1. Caché de CPU
1. Introducción a la caché de la CPU
CPUCache es un almacenamiento temporal entre la CPU y la memoria, la capacidad es menor que la memoria pero la velocidad de intercambio es mucho más rápida que la memoria. La aparición de Cache es principalmente para resolver la contradicción entre la velocidad de operación de la CPU y la velocidad de lectura y escritura de la memoria, porque la velocidad de operación de la CPU es mucho más rápida que la velocidad de lectura y escritura de la memoria, lo que hará que la CPU pase mucho tiempo esperando que lleguen los datos o escribir datos en la memoria. Los datos en la caché son una pequeña parte de la memoria, pero la CPU accederá a ellos en poco tiempo. Cuando la CPU llama a una gran cantidad de datos, puede evitar la memoria y llamarla directamente desde la caché, acelerando así la lectura. La caché tiene un gran impacto en el rendimiento de la CPU, principalmente debido a la secuencia de intercambio de datos de la CPU y al ancho de banda entre la CPU y la caché.
El principio de funcionamiento de Cache es que cuando la CPU quiere leer un dato, primero lo busca en el Cache, si lo encuentra, lo lee de inmediato y lo envía a la CPU para su procesamiento; si no lo encuentra, lo lee de la memoria a una velocidad relativamente lenta y lo envía a la CPU. Procesar y, al mismo tiempo, transferir el bloque de datos donde se encuentran los datos a la caché, de modo que todo el bloque de datos se pueda leer de la caché en el futuro, sin tener que llamar a la memoria.
La tasa de aciertos de la CPU que lee la caché es muy alta (la mayoría de las CPU pueden alcanzar aproximadamente el 90%), lo que ahorra en gran medida el tiempo de la CPU leyendo directamente la memoria, y también hace que la CPU básicamente no tenga que esperar al leer datos.
De acuerdo con el orden de lectura de los datos y el grado de integración cercana con la CPU, la caché de la CPU se puede dividir en caché L1, caché L2 y caché L3. Todos los datos almacenados en cada nivel de caché son parte del siguiente nivel de caché. La dificultad técnica y el costo de fabricación están disminuyendo relativamente, por lo que su capacidad está aumentando relativamente. Cuando la CPU quiere leer un dato, primero lo busca en el caché L1, si no lo encuentra, luego lo busca en el caché L2, si aún no lo hace, lo busca en el caché L3 o en la memoria. Por lo general, la tasa de aciertos de cada nivel de caché es aproximadamente del 80%, es decir, el 80% del volumen total de datos se puede encontrar en el caché L1, y solo el 20% del volumen total de datos debe leerse desde el caché L2, el caché L3 o la memoria. Por lo tanto, la caché L1 es la parte más importante de la arquitectura de la caché de la CPU.
2. Estructura de la caché de la CPU
Entre las CPU Intel, no había caché en las CPU de la era 8086 y 80286, porque las velocidades de la CPU y la memoria no eran muy diferentes en ese momento, y la CPU accedía directamente a la memoria. Pero a partir de 80386, la velocidad de la CPU era mucho más rápida que la velocidad de acceso a la memoria. La caché apareció por primera vez y la caché más antigua no se colocó en el módulo de la CPU, sino en la placa base. El material de la caché de CPU, SRAM, es mucho más caro que la memoria DRAM y el tamaño está en MB. Por lo tanto, las computadoras modernas introducen caché de alta velocidad entre la CPU y la memoria como un canal entre la CPU y la memoria. Después de un desarrollo y evolución a largo plazo, las estructuras de caché de tres niveles L1, L2 y L3 han evolucionado gradualmente y todas están integradas en el chip de la CPU. 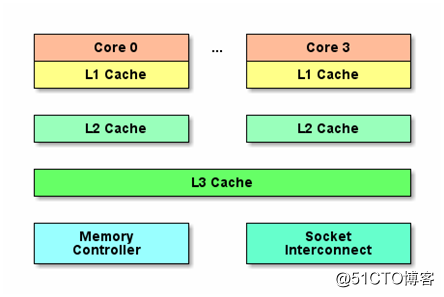
La caché L1 es la más cercana a la CPU y tiene la velocidad más rápida pero la capacidad más pequeña. La caché L1 de las CPU modernas se divide en dos: caché de datos y caché de instrucciones Las estrategias de actualización de instrucciones y datos no son las mismas, y debido a las instrucciones de longitud variable de CISC, la caché de instrucciones debe optimizarse especialmente. Cada núcleo de CPU tiene su propia caché L1 y caché L2 independientes, pero la caché L3 generalmente es compartida por toda la CPU.
