1. ¿Qué es la interfaz del software?
Clases o funciones para transferir datos y procesar entre diferentes módulos del programa
2. ¿Cuál es la diferencia entre los protocolos HTTP y HTTPS?
Respuesta: El protocolo https requiere que una CA (Autoridad de certificación) solicite un certificado. Generalmente, hay menos certificados gratuitos, por lo que se requiere una tarifa determinada; http es un protocolo de transferencia de hipertexto y la información se transmite en texto sin formato. El protocolo Https está construido por el protocolo SSL + Http El protocolo de red para la transmisión encriptada y la autenticación de identidad es más seguro que el protocolo http, http y https usan métodos de conexión completamente diferentes y usan puertos diferentes: el primero es 80 y el segundo es 443;
3. ¿En qué capa está HTTPS?
Me gustaba hacer preguntas sobre protocolos de red en las entrevistas, algunos amigos decían que instalé X, lo cual no es práctico. Una pequeña investigación sobre el conocimiento de la red, de hecho, no es difícil de responder.
R: HTTPS en la capa de aplicación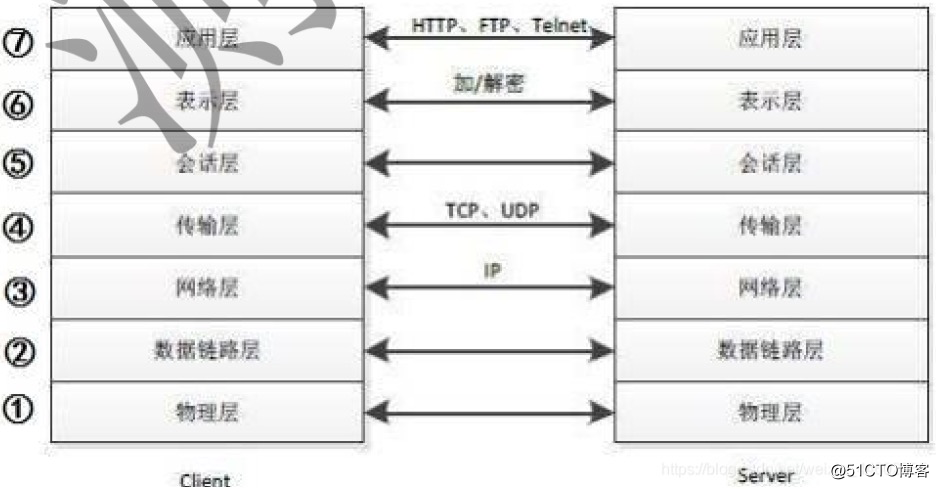
4. ¿Cuál es la diferencia entre obtener y publicar?
Respuesta: POST y GET envían datos al servidor y ambos obtienen datos del servidor. Diferencias: 1) Método de transmisión: get se transmite a través de la barra de direcciones, post se transmite a través del mensaje 2) Longitud de transmisión: el parámetro get tiene un límite de longitud (limitado por la longitud de la URL) y post no tiene límite 3) GET genera un paquete de datos TCP (para Para una solicitud GET, el navegador enviará el encabezado http y los datos juntos, y el servidor responderá con 200 y devolverá los datos. POST genera dos paquetes de datos TCP (para POST, el navegador envía el encabezado primero, el servidor responde con 100 continue, y luego el navegador Enviar datos, el servidor responde con 200 ok para devolver los datos) 4) Obtener los parámetros de la solicitud se conservarán por completo en el historial de navegación, pero los parámetros de la publicación no se conservarán 5) Al realizar la consulta de datos, se recomienda utilizar GET; mientras se hace Al agregar, modificar o eliminar datos, se recomienda publicar
5. Métodos comunes de envío de datos POST
Respuesta: Hay cuatro métodos principales: application / x-www-form-urlencoded, multipart / form-data, application / json, text / xml, etc.
