Java multihilo
- Hilos y procesos
- Ciclo de vida del hilo
- Concepto de grupo de subprocesos y escenarios de uso de subprocesos múltiples
- Análisis de parámetros del grupo de subprocesos
- Varios métodos de implementación del grupo de subprocesos JDK Executors
- Esquema de configuración de parámetros de grupo de subprocesos
- Resumen y reflexión
- Spring boot usa grupo de subprocesos
- Referencia
Hilos y procesos
El proceso es la unidad básica del sistema para la programación y asignación de recursos, y la base del sistema operativo. Thread es la unidad más pequeña de programación del sistema y la unidad de cálculo del proceso. Un proceso puede contener uno o más hilos.
Ciclo de vida del hilo
Hay seis ciclos de vida de subprocesos: nuevo, listo y en ejecución, bloqueo, espera, temporización de espera y destrucción
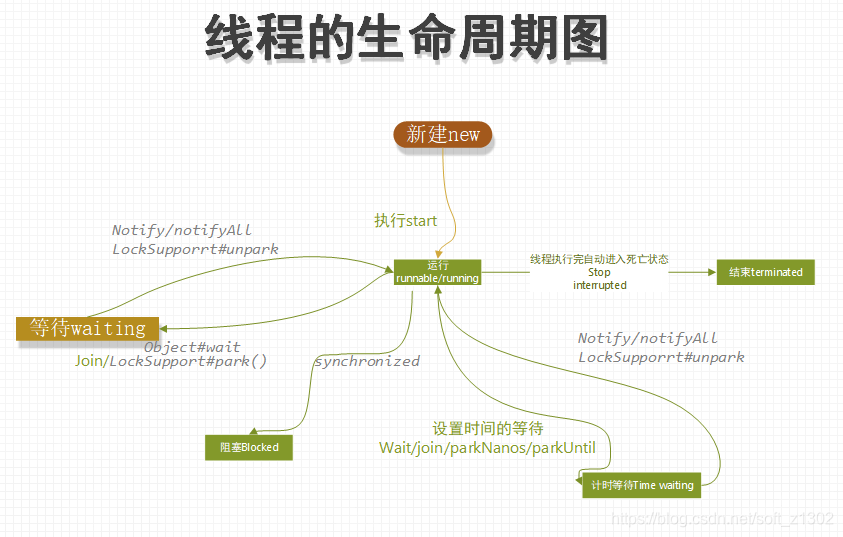
Nuevo
Hay varias formas de crear subprocesos: creación de clases de subprocesos, implementación de la interfaz Runnable, creación invocable y futura
# 1、thread
new Thread() {
@Override
public void run() {
}
}.start();
# runnable
public class RunnableThread implements Runnable {
@Override
public void run() {
System.out.println("runnable thread");
}
public static void main(String[] args){
Thread t = new Thread(new RunnableThread());
t.start();
}
}
# Callable&Future
public class CallableThread implements Callable<Integer> {
@Override
public Integer call() throws Exception {
System.out.println("Callable Thread return value");
return 0;
}
public static void main(String[] args) throws ExecutionException, InterruptedException {
FutureTask<Integer> future = new FutureTask<Integer>(new CallableThread());
new Thread(future).start();
System.out.println(future.get());
}
}
De hecho, si lo miras detenidamente, finalmente se implementa en Runnable. Interpretemos parte del código fuente de Thread juntos:
1. ¿Por qué el hilo tiene los seis estados descritos anteriormente? Este es el java.lang definido por el thread Thread object. Thread.State propiedades de enumeración
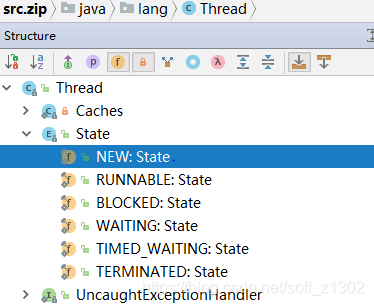
El significado y la implementación de cada estado se describen claramente en inglés. De hecho, cuando comencé a aprender los subprocesos, todavía tenía algunas preguntas. ¿Por qué necesita usar subprocesos y la diferencia entre los métodos de inicio y ejecución para ejecutar subprocesos? A continuación, interpretemos personalmente el flujo del código fuente:
线程初始化方法:
/**
* Initializes a Thread.