3. Ver la caché de la CPU
Los desarrolladores del kernel de Linux definen el sistema CPUFreq para ver información detallada de la CPU, y el directorio / sys / devices / system / cpu guarda información detallada de la CPU.
Vista de caché L1 Vista de caché 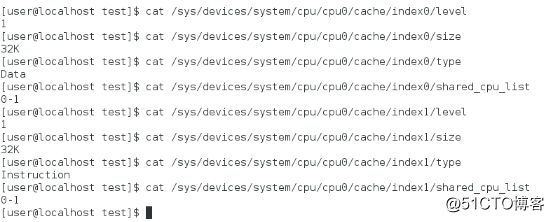
L2 Vista de caché 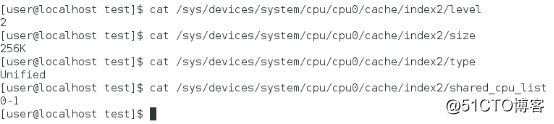
L3 El 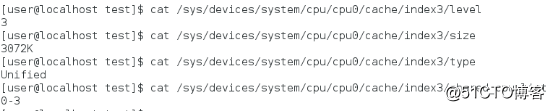
comando de vista de caché de CPU es el siguiente:
dmidecode -t cache
getconf -a | grep CACHE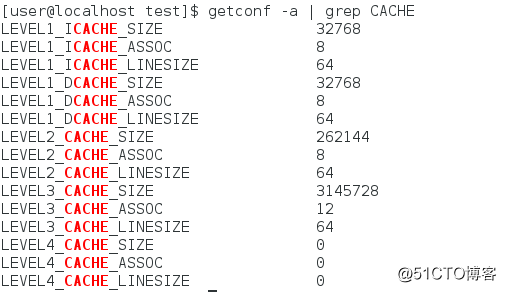
La CPU solo tiene caché de nivel 3, L4 es 0, caché de datos de caché L1 y caché de instrucciones son 32 KB, caché L2 es 256 KB, caché L3 es 3 MB y la línea de caché es 64 bytes. ASSOC representa la estrategia de mapear la dirección de la memoria principal a la caché. L1 y L2 son asociativas de grupo de 8 vías, y L3 es asociativa de grupo de 12 vías.
El caché de datos y el caché de instrucciones en el caché L1 son compartidos por los núcleos físicos de la CPU, por lo que los núcleos lógicos de la CPU CPU0 y CPU1 virtualizados por la tecnología Hyper-Threading comparten el caché L1.
4, línea de caché
La línea de caché es la unidad de caché más pequeña en la caché de la CPU y es la unidad básica cuando el nivel actual de caché obtiene datos del siguiente nivel. El tamaño actual de la línea de caché de la caché de la CPU principal es de 64 bytes, es decir, cuando el programa necesita leer un byte de la memoria, los 63 bytes adyacentes se cargarán desde la memoria a la caché de la CPU al mismo tiempo, cuando la CPU acceda a la memoria caché adyacente. Cuando se almacenan los datos, los datos no se leen de la memoria, pero se puede acceder a los datos desde el caché de la CPU, lo que mejora la velocidad.
El tamaño de la línea de caché de L1, L2 y L3 son todos de 64 bytes, que se pueden ver de la siguiente manera: cat /sys/devices/system/cpu/cpu0/cache/index0/coherency_line_size
Consulte los indicadores de rendimiento de los registros de la CPU, la caché y la memoria. 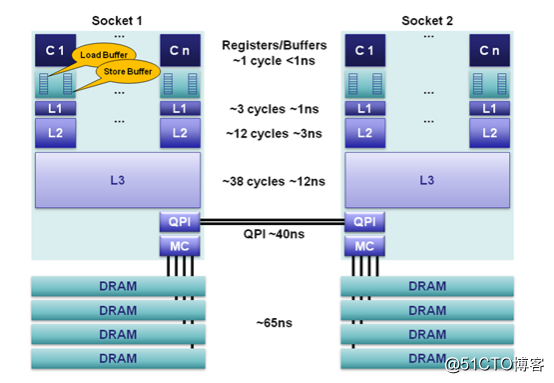
Los datos a los que accede la CPU se almacenan en la caché, lo que se denomina un acierto, y viceversa. Llamada señorita (desaparecida).
