Comprensión en profundidad de Flink Checkpoint
- Cómo entender el estado en flink
- Comprensión del caso del estado de flink (estado)
- Por qué es necesaria la gestión estatal
- Qué información se guarda en el punto de control
- En el caso de múltiples paralelismo y múltiples operadores, el proceso CheckPoint
- ¿Qué es la alineación de barreras?
- ¿Qué es la desalineación de la barrera?
- caso de estudio
- Preguntas más frecuentes
Cómo entender el estado en flink
- El estado generalmente se refiere a los datos almacenados en el procesamiento de varios elementos / eventos por las funciones de estado y los operadores en flink (nota: los datos de estado pueden modificarse y consultarse, y pueden mantenerse por sí mismos. Según sus propios escenarios comerciales, guarde los datos históricos o resultados intermedios al estado (estado);
Ejemplo de uso de cálculo de estado:
- Cuando la aplicación busca ciertos patrones de eventos, el estado almacenará la secuencia de eventos encontrados hasta el momento.
- Al agregar eventos cada minuto / hora / día, el estado guarda la agregación pendiente.
- Al entrenar un modelo de aprendizaje automático en una secuencia de puntos de datos, el estado mantiene la versión actual de los parámetros del modelo.
- Cuando es necesario administrar datos históricos, el estado permite el acceso efectivo a eventos pasados.
Comprensión del caso del estado de flink (estado)
- La computación sin estado se refiere al hecho de que cuando los datos ingresan a Flink y pasan a través del operador, solo es necesario procesar los datos actuales para obtener el resultado deseado; la computación con estado requiere algún estado histórico u operaciones relacionadas para calcular el resultado correcto ;
Ejemplos de computación sin estado:
- Por ejemplo: simplemente realizamos un empalme de cadenas, entrada a, salida a_666, entrada b, salida b_666 El resultado de salida no tiene nada que ver con el estado anterior, que es idempotente.
Idempotencia: el resultado de una solicitud o múltiples solicitudes iniciadas por el usuario para la misma operación es consistente, y no habrá efectos secundarios debido a múltiples clics;
Ejemplos de computación con estado:
- Tome el cálculo de pv / uv en el recuento de palabras como ejemplo: el
resultado de salida está relacionado con el estado anterior y no se ajusta a la idempotencia. Si lo visita varias veces, pv aumentará;
Por qué es necesaria la gestión estatal
Los trabajos de transmisión se caracterizan por ejecutarse 7 * 24 horas, los datos no son consumo repetido, no se pierden, solo se garantiza un cálculo, la salida de datos en tiempo real no se retrasa, pero cuando el estado es grande, la capacidad de memoria es limitada o la instancia se bloquea o es necesaria En el caso de la concurrencia extendida, cómo garantizar la correcta gestión del estado y la correcta ejecución de la tarea cuando la tarea se ejecuta de nuevo, la gestión del estado es particularmente importante
La gestión estatal ideal es:
- Flink, fácil de usar, proporciona una rica estructura de datos, una interfaz simple y fácil de usar;
- Eficiente, flink lee y escribe el estado rápidamente, se puede escalar horizontalmente y guardar el estado no afecta el rendimiento informático;
- Fiable, flink puede hacer que el estado sea persistente y puede garantizar una semántica exactamente una vez;
Proceso de ejecución del punto de control en flink
- El mecanismo de punto de control es la piedra angular de la confiabilidad de Flink. Puede garantizar que cuando un determinado operador falla debido a algunas razones (como una salida anormal), el clúster de Flink puede restaurar el estado de todo el diagrama de flujo de la aplicación a un estado anterior al error de garantizar la coherencia de la aplicación del estado del diagrama de flujo. El principio del mecanismo de punto de control de Flink proviene del algoritmo del "algoritmo de Chandy-Lamport". (Cálculo de instantáneas distribuidas)
- Cuando se inicia cada aplicación que necesita un punto de control, JobManager de Flink crea un Coordinador de punto de control para ella, y el Coordinador de punto de control es el único responsable de hacer la instantánea de esta aplicación.
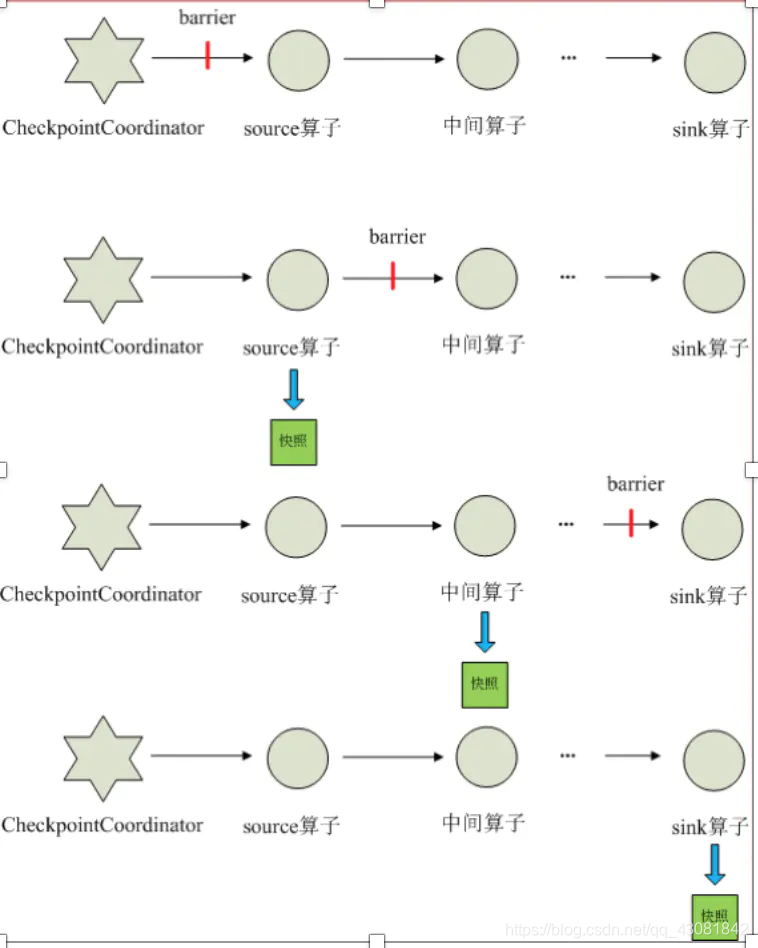
- CheckpointCoordinator envía periódicamente barreras a todos los operadores de origen de la aplicación de flujo.
- Cuando un operador de origen recibe una barrera, suspende el proceso de procesamiento de datos, luego hace una instantánea de su estado actual y la guarda en el almacenamiento persistente designado, y finalmente informa su producción de instantáneas a CheckpointCoordinator y al mismo tiempo a sí mismo Todo en sentido descendente Los operadores difunden la barrera y reanudan el procesamiento de datos.
- Una vez que el operador descendente recibe la barrera, suspenderá su propio proceso de procesamiento de datos y luego hará una instantánea de su propio estado relacionado, la guardará en el almacenamiento persistente designado y, finalmente, informará su propia instantánea a CheckpointCoordinator, y al mismo tiempo. tiempo a todos sus operadores posteriores. El niño transmite la barrera para reanudar el procesamiento de datos.
