En las aplicaciones de Internet móvil, a menudo es necesario realizar un análisis estadístico de la información del lado del usuario en función de la información de ubicación del usuario, etc. Para obtener la información de ubicación del usuario, generalmente existen dos métodos: información de posicionamiento GPS y la dirección IP del usuario. Dado que todos los teléfonos móviles no necesariamente encienden el GPS y, a veces, no necesitan una ubicación demasiado precisa (hasta el nivel de una ciudad), es una buena opción analizar la ubicación del usuario en función de la dirección IP. Para lograr esta función, necesita una biblioteca de relaciones de mapeo entre IP y ubicación geográfica, y confíe en esta biblioteca para iniciar un servicio de IP a ubicación geográfica. Este artículo parte de los requisitos, combinado con ip2region con 8.4k estrellas en Github para analizar el diseño de la biblioteca de mapas y cómo la IP se puede convertir rápidamente en una ubicación geográfica.
Introducción
Los servicios de ubicación IP son muy comunes, y muchas empresas brindan servicios pagos similares, como Ali, Gaode, Baidu, etc., por supuesto, también hay servicios gratuitos abiertos, como GeoIP, IP pura, etc. Estos servicios se analizan a través de páginas HTML o se solicitan a través de una interfaz, pero no importa qué, una solicitud http es indispensable, sin mencionar que la mayoría de los servicios tienen restricciones en QPS. La siguiente tabla enumera algunas formas comunes de obtener una dirección por IP.
| Servicio de API abierta | la manera | límite | Muestra |
|---|---|---|---|
| Biblioteca de direcciones IP de Taobao | interfaz | El QPS de cada usuario debe ser inferior a 1 | curl -d "ip=218.97.9.25&accessKey=alibaba-inc" http://ip.taobao.com/outGetIpInfo |
| Mapa de Gaode | interfaz | Cada usuario tiene un límite de acceso de 100.000 por día y los desarrolladores empresariales tienen un límite de acceso de 30 millones. | curl "https://restapi.amap.com/v3/ip?ip=218.97.9.25&key=f4cf14aca974dfbb0501c582ce3fce77" |
| GeoIP | Análisis de HTML | curl -d "ip=218.97.9.25&submit=提交" https://www.geoip.com |
|
| IP pura | Análisis de HTML | curl http://www.cz88.net/ip/?ip=218.97.9.25 |
En el trabajo diario, suele ser necesario convertir una gran cantidad de registros de solicitudes de usuarios en información de ubicación del usuario para su posterior análisis. La clave de esto es la gran cantidad de datos y el procesamiento rápido. Obviamente, no podemos satisfacer nuestras necesidades diarias solicitando servicios públicos de API cada vez.
Biblioteca de IP de generación de fuerza bruta
Para las necesidades diarias, una forma sencilla y grosera es obtener la información de ubicación correspondiente a todas las IP de la red pública a través de API por adelantado. De acuerdo con los siguientes CONSEJOS, podemos estimar que si visita la biblioteca de direcciones IP de Taobao atravesará 330 millones de direcciones IP nacionales 10 años. Si se trata de un usuario empresarial de alta tecnología, tardará unos 11 días en atravesar la dirección IP nacional. Siento que estos 11 días todavía son aceptables.
CONSEJOS:
La dirección IP a la que actualmente hace referencia IPv4 se refiere a IPv4 , que utiliza una dirección de 32 bits (4 bytes), por lo que el espacio de direcciones es de aproximadamente 4.290 millones 2 3 2 = 4294967296 2 ^ 32 = 429496729623 2=4 2 9 4 9 6 7 2 9 6 Ge,
pero algunas direcciones se conservan para usos especiales, como redes privadas (aproximadamente 18 millones) y direcciones de multidifusión (aproximadamente 270 millones), lo que reduce el número de direcciones enrutadas disponibles en Internet .
Según lasestadísticas de lawiki, la cantidad de IPv4 en China alcanzó los 330 millones, mientras que la cantidad de IPv4 en los Estados Unidos fue de 1,54 mil millones.
