Función de pérdida:
 La función de pérdida es la diferencia entre el resultado y calculado por la propagación hacia adelante y la respuesta estándar conocida y_
La función de pérdida es la diferencia entre el resultado y calculado por la propagación hacia adelante y la respuesta estándar conocida y_
El objetivo de optimización de la red neuronal es encontrar un cierto conjunto de parámetros de modo que el resultado calculado y esté infinitamente cerca de la respuesta estándar conocida y_, es decir, la diferencia entre su valor de pérdida es la más pequeña.
Hay tres métodos de cálculo para pérdida de corriente principal:
error promedio (mse) entropía cruzada
personalizada
(ce)
1. Error medio
Es el cuadrado de la diferencia entre el resultado y del cálculo de propagación hacia adelante y la respuesta estándar conocida y_. Encuentra el promedio de nuevo.
Ejemplo 1:
separo el código
import tensorflow as tf
import numpy as np
SEED = 23455
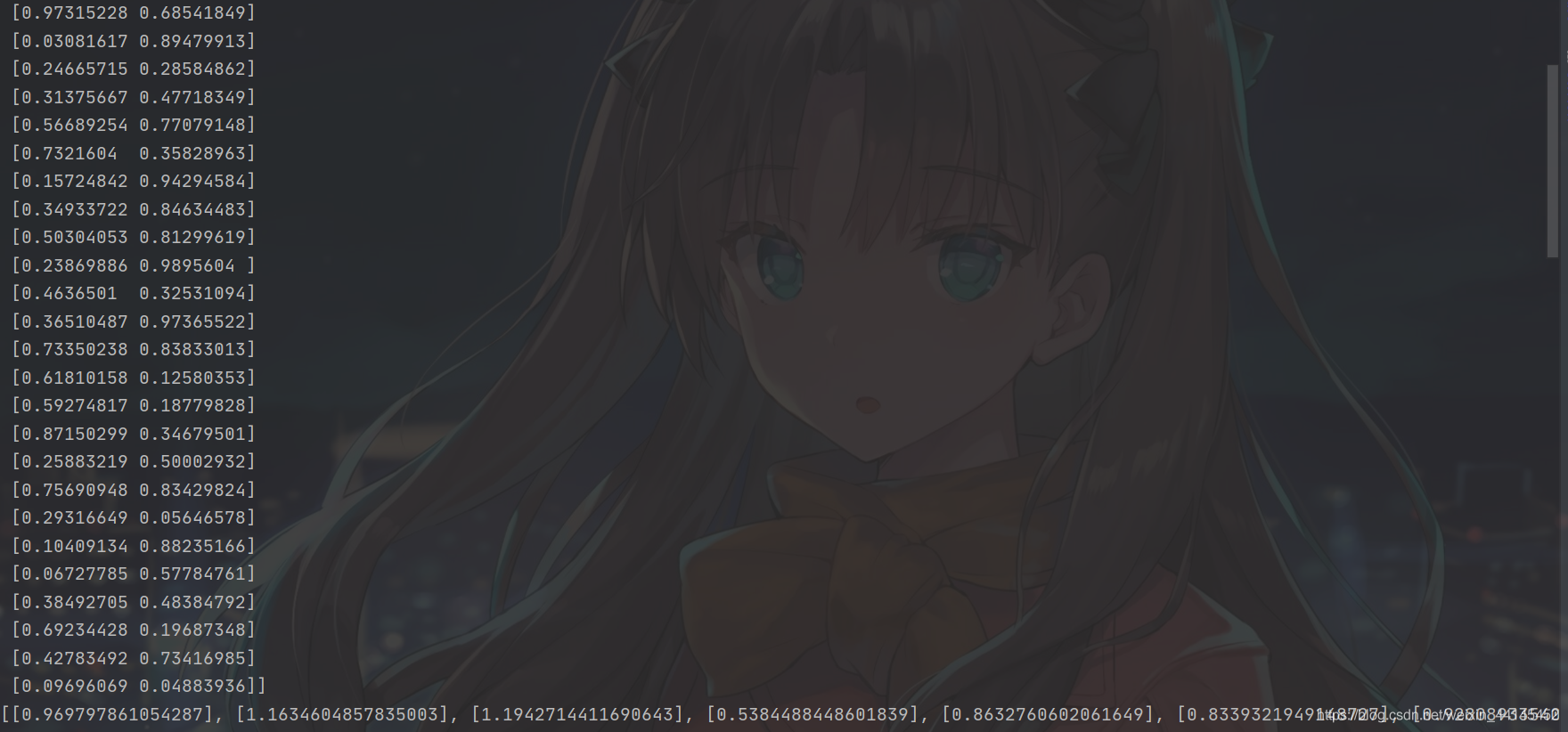
rdm = np.random.RandomState(seed=SEED) # 生成[0,1)之间的随机数
x = rdm.rand(32, 2) # 生成32行2列的输入特征x,包含了32组0到1之间的随机数x1和x2
print(x)
y_ = [[x1 + x2 + (rdm.rand() / 10.0 - 0.05)] for (x1, x2) in x]
print(y_)
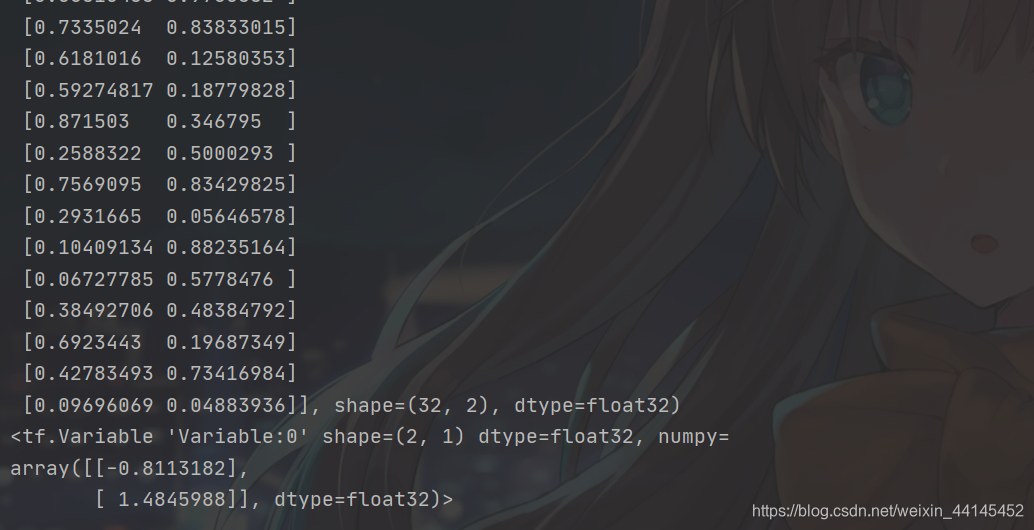
x = tf.cast(x, dtype=tf.float32) # x转变数据类型
