Entorno de instalación
verificación
127.0.0.1:6379> info
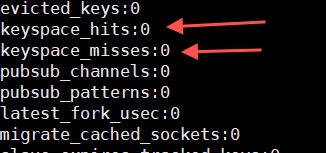
Consultar una clave que no existe
127.0.0.1:6379> get test
(nil)
Mirando la tasa de aciertos,
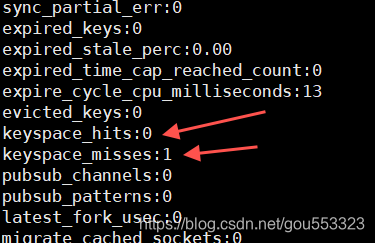
inserte un nuevo nombre de valor
127.0.0.1:6379> set name JackMA
OK
Nombre de la consulta
127.0.0.1:6379> get name
"JackMA"
Mira la tasa de aciertos
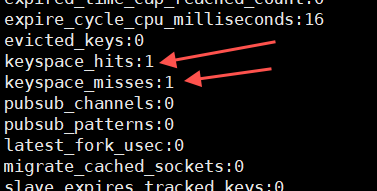
para resumir
El cálculo de la tasa de aciertos aciertos / (aciertos + fallos) A partir de este cálculo solo, siempre que todos los datos a consultar estén en la caché, entonces es 100%, y no es necesario distinguir entre alta frecuencia y baja frecuencia. En el caso de que no se encuentren algunos datos, cuanto más grande sea la molécula, mayor será la tasa de aciertos, es decir, se necesitarán más claves de alta frecuencia, lo que puede aumentar relativamente la tasa de aciertos. Lo que quiero aclarar es si no es necesario almacenar en caché los datos de acceso de baja frecuencia. Anteriormente, todos los datos en el centro de productos de las grandes fábricas y los centros de productos orientados a C se almacenaban en caché. Ahora, en las pequeñas empresas, en primer lugar, los datos La estructura es un conjunto, no hay diferencia entre la orientación B y la orientación C, y algunos datos relacionados con el usuario, la frecuencia de acceso definitivamente será muy baja, porque está relacionada con un solo usuario, ¿es necesario almacenar estos datos en caché? , o si es concurrente. Es necesario colocar la caché en casos grandes, y la recuperación de la caché es definitivamente más rápida que mysql.