Cuando la CPU intenta cargar datos desde una determinada dirección, primero verifica si son aciertos desde la caché L1 y devuelve los datos a la CPU si aciertos. Si falta la caché L1, continúe buscando desde la caché L2. Cuando llega la caché L2, los datos se devolverán a la caché L1 y a la CPU. Si también faltan L2 Cache y L3 Cache, debe cargar datos desde la memoria principal y devolver los datos a L3 Cache, L2 Cache, L1 Cache y CPU.
5. Consistencia de la caché de varios núcleos
Cada núcleo de CPU tiene una caché L1 privada. Para CPU de varios núcleos, las cachés L1 entre diferentes núcleos de CPU deben ser coherentes.
(1) Protocolo de búsqueda de bus
Cuando un núcleo de CPU modifica su propia caché privada, el hardware transmitirá notificaciones a todos los demás núcleos de CPU en el bus. Cada núcleo de CPU tiene hardware especial para monitorear eventos de transmisión y verificar si los mismos datos están almacenados en su propia caché.
Bus Snooping necesita monitorear todas las actividades en el bus en todo momento, lo que aumenta la carga del bus hasta cierto punto y aumenta el retardo de lectura y escritura.
(2) Protocolo MESI El protocolo
MESI es un protocolo que utiliza un mecanismo de máquina de estado para reducir la presión del ancho de banda para mantener la coherencia de la caché de varios núcleos.
El nombre del protocolo MESI proviene de las abreviaturas de los cuatro estados Modificado, Exclusivo, Compartido e No válido de la línea de caché. Cuando el estado de la línea de caché es el estado Modificado o Exclusivo, la modificación de sus datos no necesita enviar mensajes a otras CPU, lo que reduce la presión del ancho de banda hasta cierto punto.
La coherencia de la caché de varios núcleos está garantizada por el hardware. El protocolo de coherencia adoptado por el hardware de CPU moderno suele ser una variante del protocolo MESI. Por ejemplo, la arquitectura ARM64 utiliza el protocolo MOESI.
Dos, TLB
1. Introducción a MMU
MMU (Unidad de gestión de memoria) es un circuito de hardware que convierte direcciones virtuales en direcciones físicas a través de un mecanismo de segmento y un mecanismo de página, y generalmente está integrado en el chip de la CPU. 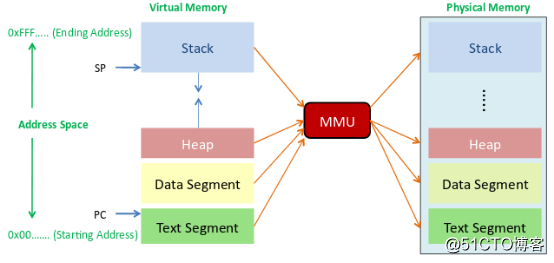
MMU completa la conversión de dirección virtual a dirección física estableciendo una tabla de páginas. Cuando es necesario acceder a un dato en la memoria, la tabla de páginas se busca a través de la dirección virtual de los datos. Una vez que se accede a la tabla de páginas, los datos en la memoria se direccionan a través de la dirección física encontrada. Si no hay ningún acierto en la tabla de páginas, significa que la dirección virtual de datos a la asignación de direcciones físicas no está establecida en la tabla de páginas, y la entrada de asignación de datos de la tabla de páginas se establece a través de la excepción de página faltante.
Para los datos constantes de uso frecuente, los datos de búsqueda y las entradas de la tabla de páginas correspondientes se realizan cada vez. Para acelerar la búsqueda de tablas de páginas y reducir la duplicación innecesaria, se introduce TLB.
2. Introducción a TLB
TLB (Translation Look-aside Buffer) se usa específicamente para almacenar en caché las entradas de la tabla de páginas en la memoria, y generalmente está integrado dentro de la MMU. TLB es una caché pequeña. El número de entradas de TLB es relativamente pequeño. Cada entrada de TLB contiene información sobre una página, como bits válidos, números de página virtual, bits modificados y números de trama de página física. Cuando el procesador desea acceder a una dirección virtual, primero buscará en la TLB. Si no hay ningún acierto en la entrada de la tabla TLB, es necesario acceder a la tabla de páginas para calcular la dirección física correspondiente. Si hay un acierto en la entrada de TLB, la dirección física se obtiene directamente de la entrada de TLB.
