Tabla de contenido

Introducción a HTTP
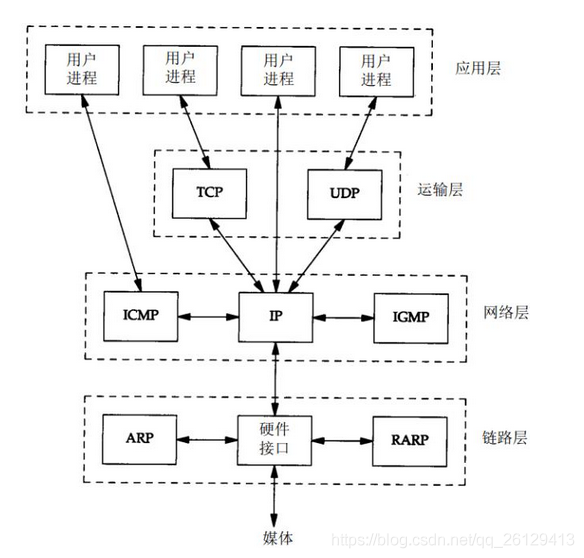
El protocolo httpd es un protocolo de transferencia de hipertexto. Se basa en el protocolo de comunicación TCP / IP para transferir datos (texto, imágenes, resultados de consultas, etc.).
Cuando el cliente accede a recursos estáticos, es una página estática. Cuando el cliente accede a un recurso estático, es un acceso dinámico (algunos unilateral).), se encuentra en la capa de aplicación.
Tres características de HTTP
Sin conexión:
por ejemplo, descargar datos, desconectar después de descargar datos.
Independiente:
Puede transmitir
video, audio e imágenes en cualquier tipo de datos, contenido tipo MIME.
Stateless:
sin capacidad de memoria.
Por ejemplo, necesita ser retransmitido por falta de información. A diferencia de tcp, tcp tiene memoria.
Estructura de mensaje HTTP
HTTP se basa en el modelo de arquitectura cliente / servidor (C / S), que intercambia información a través de un enlace confiable y es un protocolo de solicitud / respuesta sin estado.
Un "cliente" HTTP es una aplicación (navegador web o cualquier otro cliente) que se conecta al servidor para enviar una o más solicitudes HTTP al servidor.
Un "servidor" HTTP también es una aplicación (generalmente un servicio web, como Nginx, servidor web Apache o servidor IIS, etc.), que recibe solicitudes del cliente y envía datos de respuesta HTTP al cliente.
HTTP utiliza identificadores uniformes de recursos (URI) para transmitir datos y establecer conexiones.
Flujo de solicitud HTTP
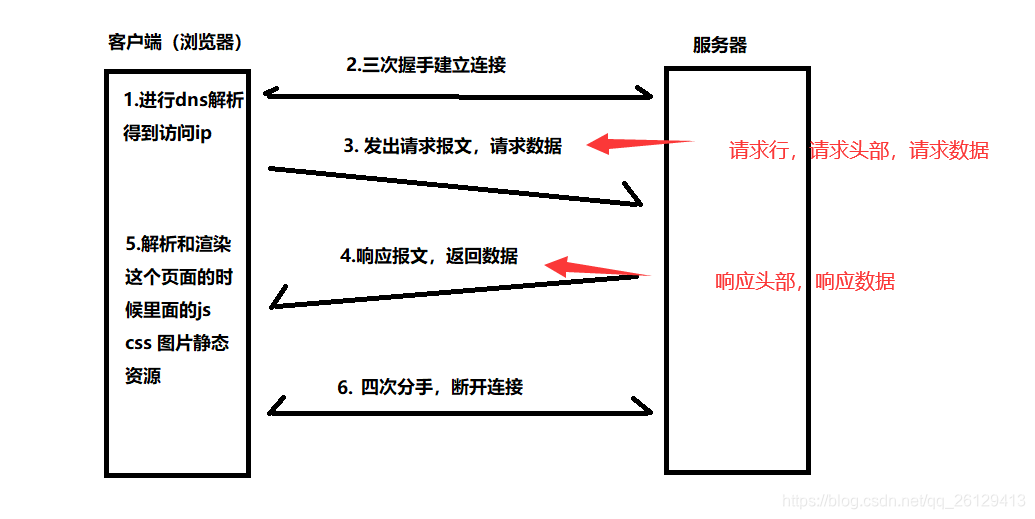
1. Resolución de DNS El
navegador comprueba su propia caché de DNS y lee el archivo HOST local sin leer la caché. Inicie una llamada al sistema DNS (como un operador inicia la resolución de la caché de DNS). El operador comprueba su propia caché. Inicie una solicitud de resolución de DNS iterativa (servidor DNS raíz -> servidor DNS del dominio com), devuelva el resultado al kernel del sistema operativo y almacénelo en caché (para el próximo uso). Esta es una resolución de DNS simple para obtener la IP correspondiente al nombre de dominio del servidor.