- Cada operador crea continuamente una instantánea de acuerdo con el paso 3 y la transmite corriente abajo, hasta que se pasa la barrera al operador del fregadero y se completa la instantánea.
- Cuando CheckpointCoordinator recibe reportes de todos los operadores, considera que la instantánea del ciclo se realizó con éxito; de lo contrario, si no recibe reportes de todos los operadores dentro del tiempo especificado, se considera que la instantánea de este ciclo ha fallado;
Qué información se guarda en el punto de control
- ¿Cuáles son las funciones específicas que realiza CheckPoint? ¿Por qué se puede reanudar la tarea a través de CheckPoint después de suspender la tarea?
- CheckPoint guarda el estado en ciertos momentos del historial tomando una instantánea del programa. Cuando la tarea se cuelga, la restaurará desde la última instantánea completa por defecto. La pregunta es, ¿qué diablos es una instantánea? ¿Puedes comerlo?
- SnapShot se traduce como una instantánea, lo que significa guardar cierta información en el programa, que se puede usar para restaurarla más tarde. Para una tarea de Flink,
¿Qué información se almacena en la instantánea? Tome el recuento de palabras de los datos de kafka consumidos por flink como ejemplo:
- Leemos un fragmento de registro de Kafka, analizamos el app_id del registro y luego colocamos el resultado estadístico en un mapa establecido en la memoria, con app_id como clave y el pv correspondiente como valor. Solo necesitas el app_id correspondiente cada uno. tiempo. Ponga el valor pv de +1 en el mapa;
- tema de kafka : prueba ;
- El proceso de cálculo de flink es el siguiente:

El tema de Kafka tiene una y solo una partición
- Suponga que la prueba de tema de Kafka tiene solo una partición, y la tarea Fuente de Flink registra las compensaciones de todas las particiones consumidas actualmente en el tema de prueba de Kafka
例:(0,1000)表示0号partition目前消费到offset为1000的数据
- La tarea de PV de flink registra el valor de PV de cada aplicación calculada actualmente. Para la comodidad de la explicación, tengo dos aplicaciones aquí: app1, app2
例:(app1,50000)(app2,10000)
表示app1当前pv值为50000
表示app2当前pv值为10000
每来一条数据,只需要确定相应app_id,将相应的value值+1后put到map中即可;
En este caso, ¿qué información registró CheckPoint?
- Lo que se registra es en realidad la información de compensación consumida por CheckPoint por enésima vez y la información del valor pv de cada aplicación. Registre la información de estado actual de CheckPoint que ocurrió y guarde la información de estado en el backend de estado correspondiente. (Nota: el backend del estado es el lugar para guardar el estado. Decide cómo guardar el estado y cómo garantizar que el estado esté altamente disponible. Solo necesitamos saber que podemos obtener la información de compensación y la información de pv del estado El backend de estado debe ser alto Disponible, de lo contrario, nuestro backend de estado a menudo falla, lo que resultará en la imposibilidad de restaurar nuestra aplicación a través del punto de control).
Ejemplo:
chk-100
offset: (0, 1000)
pv: (app1, 50000) (app2, 10000)
Esta información de estado indica que en el punto de control 100, el offset de la partición 0 ha consumido 1000 y el resultado de las estadísticas de pv es (app1, 50000) (app2, 10000) La
tarea está colgada, ¿cómo restaurarla?
- Supongamos que establecemos un CheckPoint cada tres minutos, y después de guardar el estado de CheckPoint del chk-100 mencionado anteriormente, después de diez segundos, el desplazamiento se ha consumido a (0, 1100) y el resultado de las estadísticas pv se convierte en (app1, 50080) (App2, 10020), pero de repente la tarea se bloquea, ¿qué debo hacer?
- No entre en pánico, en realidad es muy simple. Flink solo necesita consumir del desplazamiento (0, 1000) guardado por el CheckPoint exitoso más reciente. Por supuesto, el valor de pv también debe seguir el valor de pv en el estado (app1, 50000 ) (app2, 10000)) Para la acumulación, no se puede acumular desde (app1, 50080) (app2, 10020), porque cuando el consumo de compensación de la partición 0 llega a 1000, el resultado de las estadísticas de PV es (app1, 50000) (app2, 10000 )
- Por supuesto, si desea recuperarse del estado de offset (0, 1100) pv (app1, 50080) (app2, 10020), no puede hacerlo, porque el programa se cuelga repentinamente en ese momento y este estado es no guardado en absoluto. La forma más eficiente que podemos hacer es recuperarnos del último CheckPoint exitoso, que es lo que siempre he llamado chk-100;
La explicación anterior es básicamente el trabajo realizado por CheckPoint, y la escena descrita es relativamente simple.
- Pregunta, la tarea de calcular pv siempre se está ejecutando, ¿cómo sabe cuándo tomar esta instantánea? En otras palabras, ¿cómo garantiza la tarea que calcula pv que el valor de pv (app1, 50000) (app2, 10000) calculado por sí mismo sea el resultado estadístico en el momento del desplazamiento (0, 1000)?
Flink agrega una cosa llamada barrera a los datos (barrera traducción al chino: barrera) Hay dos barreras en el círculo rojo en la figura siguiente;
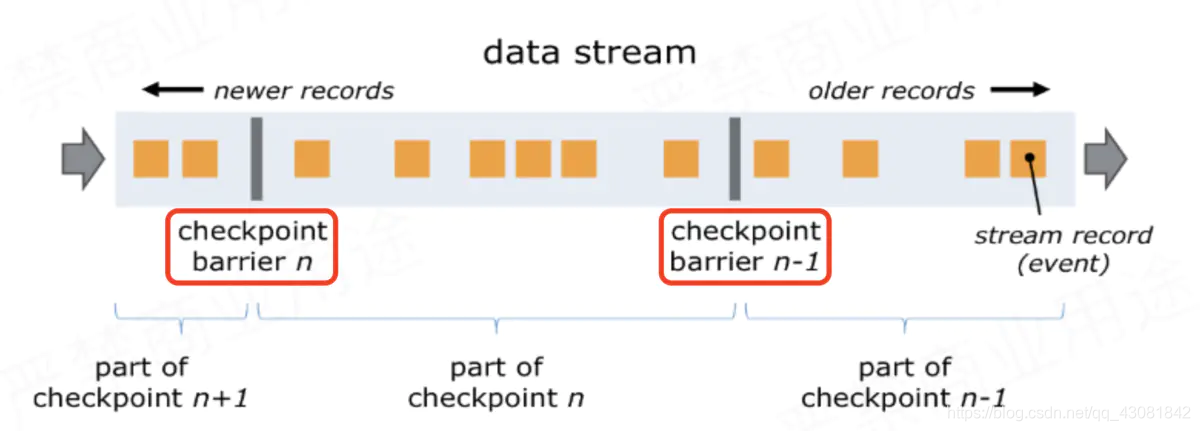
- La barrera se genera a partir de la Tarea de origen y fluye a la Tarea de sumidero, durante la cual todas las tareas se activarán para tomar una instantánea siempre que encuentren la barrera;
- La instantánea tomada en la barrera CheckPoint n-1 se refiere a todos los datos de estado del trabajo desde el inicio hasta la barrera n-1;
- La instantánea tomada en la barrera n se refiere a todos los datos de estado desde el inicio del trabajo hasta el procesamiento de la barrera n;
- En correspondencia con el caso pv, después de que la Tarea de origen recibió la solicitud de activación de CheckPoint de JobManager con el número chk-100, descubrió que recibió los datos en el desplazamiento de kafka (0, 1000), por lo que iría al desplazamiento (0, 1000) Después de eso, inserte una barrera antes de los datos de desplazamiento (0, 1001) y luego comience a tomar una instantánea por sí mismo, es decir, guarde el desplazamiento (0, 1000) en el backend de estado chk-100. Luego, la barrera se envía en sentido descendente. Cuando la tarea PV recibe la barrera, también suspenderá el procesamiento de datos y guardará la información PV (app1, 50000) (app2, 10000) almacenada en su memoria en el estado backend chk-100. De acuerdo, flink probablemente use este principio para guardar instantáneas;
- La tarea de la estadística PV recibe la barrera, lo que significa que los datos anteriores a la barrera han sido procesados, por lo que no habrá pérdida de datos.