*
* @param g 线程组,是维护线程树的对象,所有线程必须具备的属性要素,这里可以判断线程是否具有相应的权限,以及是否合法,线程状态,是否守护线程等;目标是维护一组线程和线程组,同时我们要注意的线程之前的通讯是局限于线程组,是一组线程中维护的线程**
* @param target 运行线程的对象,线程执行时拿到的run或者call方法的目标对象
* @param name 当前线程名称
* @param stackSize 新建线程时栈大小,当为0时可忽略
*
* @param acc 上下文权限控制
*/
private void init(ThreadGroup g, Runnable target, String name,
long stackSize, AccessControlContext acc) {
// ………… 省略部分代码
/*获取安全管理策略,主要用来检查权限相关因素,若权限不满足时,抛出异常SecurityException,启动时是通过jvm参数设置[java.security.manager],具体可查看 [java API](https://docs.oracle.com/en/java/javase/15/docs/api/java.base/java/lang/SecurityManager.html)*/
SecurityManager security = System.getSecurityManager();
if (g == null) { // 当java.security.manager不设置时,这里为空
// 若需要安全管理策略,直接取得线程组
if (security != null) {
g = security.getThreadGroup();
}
// 不存在父级树寻找
if (g == null) {
g = parent.getThreadGroup();
}
}
// 检查权限
g.checkAccess();
/*
* 检测是否能被实力构造和重写
*/
if (security != null) {
if (isCCLOverridden(getClass())) {
security.checkPermission(SUBCLASS_IMPLEMENTATION_PERMISSION);
}
}
// 以便垃圾回收,增加未启动线程数
g.addUnstarted();
// 设置是否守护线程,线程优先级,安全控制,执行目标,堆栈长度以及线程id等
………… 省略部分代码
}
A continuación, explicaré la diferencia entre la ejecución directa de run y el método de inicio. La ejecución de run es el cuerpo del método de ejecución de hilo actual de la JVM existente. Ejecutar el inicio es asignar recursos al proceso donde se encuentra el jvm y crear un espacio de marco de pila para crear una nueva unidad de ejecución. Asigne el espacio del marco de la pila y así sucesivamente, llame al método de ejecución de Thread en el espacio del marco de la pila actual y luego ejecute las llamadas al método de ejecución del objetivo entrante (si está interesado, puede interpretar el método start0 de open jdk).
# Thread#run
@Override
public void run() {
if (target != null) {
target.run(); // runnable
}
}
Runable y Correr
Cuando ejecutamos iniciar después de crear un nuevo hilo, entramos en el estado listo Ejecutable. Cuando se llama al método de ejecución dentro del hilo, entra en la etapa de ejecución Ejecutando, pero la ejecución directa del método de ejecución no inicia el hilo. La verificación específica es como sigue.
public class RunStartThread extends Thread {
public RunStartThread(String name) {
super(name);
}
@Override
public void run() {
System.out.println(System.currentTimeMillis());
try {
sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
RunStartThread rst = new RunStartThread("runThread");
rst.run(); // 主线程运行run方法
rst.start(); // 启动子线程运行run
}
}
Ejecute el método de ejecución del código anterior para capturar el volcado del hilo como se muestra a continuación. Observamos que el nombre del hilo es " principal ".