Aquí acordamos el formato de datos de la información de ubicación: 国家|区域|省份|城市|ISPsi el campo devuelto en la interfaz no tiene la información correspondiente, el campo correspondiente se rellena con 0. Luego, podemos obtener los siguientes datos de archivo solicitando secuencialmente el servicio API (las direcciones aumentan en orden):
0.0.0.0|0|0|0|内网IP|内网IP
0.0.0.1|0|0|0|内网IP|内网IP
...
1.0.15.255|中国|0|广东省|广州市|电信
...
255.255.255.255|0|0|0|内网IP|内网IP
Siempre que tenga este archivo, puede leerlo en la memoria y guardarlo en un diccionario La clave es la dirección IP y el valor es la información de ubicación. El programa puede devolver información de ubicación en O (1) complejidad de tiempo, pero podemos calcular aproximadamente el tamaño del programa o archivo.
Supongamos que usamos utf-8 para el almacenamiento. El registro más corto es 0.0.0.0 | 0 | 0 | 0 | 0 | 0, que ocupa 17 bytes. El tamaño del archivo de la biblioteca IP es 17 * 4294967296 = 73014444032 B = 71303MB = 71GB . Este tamaño es inaceptable para cualquier programa.
Optimización del espacio
Optimización de archivos de biblioteca de IP
A partir de los datos de archivo anteriores, se encuentra que una gran cantidad de IP adyacentes tienen la misma información de ubicación (el cliente intentará conectarse cuando solicite un segmento de direcciones IP), por lo que podemos combinar dichos registros en un solo registro. Los siguientes datos de archivo (el segmento de dirección aumenta de forma secuencial):
0.0.0.0|0.255.255.255|0|0|0|内网IP|内网IP
...
1.0.8.0|1.0.15.255|中国|0|广东省|广州市|电信
...
224.0.0.0|255.255.255.255|0|0|0|内网IP|内网IP
El último ip.merge.txt de la biblioteca ip2region tiene un total de 658207 registros y el tamaño del archivo es 39 M.
Optimización de direcciones IP
A partir de los datos de archivo anteriores, se encuentra que una gran cantidad de direcciones IP se almacenan en forma de cadenas , mientras que IPv4 usa direcciones de 32 bits. Por lo tanto, convertirlo en un número entero para el almacenamiento puede ahorrar mucho espacio. Por ejemplo, la cadena más corta 0.0.0.0 ocupa 7 bytes y la cadena más larga 111.111.111.111 ocupa 15 bytes. Si lo convierte en un número entero, ambos ocupan 4 bytes . 0.0.0.0 es int (0), 111.111.111.111 es int (1869573999).
Optimización de la información de ubicación
A partir de los datos de archivo anteriores, se encuentra que la misma información de ubicación corresponde a diferentes segmentos de IP (los clientes pueden solicitar segmentos de IP en diferentes períodos de tiempo), por lo que todavía hay una gran cantidad de información de ubicación en el archivo de la biblioteca de IP, y nosotros solo puede guardarlo en la memoria Una copia de la información de ubicación, y usar el puntero o el desplazamiento de archivo + longitud de datos para obtener la información de ubicación correspondiente.
Biblioteca de IP optimizada
De acuerdo con la optimización anterior, podemos generar la biblioteca de IP final: ip2region.db, que es solo 8.1M.