print(x)
w1 = tf.Variable(tf.random.normal([2, 1], stddev=1, seed=1)) # 随机初始化参数w1,初始化为2行1列,并设置标准差是1
print(w1)
Primero genere datos aleatorios y conviértalos en tensor.
Resultado de salida:
for epoch in range(epoch):
with tf.GradientTape() as tape:
y = tf.matmul(x, w1) # 求前向传播计算结果y, 矩阵x乘以矩阵w1
loss_mse = tf.reduce_mean(tf.square(y_ - y)) # 求均方误差损失函数loss_mse
grads = tape.gradient(loss_mse, w1) # 损失函数对带训练参数w1求偏导
w1.assign_sub(lr * grads) # 更新参数w1
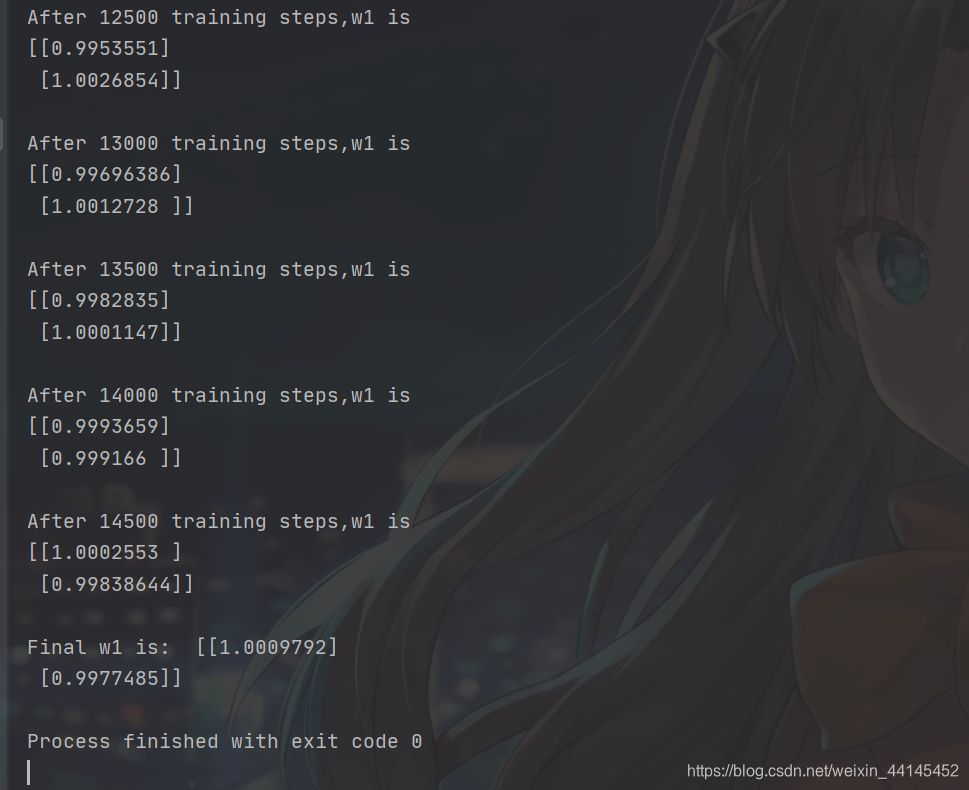
if epoch % 500 == 0: # 每迭代500轮,打印当前的参数w1
print("After %d training steps,w1 is " % (epoch))
print(w1.numpy(), "\n")
print("Final w1 is: ", w1.numpy())
con tf.GradientTape () como cinta Gradiente con API derivada automática de Tensorflow
2. Función de pérdida personalizada:

import tensorflow as tf
import numpy as np
SEED = 23455
COST = 1
PROFIT = 99
rdm = np.random.RandomState(SEED)
x = rdm.rand(32, 2)
y_ = [[x1 + x2 + (rdm.rand() / 10.0 - 0.05)] for (x1, x2) in x] # 生成噪声[0,1)/10=[0,0.1); [0,0.1)-0.05=[-0.05,0.05)
x = tf.cast(x, dtype=tf.float32)
w1 = tf.Variable(tf.random.normal([2, 1], stddev=1, seed=1))
epoch = 10000
lr = 0.002
for epoch in range(epoch):
with tf.GradientTape() as tape:
y = tf.matmul(x, w1)