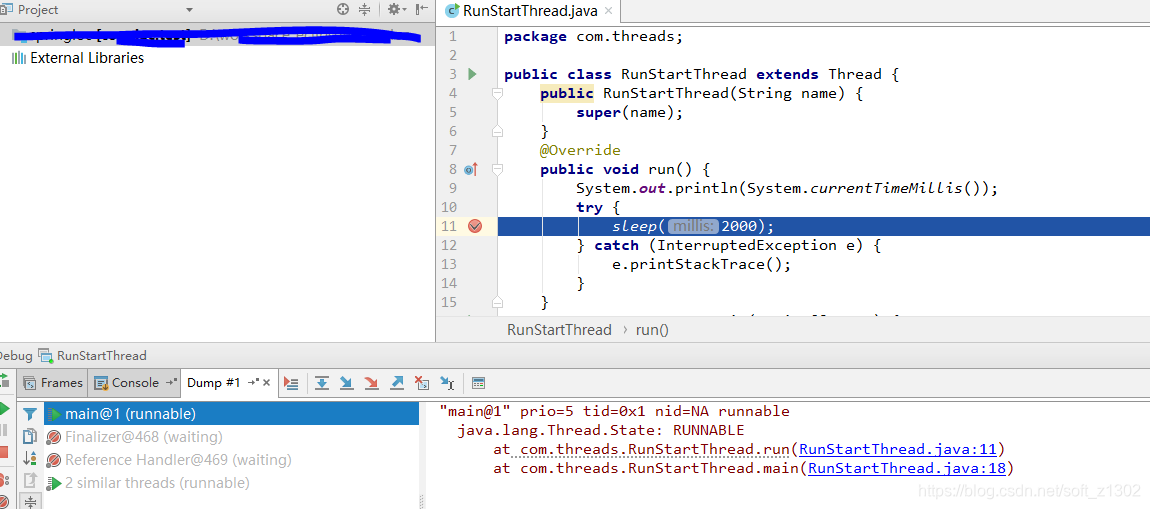
Cuando ejecutamos el método de inicio, cuando tomamos el volcado de nuevo, encontramos que el nombre del hilo que se está ejecutando actualmente es mi nombre de hilo personalizado runThread. Además, encontramos que start no llama directamente a runnable, sino que llama a start0 en la pila local para permitir que jvm maneje la programación de hilos.
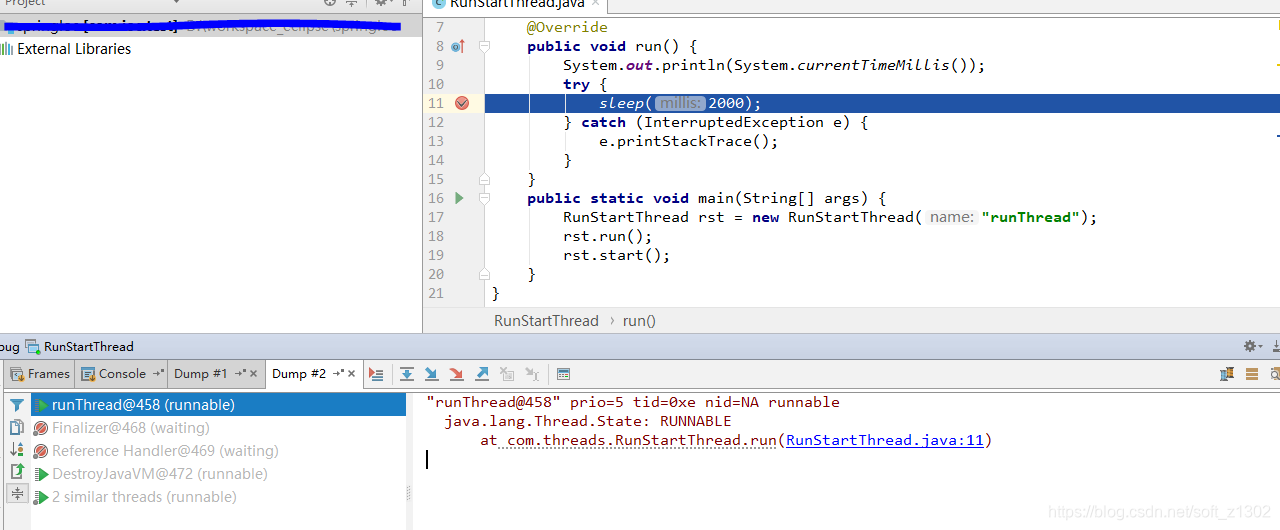
Obstruido
Cuando un hilo ingresa al estado bloqueado, generalmente espera automáticamente y luego ingresa al estado de ejecución o muere directamente. Generalmente, el bloque está sincronizado, como se muestra en el siguiente ejemplo de código. Por lo tanto, principalmente tratamos de no usar sincronizado durante el desarrollo. La razón es que la liberación automática de la tecla es incontrolable. Operación de un solo subproceso, el mismo objeto no puede ejecutarse al mismo tiempo, si realmente necesita controlar la programación de seguridad de subprocesos, intente usar Lock:
public class BlockThreads {
public static void main(String[] args) throws InterruptedException {
TestThread th = new TestThread();
th.runThread(th,"Thread1");
th.runThread(th,"Thread2");
th.runThread(th,"Thread3");
System.out.println("111");
}
private static class TestThread {
public synchronized void sayHello() throws InterruptedException {
System.out.println(System.currentTimeMillis());
Thread.sleep(3000);
}
public void runThread(TestThread th, String threadName) {
new Thread(threadName) {
@Override
public void run() {
try {
th.sayHello();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}.start();
}
}
}
Esperando
Los métodos que hacen que el subproceso espere incluyen Objeto # esperar (Objeto # notificar o Objeto # notificar recuperación de toda), Subproceso # unirse y LockSupport # estacionar (LockSupport # unpark), lo que hace que la CPU libere recursos mientras está en el estado de espera.