2. Tres apretones de manos
basados en el protocolo TCP
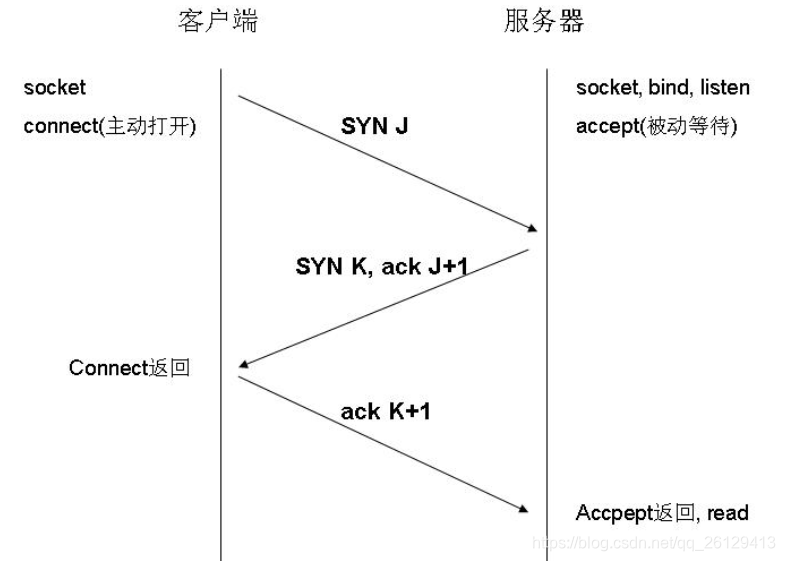
En el protocolo TCP / IP, el protocolo TCP proporciona un servicio de conexión confiable y utiliza un protocolo de enlace de tres vías para establecer una conexión.
El primer protocolo de enlace: cuando se establece una conexión, el cliente envía un paquete de sincronización (syn = j) al servidor y entra en el estado SYN_SEND, esperando que el servidor confirme; el
segundo protocolo de enlace: el servidor recibe el paquete de sincronización y debe confirmar el SYN del cliente (ack = j + 1), al mismo tiempo envía un paquete SYN (syn = k), es decir, paquete SYN + ACK, en este momento el servidor ingresa al estado SYN_RECV; el tercer handshake: el el cliente recibe el paquete SYN + ACK del servidor y envía un paquete de acuse de recibo al servidor ACK (ack = k + 1), este paquete se envía, el cliente y el servidor entran en el estado ESTABLECIDO y se completa el protocolo de enlace de tres vías. Después de completar el protocolo de enlace de tres vías, el cliente y el servidor comienzan a transmitir datos.
Después de completar el protocolo de enlace de tres vías, el host A y el host B comienzan a transmitir datos.
3. El cliente envía un
protocolo http de solicitud de recursos al servidor , que define la forma del mensaje de solicitud y el mensaje de respuesta. Aunque el mensaje http se transmite a través del "canal de transmisión de datos basado en el protocolo tcp", el protocolo http no preocuparse por el mensaje http La forma de transmisión de texto es cómo estandarizar el contenido de la solicitud y el contenido de la respuesta.
El mensaje de solicitud de que el cliente envía una solicitud HTTP al servidor incluye el siguiente formato: línea de solicitud, encabezado de solicitud, línea en blanco y datos de solicitud. La siguiente figura muestra el formato general del mensaje de solicitud.
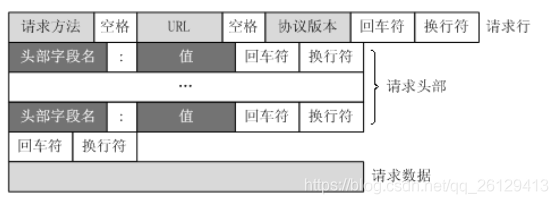
Por ejemplo, un proceso de solicitud como Baidu:
 Línea de solicitud:
Línea de solicitud:
① Método de solicitud HTTP:
según el estándar HTTP, las solicitudes HTTP pueden utilizar varios métodos de solicitud.
HTTP1.0 define tres métodos de solicitud: métodos GET, POST y HEAD.
HTTP1.1 agrega cinco nuevos métodos de solicitud: métodos OPTIONS, PUT, DELETE, TRACE y CONNECT.