- El papel de la barrera es separar los datos. En el proceso de CheckPoint, hay una instantánea de sincronización que no puede procesar los datos después de la barrera. ¿Por qué?
- Si los datos se procesan mientras se toma la instantánea, los datos procesados pueden modificar el contenido de la instantánea, por lo tanto, primero haga una pausa en el procesamiento de los datos y guarde la instantánea en la memoria antes de procesar los datos.
- En términos del caso, la tarea que cuenta PV quiere tomar una instantánea de (app1, 50000) (app2, 10000), pero si los datos aún se están procesando, es posible que la instantánea aún no se haya guardado y el estado sea ( app1, 50001) (app2, 10001), la instantánea no es precisa y no se puede garantizar Exactly Once;
Interacción de estado en la computación de flujo:
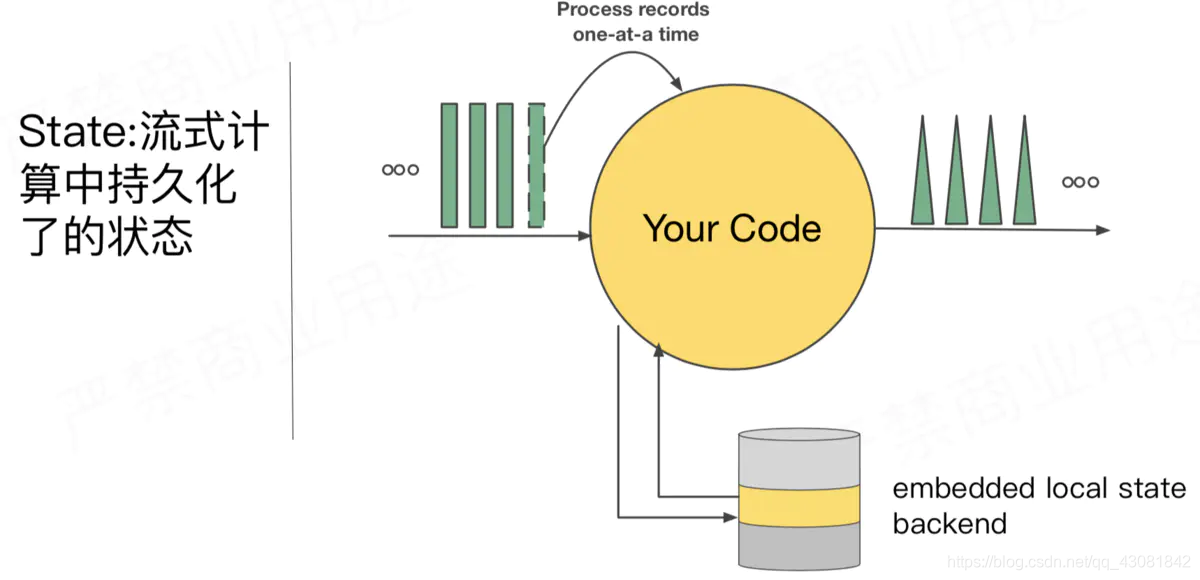
escenario simple, método preciso de tolerancia a fallas de una sola vez: instantáneas periódicas de compensación de consumo e información de estado estadístico o resultados estadísticos. Al
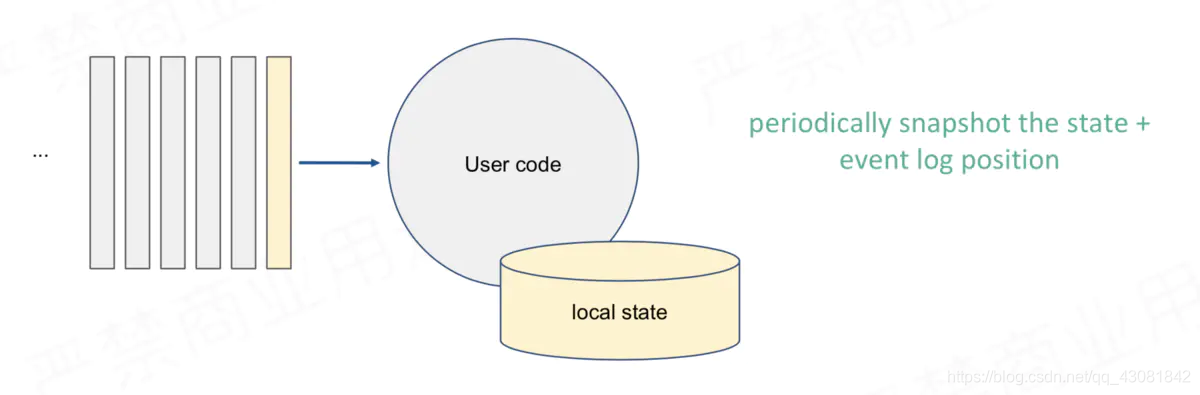
consumir en la posición X, guardar el estado correspondiente a X cuando se
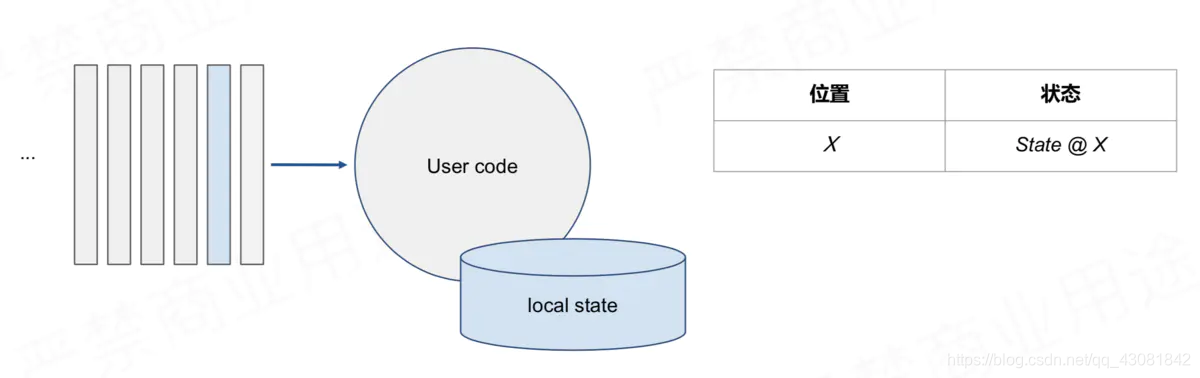
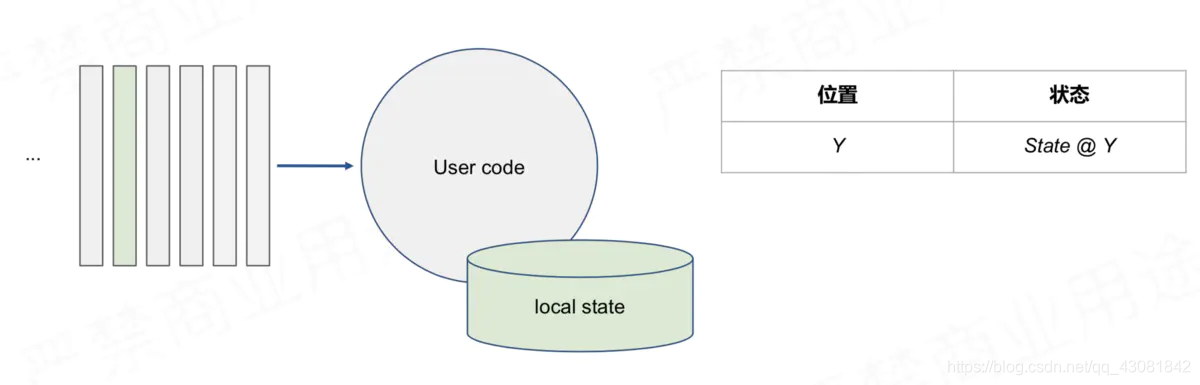
consume en la posición Y, Guardar el estado correspondiente a Y
En el caso de múltiples paralelismo y múltiples operadores, el proceso CheckPoint
Problemas y desafíos que enfrenta la tolerancia a fallas de estado distribuido
- ¿Cómo asegurar que el estado tenga una garantía precisa de tolerancia a fallas?