Tiempo de espera
Object # wait (tiempo), LockSupport # parkNanos y LockSupport # parkUntil tiempo de espera. De hecho, usamos el concepto de tiempo de espera en muchos escenarios, como el ajuste de nginx, el ajuste del tiempo de destrucción de subprocesos y la configuración del tiempo de espera de la concurrencia de solicitudes. La configuración efectiva del período de tiempo de espera es beneficiosa para aumentar el rendimiento del sistema.
Terminado
La destrucción de subprocesos incluye la destrucción automática y la destrucción manual. La destrucción automática significa que después de que el subproceso ejecuta el método de ejecución, la JVM destruirá el subproceso. La destrucción manual se puede destruir utilizando el método Thread # stop, pero este método se ha abandonado porque es un método violento, y la JVM interna puede ser La información de monitoreo tampoco se puede monitorear. El método interrumpido Thread # realiza un juicio de destrucción. Si no se puede destruir, ocurrirá una InterruptedException.
Concepto de grupo de subprocesos y escenarios de uso de subprocesos múltiples
Un subproceso es una unidad de ejecución y un grupo de subprocesos es un colectivo compuesto por un grupo de unidades de ejecución, es decir, una forma de usar subprocesos. El grupo de subprocesos se utiliza para mantener el mecanismo de inicio, toma y programación de subprocesos. En la CPU de múltiples núcleos y la programación de múltiples tareas, podemos usar el grupo de subprocesos para manejar múltiples subprocesos, aumentar el uso de la CPU mientras controlamos la alta presión de la CPU, mejorar el rendimiento y evitar bloqueos. Por ejemplo, envío de SMS, solicitud http, tarea temporizada, llamada asíncrona, etc.
Análisis de parámetros del grupo de subprocesos
El objeto de creación de subprocesos que viene con JDK es ThreadPoolExecutor. Hay varios parámetros en el objeto: número de subproceso central, número máximo de subprocesos, tiempo de supervivencia de subprocesos, fábrica de subprocesos y estrategia de rechazo de subprocesos. El siguiente código fuente
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
Varios significados específicos tienen una introducción de texto simple: el número de subprocesos centrales corePoolSize es el número de subprocesos en ejecución. Cuando el número de subprocesos al mismo tiempo es mayor que el número de subprocesos centrales, los subprocesos ingresan a la cola de espera workQueue. Cuando el La cola de espera excede la cola de espera, habrá un nuevo subproceso no central (maximumPoolSize -corePoolSize) se ejecutará. Cuando el número de subprocesos es mayor que el tamaño máximoPoolSize + workQueue #, se producirá una estrategia de rechazo. La estrategia de rechazo específica será discutido después. El equipo técnico de Tumei Group citó al equipo técnico de Meituan
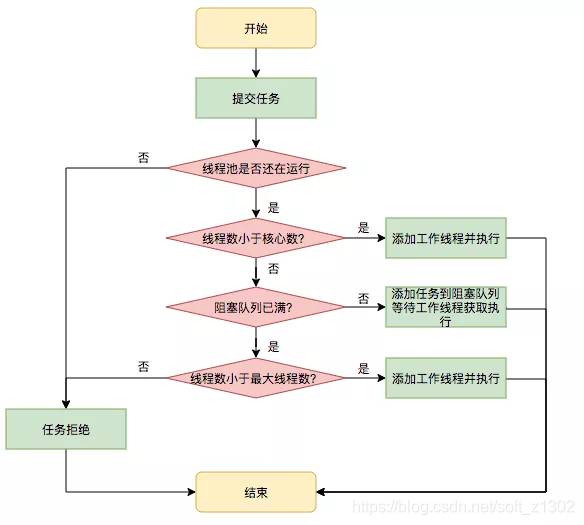
Cola de bloqueo del grupo de subprocesos BlockingQueue
Las colas de espera comunes que vienen con JDK son LinkedBlockingQueue, ArrayBlockingQueue, SynchronousQueue (además, se menciona que la longitud de la cola se puede cambiar dinámicamente, por ejemplo, la capacidad de LinkedBlockingQueue se establece en volátil)
- LinkedBlockingQueue es un almacenamiento de nodo de lista vinculada, modelo FIFO y, por supuesto, el almacenamiento de tipo de lista vinculada es ilimitado. Generalmente, cuando se establece, el número máximo de subprocesos es básicamente inválido, porque la longitud nunca excederá, a menos que ocurra una excepción OOM , se recomienda bajo la condición de alta concurrencia con una gran cantidad de subprocesos en espera. Utilice esta cola de bloqueo.