Métodos clave:
OBTENER: simplemente obtener datos (obtener una página index.html)
POST: cargar / crear un archivo (se generarán nuevos datos)
PUT: guardar datos (sobrescribir / actualizar archivos, imágenes, etc., no se mostrarán nuevos datos generado)
BORRAR : Eliminar
②URL:
URL: Localizador uniforme de recursos, que es un método de identificación abstracto y único de la ubicación de recursos.
Composición: <protocolo>: // <host>: <puerto> / <ruta> El
puerto y la ruta se pueden omitir (el número de puerto predeterminado HTTP es 80)
③Versión
del protocolo : El formato de la versión del protocolo es: HTTP / número de versión principal. Número de versión menor, comúnmente utilizado son HTTP / 1.0 y HTTP / 1.1
Encabezado de solicitud
Son exclusivos del mensaje de solicitud y proporcionan información adicional para el servidor, como qué tipo de datos desea recibir el cliente, como el encabezado Aceptar.
Solicitar datos
4. Datos de respuesta del servidor La respuesta
HTTP también consta de cuatro partes: línea de estado, encabezado del mensaje, línea en blanco y cuerpo de la respuesta.
 Línea de estado
Línea de estado
Cuando un navegador visita una página web, el navegador del espectador envía una solicitud al servidor donde se encuentra la página web. Antes de que el navegador reciba y muestre la página web, el servidor donde se encuentra la página web devolverá un encabezado de servidor que contiene el código de estado HTTP para responder a la solicitud del navegador.
El inglés del código de estado HTTP es HTTP Status Code.
Los siguientes son códigos de estado HTTP comunes:
- 200 solicitudes exitosas
- 301-Los recursos (páginas web, etc.) se transfieren permanentemente a otras URL
- 404-El recurso solicitado (página web, etc.) no existe
- 403-El servidor entendió la solicitud del cliente solicitante, pero se negó a ejecutar la solicitud
- Error interno de servidor 500

Encabezado de respuesta
Encabezado de respuesta: es conveniente que el cliente proporcione información, por ejemplo, con qué tipo de servidor está interactuando el servicio al cliente, como el encabezado del servidor.
Encabezado de la entidad: se refiere al encabezado que se usa para tratar la parte del cuerpo de la entidad. Por ejemplo, el encabezado de la entidad se puede usar para describir el tipo de datos del cuerpo de la entidad, como el encabezado Content-Type.
| Encabezado de respuesta | Descripción |
|---|---|
| Permitir | Qué métodos de solicitud admite el servidor (como GET, POST, etc.). |
| Codificación de contenido | Método de codificación del documento. Solo después de la decodificación se puede obtener el tipo de contenido especificado por el encabezado Content-Type. El uso de gzip para comprimir documentos puede reducir significativamente el tiempo de descarga de documentos HTML. GZIPOutputStream de Java puede realizar fácilmente la compresión gzip, pero solo lo admiten Netscape en Unix e IE 4 e IE 5 en Windows. Por lo tanto, el servlet debe verificar si el navegador es compatible con gzip mirando el encabezado Accept-Encoding (es decir, request.getHeader ("Accept-Encoding")), y devolver páginas HTML comprimidas con gzip para los navegadores que admiten gzip, y devolver páginas normales. para otros navegadores. |
| Largancia de contenido | Indica la longitud del contenido. Estos datos solo son necesarios cuando el navegador utiliza una conexión HTTP persistente. Si desea aprovechar la conexión persistente, puede escribir el documento de salida en un ByteArrayOutputStream, verificar su tamaño después de la finalización y luego poner el valor en el encabezado Content-Length y finalmente enviar el contenido a través de byteArrayStream.writeTo (respuesta .getOutputStream (). |
| Tipo de contenido | Indica a qué tipo MIME pertenece el siguiente documento. Servlet tiene como valor predeterminado texto / sin formato, pero generalmente debe especificarse explícitamente como texto / html. Dado que Content-Type se establece a menudo, HttpServletResponse proporciona un método dedicado setContentType. |
| Fecha | La hora GMT actual. Puede usar setDateHeader para configurar este encabezado y evitar el problema de convertir el formato de hora. |
| Expira | ¿Cuándo debo pensar que el documento ha caducado para que ya no se almacene en caché? |
| Última modificación | La hora en que se modificó por última vez el documento. Los clientes pueden proporcionar una fecha a través del encabezado de solicitud If-Modified-Since, la solicitud se tratará como un GET condicional, y solo se devolverán los documentos cuya hora de modificación sea posterior a la hora especificada; de lo contrario, un estado 304 (No modificado) Será devuelto. Last-Modified también se puede configurar con el método setDateHeader. |
