, procesador de varios núcleos, etc.), de modo que las instrucciones de la máquina puedan estar más en línea con las características de ejecución de la CPU y el rendimiento de la máquina. se puede maximizar.

Hay dos etapas principales de reordenamiento de la instrucción:
1. Etapa de compilación del compilador: el compilador reorganizará las instrucciones cuando se cargue el archivo de clase y se compile en código de máquina.
2. Etapa de ejecución de la CPU: cuando la CPU ejecuta instrucciones de ensamblaje, las instrucciones pueden reordenarse
public class VolatileReOrderSample {
private static int x = 0, y = 0;
private static int a = 0, b =0;
static Object object = new Object();
public static void main(String[] args) throws InterruptedException {
int i = 0;
for (;;){
i++;
x = 0; y = 0;
a = 0; b = 0;
Thread t1 = new Thread(new Runnable() {
public void run() {
//由于线程one先启动,下面这句话让它等一等线程two. 读着可根据自己电脑的实际性能适当调整等待时间.
shortWait(10000);
a = 1; //是读还是写?store,volatile写
//storeload ,读写屏障,不允许volatile写与第二部volatile读发生重排
//手动加内存屏障
//UnsafeInstance.reflectGetUnsafe().storeFence();
x = b; // 读还是写?读写都有,先读volatile,写普通变量
//分两步进行,第一步先volatile读,第二步再普通写
}
});
Thread t2 = new Thread(new Runnable() {
public void run() {
b = 1;
//手动增加内存屏障
//UnsafeInstance.reflectGetUnsafe().storeFence();
y = a;
}
});
t1.start();
t2.start();
t1.join();
t2.join();
String result = "第" + i + "次 (" + x + "," + y + ")";
if(x == 0 && y == 0) {
System.err.println(result);
break;
} else {
System.out.println(result);
}
}
}
public static void shortWait(long interval){
long start = System.nanoTime();
long end;
do{
end = System.nanoTime();
}while(start + interval >= end);
}
}
El resultado final de la ejecución puede ser 0 0, que es causado por la ejecución del reordenamiento, porque reordenar en un solo subproceso no afectará el resultado de la ejecución como-si-serial, pero no es necesariamente en un multi-subproceso.
como-si-serial
public static void main(String[] args) {
/**
* as-if-serial语义的意思是:不管怎么重排序(编译器和处理器为了提高并行度),(单线程)
* 程序的执行结果不能被改变。编译器、runtime和处理器都必须遵守as-if-serial语义。
*
* 以下例子当中1、2步存在指令重排行为,但是1、2不能与第三步指令重排
* 也就是第3步不可能先于1、2步执行,否则将改变程序的执行结果
*/
double p = 3.14; //1
double r = 1.0; //2
double area = p * r * r; //3计算面积
}
public class DoubleCheckLock {
private static DoubleCheckLock instance;
private DoubleCheckLock(){
}
public static DoubleCheckLock getInstance(){
//第一次检测
if (instance==null){
//同步
synchronized (DoubleCheckLock.class){
if (instance == null){
//多线程环境下可能会出现问题的地方
instance = new DoubleCheckLock();
}
}
}
return instance;
}
}
El código anterior es un código clásico de detección doble singleton. Este código no tiene ningún problema en un entorno de un solo subproceso, pero los problemas de seguridad de subprocesos pueden ocurrir en un entorno de subprocesos múltiples. La razón es que cuando un subproceso se ejecuta en la primera detección, cuando la instancia leída no es nula, es posible que el objeto de referencia de la instancia no se inicialice. Porque instance = new DoubleCheckLock (); se puede dividir en los siguientes 3 pasos para completar (pseudocódigo)
memory = allocate();//1.分配对象内存空间
instance(memory);//2.初始化对象
instance = memory;//3.设置instance指向刚分配的内存地址,此时
instance!=null
Como puede haber un reordenamiento entre el paso 1 y el paso 2, de la siguiente manera:
memory=allocate();//1.分配对象内存空间
instance=memory;//3.设置instance指向刚分配的内存地址,此时instance!
=null,但是对象还没有初始化完成!
instance(memory);//2.初始化对象
Dado que no hay dependencia de datos entre los pasos 2 y 3, y el resultado de la ejecución del programa no cambia en un solo subproceso antes o después de la reordenación, se permite esta optimización de la reordenación. Sin embargo, el reordenamiento de instrucciones solo asegurará la consistencia de la ejecución de la semántica serial (un solo hilo), pero no se preocupa por la consistencia semántica entre múltiples hilos. Por lo tanto, cuando un subproceso accede a la instancia no es nulo, debido a que es posible que la instancia de la instancia no se haya inicializado, se producen problemas de seguridad de subprocesos. Entonces, cómo resolverlo, es muy simple, podemos usar volatile para prohibir la ejecución de la variable de instancia y reordenar y optimizar la instrucción.