- ArrayBlockingQueue especifica la longitud de la cola de espera. Este punto es para configurar la cola de datos con mayor precisión para realizar la cola de espera.
- SynchronousQueue no tiene cola de espera de caché, y la cola siempre es 0. Esta operación es generalmente una operación ilimitada y hace un uso completo del uso de la CPU. Por ejemplo, Executors # newCachedThreadPool se implementa en el segundo método.
Fábrica de grupos de subprocesos ThreadFactory
Las fábricas de grupos de subprocesos de proyectos de código abierto comúnmente utilizadas incluyen CustomizableThreadFactory, ThreadFactoryBuilder, BasicThreadFactory. El método de fábrica establece principalmente la prioridad del subproceso y el nombre del subproceso y otros atributos del subproceso. No lo explicaré en detalle aquí. Los principales ejemplos prácticos simples son los siguientes:
ublic class ThreadFactoryTest implements ThreadFactory {
private final AtomicInteger threadCount = new AtomicInteger(0);
public static void main(String[] args) {
ExecutorService executor = new ThreadPoolExecutor(2, 2, 60L, TimeUnit.SECONDS, new LinkedBlockingDeque<Runnable>(), new ThreadFactoryTest());
executor.submit(() -> {
System.out.println(String.format("thread-Name = %s,Thread priority = %d",
Thread.currentThread().getName(), Thread.currentThread().getPriority()));
});
executor.submit(() -> {
System.out.println(String.format("thread-Name = %s,Thread priority = %d",
Thread.currentThread().getName(), Thread.currentThread().getPriority()));
});
}
/**
* @param r 传入的线程
**/
@Override
public Thread newThread(Runnable r) {
Thread th = new Thread(r);
th.setPriority(2);
th.setName("设置线程名前缀" + this.threadCount.incrementAndGet());
return th;
}
}
Estrategia de rechazo del grupo de subprocesos RejectedExecutionHandler
Políticas comunes de rechazo de JDK Política de aborto de AbortPolicy, ejecutar ejecutar cuando CallerRunsPolicy excede, descartar cuando DiscardPolicy excede, y DiscardOldestPolicy descarta el último en la cola.