| Ubicación | Indica a dónde debe ir el cliente para recuperar el documento. La ubicación generalmente no se establece directamente, sino a través del método sendRedirect de HttpServletResponse, que también establece el código de estado en 302. |
| Actualizar | Indica el tiempo después del cual el navegador debe actualizar el documento, en segundos. Además de actualizar el documento actual, también puede usar setHeader ("Refresh", "5; URL = http: // host / path") para permitir que el navegador lea la página especificada. Tenga en cuenta que esta función generalmente se logra configurando <META HTTP-EQUIV = "Refresh" CONTENT = "5; URL = http: // host / path"> en el área HEAD de la página HTML. Esto se debe a que la actualización automática o redirección Aquellos escritores HTML que no pueden usar CGI o Servlet son muy importantes. Sin embargo, para Servlet, es más conveniente establecer directamente el encabezado Refresh. Tenga en cuenta que el significado de Actualizar es "actualizar esta página o visitar la página especificada después de N segundos", no "actualizar esta página o visitar la página especificada cada N segundos". Por lo tanto, la actualización continua requiere enviar un encabezado Refresh cada vez, y el envío de un código de estado 204 puede evitar que el navegador continúe actualizándose, ya sea utilizando el encabezado Refresh o <META HTTP-EQUIV = "Refresh"…>. Tenga en cuenta que el encabezado Refresh no es parte de la especificación oficial HTTP 1.1, sino una extensión, pero tanto Netscape como IE lo admiten. |
| Servidor | El nombre del servidor. El servlet generalmente no establece este valor, pero lo establece el propio servidor web. |
| Set-Cookie | Establecer cookies asociadas a la página. Servlet no debe usar response.setHeader ("Set-Cookie",…), pero debe usar el método especial addCookie proporcionado por HttpServletResponse. Vea la discusión sobre la configuración de cookies a continuación. |
Datos correspondientes
El tipo de cabeza raíz devuelve datos
5. Representación de páginas
El proceso de los navegadores modernos para representar una página es así: Analizar html para construir un árbol DOM -> construir un árbol de representación -> diseñar un árbol de representación -> dibujar un árbol de representación.
El árbol DOM está compuesto por la disposición de etiquetas en el archivo html.
El árbol de representación se forma agregando estilos de estilo en css o html al árbol DOM. El árbol de representación solo contiene elementos DOM que deben mostrarse en la página, como elementos o elementos cuyo valor de atributo de visualización es ninguno están en el árbol de representación. Antes de que el navegador reciba el archivo html completo, comienza a representar la página.
Cuando encuentre etiquetas de script, etiquetas de estilo e imágenes vinculadas externamente, la solicitud http se enviará nuevamente para repetir los pasos anteriores. Después de recibir el archivo css, volverá a renderizar las páginas renderizadas y agregará sus estilos adecuados. Después de cargar el archivo de imagen, se mostrará inmediatamente en la posición correspondiente. En este proceso, se puede activar el rediseño o la reorganización de la página.
6. El servidor se desconecta (saluda cuatro veces)
Dado que la conexión TCP es full-duplex, cada dirección debe cerrarse por separado. El principio es que cuando una parte completa su tarea de envío de datos, puede enviar un FIN para terminar la conexión en esta dirección. Recibir un FIN solo significa que no hay flujo de datos en esta dirección. Una conexión TCP aún puede enviar datos después de recibir un FIN. La parte que se apaga primero ejecutará el apagado activo y la otra parte ejecutará el apagado pasivo.
第一次挥手:TCP 客户端发送一个 FIN,用来关闭客户端到服务器的数据传送。
(第一次挥手:由浏览器发起的,发送给服务器,我请求报文发送完了,你准备关闭吧)
第二次挥手:服务器收到这个 FIN,它发回一个 ACK,确认序号为收到的序号加 1 。和 SYN 一样,一个 FIN 将占用一个序号。
(第二次挥手:由服务器发起的,告诉浏览器,我请求报文接受完了,我准备关闭了,你也准备吧)
第三次挥手:服务器关闭客户端的连接,发送一个 FIN 给客户端。
(第三次挥手:由服务器发起,告诉浏览器,我响应报文发送完了,你准备关闭吧)
第四次挥手:客户端发回 ACK 报文确认,并将确认序号设置为收到序号加 1 。
(第四次挥手:由浏览器发起,告诉服务器,我响应报文接受完了,我准备关闭了,你也准备吧)
=============================================== = ============================================== == ============================================= === ============================================ ==== ============================================= ===== ========================================
Navegación y visualización difíciles, si es correcto, es útil , por favor dale me gusta (σ ゚ ∀ ゚) σ…: * ☆