//禁止指令重排优化
private volatile static DoubleCheckLock instance;
Barrera de la memoria
La barrera de memoria (Memory Barrier), también conocida como barrera de memoria, es una instrucción de la CPU. Tiene dos funciones. Una es asegurar el orden de ejecución de operaciones específicas y la otra es asegurar la visibilidad de la memoria de ciertas variables (usando esta función para lograr la Visibilidad de la memoria volátil). Porque tanto el compilador como el procesador pueden realizar la optimización del reordenamiento de instrucciones. Si se inserta una barrera de memoria entre instrucciones, le indicará al compilador y a la CPU que no se pueden reordenar instrucciones con esta instrucción de barrera de memoria, es decir, insertando una barrera de memoria, las instrucciones antes y después de la barrera de memoria están prohibidas. Realización de optimización de reordenamiento. Otra función de Memory Barrier es forzar a que se vacíen los datos de la caché de varias CPU, para que cualquier hilo de la CPU pueda leer la última versión de estos datos. En resumen, las variables volátiles logran su semántica en la memoria a través de la barrera de la memoria (instrucción de bloqueo), visibilidad y optimización de la prohibición de reordenamiento.
La siguiente figura es una tabla de reglas de reordenamiento volátiles formuladas por JMM para el compilador.

Por ejemplo, la última celda de la tercera fila significa: En el programa, cuando la primera operación es la lectura o escritura de variables ordinarias, si la segunda operación es escritura volátil, el compilador no puede reordenar las dos Operaciones.
Como se puede ver en la figura anterior:
- Cuando la segunda operación es una escritura volátil, no importa cuál sea la primera operación, no se puede reordenar. Esta regla garantiza que el compilador no reordene las operaciones anteriores a las escrituras volátiles para después de las escrituras volátiles.
- Cuando la primera operación es una lectura volátil, no importa cuál sea la segunda operación, no se puede reordenar. Esta regla garantiza que el compilador no reordene las operaciones posteriores a la lectura volátil a antes de la lectura volátil.
- Cuando la primera operación es una escritura volátil y la segunda operación es una lectura volátil, no se puede reordenar.
Para realizar la semántica de memoria de volátil, el compilador inserta una barrera de memoria en la secuencia de instrucciones para prohibir tipos específicos de reordenamiento del procesador al generar código de bytes. Para el compilador, es casi imposible encontrar una disposición óptima para minimizar el número total de barreras de inserción. Por esta razón, JMM adopta una estrategia conservadora. La siguiente es una estrategia de inserción de barrera de memoria JMM basada en una estrategia conservadora.
- Inserte una barrera StoreStore antes de cada operación de escritura volátil.
- Inserte una barrera StoreLoad después de cada operación de escritura volátil.
- Inserte una barrera LoadLoad después de cada operación de lectura volátil.
- Inserte una barrera LoadStore después de cada operación de lectura volátil.
El siguiente es un diagrama esquemático
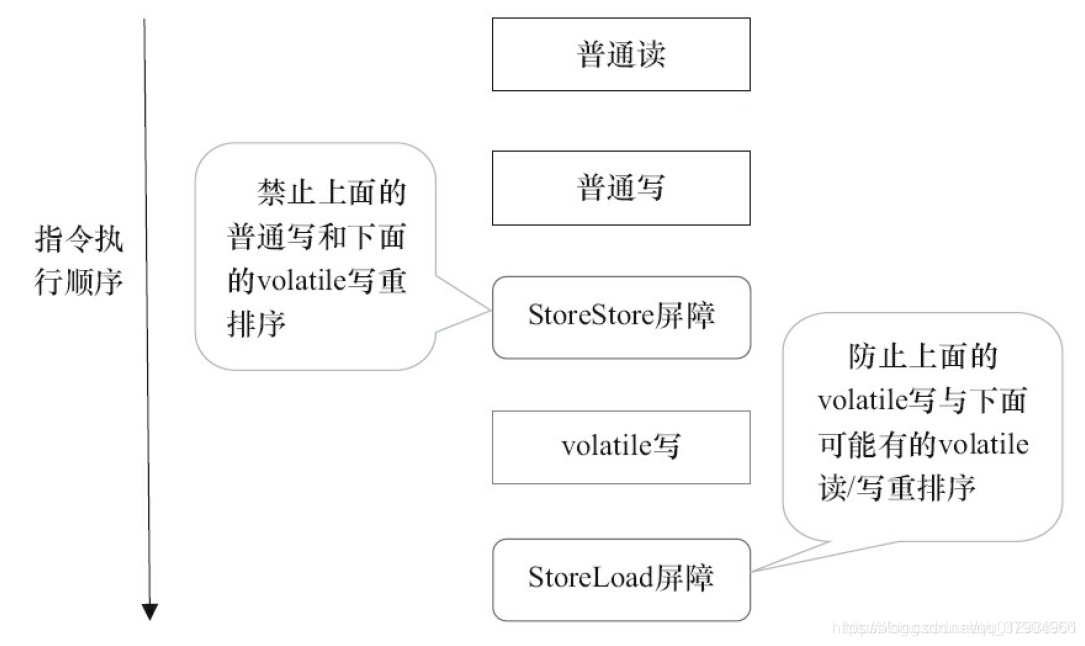
de la secuencia de instrucciones generada después de que se inserta una escritura volátil en la barrera de memoria bajo una estrategia conservadora. La siguiente figura es un diagrama esquemático de la secuencia de instrucciones generada después de que se inserta una lectura volátil en la barrera de memoria debajo de un estrategia conservadora.