- ¿Cómo generar una instantánea globalmente consistente para múltiples operadores con el estado local en un escenario distribuido?
- ¿Cómo generar instantáneas sin interrumpir operaciones?
En el caso de múltiples paralelismos y múltiples instancias de Operador, ¿cómo hacer una instantánea globalmente consistente?
- Todos los operadores tomarán una instantánea de su propio estado después de encontrar la barrera durante el proceso de ejecución y la guardarán en el estado correspondiente. El back-end
corresponde al caso de PV: algunos operadores calculan el PV de app1 y algunos operadores calculan el PV de la aplicación 2. Cuando se encuentran con la barrera, todos necesitan hacer una instantánea de las estadísticas actuales de la información PV en el backend del estado.
Instantánea simple de múltiples gráficos paralelos y
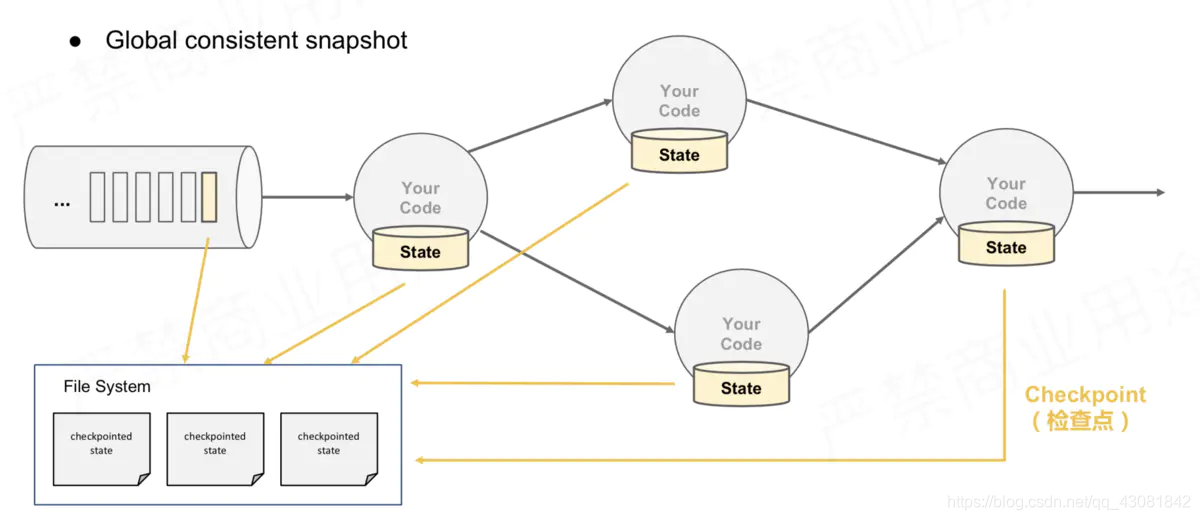
recuperación de estados de múltiples operadores
¿Cómo hacer esta instantánea? Toda la política de barrera antes de usar
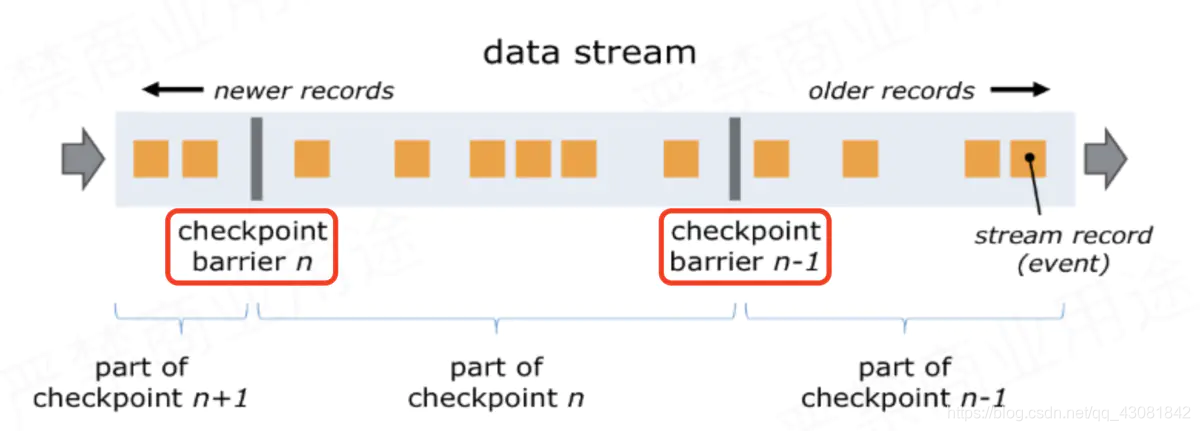
JobManager envía la tarea de origen CheckPointTrigger, la barrera de CheckPoint de la tarea de origen se colocará en el flujo de datos; la
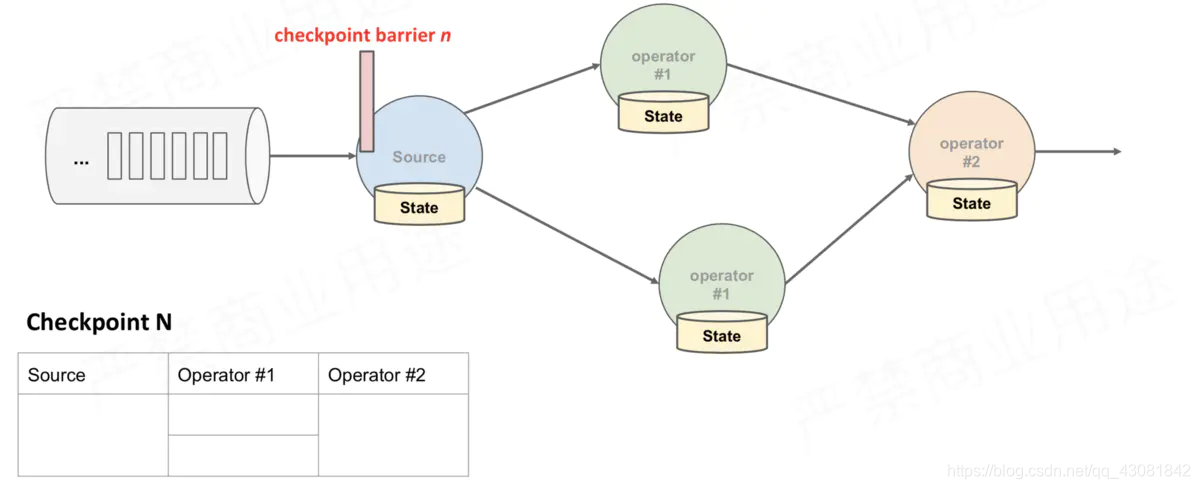
tarea de origen en sí misma para hacer una instantánea y se guardará en el estado de back-end;
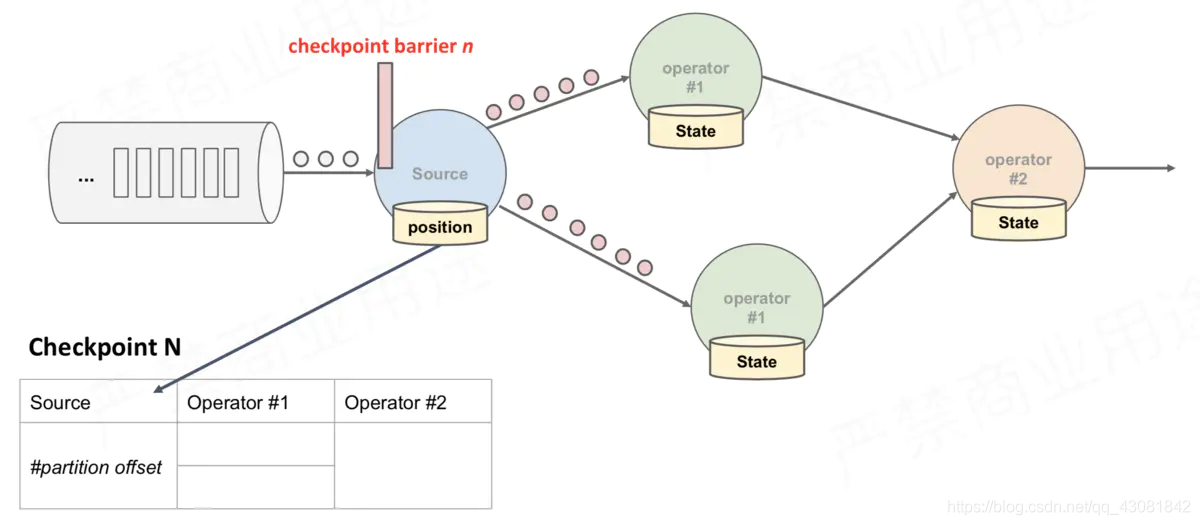
la barrera de la tarea de origen ahora enviará un flujo de datos a descendente;
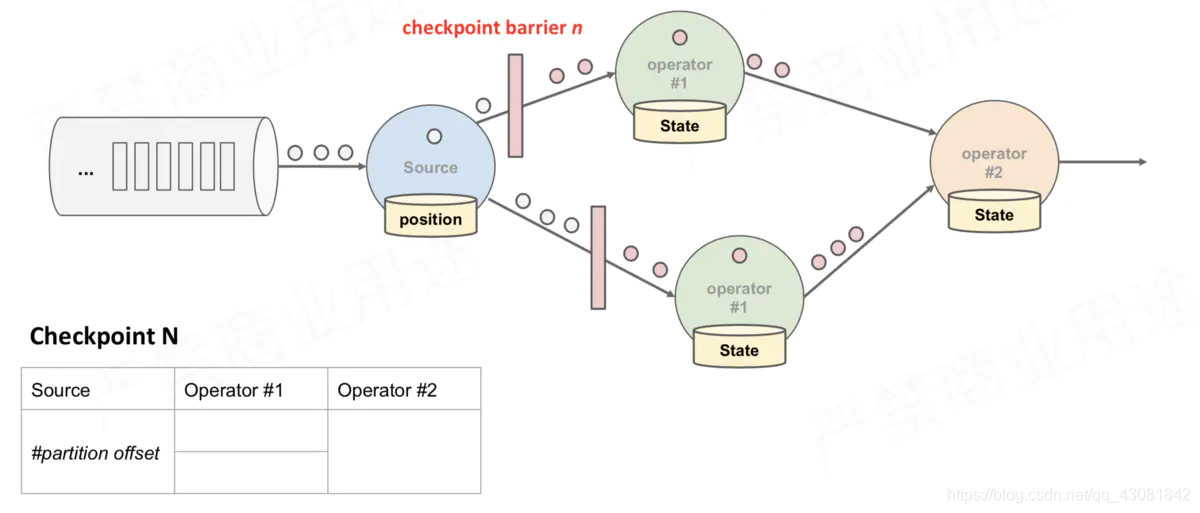
cuando Después de que la instancia de Operador descendente recibe la barrera CheckPoint, toma una instantánea de sí misma. En la
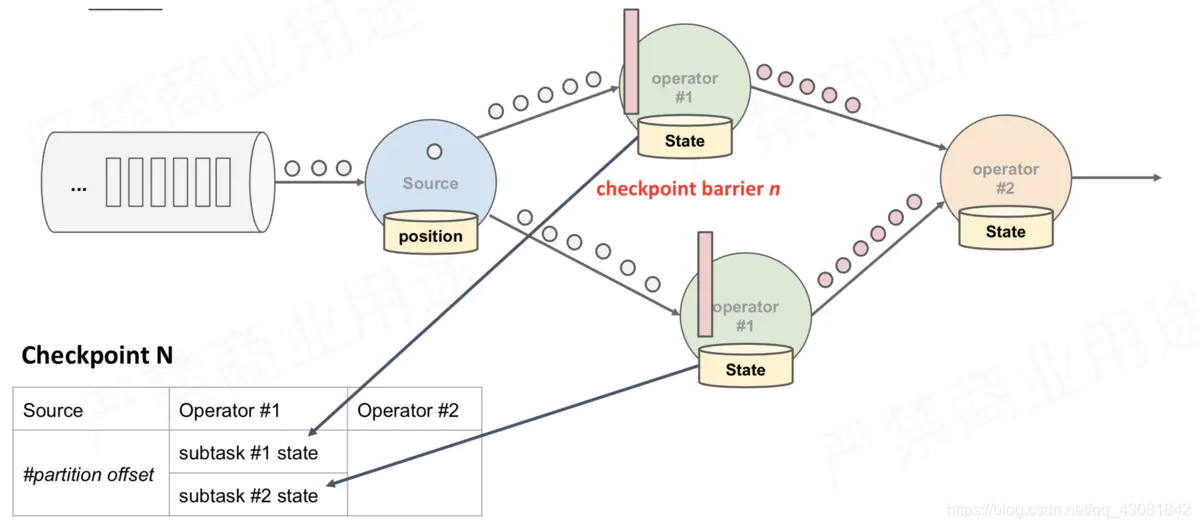
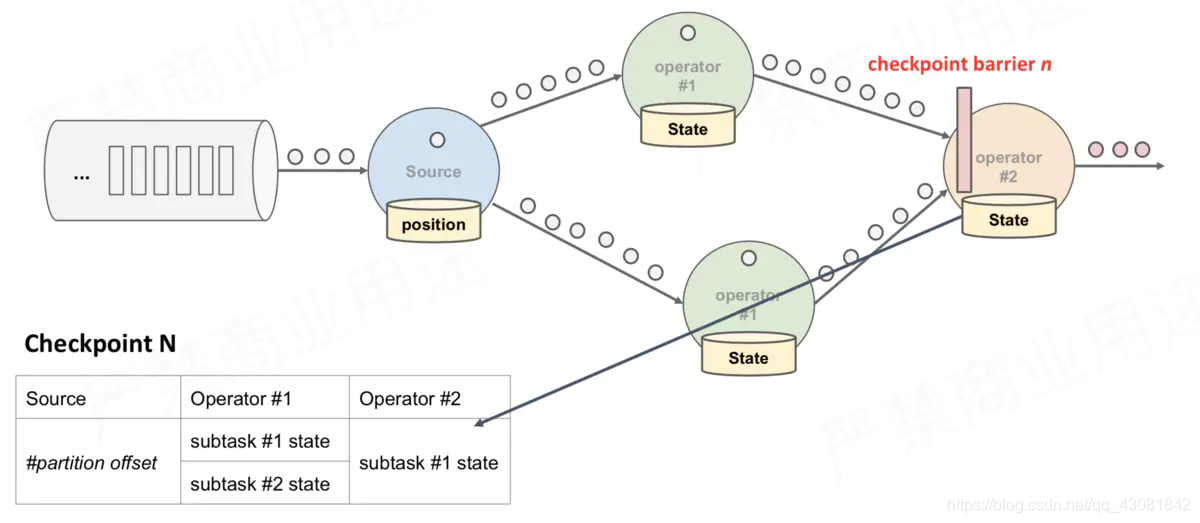
figura anterior, hay 4 instancias de Operador con estado, y el backend de estado correspondiente se puede imaginar como rellenando 4 cuadrículas. Todo el proceso de CheckPoint se puede considerar como el proceso de la instancia del Operador que llena su propia cuadrícula. La instancia del Operador escribe su propio estado en la cuadrícula correspondiente en el backend de estado. Cuando todas las cuadrículas están llenas, simplemente se puede considerar que un complete CheckPoint ha finalizado.