La estructura de la biblioteca de PI
La estructura del archivo de biblioteca de IP ip2region.db se divide en cuatro partes: superbloque, área de índice de encabezado, área de datos y área de índice. Los detalles se muestran en la siguiente figura:
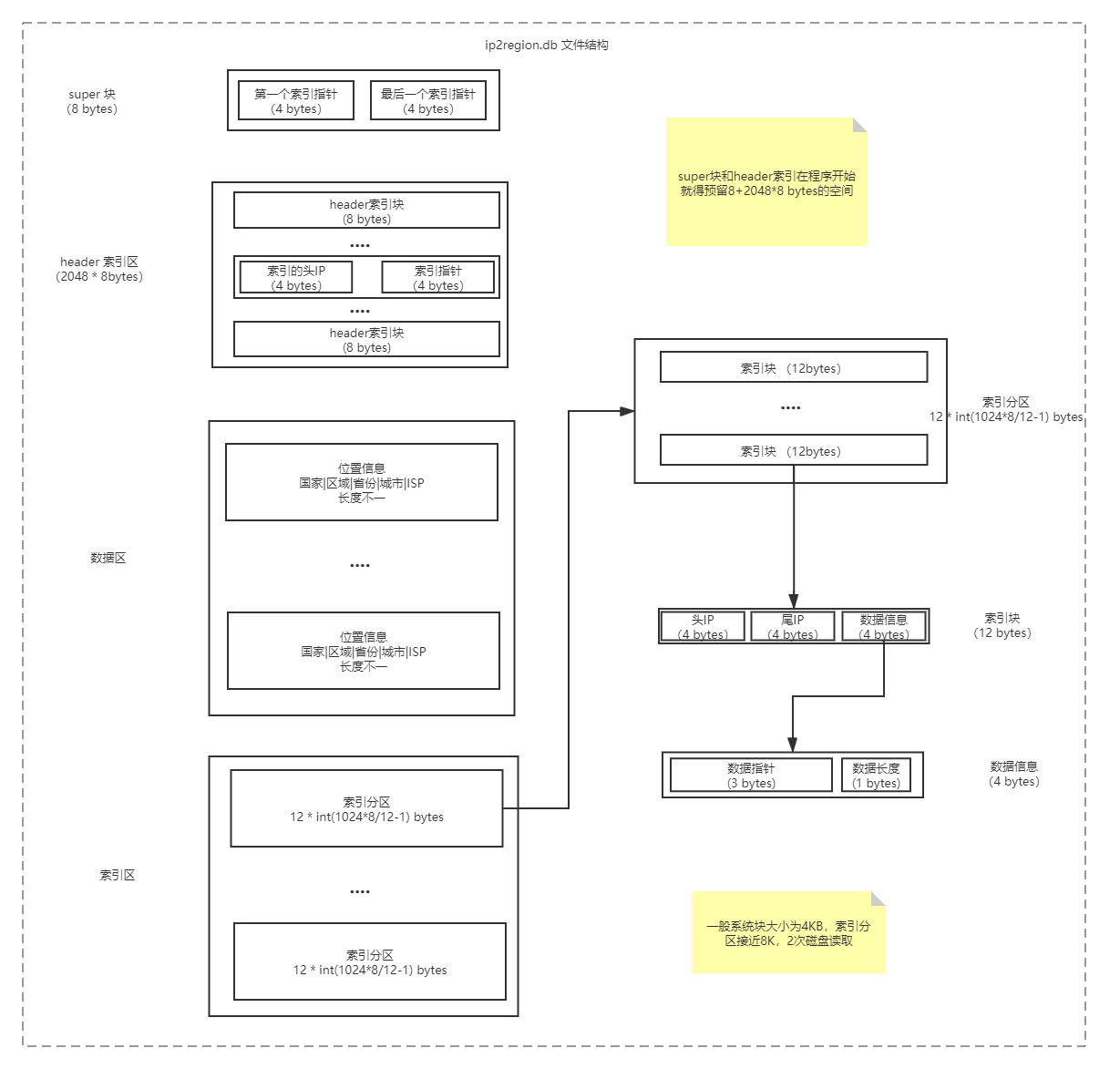
- El superbloque se
utiliza para almacenar la dirección inicial y la dirección final del第一个索引指针bloque de índice . Apunta a la posición inicial del bloque de índice, que es el primer bloque de índice de la primera partición de índice, y最后一个索引指针apunta a la posición final del índice. block -12, que es el último índice La dirección principal del último bloque de índice de la partición. De esta manera, puede leer directamente los 8 bytes del superbloque al realizar una consulta y puede obtener rápidamente el rango de direcciones del bloque de índice. - El índice de encabezado en el área de índice de encabezado
es un índice secundario del bloque de índice, específicamente para los servicios de búsqueda de árbol b +. La longitud total del área de índice dividida por la longitud de la partición de índice12*(1024*8/12-1)es el número real de índices del índice de encabezado. El tamaño de esta área es 2048 * 8 bytes, que se compone de 2048 bloques de índice de encabezado de 8 bytes. Los primeros cuatro bytes del bloque de índice de encabezado almacenan el valor de ip inicial del primer bloque de índice de cada partición de índice, y los últimos cuatro bytes apuntan a la dirección del bloque de índice.
