Prólogo
El concepto de equilibrio de carga se menciona a menudo en nuestro trabajo, porque al observar la capa de enlace completa de nuestro sistema, cada capa utilizará el equilibrio de carga, desde la capa de acceso, la capa de servicio hasta la capa de datos final, y por supuesto. Hay MQ, almacenamiento en caché distribuido, etc., habrá algunas ideas de equilibrio de carga en él; una breve definición de equilibrio de carga: es asignar solicitudes a múltiples unidades de operación para su ejecución; de hecho, es una idea de dividir y conquistar. En el caso de alta concurrencia, este es un método muy efectivo.
En la
breve definición de funciones básicas anterior, podemos ver aproximadamente dos cosas: distribución de solicitudes, unidad de operación; de hecho, el modo controlador + actuador, modo maestro + trabajador, etc., es muy familiar; por supuesto, un equilibrador de carga maduro El dispositivo no solo tiene estas dos funciones principales, sino también algunas otras funciones. Veamos qué funciones principales están disponibles:
Configuración de la unidad operativa
La unidad de operación aquí es en realidad el servidor upstream, que es el ejecutor real para manejar el negocio. Esto debe ser configurable (preferiblemente compatible con la configuración dinámica) para facilitar a los usuarios agregar y eliminar unidades de operación; estas unidades de operación son el balanceador de carga para distribuir mensajes Objeto;
Algoritmo de equilibrio de carga
Ya que necesita ser distribuido, cómo distribuir el mensaje a los ejecutores configurados, lo que requiere algoritmos de distribución relacionados, como nuestro sondeo común, hash aleatorio, consistente, etc .;
Reintento fallido
Dado que se configuran varias unidades de ejecución, el tiempo de inactividad de un servidor es un evento de alta probabilidad, por lo que cuando distribuimos solicitudes a un servidor caído, necesitamos tener una función de reintento por falla para redistribuir la solicitud a los ejecutores normales ;
Examen de salud
El reintento de falla anterior es para saber que el servidor está inactivo solo cuando realmente se reenvía. Es una estrategia lenta. La verificación de estado es excluir la máquina inactiva por adelantado. Por ejemplo, es común verificar si el ejecutor todavía está vivo por latido.;
Con las funciones básicas anteriores, se forma aproximadamente un equilibrador de carga. Estos principios se pueden usar en muchos lugares para formar diferentes middleware o incrustados en varios middleware, como la capa de acceso LVS, F5, Nginx, etc. varios marcos de RPC en la capa de servicio, cola de mensajes RocketMQ, Kafka, caché distribuida Redis, memcached, shardingsphere de middleware de base de datos, mycat, etc. Esta idea de dividir y conquistar se usa ampliamente en varios middleware. A continuación, se analiza cómo algunos común middleware hacer balanceo de carga, que puede ser más o menos dividido en dos tipos: sin estado con estado y, al
apátrida
unidad de ejecución en sí no tiene un estado, de hecho, es más fácil de hacer balance de carga las unidades de ejecución son los mismos middleware comunes sin estado incluyen.. Nginx, marco RPC, programación distribuida, etc .; se puede decir que la
capa de acceso
Nginx es nuestro middleware de capa de acceso más común, que proporciona de cuatro a siete capas La función de equilibrio de carga proporciona un reenvío de alto rendimiento y admite las funciones básicas anteriores;
Configuración de la unidad operativa
Nginx proporciona una configuración de unidad de operación estática simple, de la siguiente manera:
upstream tomcatTest {
server 127.0.0.1:8081; #tomcat-8081
server 127.0.0.1:8082; #tomcat-8082
}
location / {
proxy_pass http://tomcatTest;
}
复制代码
La configuración anterior es estática. Si necesita agregarla o eliminarla, debe reiniciar Nginx, lo cual es muy inconveniente. Por supuesto, también se proporciona la configuración dinámica de la unidad, que requiere la ayuda de un registro de servicios de terceros como Consul , etcd; el principio es aproximadamente el siguiente:
La unidad de operación se registrará en Consul cuando se inicie, y el tiempo de inactividad se eliminará de Consul; el lado de Nginx iniciará un oyente de plantilla de Consul para monitorear los cambios de la unidad de operación en Consul, y luego actualizará Nginx upstream, preferiblemente recargar aguas arriba;
Algoritmo de equilibrio de carga
Ejemplos comunes: ip_hash, round-robin, hash; la configuración también es muy simple:
upstream tomcatTest {
ip_hash //根据ip负载均衡,也就是常说的ip绑定
server 127.0.0.1:8081; #tomcat-8081
server 127.0.0.1:8082; #tomcat-8082
}
复制代码
Reintento fallido
upstream tomcatTest {
server 127.0.0.1:8081 max_fails=2 fail_timeout=20s;
}
location / {
proxy_pass http://tomcatTest;
proxy_next_upstream error timeout http_500;
}
复制代码
Cuando max_fails falla en fail_timeout, significa que esta unidad de ejecución no está disponible; a través de la configuración proxy_next_upstream, cuando ocurre un error de configuración, se reintentará la siguiente unidad de ejecución;
Examen de salud
Nginx realiza una verificación de estado integrando el módulo nginx_upstream_check_module; admite la detección de latidos de TCP y Http;
upstream tomcatTest {
server 127.0.0.1:8081;
check interval=3000 rise=2 fall=5 timeout=5000 type=tcp;
}
复制代码
intervalo: tiempo de intervalo de detección;
aumento: cuántas veces la detección es exitosa, la unidad operativa se identifica como disponible;
caída: cuántas veces falla la detección, la unidad operativa se identifica como no disponible;
tiempo de espera: tiempo límite de solicitud de detección;
tipo: detección los tipos incluyen tcp, http ;
Capa de
servicio La capa de servicio es principalmente marcos de microservicios como Dubbo, Spring Cloud, etc., que tienen estrategias integradas de equilibrio de carga y son muy convenientes de usar;
Configuración de la unidad operativa
El marco RPC generalmente se basa en el componente de registro. De hecho, es lo mismo que Nginx cambiando dinámicamente la unidad operativa a través del registro. El marco RPC ya se basa en el registro de forma predeterminada. El servicio se registra en el centro cuando se inicia , y el servicio se elimina cuando no está disponible. Se sincroniza automáticamente con el consumidor final, y el usuario no se da cuenta por completo. Lo que el consumidor final tiene que hacer es realizar el equilibrio de carga de acuerdo con la lista de servicios proporcionada por el registro y luego utilizar el algoritmo de distribución;
Algoritmo de equilibrio de carga
Spring Cloud proporciona componentes Ribbon para lograr el equilibrio de carga y las estrategias de equilibrio integradas directamente por Dubbo, los algoritmos comunes incluyen: sondeo, aleatorias, llamadas menos activas, Hash consistente, etc .; por ejemplo, algoritmo de sondeo de configuración dubbo:
<dubbo: interfaz de referencia = "" loadbalance = "roundrobin" />
Copiar código
Reglas aleatorias de configuración de la cinta:
@Bean
public IRule loadBalancer(){
return new RandomRule();
}
复制代码
Reintento fallido
Para el marco RPC, en realidad es un mecanismo tolerante a fallas. Por ejemplo, Dubbo tiene una variedad de mecanismos incorporados tolerantes a fallas que incluyen: Conmutación por falla, A prueba de fallas, A prueba de fallas, Recuperación, Bifurcación, Difusión; el mecanismo tolerante a fallas predeterminado es Conmutación automática de fallos de conmutación por error, y reintentar otros servidores cuando se produce un fallo; Configurar la tolerancia a fallos también es muy sencillo:
<dubbo:reference cluster="failback" retries="2"/>
复制代码
Examen de salud
El centro de registro generalmente tiene una función de verificación de estado, que verificará si el servidor está disponible en tiempo real, si no está disponible, se eliminará y la actualización se enviará al consumidor al mismo tiempo; está completamente inconsciente para el usuario; la
programación distribuida separa al programador del ejecutor, El ejecutor también se le proporciona al programador a través del registro, y luego el programador realiza operaciones de balanceo de carga. El proceso es básicamente similar y no se introducirá uno por uno aquí; Se