6. ¿Qué es el protocolo sin estado del protocolo HTTP? Cómo resolver el protocolo sin estado del protocolo HTTP
Respuesta: Sin estado significa que el protocolo no tiene capacidad de memoria para el procesamiento de transacciones y el servidor no conoce el estado del cliente. Es decir, después de enviar una solicitud HTTP al servidor, el servidor nos enviará datos de acuerdo con la solicitud, pero después de enviarla, no se registrará ninguna información. HTTP es un protocolo sin estado, lo que significa que cada solicitud es independiente y Keep-Alive no ha cambiado este resultado. La falta de estado significa que si la información anterior es necesaria para un procesamiento posterior, debe ser retransmitida, lo que puede resultar en un aumento en la cantidad de datos transmitidos por conexión. Por otro lado, cuando el servidor no necesita información previa, su respuesta es más rápida. Esta característica del protocolo HTTP tiene ventajas y desventajas. La ventaja es que libera el servidor. Cada solicitud "punto a parada" no causará una ocupación de conexión innecesaria. La desventaja es que cada solicitud transmitirá una gran cantidad de información de contenido repetida. Después de la aparición de aplicaciones web donde el cliente y el servidor interactúan dinámicamente, la naturaleza sin estado de HTTP ha obstaculizado seriamente la implementación de estas aplicaciones. Después de todo, la interacción requiere un vínculo entre el pasado y el futuro. Un simple programa de carrito de compras también debe saber qué ha elegido el usuario antes. mercancía. Por lo tanto, surgieron dos tecnologías para mantener el estado de la conexión HTTP, una es Cookie y la otra es Session.
7. La diferencia entre cookie y sesión
Respuesta: Los datos de las cookies se almacenan en el navegador del cliente. Los datos de la sesión en el servidor no son muy seguros. Otros pueden analizar las cookies almacenadas localmente y realizar suplantación de cookies. Teniendo en cuenta la seguridad, debe utilizar la sesión de sesión. La sesión se almacenará durante un cierto período de tiempo. En el servidor. Cuando aumenta el número de visitas, se reducirá el rendimiento de su servidor. Las cookies deben usarse para reducir el rendimiento del servidor. Una sola cookie no puede almacenar más de 4K datos. Muchos navegadores limitan un sitio para guardar hasta 20 cookies. Puede almacenar información importante, como información de inicio de sesión. Es sesión; se debe guardar otra información y se puede colocar en la cookie
8. Códigos de estado de devolución comunes en interfaces de solicitud
Respuesta:
Solicitud de información 1xx (representa una respuesta temporal. El cliente está listo para recibir una o más respuestas 1xx antes de recibir una respuesta regular)
2xx-Success (indica que el servidor aceptó con éxito la solicitud del cliente)
3xx-Redirection (cliente El navegador del cliente debe realizar más acciones para cumplir con la solicitud. Por ejemplo, es posible que el navegador tenga que solicitar una página diferente en el servidor o repetir la solicitud a través de un servidor proxy)
4xx-Error del cliente (error de envío, el cliente tiene un problema. Por ejemplo, , El cliente solicita una página que no existe y el cliente no proporciona información de verificación de identificación válida) Error 5xx-server (el servidor no puede completar la solicitud debido a un error) Los
códigos de retorno comunes son:
200 OK- [GET]: El servidor devolvió correctamente los datos solicitados por el usuario
201 CREADO- [POST / PUT / PATCH]: El usuario creó o modificó los datos correctamente
202 Aceepted- []: Indica que una solicitud ha entrado en la cola de fondo (tarea asíncrona)
204 SIN CONTENIDO- [BORRAR ]: El usuario borra los datos con éxito
400 SOLICITUD NO VÁLIDA- [POST / PUT / PATCH]: La solicitud enviada por el usuario tiene un error y el servidor no crea ni modifica los datos 401 No autorizado - []: Indica que el usuario no tiene autoridad (token, Nombre de usuario, error de contraseña)
403 Prohibido - []: indica que el usuario está autorizado (a diferencia del error 401), pero el acceso está prohibido
404 NO ENCONTRADO - []: La solicitud enviada por el usuario es para un registro que no existe y el servidor no Realizar una operación idempotente
406 Not Acceptable- [GET]: el formato de la solicitud del usuario no está disponible (por ejemplo, el usuario solicita el formato JSON, pero solo el formato XML)
500 INTERNAL SERVER ERROR - [*]: El servidor tiene un error y el usuario no podrá determinar si la solicitud es exitosa
9. ¿Qué es DNS?