El área de índice de encabezado se define como cercana a 16k porque puede leer el área de índice de encabezado completa a través de cuatro lecturas de disco y luego consultarla en la memoria. El resultado de la consulta puede determinar que la IP está en una partición de índice en el área de índice Luego lea la partición de índice de 8k en la memoria dos veces de acuerdo con la dirección, y luego consulte en la memoria, reduciendo así el número de lecturas de disco. - Los datos
guardados en el área de datos , el formato de los datos es el siguiente :,中国|华南|广东省|深圳市|鹏博士indicar respectivamente el país, región, provincia, ciudad, operador - Área de
índice El área de índice se compone de bloques de índice.Cada bloque de índice ocupa 12 bytes, incluida la IP inicial, la IP final y la información de datos. Los primeros tres bytes de la información de datos almacenan la dirección de datos y el último byte almacena la longitud de los datos. Cada bloque de índice corresponde a un registro en ip.merge.txt, que representa el índice de un segmento de IP.
En la búsqueda, cuando la IP especificada se encuentra entre la IP de inicio y la IP final de un bloque de índice, significa que se accedió al índice. Luego, a través de la dirección de datos y la longitud de los datos en el bloque de índice, se pueden leer los datos de información de ubicación correspondientes desde ip2region.db.
Generación de bibliotecas de IP
El proceso de generación de ip2region.db se proporciona en el almacén de Github de ip2region, que está escrito en JAVA, y su diagrama de clases es el siguiente:
[ Error en la transferencia de imagen de enlace externo, el sitio de origen puede tener un mecanismo anti-sanguijuela, es se recomienda guardar la imagen y subirla directamente (img-Wi5gW3qH-1610985591446) (https://blog.haojunyu.com/imgs/ip2region_class.svg)]
Familiarizándose con el código fuente para generar ip2region.db, describa brevemente el proceso de generación de la siguiente manera:
- Reserve un superbloque de 8 bytes y un área de índice de encabezado de 2048 * 8 bytes en el archivo a través de RandomAccessFile
- Escanee el archivo ip.merge.txt y procese cada registro de la siguiente manera:
De acuerdo con la IP de inicio, la IP de finalización y los datos de cada registro, se genera un bloque de índice, los primeros cuatro bytes almacenan la IP de inicio y los cuatro bytes del medio Después de almacenar la IP, los últimos cuatro bytes almacenan la dirección de datos calculada (escrita por RandomAccessFile, donde se mantiene un diccionario de información de ubicación a la ubicación del archivo para garantizar que la misma información de ubicación se escriba solo una vez), y el bloque de índice se guarda temporalmente. almacenado Existe en la lista vinculada indexPool. Este paso determinará toda la información de ubicación del área de datos. - Después de escanear todos los registros en ip.merge.txt, escriba todos los bloques de índice en indexPool en la parte posterior del área de datos. En este proceso, int (1024 * 8 / 12-1) = 681 bloques de índice se forman en una partición de índice, y la información de dirección e IP inicial (bloque de encabezado) del primer bloque de índice de cada partición de índice se registran y temporalmente almacenado en la lista enlazada headerPool. Además, se registrarán las posiciones inicial y final del área de índice.
- Ajuste RandomAccessFile para que apunte al principio del archivo. La posición inicial del área de índice de escritura se almacena en los primeros cuatro bytes del superbloque, y la posición final se almacena en los últimos cuatro bytes del superbloque.