loss = tf.reduce_sum(tf.where(tf.greater(y, y_), (y - y_) * COST, (y_ - y) * PROFIT))#让预测的y多了时损失成本,预测的y少了是损失利润
grads = tape.gradient(loss, w1)
w1.assign_sub(lr * grads)
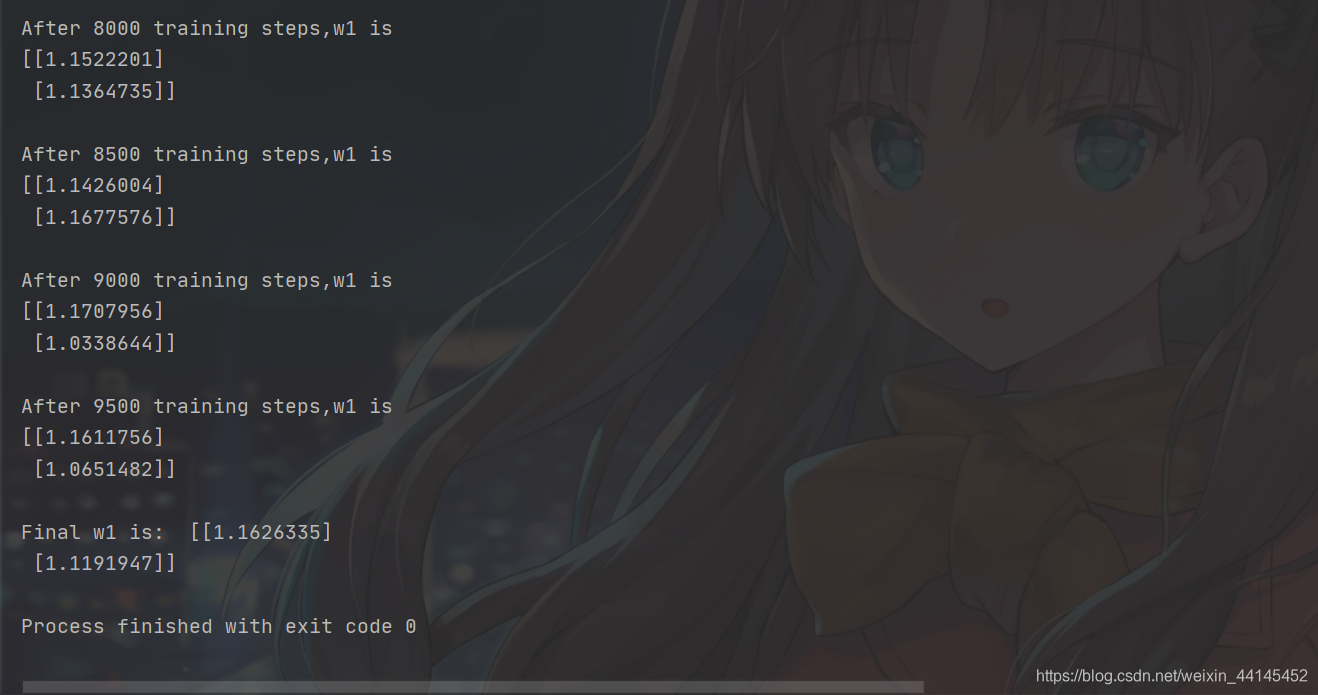
if epoch % 500 == 0:
print("After %d training steps,w1 is " % (epoch))
print(w1.numpy(), "\n")
print("Final w1 is: ", w1.numpy())
# 自定义损失函数
# 酸奶成本1元, 酸奶利润99元
# 成本很低,利润很高,人们希望多预测些,生成模型系数大于1,往多了预测
La función ajustada es el volumen de ventas y = 1,16 X1 + 1,12 X2, los coeficientes son demasiado grandes y todos son mayores que el coeficiente del error cuadrático medio como función de pérdida
3. Función de pérdida de entropía cruzada:
 La entropía cruzada puede representar la distancia entre dos distribuciones de probabilidad. Entropía cruzada, cuanto más alejadas están las dos distribuciones de probabilidad, menor es la entropía cruzada y más cercanas están las dos distribuciones de probabilidad La distribución de probabilidad
La entropía cruzada puede representar la distancia entre dos distribuciones de probabilidad. Entropía cruzada, cuanto más alejadas están las dos distribuciones de probabilidad, menor es la entropía cruzada y más cercanas están las dos distribuciones de probabilidad La distribución de probabilidad
y_ (1, 0) de la
respuesta estándar tiene dos elementos, lo que indica dos clasificaciones.
El primer elemento es 1, lo que significa que la probabilidad de la primera situación es 100%
. El primer elemento es 0, lo que significa que la probabilidad de la primera situación es 0. La
red neuronal predice dos conjuntos de probabilidades y1 e y2. la probabilidad corresponde a y_ Cuando
 realizamos el problema de clasificación, generalmente usamos la función softmax primero para hacer que el resultado de salida se ajuste a la distribución de probabilidad, y luego encontramos la función de pérdida de entropía cruzada para
realizamos el problema de clasificación, generalmente usamos la función softmax primero para hacer que el resultado de salida se ajuste a la distribución de probabilidad, y luego encontramos la función de pérdida de entropía cruzada para
comprender la función softmax en un minuto (súper simple)
TensorFlow proporciona una forma de calcular la distribución de probabilidad y La función de entropía cruzada
tf.nn.softmax_cross_entropy_with_logits (y_, y)

Como se puede ver en este ejemplo, la oración loss_ce2 puede reemplazar las dos oraciones y_pro y loss_ce1, y el cálculo de probabilidad la distribución y la entropía cruzada se pueden completar al mismo tiempo