Introducción al modelo DIN
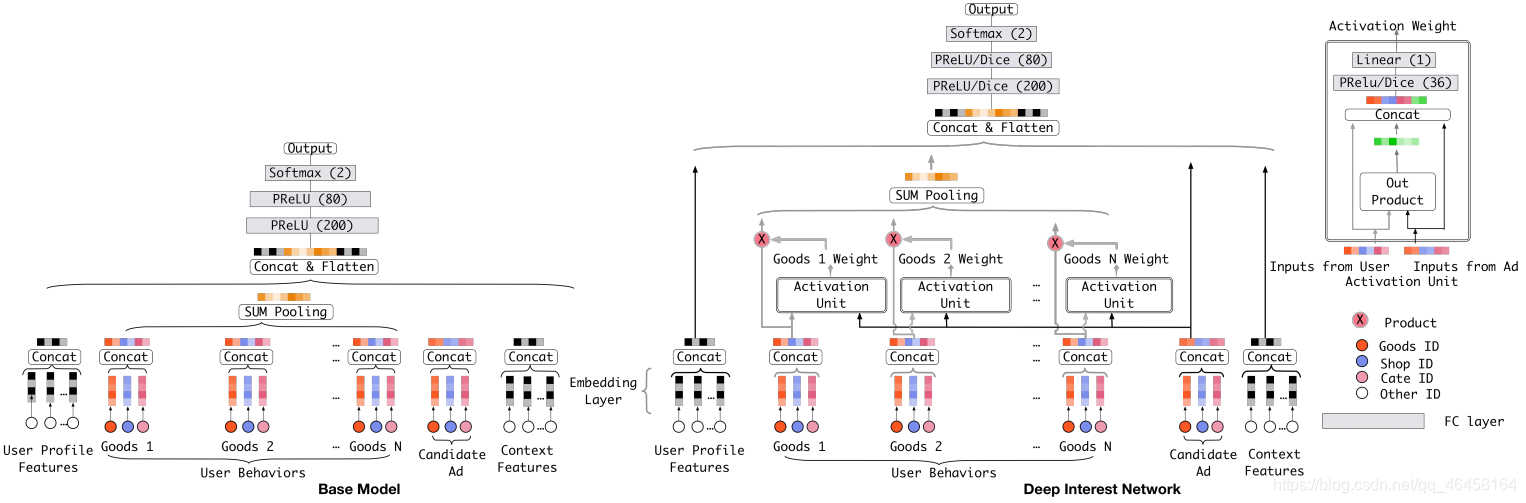
El nombre completo de DIN es Deep Interest Network, que es un modelo propuesto por Alibaba en 2018 basado en el modelo de aprendizaje profundo anterior que no puede expresar los diversos intereses de los usuarios. Se puede considerar considerando [anuncios candidatos dados] y [historial del usuario comportamiento] Calcular el vector de representación de interés del usuario. Específicamente, la unidad de activación local se introduce para enfocarse en los intereses relevantes del usuario a través de las partes relevantes del comportamiento del historial de búsqueda suave, y la suma ponderada se usa para obtener la expresión de los intereses del usuario relacionados con los anuncios de los candidatos. Los comportamientos que son más relevantes para los anuncios de los candidatos obtendrán un mayor peso de activación y dominarán los intereses de los usuarios. El vector de representación es diferente en diferentes anuncios, lo que mejora enormemente la capacidad expresiva del modelo. Por lo tanto, este modelo también es más adecuado para la tarea de recomendación de noticias.Aquí calculamos el interés del usuario en el artículo en función de la correlación entre el artículo candidato actual y el artículo histórico de clics del usuario. La estructura del modelo es la siguiente:
def DIN (dnn_feature_columns, history_feature_list, dnn_use_bn = False, dnn_hidden_units = (200, 80), dnn_activation = 'relu', att_hidden_size = (80, 40), att_activation = "dice_normalization" 0, l2_reg_embedding = 1e-6, dnn_dropout = 0, seed = 1024, task = 'binary'):
dnn_feature_columns: 特征列, 包含数据所有特征的列表
history_feature_list: 用户历史行为列, 反应用户历史行为的特征的列表
dnn_use_bn: 是否使用BatchNormalization
dnn_hidden_units: 全连接层网络的层数和每一层神经元的个数, 一个列表或者元组
dnn_activation_relu: 全连接网络的激活单元类型
att_hidden_size: 注意力层的全连接网络的层数和每一层神经元的个数
att_activation: 注意力层的激活单元类型
att_weight_normalization: 是否归一化注意力得分
l2_reg_dnn: 全连接网络的正则化系数
l2_reg_embedding: embedding向量的正则化稀疏
dnn_dropout: 全连接网络的神经元的失活概率
task: 任务, 可以是分类, 也可是是回归
Para un uso específico, debemos pasar la columna de características y la columna de comportamiento histórico, pero antes de pasarla, necesitamos preprocesar la columna de características. detalles como sigue:
Primero, necesitamos procesar el conjunto de datos para obtener los datos. Dado que predecimos si el usuario hace clic en el artículo actual en función del comportamiento anterior del usuario, debemos dividir la columna de características de datos en características numéricas, características discretas y características de comportamiento histórico. .Parte, para cada parte, el procesamiento del modelo DIN será diferente.