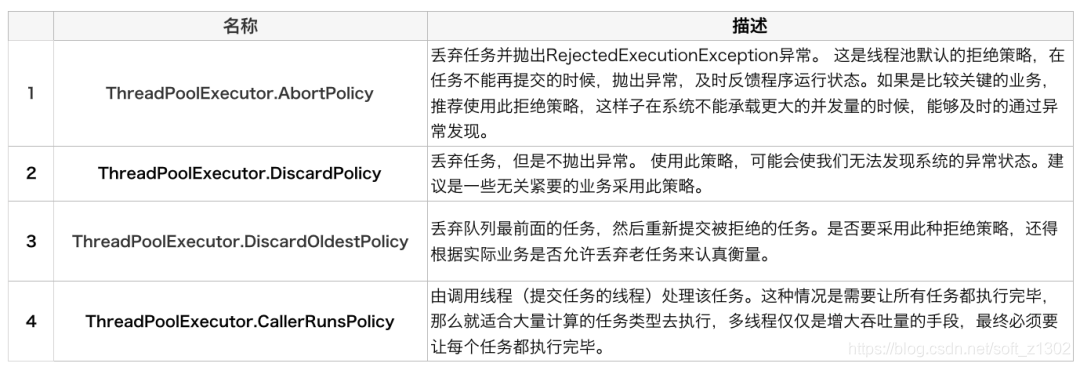
Varios métodos de implementación del grupo de subprocesos JDK Executors
Los ejecutores son herramientas (generalmente son herramientas, como matrices, sistemas, colecciones, objetos, etc.), tonterías, los ejecutores crean métodos de hilo newFixedThreadPool, newCachedThreadPool (análisis del código fuente principal de ThreadPoolExecutor) , newScheduledThreadPool, newSingleThreadExecutor, newScheduledThread.
Análisis simple del tipo de creación
newCachedThreadPool
newCachedThreadPool proporciona dos métodos de construcción para lograr, uno es construir Ejecutores # newCachedThreadPool (); sin parámetros, y el otro para construir Ejecutores # newCachedThreadPool (ThreadFactory threadFactory) con parámetros.
Ventajas: El número de hilos centrales se establece en 0, lo que significa que cuando la CPU está inactiva, los subprocesos ingresan inmediatamente Ingrese al estado de ejecución, la cola de espera es una cola de espera síncrona ilimitada SynchronousQueue, que se utiliza completamente en el caso de varias CPU. De hecho, la combinación de los dos factores anteriores muestra que el subproceso máximo La configuración del número es equivalente a inválida, así que aproveche al máximo las características de las CPU de varios núcleos.
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
Desventajas: la alta concurrencia hace que la CPU ocupe el 100%, otras tareas de subprocesos no se pueden procesar y la alta presión a largo plazo de la CPU se calentará y provocará altas temperaturas. Nuestro sistema recomienda que el uso de la CPU no supere el 80% y el uso normal no supere el 60%. Presentamos dos de los métodos de ejecución y análisis de código fuente adicional
newFixedThreadPool (análisis de código fuente adicional)
Ejecutores # newFixedThreadPool grupo de subprocesos de tamaño fijo, es decir, establecen el número de subprocesos principales para que sea el mismo que el número máximo de subprocesos. La cola de espera es una cola de espera lineal ilimitada. Una ventaja aquí es hacer un uso completo de la reutilización de hilos. En cuanto a por qué, por supuesto, es para interpretar el testimonio del código fuente:
AbstractExecutorService # el método submit crea la tarea FutureTask y llama a ThreadPoolExecutor # execute:
public Future<?> submit(Runnable task) {
if (task == null) throw new NullPointerException();
RunnableFuture<Void> ftask = newTaskFor(task, null); // 新建future任务
execute(ftask);
return ftask;
}
A continuación, nos centraremos en analizar el método de ejecución en ThreadPoolExecutor # ejecutor, que se divide en tres pasos ( un punto mencionado aquí, el número de subprocesos y el estado se pasan a través del CTL de 32 bits de AtomicInteger, los tres bits superiores son preservación del estado, y el bajo 29 es el número máximo de grupos de subprocesos ):
int c = ctl.get();/* 获取主线程状态控制29位变量 */
if (workerCountOf(c) < corePoolSize) { /* 前29位作为统计线程数,判断worker是否大于核心线程数 */
if (addWorker(command, true)) /* 添加worker工作线程,若新建成功则执行线程,并返回true */
return;
c = ctl.get(); /* 再次检测当前线程地位29 */
}
if (isRunning(c) && workQueue.offer(command)) { // worker无法获取和创建,插入等待队列
int recheck = ctl.get(); // 再次检测线程池worker大小
if (! isRunning(recheck) && remove(command)) // 若线程池不可运行状态,且移除当前线程成功,则拒绝策略
reject(command);
else if (workerCountOf(recheck) == 0) // 若当前没有线程worker,即核心线程为0,则立即执行队列
addWorker(null, false);
}
else if (!addWorker(command, false)) // 队列已经满了,则直接添加非核心线程并运行
reject(command); // 运行或者创建非核心线程失败,则拒绝策略
Del análisis anterior, se puede ver que el estado del grupo de subprocesos se guarda en los tres bits superiores y los 29 bits inferiores guardan el número de subprocesos en ejecución.