Lo anterior es solo un proceso de instantánea, todo el proceso de ejecución de CheckPoint es el siguiente
- CheckPointCoordinator en el lado de JobManager envía CheckPointTrigger a todas las Tareas de origen, y la Tarea de origen insertará la barrera CheckPoint en el flujo de datos.
- Cuando la tarea recibe todas las barreras, continúa traspasando las barreras a su propio flujo descendente y luego ejecuta la instantánea en sí misma y escribe su propio estado de forma asincrónica en el almacenamiento persistente. Incremental CheckPoint simplemente escribe la última parte de la actualización en el almacenamiento externo; para que CheckPoint sea descendente tan pronto como sea posible, enviará la barrera al descendente primero y luego sincronizará la instantánea en sí.
- Cuando la tarea completa la copia de seguridad, notificará al CheckPointCoordinator del JobManager de la dirección de los datos de la copia de seguridad (identificador de estado); si la duración del CheckPoint excede el tiempo de espera establecido por CheckPoint, CheckPointCoordinator no ha recopilado todo el identificador de estado. , el CheckPointCoordinator pensará si este CheckPoint falla, todos los datos de estado generados por este CheckPoint serán eliminados.
- Finalmente, el Coordinador de CheckPoint encapsulará el StateHandle completo en un Meta de CheckPoint completo y lo escribirá en hdfs.
¿Qué es la alineación de barreras?

- Una vez que el operador recibe la barrera CheckPoint n del flujo de entrada, no puede procesar ningún registro de datos del flujo hasta que reciba la barrera n de todas las demás entradas. De lo contrario, mezclará los registros que pertenecen a la instantánea ny los registros que pertenecen a la instantánea n + 1;
- La secuencia que recibió la barrera n se archiva temporalmente. Los registros recibidos de estos flujos no se procesarán, sino que se colocarán en el búfer de entrada.