Ejemplo de código
public class VolatileBarrierExample {
int a;
volatile int m1 = 1;
volatile int m2 = 2;
void readAndWrite() {
int i = m1; // 第一个volatile读
int j = m2; // 第二个volatile读
a = i + j; // 普通写
m1 = i + 1; // 第一个volatile写
m2 = j * 2; // 第二个 volatile写
}
}
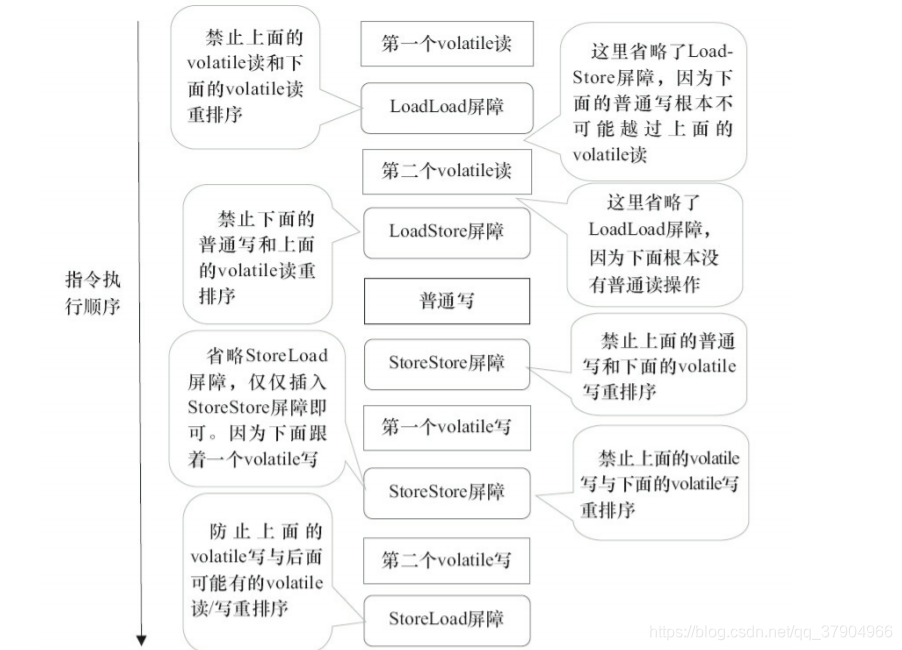
Tenga en cuenta que la última barrera StoreLoad no se puede omitir. Porque después de escribir el segundo volátil, el método regresa inmediatamente. En este momento, es posible que el compilador no pueda determinar con precisión si habrá una lectura o escritura volátil más tarde. Por razones de seguridad, el compilador generalmente inserta una barrera StoreLoad aquí.