A continuación, céntrese en el trabajador y la tarea
private boolean addWorker(Runnable firstTask, boolean core) {
retry:
for (;;) {
// ……………… 省略部分代码
for (;;) {
// ……………… 省略部分代码
// 这里判断最大worker数,查看是核心线程还是最大线程,若超出范围直接返回创建worker失败
if (wc >= CAPACITY ||
wc >= (core ? corePoolSize : maximumPoolSize))
return false;
if (compareAndIncrementWorkerCount(c)) // 创建worker前检测后并增加运行线程数
break retry;
}
}
// …………
Worker w = null;
try {
// 新建worker,同时调用ThreadFactory的newThread进而线程池的参数,比如参数名称等
w = new Worker(firstTask);
final Thread t = w.thread;
if (t != null) {
final ReentrantLock mainLock = this.mainLock; // 获取线程池锁
mainLock.lock();
try {
int rs = runStateOf(ctl.get());
// 判断是否有效范围内
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
if (t.isAlive()) // precheck that t is startable
throw new IllegalThreadStateException();
workers.add(w);
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
workerAdded = true;
}
} finally {
mainLock.unlock();
}
if (workerAdded) {
t.start(); // 创建worker成功后直接调用线程的start方法执行线程,并且返回成功,调用worker启动后将会执行run方法。
workerStarted = true;
}
}
} finally {
if (! workerStarted)
addWorkerFailed(w);
}
return workerStarted;
}
Después del análisis del código, los trabajadores son en última instancia responsables de programar las tareas. Cuando el número de subprocesos es mayor que el número de subprocesos centrales, el subproceso que pasa el trabajador está vacío y las tareas que se deben ejecutar se colocan en la cola de trabajo de la cola. ( es decir, new Worker-> start worker -> runWork -> getTask -> runTask ), la verdad radica en nuestro método runWorker de la siguiente manera. Existe un " concepto de prioridad de envío ", la tarea del hilo principal se ejecuta primero! = Null y luego se ejecuta getTask (), lo que significa que el hilo con el desbordamiento de la cola se ejecuta primero. Debido a que la ejecución del código anterior explica la cola de desbordamiento y directamente addworker directamente tiene prioridad sobre la adición de la cola.
/*
worker启动时,委托给主线程的runWorker
*/
public void run() {
runWorker(this);
}
final void runWorker(Worker w) {
// ………省略部分代码
// 获取当前任务,当时非核心时且添加进队列时为null,需要从队列中获取
Runnable task = w.firstTask;
// …………
/* 当任务为空,且队列也不为空是,不执行 */
while (task != null || (task = getTask()) != null) {
try {
task.run();
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
afterExecute(task, thrown);
}
} finally {
task = null; //这个地方非常关键,执行完后队列中查找。
w.completedTasks++;
w.unlock();
}
}
Esquema de configuración de parámetros de grupo de subprocesos
Los dos factores que generalmente consideramos son CPU e IO. La configuración de los parámetros generales es para uso intensivo de CPU e IO, pero debe analizarse en combinación con escenarios comerciales reales, como tiempo de negocios, tps y otros factores para asignar subprocesos del núcleo de manera razonable Es mejor establecer dinámicamente los parámetros (JDK admite el ajuste dinámico del número de subprocesos del núcleo, el número máximo de subprocesos y la longitud de la cola de espera, combinado con la actualización dinámica del centro de configuración de apolo, como el Meituan técnica equipo ).
CPU-intensivo, el número de hilos de núcleo se establece en el número efectivo de CPUs 1, y el número máximo de hilos se establece en 2 × el número efectivo de CPUs 1, lo que puede causar un poco de animación suspendida.