- En la segunda imagen de arriba, aunque ha llegado la barrera correspondiente al flujo digital, los datos 1, 2 y 3 posteriores a la barrera solo se pueden colocar en el buffer, esperando que llegue la barrera del flujo de letras;
- Una vez que finalmente todos los flujos de entrada hayan recibido la barrera n, el operador enviará los datos de salida pendientes en el búfer y luego enviará la barrera CheckPoint n aguas abajo
- También habrá una instantánea de sí mismo; después de eso, el operador continuará procesando los registros de todos los flujos de entrada, procesando los registros del búfer de entrada antes de procesar los registros del flujo.
¿Qué es la desalineación de la barrera?
El punto de control es esperar hasta que se alcancen todas las barreras antes de que se complete
- En la Figura 2 anterior, cuando hay otras barreras de flujo de entrada que aún no han llegado, los datos 1, 2 y 3 posteriores a la barrera llegada se colocarán en el búfer y solo se pueden procesar después de la llegada de la barrera de otros arroyos.
- La desalineación de la barrera significa que cuando hay otros flujos de barreras que aún no han llegado, para no afectar el rendimiento, no es necesario preocuparse y procesar directamente los datos después de la barrera. Una vez que hayan llegado las barreras de todas las corrientes, puede controlar al Operador;
¿Por qué es necesaria la alineación de barreras? ¿Es posible desalinear?
- Respuesta: La barrera debe estar alineada cuando Exactamente una vez, si la barrera no está alineada, se convierte en Al menos una vez;
El propósito de CheckPoint es guardar la instantánea. Si no está alineado, algunos datos después del desplazamiento correspondiente a chk-100 se han procesado antes de la instantánea de chk-100. Cuando el programa reanuda la tarea desde chk-100, el desplazamiento correspondiente to chk-100 Los datos posteriores se procesarán una vez, por lo que habrá un consumo repetido. Está bien si no lo entiende. A continuación, hay casos para hacérselo saber.