puede encontrar que el balanceo de carga sin estado es en realidad más común desde el registro, a través del registro para aumentar o disminuir dinámicamente la unidad de ejecución, por lo que es muy conveniente lograr expansión y contracción;
la
unidad de ejecución con estado es más difícil que la apátrida , porque el estado de cada nodo es parte de todo el sistema, no los nodos que se pueden agregar o eliminar a voluntad; el middleware con estado común es: colas de mensajes, cachés distribuidos, middleware de bases de datos, etc.; las
colas de mensajes
ahora tienen un alto rendimiento , las colas de mensajes de alto rendimiento se están volviendo cada vez más comunes, como RocketMQ, Kafka, etc., hay una fuerte capacidad de expansión horizontal; RocketMQ presenta el mecanismo de cola de mensajes, Kafka presenta particiones (Partición), un tema corresponde a múltiples particiones , utilizando la idea de dividir y conquistar para mejorar el rendimiento y el rendimiento; puede ver un diagrama simple de RocketMQ:
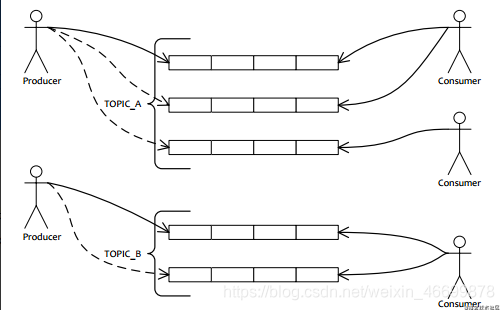
Configuración de la unidad de operación
La unidad operativa en la cola de mensajes es en realidad la partición o la cola de mensajes aquí. Por ejemplo, RocketMQ puede modificar dinámicamente el número de colas de lectura y escritura; RocketMQ también proporciona la consola rocketmq-console, que se puede modificar directamente;
Algoritmo de equilibrio de carga
Las colas de mensajes generalmente tienen un lado de producción y un lado del consumidor. De forma predeterminada, el lado de producción envía mensajes a cada Message Queue por turno. Por supuesto, también puede personalizar la estrategia de envío y puede ser implementada por MessageQueueSelector; la estrategia de asignación del lado del consumidor incluye : modo de paginación (modo de asignación aleatoria), modo de configuración manual, modo de sala de computadoras designado, modo de sala de computadoras más cercana, modo hash unificado, modo de timbre;
Reintento fallido
Para una unidad de ejecución con estado, no significa que se pueda eliminar directamente cuando está inactiva. Necesita garantizar la integridad de los datos. Normalmente, realizará el procesamiento principal y de respaldo, y el host colgará la máquina de respaldo tomar el control; tome RocketMQ como ejemplo, cada partición tiene su propia copia de seguridad. La estrategia adoptada por RocketMQ es que el área de copia de seguridad es solo para garantizar la integridad de los datos. Los consumidores pueden enviar mensajes a los datos en el área de copia de seguridad, pero no volver a recibir los datos;
Examen de salud
La cola de mensajes también tiene un componente central, que puede entenderse como un coordinador, o como un registro. Kafka usa zookeeper y RocketMQ usa NameServer. De hecho, la información correspondiente se almacena dentro, como Topic correspondiente a Message Queue. Si un broker no está disponible. La información se notificará al productor de manera similar al registro; las
cachés distribuidas
comunes de las cachés distribuidas incluyen redis y memcached. Para acomodar más datos, generalmente estarán fragmentados y no Hay varias formas de fragmentación. Tome redis, por ejemplo, el cliente puede realizar la fragmentación, la fragmentación basada en proxy y la solución oficial de Cluster;
Configuración de la unidad operativa
Aunque la caché también tiene estado, tiene su particularidad. Presta más atención a la tasa de aciertos. De hecho, puede tolerar la pérdida de datos. Por ejemplo, el código del middleware de fragmentación basado en proxy es completamente transparente para el cliente sin afectar el servicio . Puede agregar o eliminar instancias de redis en
Algoritmo de equilibrio de carga
Basado en la premisa de garantizar la tasa de aciertos, el método de fragmentación basado en proxy generalmente usa un algoritmo hash consistente; y la solución Cluster proporcionada oficialmente por redis, porque tiene 16384 ranuras virtuales integradas, por lo tanto, use directamente el módulo para completar el fragmentación
Reintento fallido