Respuesta: DNS es el sistema de nombres de dominio. DNS se utiliza para la resolución de nombres de dominio. Después de ingresar la dirección web en Internet, la convertirá en una IP y luego irá al servidor de la otra parte; sin ella, solo desea ir a Baidu Recuerda la IP de Baidu, pero con el procesamiento de DNS, solo necesitas recordar el nombre de dominio del sitio web correspondiente, es decir, la URL.
10. ¿Cómo realiza su empresa las pruebas de interfaz?
Respuesta: La prueba de interfaz real es diferente de la prueba general en la parte de diseño del caso de prueba. ① Obtenga las especificaciones de la interfaz.
② Diseñar casos de uso de funciones de prueba de interfaz (principalmente desde la perspectiva de los usuarios para ver si la interfaz puede cumplir con los requisitos comerciales, el diseño de casos de uso es el conjunto de casos de uso de caja negra).
③ Verificación de varios parámetros de entrada (las condiciones normales, las condiciones anormales incluyen un número incorrecto de parámetros de entrada, tipo incorrecto, opcional / obligatorio y consideración de parámetros mutuamente excluyentes o relacionados).
④Varias verificaciones de los valores de retorno de la interfaz (en línea con los requisitos del documento de la interfaz)
⑤Comprender la lógica de la implementación de la interfaz y realizar la cobertura lógica (declaraciones / condiciones / rama / juicios / ...)
⑥¿Puede ejecutarse la interfaz al mismo tiempo, es segura y el rendimiento cumple con los requisitos?
⑦Adoptar Herramientas o código autoescrito para verificar.
⑧ Encontrar el problema es lo mismo que la prueba de funcionamiento, se debe informar el error y se debe realizar un seguimiento del estado de seguimiento.
11. ¿Cómo diseñar casos de prueba de interfaz?
Respuesta: Generalmente, se deben considerar los siguientes aspectos al diseñar casos de prueba de interfaz:
①Si se cumplen las condiciones previas Algunas interfaces deben cumplir las condiciones previas antes de poder obtener datos correctamente. Por lo general, es necesario iniciar sesión en Token Caso de uso inverso: diseñar 0 ~ n casos de uso para determinar si se cumplen las condiciones previas (asumiendo n condiciones)
② Si se deben llevar parámetros de valor predeterminado Caso de uso siguiente: los parámetros con valores predeterminados no se completan ni se pasan Parámetro, los parámetros obligatorios se completan con valores "normales" correctos y existentes, otros no se completan, diseño 1 caso de uso
③Reglas comerciales, requisitos funcionales Aquí, de acuerdo con la situación del tiempo, combinado con la descripción del parámetro de la interfaz, puede ser necesario diseñar N casos de uso hacia adelante y hacia atrás Caso de uso
④Si el parámetro es obligatorio. Caso de uso inverso: para cada parámetro requerido, diseñe un caso de uso inverso con un valor de parámetro vacío.
⑤ Si hay correlaciones entre parámetros. Algunos parámetros son mutuamente restrictivos.
⑥ Límite de tipo de datos de parámetro inverso Caso de uso: diseñar un caso de uso inverso para cada parámetro que no coincida con el tipo de valor del parámetro
⑦ El valor del rango de datos del tipo de datos del parámetro en sí es limitado. Caso de uso positivo: para todos los parámetros, diseñe un valor de parámetro de cada parámetro para que sea el más grande dentro del rango de datos Caso de uso positivo
12. ¿Qué prueba para la interfaz?