caso de estudio
Combinando el caso pv, el caso anterior es simple, el tema de Kafka descrito tiene solo 1 partición, aquí para describir la alineación de la barrera, por lo que el tema tiene 2 particiones;
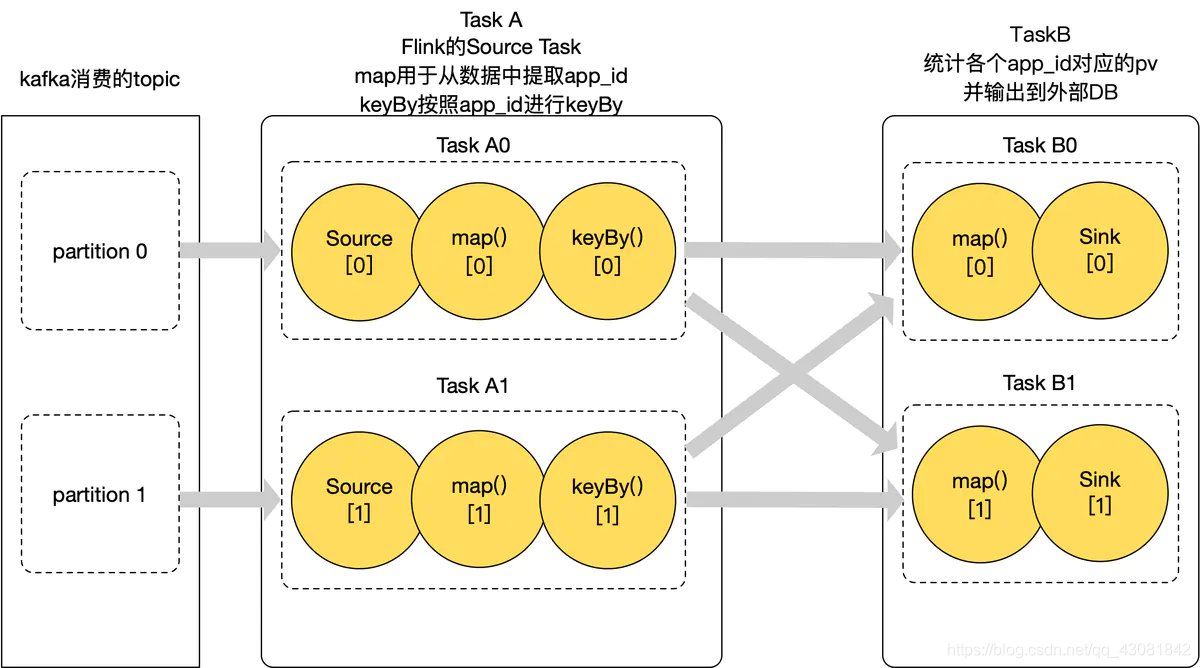
combinado con el negocio, primero introduzca las funciones de todos los operadores anteriores en el negocio
- El consumidor de kafka of Source, lee los datos de kakfa al mapa en TaskA en la aplicación flink y convierte un registro de kafka leído en el app_id que necesitamos contar.
- keyBy realiza keyBy según app_id, y el mismo app_id se asignará a la misma instancia de TaskB descendente
- El mapa de TaskB encuentra el valor de pv correspondiente al app_id en el estado, luego +1, y lo almacena en el estado. Utilice Sink para escribir el valor de pv estadístico en el medio de almacenamiento externo;
- Consumimos datos de las dos particiones de Kafka, TaskA y TaskB tienen dos grados paralelos, por lo que hay un total de 4 instancias de Operator en flink, aquí las llamamos TaskA0, TaskA1, TaskB0, TaskB1;
Suponiendo que 99 CheckPoint se ha realizado correctamente, aquí hay una explicación detallada del proceso número 100 de CheckPoint;
- Hay un cronograma de tiempo dentro del JobManager. Si la hora para el CheckPoint 100 es ahora 10:00:00, el proceso CheckPointCoordinator del JobManager enviará CheckPointTrigger a todas las Tareas de origen, es decir, enviará CheckPointTrigger a TaskA0 y TaskA1.
- TaskA0 y TaskA1 reciben CheckPointTrigger, insertarán una barrera en el flujo de datos, enviarán la barrera a la corriente descendente, registrarán la posición de compensación de la barrera en su propio estado y luego tomarán una instantánea de sí mismos y guardarán la información de compensación en la parte posterior fin del estado.
- Aquí, suponga que el desplazamiento de la partición0 consumido por TaskA0 es 10000 y el desplazamiento de la partición1 consumido por TaskA1 es 10005. Entonces, el estado guardará (0, 10000) (1, 10005), lo que significa que la 0ª partición consume la posición de compensación 10000 y la 1ª partición consume la posición de compensación 10005;
- Entonces no hay ningún estado en el mapa y los operadores keyBy de TaskA, por lo que no es necesario tomar una instantánea.
Luego, los datos y la barrera se envían a la TaskB descendente. El mismo app_id se enviará a la misma instancia de TaskB. Aquí, suponga que hay dos aplicaciones: app0 y app1 Después de keyBy, suponga que app0 está asignada a TaskB0 y app1 está asignada a TaskB1. Según la descripción anterior, todos los datos de app0 en TaskA0 y TaskA1 se envían a TaskB0, y todos los datos de app1 se envían a TaskB1
Ahora supongamos que la barrera está alineada cuando TaskB0 se usa para CheckPoint, y la barrera no está alineada cuando TaskB1 se usa para CheckPoint. Por supuesto, esta configuración no se puede hacer. Les daré un ejemplo para analizar el impacto de la barrera. sobre los resultados estadísticos.
- El CheckPoint de chk-100 mencionado anteriormente, la posición de compensación es (0, 10000) (1, 10005), TaskB0 usa alineación de barrera, lo que significa que TaskB0 no procesará los datos después de la barrera, por lo que TaskB0 está en chk-100 instantánea En ese momento, los datos pv de app0 guardados en el backend de estado son el valor pv calculado a partir de todos los datos desde el inicio del programa hasta la posición de compensación de Kafka (0, 10000) (1, 10005), uno no es muchos (después de que la barrera no se procese, por lo que no se repetirá), mucho (todos los datos antes de que se haya procesado la barrera, por lo que no se perderá), si la información de estado guardada es (app0, 8000), significa que consumo de (0, 10000) (1, 10005) offset En este momento, el valor pv de app0 es 8000
- La barrera utilizada por TaskB1 no está alineada. Si TaskA0 se debe a otras fluctuaciones, como la CPU del servidor o la red, TaskA0 es lento para procesar los datos y TaskA1 es muy estable, por lo que procesa los datos más rápido. El resultado es que TaskB1 recibe primero la barrera de TaskA1. Debido a que la barrera configurada no está alineada, TaskB1 continuará procesando los datos después de la barrera TaskA1. Después de 2 segundos, TaskB1 recibe la barrera de TaskA0, por lo que verifica la aplicación1 almacenada en el estado. Inicie la instantánea de CheckPoint del valor pv, y la información de estado guardada es (app1, 12050), pero sabemos que esto (app1, 12050) en realidad procesa los datos después de la barrera enviada por TaskA1 durante 2 segundos, que es el tema de kafka correspondiente Para los datos después del desplazamiento 10005 de la partición1, los datos PV reales de app1 deben ser menores que 12050. Aunque el desplazamiento guardado por el desplazamiento de la partición1 es 10005, es posible que hayamos procesado los datos del desplazamiento 10200, asumiendo que se procesa a 10200;
- Aunque el valor pv del estado guardado es demasiado alto, no puede explicar el procesamiento repetido, porque mi TaskA1 no consumió los datos del desplazamiento 10005 ~ 10200 de la partición1 nuevamente, por lo que no hay consumo repetido, pero los resultados mostrados son más tiempo real
En este punto del análisis, clasifiquemos lo que nuestro estado ha ahorrado:
chk-100:
- offset:(0,10000)(1,10005)
- pv:(app0,8000) (app1,12050)
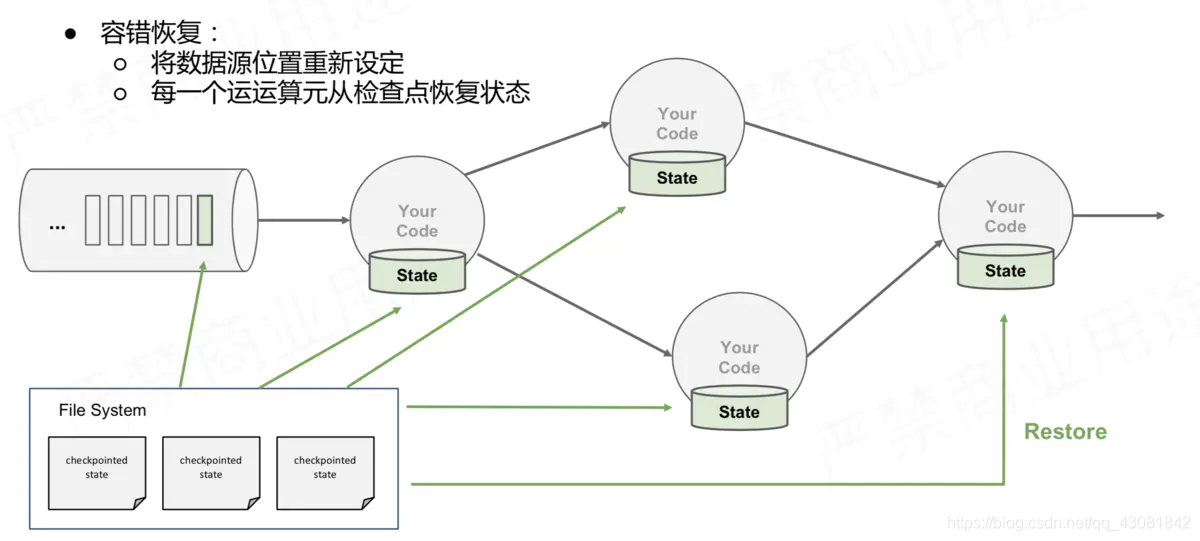