La unidad básica almacenada en el TLB es la entrada de la tabla de TLB. Cuanto mayor sea la capacidad de TLB, más entradas de la tabla de TLB se pueden almacenar y mayor será la tasa de aciertos de TLB. Sin embargo, la capacidad de TLB es limitada. Actualmente, el kernel de Linux usa páginas pequeñas de 4 KB de forma predeterminada. Si un programa usa 512 páginas pequeñas, es decir, de 2 MB de tamaño, se requieren al menos 512 entradas de TLB para garantizar que no aparezca TLB Miss. Sin embargo, si se utiliza una página grande de 2 MB, solo se requiere una entrada de TLB para garantizar que no aparezca TLB Miss. Para aplicaciones grandes que consumen memoria en GB, también puede usar páginas grandes en 1GB para reducir TLB Miss. 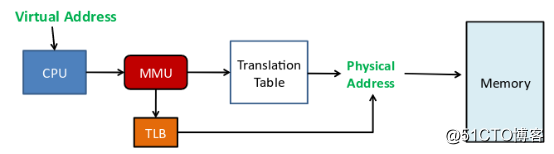
La esencia de la TLB es la caché de la tabla de páginas La TLB almacena en caché las entradas de la tabla de páginas de los datos usados más recientemente (la asignación de direcciones virtuales a direcciones físicas). La aparición de TLB tiene como objetivo acelerar la velocidad de acceso a los datos de la memoria y reducir las búsquedas repetidas en la tabla de páginas. No es necesario, pero TLB puede aumentar la velocidad de acceso a los datos de la memoria.
3. Principio TLB
Cuando la CPU quiere acceder a una dirección virtual / dirección lineal, la CPU primero busca en el TLB de acuerdo con los 20 bits superiores de la dirección virtual (arquitectura X86). Si no hay ningún resultado en la tabla, la dirección física correspondiente debe calcularse accediendo a la tabla de páginas en la RAM lenta. Al mismo tiempo, la dirección física se almacena en una entrada TLB y los accesos posteriores a la misma dirección lineal pueden obtener directamente la dirección física de la entrada TLB.
La estructura de TLB es la siguiente: 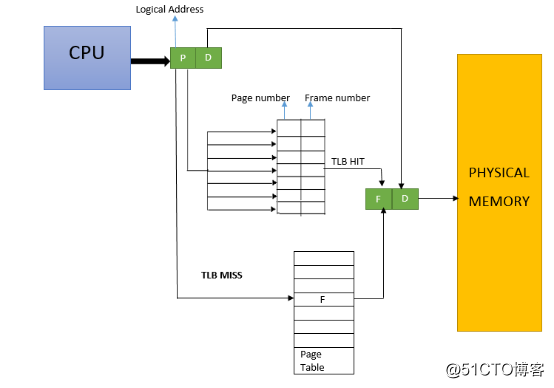
si uno necesita acceder a un dato en la memoria, dada la dirección virtual de los datos, consulte el TLB y encuentre que existe (hit), obtenga la dirección física directamente y lea los datos en la memoria de acuerdo con la dirección física. Si no se pierde el TLB, solo se puede encontrar a través de la tabla de páginas.
4. Método de mapeo TLB
La unidad básica almacenada en el TLB es la entrada de la tabla TLB, que corresponde a la entrada de la tabla de páginas almacenada en la RAM. El tamaño de la entrada de la tabla de páginas es fijo, por lo que cuanto mayor sea la capacidad de TLB, más entradas de la tabla de páginas se pueden almacenar, mayor será el impacto de TLB. Pero la capacidad de TLB es limitada después de todo, por lo que la tabla de páginas RAM y las entradas de la tabla TLB no pueden tener una correspondencia uno a uno.
(1) Completamente conectado
. No hay relación entre las entradas en la caché de TLB y la dirección lineal. Una entrada de TLB se puede asociar con la entrada de la tabla de páginas de cualquier dirección lineal. El método de asociación completamente conectado maximiza la utilización del espacio de entrada de la tabla TLB, pero el retraso también puede ser grande. Debido a que cada solicitud de CPU, el hardware de TLB compara la dirección lineal con la entrada de la tabla TLB una por una hasta que la TLB llega o se comparan todas las entradas de la tabla TLB. llevar a cabo. A medida que la memoria caché de la CPU aumenta cada vez más, se requiere una gran cantidad de entradas TLB, por lo que solo es adecuada para TLB de pequeña capacidad.