Respuesta:
Prueba de usabilidad de acuerdo con el protocolo, método, contenido de formato acordado, transferir datos a la interfaz y devolver el resultado esperado después del procesamiento:
Si la función de la interfaz está implementada correctamente;
Prueba de valor de retorno: el valor de retorno debe ser correcto además del contenido y el tipo. Asegúrese de que la persona que llama pueda analizar correctamente;
Valor límite del valor del parámetro, prueba de clase de equivalencia; Prueba de manejo de errores y excepciones
Ingrese un valor anormal (valor nulo, carácter especial, excediendo la longitud acordada, etc.), la interfaz puede manejarlo correctamente y responder como se esperaba ;
parámetros de entrada incorrectos, la interfaz puede manejar correctamente, como respuesta esperada;
entrada múltiple, menos parámetros de entrada, la interfaz puede manejar correctamente, y la respuesta esperada
(por ejemplo, formato escrito formato json) prueba de error de transmisión de datos de formato ; seguridad La prueba de seguridad se refiere principalmente a la seguridad de los datos transmitidos:
Si los datos confidenciales (como contraseñas, claves secretas, etc.) están encriptados para su transmisión;
Si los datos devueltos contienen datos confidenciales, como contraseñas de usuario, información completa de la cuenta bancaria del usuario, etc .;
Si la interfaz es correcta. Se verifica la seguridad de los datos entrantes, como la identificación de identidad más una verificación similar de token;
Si la interfaz previene solicitudes maliciosas (como una gran cantidad de solicitudes falsificadas que hacen que el servidor se bloquee); Pruebas de rendimiento, como tiempo de respuesta de la interfaz, capacidades de procesamiento simultáneo, pruebas de estrés Situación de manejo:
Solicitudes concurrentes para la misma interfaz (especialmente solicitudes POST), manejo de la interfaz (como insertar el mismo registro, causar errores de datos y fallas del sistema); Code Testing Institute
El tiempo de respuesta de la interfaz está dentro de la tolerancia del usuario Realizar una prueba de esfuerzo en la interfaz con una gran cantidad de solicitudes para determinar si el mayor punto de cuello de botella satisface las necesidades comerciales actuales;
13. ¿Qué herramientas se utilizan comúnmente para probar interfaces?
Respuesta: Herramientas de prueba de interfaz de protocolo http de uso común, como: cartero, fiddler, jmeter; la interfaz de servicio web utiliza SoapUI, jmeter, etc.
14. Si no hay un documento de interfaz, ¿cómo realizar la prueba de interfaz?
Esta pregunta evalúa principalmente la inteligencia emocional, que es la capacidad de engañar al entrevistador en general. También es una prueba a ciegas cuando ingresa. Esté preparado para volver en cualquier momento. Por supuesto, no debe responder la
respuesta inesperada del entrevistador : use la herramienta de captura de paquetes Tome la interfaz y luego realice pruebas específicas; si la información de campo en la interfaz no es clara, encuentre tiempo para
concentrarse en buscar soluciones de desarrollo. (Herramientas de captura de uso común Fiddler, Charles, etc.)
15. En el proceso de prueba de interfaz manual o prueba de interfaz automatizada, ¿cómo lidiar con las dependencias de datos en interfaces ascendentes y descendentes?
Respuesta: Use una variable global para procesar datos dependientes, como devolver un token después de iniciar sesión. Otras interfaces necesitan este token, luego usan variables globales para pasar los parámetros del token.
16. ¿Cómo probar interfaces que se basan en datos de terceros?
R: Simulacro Luego, el entrevistador le preguntará si es un simulacro, luego continuará cavando a lo largo del pozo y construyendo un servicio simulado. Consulte este http://www.51ste.com/share/det-485.html
17. En la prueba de interfaz, ¿cómo probar la interfaz que depende del estado de inicio de sesión?
Respuesta: La naturaleza de la interfaz que se basa en el estado de inicio de sesión es que cada vez que se envía una solicitud, se requiere que se envíe una sesión o cookie correctamente, y se agrega la sesión o cookie necesaria al construir una solicitud POST.