Para las características discretas, en nuestro conjunto de datos están las características categóricas, como user_id. Para esta característica categórica, primero debemos pasar por la incrustación para obtener cada representación densa de características. Dado que se requiere incrustación, necesitamos crear un diccionario para el valor de la característica de categoría de cada columna y especificar la dimensión de inserción. Por lo tanto, al preparar datos utilizando el modelo DIN de deepctr, debemos pasar The SparseFeat La función indica estas características categóricas Los parámetros entrantes de esta función son el nombre de la columna, el valor único de la columna (para la creación del diccionario) y la dimensión de incrustación.
Para las columnas de características del comportamiento histórico del usuario, como la identificación del artículo, la categoría del artículo, etc., primero debemos realizar la inserción, pero la diferencia con lo anterior es que para esta característica, obtenemos la inserción de cada característica después de la representación, es necesario calcular la correlación entre el comportamiento histórico del usuario y el artículo candidato actual a través de un Attention_layer para obtener el vector de inserción del usuario actual. Este vector puede basarse en la similitud entre el artículo candidato actual y el artículo histórico que el usuario ha hecho clic en el pasado. El título refleja el interés del usuario y cambia con los diferentes clics históricos del usuario para simular dinámicamente el proceso de cambio del interés del usuario. Este tipo de función es una secuencia de comportamiento histórico para cada usuario. Para cada usuario, la duración de la secuencia de comportamiento histórico será diferente. Algunos usuarios pueden hacer clic en más artículos históricos y otros en menos artículos históricos, por lo que todavía necesitamos Esta longitud está unificada. Al preparar datos para el modelo DIN, primero debemos especificar estas características categóricas a través de la función SparseFeat, y luego debemos completar la secuencia a través de la función VarLenSparseFeat para que la secuencia histórica de cada usuario tenga la misma longitud, por lo que esta función habrá un máximo en el parámetro para indicar la longitud máxima de la secuencia.
Para columnas de características continuas, solo necesitamos usar la función DenseFeat para especificar el nombre y la dimensión de la columna.
Después de procesar la columna de características, correspondemos los datos correspondientes con la columna para obtener los datos finales.
Vamos a tener una idea del código específico. La lógica es así. Primero, necesitamos escribir una función de preparación de datos. Aquí, necesitamos preparar los datos de acuerdo con los pasos específicos anteriores, obtener los datos y las columnas de características, luego construir y entrenar el modelo DIN, y finalmente en base al modelo realizar las pruebas.