(2) La coincidencia directa de
cada bloque de dirección lineal puede corresponder a una entrada de TLB única a través de la operación de módulo. Solo se requiere una comparación, lo que reduce el retraso en el TLB, pero el conflicto es muy grande, lo que lleva a la aparición de TLB fallado y reduce La tasa de aciertos.
(3) Conexión de grupo
Para resolver los conflictos de baja eficiencia y coincidencia directa dentro de Full Connection, se introduce la conexión de grupo. La concatenación de grupos divide todas las entradas de la tabla TLB en varios grupos, y cada bloque de dirección lineal ya no corresponde a una entrada de la tabla TLB, sino a un grupo de entradas de la tabla TLB. Cuando la CPU realiza la conversión de dirección, primero calcula a qué grupo de entrada de TLB corresponde el bloque de dirección lineal y luego lo compara en orden en el grupo de entrada de TLB. Según la longitud del grupo, se puede dividir en 2 rutas, 4 rutas y 8 rutas.
Después de una práctica de ingeniería a largo plazo, se descubre que la conexión de grupo de 8 vías es un punto de demarcación de rendimiento. La tasa de aciertos conectados en grupo de 8 vías es equivalente a la tasa de aciertos totalmente conectados. Si es más de 8 vías, las desventajas causadas por el retardo de comparación intragrupo excederán la ventaja de la tasa de aciertos mejorada.
3. Tecnología Hyper-Threading
1. Introducción a la tecnología Hyper-Threading
La tecnología Hyperthreading (Hyperthreading) simula dos núcleos lógicos en un núcleo físico. Los dos núcleos lógicos tienen sus propios registros independientes (eax, ebx, ecx, msr, etc.) y APIC, pero comparten los recursos de ejecución del núcleo físico, incluidos Motor de ejecución, caché L1 / L2, TLB, bus del sistema, etc.
2. El impacto del Hyper-Threading en el rendimiento
La tecnología Hyper-Threading solo usa dos descriptores de tareas físicas en un núcleo físico, y la potencia informática física no ha aumentado. La aplicación está diseñada con varios trabajadores. Con la ayuda de hyperthreading, dos trabajadores programados en el mismo núcleo con diferentes hyperthreads pueden compartir Cache y TLB, lo que reduce en gran medida la sobrecarga de conmutación de tareas. Cuando un trabajador no está ocupado, el hyperthreading permite que otros trabajadores utilicen recursos informáticos físicos, lo que ayuda a mejorar el rendimiento general del núcleo físico. Sin embargo, debido a la competencia del hyperthreading por los recursos de ejecución del núcleo físico, el retraso en la ejecución del negocio aumentará en consecuencia. 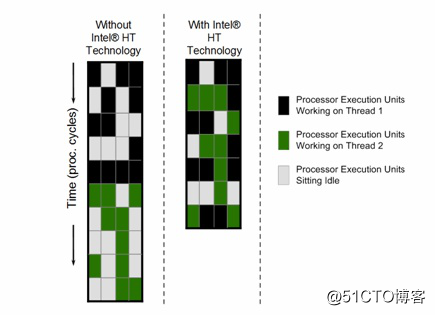
Después de activar Hyper-Threading, si se mejora la potencia informática total del núcleo físico y el alcance de la mejora está relacionado con el modelo de negocio. El aumento promedio es de aproximadamente 20% -30%.
Cuando Hyper-Threading compite entre sí, la potencia informática de Hyper-Threading se compara con la de Hyper-Threading El núcleo físico caerá aproximadamente un 30%
3. Aplicaciones con hiperproceso
Hyper-threading se activa o desactiva según el modelo de aplicación. Para tareas sensibles al retraso, se producirá una competencia de hyper-threading cuando la carga del nodo es demasiado alta y el tiempo de ejecución de la tarea aumentará significativamente. Hyper-threading debe desactivarse; para tareas de computación en segundo plano, se recomienda activar Hyper-Threading. Los subprocesos aumentan el rendimiento de todo el nodo.