El tipo de IO intensivo significa que el número de subprocesos del núcleo es 2 × el número efectivo de CPU , y el número máximo de subprocesos es 25 × el número efectivo de CPU , como sigue
Parámetros establecidos dinámicamente
Establecer dinámicamente el tamaño del grupo de subprocesos es propicio para manejar problemas de picos y ajustar los datos del grupo de subprocesos. El método adoptado es ThreadPoolExecutor # setCorePoolSize para establecer dinámicamente el número de subprocesos centrales. InterruptIdleWorkers puede borrar los trabajadores inactivos para ocupar recursos, como se muestra en el siguiente código:
public void setCorePoolSize(int corePoolSize) {
if (corePoolSize < 0)
throw new IllegalArgumentException();
int delta = corePoolSize - this.corePoolSize; // 设置的核心线程数和原来的差值
this.corePoolSize = corePoolSize;
if (workerCountOf(ctl.get()) > corePoolSize) // 工作worker是否大于设置的核心线程数,如果大于则当worker空余时清空。
interruptIdleWorkers(); // 这方法其实很重要,我们可以用来设置回收没有使用的核心线程数,
else if (delta > 0) { // 若设置线程数大于原有线程数,则看队列是否有等待线程,如果有则直接循环创建worker并执行task任务,知道worker大于最大线程数或者队列已空
// We don't really know how many new threads are "needed".
// As a heuristic, prestart enough new workers (up to new
// core size) to handle the current number of tasks in
// queue, but stop if queue becomes empty while doing so.
int k = Math.min(delta, workQueue.size());
while (k-- > 0 && addWorker(null, true)) {
if (workQueue.isEmpty())
break;
}
}
}
Resumen y reflexión
1. addWorker (Runnable firstTask, boolean core) Crea un nuevo trabajador. Cuando el parámetro firstTask de este método está vacío, la función de precalentamiento es similar a la carga diferida de primavera.
2. setCorePoolSize establece dinámicamente el número de subprocesos principales
3. setMaynamumPoolSize dinámicamente establece el número máximo de subprocesos
4, intensivo en CPU e IO
5, tareas de ejecución de trabajador runWorker
6, interruptIdleWorkers destruyen subprocesos centrales inactivos
7, Ejecutores crean métodos de subprocesos newFixedThreadPool, newCachedThreadPool, newScheduledThreadPool, newSingleThreadExecutor
8, ejecuta y envía prioridad de ejecución y envío prioridad y dos La diferencia es que hay valores de retorno y así sucesivamente.
9. Varias formas de crear subprocesos: subproceso, ejecutable, invocable y futuro, y el estado de los subprocesos, el uso de depuración de pila JVM
10. Subprocesos de bloqueo comunes LinkedBlockingQueue, ArrayBlockingQueue, SynchronousQueue
11. Fábricas de subprocesos comunes CustomizableThreadFactory, ThreadFactoryBuilder, BasicThreadFactory y propósito
12. Varias clases de implementación comunes de RejectedExceptionHandler AbortPolicy, CallerRunsPolicy, DiscardPolicy, DiscardOldestPolicy
13. Cómo establecer dinámicamente el número de subprocesos centrales y el número máximo de subprocesos y la cola de bloqueo
14. ¿Cuáles son los significados de ThreadGroup y securityManager
15. Adición de seguimiento ............. .....
Spring boot usa grupo de subprocesos
La producción aquí es simple y práctica, y el uso detallado debe combinarse con la escena real:
@SpringBootTest
@EnableAsync
class PoolApplicationTests {
@Autowired
private PoolService poolService;
@Test
void contextLoads() {
poolService.say1();
poolService.say2();
}
}
@Service
public class PoolService {
@Value("${spring.pool.core.size:5}")
private int coreSize;
@Value("${spring.pool.max.size:10}")
private int maxNumSize;
/**
* 自定义线程池
*
* @return
*/
@Bean("executor")
public Executor executor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(coreSize);
executor.setMaxPoolSize(maxNumSize);
executor.setQueueCapacity(20);
executor.initialize();
return executor;
}
/**
* 在目标线程池执行任务
*/
@Async(value = "executor")
public void say1() {
System.out.println(Thread.currentThread().getName());
}
@Async(value = "executor")
public void say2() {
System.out.println(Thread.currentThread().getName());
}
}
Referencia
[1] Código fuente JDK 1.8
[2] Equipo técnico de Meituan (citas de imágenes parciales y puntos de conocimiento)
[3] Hilo y proceso Enciclopedia de Baidu