- Continúe escribiendo el bloque de encabezado en headerPool en el área de encabezado.
- Ajuste RandomAccessFile para que apunte al final del archivo, escriba la marca de tiempo y la información de copyright.
CONSEJOS: Los
datos global_region.csv también se utilizan en el almacén de ip2region. Este archivo tiene 5 columnas (número de línea, región, código postal), correspondientes a la información específica de la región, que se puede completar con la información de cada ubicación en los datos. zona.
búsqueda rápida
ip2region proporciona tres algoritmos de consulta, el peor tiempo de consulta es el nivel ms. Son búsqueda binaria de memoria, búsqueda de árbol b + y búsqueda binaria. Incrementos secuenciales que requieren mucho tiempo. El diagrama de la estructura de búsqueda es el siguiente:
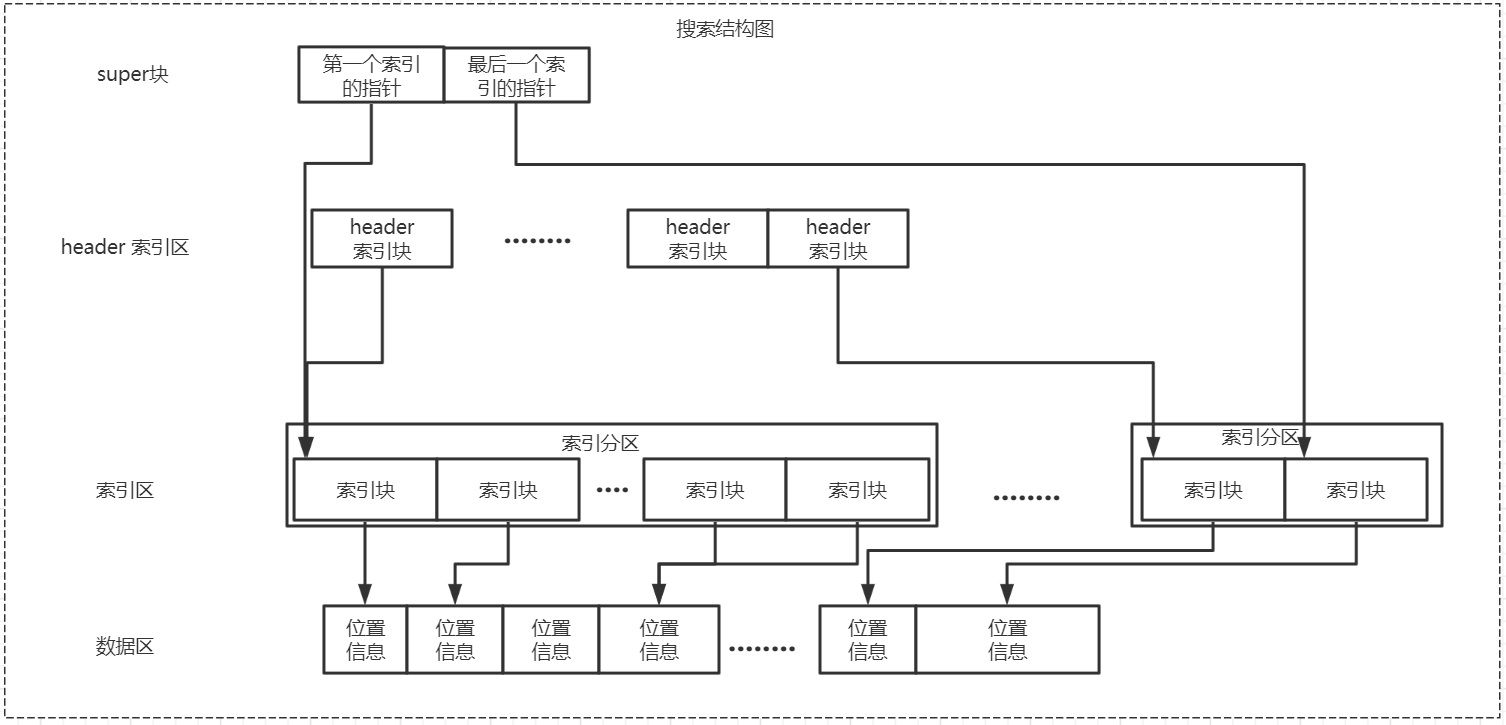
Búsqueda binaria
Las posiciones inicial y final del área de índice se pueden obtener a través del superbloque, y cada bloque de índice tiene 12 bytes, y la dirección IP en él se incrementa, por lo que la búsqueda binaria se puede usar para obtener rápidamente información de ubicación. Los pasos son los siguientes:
- Convierta el valor de IP a un número entero usando el método ip2long
- Lea el superbloque para obtener la posición inicial y la posición final del área de índice, y reste +1 para obtener el número total de bloques de índice
- Utilice la dicotomía para resolver el problema directamente, compare el tamaño de la IP inicial, la IP final y la IP actual en el bloque de índice, puede encontrar el bloque de índice correspondiente a la IP y obtener la dirección de datos y la longitud de los datos de acuerdo con el cuatro bytes detrás del bloque de índice, información de ubicación.