18. Cómo simular una red débil para realizar pruebas
? Respuesta: Tanto Fiddler como Charles pueden simular una prueba de red débil. La simulación habitual de pérdida de paquetes es también una simulación de una prueba de red débil. Con
el cuerpo se puede ver "varios métodos de simulación de red débil, siempre hay un derecho para usted".
19. ¿Qué errores ha encontrado en el proceso de prueba de la interfaz?
El entrevistador hizo esta pregunta principalmente para saber si realmente hiciste la prueba de interfaz. Después de todo, los currículums de muchos socios pequeños están empaquetados (sin empaque, no hay oportunidad de entrevista, no hay forma, para sobrevivir, de entender)
R:
Errores generales , La interfaz no está implementada, el resultado no se devuelve según lo acordado, el error de procesamiento del valor límite, etc. Ingrese valores anormales (valores nulos, caracteres especiales, excediendo la longitud acordada, etc.), la interfaz arroja errores y no se realiza ningún encapsulado; ingrese parámetros incorrectos, más entrada, menos parámetros de entrada,
posibles errores en la interfaz; problemas de seguridad, como transmisión de texto claro , El resultado devuelto contiene información confidencial, sin verificación de la información de identidad del usuario, sin interceptación de solicitudes maliciosas, etc .;
problemas de rendimiento, como la inserción simultánea de múltiples operaciones idénticas en la interfaz, tiempo de respuesta demasiado largo y cuellos de botella en la prueba de presión de la interfaz;
20. Cuando una interfaz es anormal, ¿cómo analiza la anormalidad?
Respuesta: Primero capture el paquete, use la herramienta fiddler (charles) para capturar el paquete, o la herramienta de depuración F12 en el navegador; si está en la APLICACIÓN, luego use Fiddler como proxy, configure el proxy a través del teléfono móvil para ver la solicitud y devolver los mensajes; ver el registro de backend , Por ejemplo, si el sistema Linux se conecta al servidor a través de xhell, verifique el registro de la interfaz para ver si hay algún mensaje de error (comando: tail -f log file);
21. ¿Cómo analizar si un error es front-end o back-end?
Respuesta: Cuando solemos mencionar errores, el desarrollo de front-end y el desarrollo de back-end siempre están discutiendo, sin admitir que es un error del otro lado. Esta situación es fácil de juzgar. Primero tome el paquete y mire el mensaje de solicitud, y mire el documento de la interfaz para ver si hay algún problema con el mensaje de solicitud. Si hay un problema, los datos enviados por el front-end son incorrectos; el mensaje de solicitud está bien, luego mire el mensaje de respuesta. Los datos devueltos son incorrectos, ese es el problema del desarrollo de back-end.
22. ¿Automatizan las pruebas de interfaz?
Respuesta: Para una gran cantidad de aplicaciones, generalmente se recomienda automatizar las pruebas de interfaz, lo que tiene bajos costos de mantenimiento y altos retornos. Hay muchas herramientas de uso común, como Jmeter, Robot Framework, pytest, etc.
23. ¿Cuántos oyentes de JMeter se enumeran?
Algunos oyentes de JMeter son: Informe de recopilación Informe de resumen Ver árbol de resultados Ver resultados en tablas Resultados de gráficos Informes de resumen de BeanShell Listener, etc.
24. Pruebas basadas en datos en python
En unittest, no hay un controlador de datos incorporado, tenemos que usar ddt para lograrlo. Primero, tenemos que instalar ddt en el entorno de ejecución de python y usar el siguiente comando para instalar pip install ddt. Otro marco de prueba, pytest, tiene su propia implementación basada en datos. Está parametrizado por @ pytest.mark.parametrize (argnames, argvalues). También puede usar Python para leer y manejar datos según sus necesidades.
25. ¿Cómo lidiar con la asociación en la automatización de interfaces?
Pase el resultado devuelto por la solicitud anterior a los parámetros de la siguiente solicitud, refleje el resultado de la solicitud a un atributo de clase (utilizando la función setattr ()) y llame a este atributo de clase en la siguiente solicitud
26. ¿Cómo verificar los resultados de las pruebas automatizadas?