Los fragmentos con estado generalmente tienen zonas de respaldo. Una vez que la zona principal se desactiva, la zona de respaldo toma el control para implementar la migración de fallas, como el modo centinela de redis, o la función incorporada de middleware como codis; no hay necesidad de cambiar otras zonas, derecha Para los usuarios, este tipo de toma de control es completamente imperceptible;
Examen de salud
Tomemos a redis como ejemplo. En el modo centinela, centinela monitorea los nodos en tiempo real por latido e implementa la migración de fallas a través del objetivo fuera de línea; se puede encontrar que las verificaciones de estado se detectan básicamente por latido; la
capa de la base de datos se
equilibra con la capa de la base de datos .Es el más complicado, primero tiene estado y, en segundo lugar, la seguridad de los datos es muy importante. El middleware de base de datos común incluye: mycat, shardingjdbc, etc .;
Configuración de la unidad operativa
Tome la fragmentación como ejemplo. La unidad de operación aquí es en realidad una tabla de datos fragmentada. La cantidad de datos a veces supera nuestras expectativas. Por lo general, rara vez se dice cuántos fragmentos se le asignan. Es mejor usar automáticamente el algoritmo de carga Genere una tabla de datos, y es mejor evaluar un cierto algoritmo de carga de antemano, de lo contrario es difícil cambiarlo;
Algoritmo de equilibrio de carga
Tomando mycat como ejemplo, proporciona una variedad de algoritmos de carga: convención de rango, módulo, fragmentación por fecha, hash, hash consistente, enumeración de fragmentación, etc .; por ejemplo, la siguiente configuración particionada por día:
<tableRule name="sharding-by-date">
<rule>
<columns>create_time</columns>
<algorithm>sharding-by-date</algorithm>
</rule>
</tableRule>
<function name="sharding-by-date" class="io.mycat.route.function.PartitionByDate">
<property name="dateFormat">yyyy-MM-dd</property>
<property name="sBeginDate">2021-01-01</property>
<property name="sEndDate">2051-01-01</property>
<property name="sPartionDay">10</property>
</function>
复制代码
Especifique la hora de inicio, la hora de finalización y la cantidad de días de la partición; debido a que los datos son continuos en el tiempo, este método tiene una buena escalabilidad; si es un método de módulo, la cantidad de fragmentos debe considerarse claramente. Es muy es problemático cambiar el número de fragmentos, a diferencia de la caché, que puede usar un hash consistente para garantizar la tasa de aciertos;
Reintento fallido
Para los nodos con estado, la base de datos en espera es indispensable. Por ejemplo, mycat proporciona una función de conmutación maestro-esclavo defectuosa. El cambio del maestro al esclavo cuando el maestro está inactivo es básicamente esta rutina, y los datos no se pueden perder;
Examen de salud
La misma detección activa también es esencial. Generalmente se basa en declaraciones de latido para realizar la detección de tiempo y luego realizar la conmutación maestro-esclavo de falla; los
anteriores son tres middlewares con estado comunes. Se puede encontrar que, aunque todos son con estado, son basado en diferentes estados de datos. (Temporal, estado final), el método de procesamiento también es muy diferente;
de hecho, también hay un middleware con estado: el registro, que admite múltiples nodos al mismo tiempo, pero cada nodo guarda el cantidad de datos, porque el centro de registro a menudo guarda una pequeña cantidad de datos, y la estrategia de equilibrio que proporciona puede ser tan simple como apátrida.
Resumen En
resumen, podemos encontrar que la idea de dividir y conquistar ha sido ampliamente utilizada en varios software, encontrando grandes problemas, grandes cantidades de datos, grandes cantidades de concurrencia, etc., de hecho, la idea central es dividir , en cuanto a cómo dividir Para utilizar diferentes algoritmos de división o algoritmos de ecualización de acuerdo con las diferentes necesidades comerciales, y debe garantizar las funciones básicas descritas anteriormente.
Referencia: "¡Los últimos conceptos básicos de Java de 2020 y tutoriales en video detallados y rutas de aprendizaje! 》
Enlace original: https://juejin.cn/post/6914911007349407751