b + búsqueda de árbol
El área de índice de encabezado se usa en la búsqueda de árbol b +. El primer paso es usar la búsqueda binaria en el área de índice de encabezado. Después de localizar una partición de índice, use la búsqueda binaria en la partición de índice correspondiente. En comparación con la búsqueda binaria, es más rápida, porque el número de veces que se lee el disco es mucho menor que el de la búsqueda binaria. Los pasos son los siguientes:
- Convierta el valor de IP a un número entero a través de ip2long
- Utilice la dicotomía para buscar en el área de índice de encabezado y compare el bloque de índice de encabezado correspondiente y su partición de índice correspondiente.
- Lea la partición de índice correspondiente y luego ubique el bloque de índice correspondiente a través de la dicotomía para obtener información de ubicación.
Búsqueda binaria basada en memoria
Este método es similar al método de búsqueda binaria, la diferencia es que el primero lee todo ip2region.db en la memoria, mientras que el segundo lee el archivo ip2region.db continuamente.
para resumir
La biblioteca ip2region solo resuelve un problema de posicionamiento de IP muy común, pero el servicio es pequeño y rápido (por supuesto, también proporciona un cliente multilingüe), y así obtuvo una estrella de 8.4k en Github.
Pequeño uso de memoria
- La información de ubicación de las IP vecinas es la misma, y el segmento de IP se utiliza para resolver el problema de que las IP vecinas corresponden a la misma información de ubicación para evitar el almacenamiento repetido de información de ubicación.
- La IP se convierte a INT, como la cadena 111.111.111.111 se convierte a int (1869573999), se reduce de 15Byte a 4Byte
- Los diferentes segmentos de IP también tienen la misma información de ubicación, y los punteros se utilizan para señalar información de ubicación específica para garantizar que la información de ubicación solo se guarde una vez (el escaneo completo se almacena en el diccionario)
Busqueda rapida
- La IP está ordenada, utilizando búsqueda binaria para reducir la complejidad del tiempo a O (logN)
- El uso del área de índice del encabezado del índice secundario reduce la frecuencia de lectura y escritura del disco. Primero determine la partición del índice, luego determine la posición del índice a partir de la partición del índice y luego determine los datos de información de ubicación.
Soporte al cliente multilingüe
Admite java, C #, php, c, python, nodejs, extensión php (php5 y php7), golang, rust, lua, lua_c, nginx.
referencias
- Estructura y principio del archivo de la base de datos ip2region
- código fuente de ip2region
- Wikipedia para ipv4
- Lista de asignación de direcciones IPv4 en varios países
- Api del mapa de Gaode
- Baidu map api
Si este artículo es útil para usted, o si está interesado en artículos técnicos, puede seguir la cuenta pública de WeChat: Technical Tea Party. Puede recibir artículos técnicos relacionados lo antes posible, ¡gracias!

Este artículo es publicado automáticamente por ArtiPub , una plataforma de publicación múltiple.