Afirmar, el resultado esperado se compara con el resultado real
, y los datos en la base de datos se verifican de acuerdo con el escenario de prueba y los datos antes de comparar la solicitud.
27. ¿Cuál es el marco de prueba utilizado para la automatización?
Describa brevemente el diseño y mantenimiento del marco de automatización. El
marco de prueba: python + unittest + solicitudes + ddt + openpyxl + pymysql + logging
python: entrada simple, sintaxis simple
unittest: define una clase de caso de prueba y métodos específicos para mantener el ciclo de vida de los casos de prueba, Comportamiento del escenario de prueba, escenario previo del caso de prueba, comportamiento, resultado esperado, resultado real, método de afirmación,
solicitudes del método de desmontaje de la configuración : llamada de interfaz, biblioteca que admite solicitud http, API concisa, que proporciona diferentes métodos de solicitud http, sesión de soporte, cookies,
ddt: basado en datos, decorador de clase ddt, decorador de métodos de prueba de datos desempaquetar desempaqueta tipos de datos iterables,
usuarios comunes, bases de datos,
archivos de configuración (datos básicos) openpyxl: administración de datos, datos de administración de Excel, use el módulo openpyxl para realizar datos de Excel
Lectura y escritura (excle, csv, json, yaml, txt puede administrar datos de prueba) pymysql: interacción de base de datos, verificación de datos
eval, json: conversión de formato de datos Eval convierte el formato soportado por python en el formato correspondiente
logging: log Procesamiento, formato de salida de registro unificado, canal, nivel, registro de resultados de ejecución, fácil de localizar el problema
jenkins: integración continua
2 / ideas de diseño del marco: basado en datos + estratificación estructural (legibilidad, mantenibilidad, escalabilidad)
basado en datos : Separar los datos de mantenimiento del código, comportamiento coherente de la llamada de interfaz, impulsar diferentes escenarios de prueba para diferentes combinaciones de parámetros y reducir la redundancia del código.
Capa de estructura: capa de datos + capa de caso de uso + capa lógica Capa de
datos: datos de prueba compatibles con datos.xls
Capa de caso de uso: ejecución de caso de uso test_register.py test_recharge.py
capa lógica: encapsulación y extracción de métodos públicos doexcle.py do_mysql.py http_requests.py logger.py y otros módulos
3 / pasos de diseño del marco:
preparar datos de prueba: preparar tabla EXCEL para prueba Caso de uso: lectura de datos de Excel: valor de parámetro código de reemplazo
solicitud iniciada por el instituto de prueba : método de solicitud (método de obtención / publicación para encapsulación: empalme de URL (diferentes): los parámetros se convierten al diccionario
para obtener el valor de retorno de la solicitud: analizar el código de valor de retorno, Beneficios de la
afirmación de estado, información de mensajes
:
1. La combinación perfecta de casos de prueba automatizados y casos de prueba manuales, lo que reduce el trabajo repetitivo
2. Configuración flexible, puede cambiar los entornos de prueba y ejecutar casos de prueba de forma independiente
3. Las funciones comunes están encapsuladas, la lógica es clara y fácil de mantener
4 , Entrada de ejecución unificada, gestión del conjunto de casos de prueba: el
módulo run.py selecciona los casos de prueba que deben ejecutarse mediante búsqueda difusa
5. Integración continua, construcción regular, retroalimentación rápida
28. Específicamente, cómo aplicar la automatización a lo real en este proyecto y su análisis de los resultados de la automatización.
Después de completar el diseño y la implementación de todos los marcos de prueba automatizados, realice las pruebas de interfaz y luego
intégrelo en jenkins, configure la ejecución del tiempo, genere informes html, vea las tasas de aprobación de las pruebas y vea las funciones de la interfaz
. Las pruebas de regresión se realizan cada vez que se lanza la versión, nuevas funciones Antes del desarrollo y las pruebas