- Luego, el programa continúa ejecutándose. Después de 10 segundos, una de nuestras cuatro instancias de Operador está inactiva debido a un servidor colgando, por lo que Flink se reanudará desde el último estado, que es el chk, que acabamos de discutir en detalle.100 restauraciones, cómo se recuperaron?
- Flink también configurará cuatro instancias de Operador, también las llamo TaskA0, TaskA1, TaskB0 y TaskB1. Los cuatro operadores leerán la información de estado guardada del backend del estado.
- Comience el consumo desde el desplazamiento: (0, 10000) (1, 10005) y acumule estadísticas basadas en el valor de pv: (app0, 8000) (app1, 12050), y luego debería encontrar que el valor de pv de app1 12050 es realmente incluido Los datos del desplazamiento 10005 ~ 10200 de la partición1, por lo que cuando la partición1 reanuda la tarea desde el desplazamiento 10005, los datos del desplazamiento 10005 ~ 10200 de la partición1 se consumen dos veces
- La barrera establecida por TaskB1 no está alineada, por lo que el estado correspondiente al CheckPoint chk-100 consume más datos después de la barrera (enviado por TaskA1). Después de reiniciar, se restaura desde el desplazamiento guardado en chk-100. Esto es lo que se llama Al menos una vez
- Debido a que la barrera establecida por TaskB0 está alineada arriba, no habrá consumo repetido de app0, porque app0 no consume compensación: (0, 10000) (1, 10005) después de los datos, que es lo que se denomina Exactamente una vez;
Al ver esto, ya debe saber qué tipo de consumo repetido ocurrirá y también debe comprender por qué la alineación de la barrera es Exactamente una vez y por qué la alineación de la barrera es Al menos una vez.
¿Cuándo ocurrirá exactamente la alineación de la barrera?
- Primero configure la semántica de CheckPoint de Flink: Exactly Once
- La instancia del operador debe tener múltiples flujos de entrada para que parezca una alineación de barrera
Preguntas más frecuentes
En el primer escenario, al calcular el PV, Kafka solo tiene una partición. ¿No importa si es precisa una vez, al menos una vez?
- Respuesta: Si solo hay una partición, el paralelismo de la tarea fuente de la tarea flink correspondiente solo puede ser 1. De hecho, no hay diferencia, no habrá al menos una existencia, debe ser precisa una vez. Debido a que es posible repetir el procesamiento solo si la barrera no está alineada, el paralelismo aquí ya es 1 y el valor predeterminado está alineado. Solo cuando hay múltiples paralelismos en sentido ascendente, la barrera de que el paralelismo múltiple se envía en sentido descendente debe alinearse. El paralelismo no provocará una desalineación de la barrera, por lo que debe ser exacto una vez. De hecho, todavía es necesario comprender que la alineación de la barrera significa que Exactly Once no se consumirá repetidamente, y la desalineación de la barrera significa que Al menos una vez se puede consumir repetidamente. Aquí, solo hay un grado de paralelismo y no hay barrera desalineación, por lo que no habrá semántica al menos una vez;
Para que CheckPoint se realice en sentido descendente lo antes posible, la barrera se enviará primero al flujo descendente y luego la instantánea se sincronizará por sí misma. En este paso, ¿qué sucede si la instantánea de sincronización es lenta después de que se envía la barrera? El downstream se ha sincronizado, ¿todavía no?
- Respuesta: Puede suceder que la instantánea descendente sea anterior a la instantánea ascendente, pero esto no afecta el resultado de la instantánea, pero la instantánea descendente es más oportuna. Solo necesito asegurarme de que el flujo descendente procesa todos los datos antes de la barrera y lo hace No procese los datos después de la barrera. Luego tome una instantánea, luego el flujo descendente también admite una vez precisa. No piense en este problema desde la perspectiva general. Si piensa en los ejemplos ascendentes y descendentes de forma individual, encontrará que el estado ascendente y descendente es preciso y no hay pérdida ni doble recuento. Una cosa a tener en cuenta aquí, si hay un CheckPoint del operador que falla o el tiempo de espera de CheckPoint también causará la falla, JobManager considerará que todo el CheckPoint falla. El CheckPoint fallido no se puede usar para restaurar la tarea. Todos los puntos de control de los operadores deben ser exitosos, entonces el CheckPoint se puede considerar exitoso esta vez y se puede usar para restaurar la tarea;
La semántica de CheckPoint de Flink en mi programa se establece exactamente una vez, pero los datos están duplicados en mi mysql. El CheckPoint se establece una vez cada 1 minuto en el programa, pero los datos se escriben en mysql cada 5 segundos y se confirman;
- Respuesta: Flink requiere que el extremo a extremo debe implementar TwoPhaseCommitSinkFunction exactamente una vez. Si su chk-100 tiene éxito, después de 30 segundos, porque se confirma una vez cada 5 segundos, en realidad ha escrito 6 lotes de datos en mysql, pero de repente el programa se cuelga y se reanuda desde chk100. En este caso, los seis lotes enviados anteriormente de datos se escribirán repetidamente, por lo que se producirá un consumo repetido. Hay dos casos de precisión de Flink una vez. Uno es la precisión dentro de Flink y el otro es la precisión de un extremo a otro. Este blog describe la precisión de Flink internamente. Publicaré otro blog para presentar Flink en detalle más adelante. Cómo lograr precisión de extremo a extremo una vez