La optimización anterior es para cualquier plataforma de procesador Dado que los diferentes procesadores tienen diferentes modelos de memoria de procesador de "rigidez", la inserción de barreras de memoria también se puede optimizar de acuerdo con el modelo de memoria del procesador específico. Tome el procesador X86 como ejemplo, excepto por la última barrera StoreLoad en la Figura 3-21, se omitirán otras barreras. La lectura y escritura volátiles bajo la estrategia conservadora anterior se puede optimizar como se muestra en la figura siguiente en la plataforma del procesador X86. Como se mencionó anteriormente, el procesador X86 solo reordena las operaciones de escritura y lectura. X86 no reordena las operaciones de lectura-lectura, lectura-escritura y escritura-escritura, por lo que las barreras de memoria correspondientes a estos tres tipos de operaciones se omitirán en el procesador X86. En X86, JMM solo necesita insertar una barrera StoreLoad después de la escritura volátil para implementar correctamente la semántica de memoria de lectura y escritura volátil. Esto significa que en los procesadores X86, el costo de las escrituras volátiles será mucho mayor que el de las lecturas volátiles (porque la ejecución de la barrera StoreLoad será más cara)
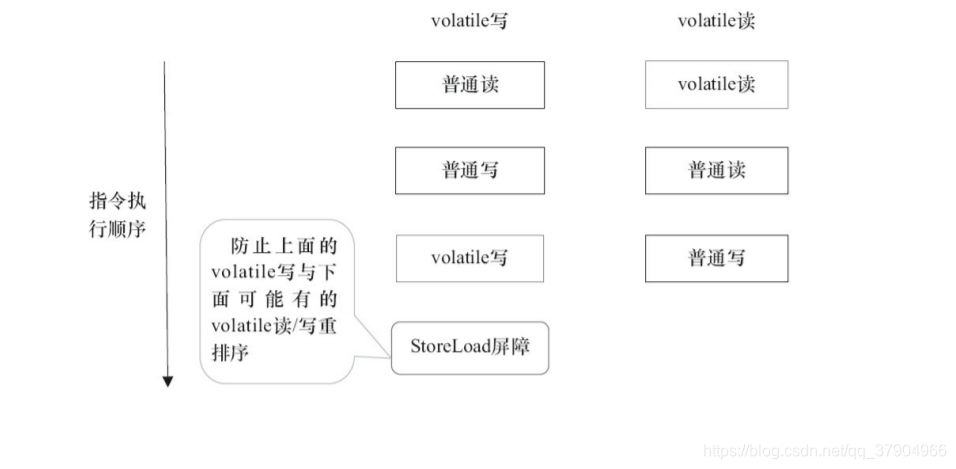
El principio subyacente de volátil
Las variables modificadas por la palabra clave volátil pueden garantizar la visibilidad y el orden, pero no pueden garantizar la atomicidad. Echemos un vistazo al modo singleton de doble verificación y bloqueo. Esta variable global debe ser volátil. Imprimamos las instrucciones de ensamblaje y veamos qué hace la palabra clave volátil.
Cómo imprimir las instrucciones de montaje
- -XX: + UnlockDiagnosticVMOptions -XX: + PrintAssembly -Xcomp
- Complemento hsdis
public class Singleton {
private volatile static Singleton myinstance;
public static Singleton getInstance() {
if (myinstance == null) {
synchronized (Singleton.class) {
if (myinstance == null) {
myinstance = new Singleton();//对象创建过程,本质可以分文三步
}
}
}
return myinstance;
}
public static void main(String[] args) {
Singleton.getInstance();
}
}
0x00000000038064dd: mov %r10d,0x68(%rsi)
0x00000000038064e1: shr $0x9,%rsi
0x00000000038064e5: movabs $0xf1d8000,%rax
0x00000000038064ef: movb $0x0,(%rsi,%rax,1) ;*putstatic myinstance
; - com.it.edu.jmm.Singleton::getInstance@24 (line 22)
0x0000000003cd6edd: mov %r10d,0x68(%rsi)
0x0000000003cd6ee1: shr $0x9,%rsi
0x0000000003cd6ee5: movabs $0xf698000,%rax
0x0000000003cd6eef: movb $0x0,(%rsi,%rax,1)
0x0000000003cd6ef3: lock addl $0x0,(%rsp) ;*putstatic myinstance
; - com.it.edu.jmm.Singleton::getInstance@24 (line 22)
A través de la comparación, se encuentra que el cambio de clave es la variable con modificación volátil. Después de la asignación (movb $ 0x0, (% rsi,% rax, 1) anterior es la operación de asignación), uno más "lock addl $ 0x0, ( % rsp ")", esta operación es equivalente a una barrera de memoria.
La clave aquí es el prefijo de bloqueo. Su función es escribir el caché de este procesador en la memoria. Esta acción de escritura también hará que otros procesadores u otros núcleos invaliden su caché (Invalidate, el estado I del protocolo MESI). Esta operación es equivalente a realizar las operaciones de "almacenar y escribir" mencionadas en la introducción anterior al modelo de memoria Java en las variables de la caché. Por tanto, a través de dicha operación, la modificación de la variable volátil anterior puede ser inmediatamente visible para otros procesadores. La implementación de nivel inferior de la instrucción de bloqueo: si se admite la línea de caché, se agregará un bloqueo de caché (MESI); si no se admite el bloqueo de caché, se agregará un bloqueo de bus.
Agregar barrera de memoria manualmente
public class UnsafeInstance {
public static Unsafe reflectGetUnsafe() {
try {
Field field = Unsafe.class.getDeclaredField("theUnsafe");
field.setAccessible(true);
return (Unsafe) field.get(null);
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
}
UnsafeInstance.reflectGetUnsafe().loadFence();//读屏障
UnsafeInstance.reflectGetUnsafe().storeFence();//写屏障
UnsafeInstance.reflectGetUnsafe().fullFence();//读写屏障