Cuatro, tecnología NUMA
1. Introducción a NUMA
Antes de la aparición de la arquitectura NUMA, el desarrollo de las CPU en la dirección de las altas frecuencias se vio desafiado por límites físicos y se dirigieron a la dirección de múltiples núcleos. Dado que todos los núcleos de CPU comparten un puente norte para leer la memoria, a medida que aumenta el número de núcleos de CPU, el cuello de botella en el rendimiento del puente norte en el tiempo de respuesta se vuelve cada vez más obvio. Por lo tanto, los diseñadores de hardware dividen el controlador de memoria del North Bridge y los dividen por igual en cada núcleo de CPU, es decir, la arquitectura NUMA.
NUMA (acceso a memoria no uniforme) se originó a partir de la microarquitectura AMD Opteron y fue adoptado por Intel Nehalem al mismo tiempo.
La arquitectura NUMA divide todo el servidor en varios nodos, cada uno con una CPU y una memoria independientes. Solo cuando la CPU acceda a la dirección física correspondiente a la memoria de su propio nodo tendrá un tiempo de respuesta más corto (luego llamado Acceso Local). Si necesita acceder a los datos en la memoria de otros nodos, debe acceder a ellos a través del canal de interconexión y el tiempo de respuesta es más lento que antes (en adelante, acceso remoto). Por lo tanto, NUMA (Non-Uniform Memory Access) se denomina
dentro de Node. Su arquitectura es similar a SMP. Utiliza IMC Bus para la comunicación entre diferentes núcleos; diferentes Nodos se comunican a través de QPI (Quick Path Interconnect). 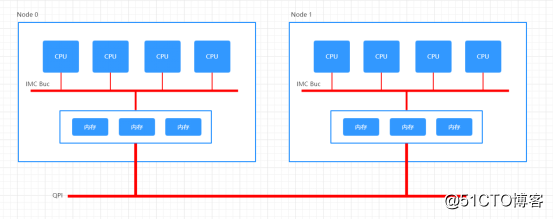
Un Socket (ranura de memoria) corresponde a un Nodo, la latencia QPI es mayor que la del Bus IMC y el acceso de la CPU a la memoria es lejano y cercano (remoto / local).
2. Defectos NUMA
La estrategia de asignación de memoria de la arquitectura NUMA es injusta para los procesos o subprocesos. En RHEL Linux, localalloc es la estrategia de asignación de memoria predeterminada de NUMA, es decir, solicitar la asignación de memoria del nodo actual hará que el programa exclusivo de recursos utilice fácilmente la memoria de un nodo determinado. Cuando se agota la memoria de un nodo, Linux simplemente asigna el nodo de la CPU a un proceso (o subproceso) que consume mucha memoria, y el intercambio se generará en este momento.
3. Aplicación NUMA
(1) BIOS cierra el
menú de configuración de memoria de BIOS NUMA para encontrar el elemento Node Interleaving, establecido en Disabled significa para habilitar NUMA, el modo de acceso no uniforme es la configuración predeterminada; establecido en Enabled significa cerrar NUMA, y usar SMP para habilitar el modo de intercalación de memoria.
(2)
Utilice numactl -interleave = all para modificar la estrategia NUMA antes de cerrar NUMA en el nivel de software e iniciar la aplicación.
Si la aplicación ocupará una gran cantidad de memoria, debe optar por desactivar el límite del nodo NUMA (o desactivar NUMA del hardware); si la aplicación no ocupa una gran cantidad de memoria, pero requiere un tiempo de ejecución del programa más rápido, debe optar por restringir el acceso a este método de nodo NUMA. Procesar.
Verifique si NUMA está habilitado en el BIOS. grep -i numa /var/log/dmesg
Verifique el nodo NUMA numactl --hardware
lscpu del sistema actual . 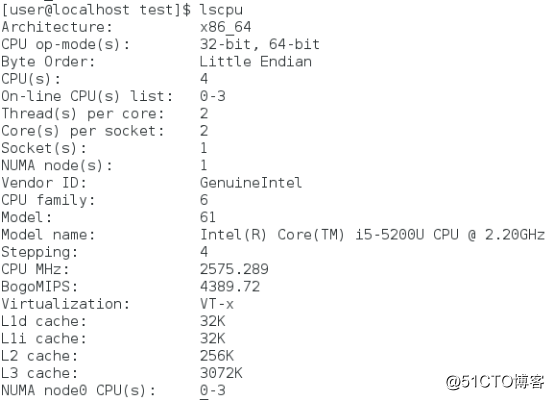
Verifique los datos de memoria
numastat. 
Cuando se encuentra que el valor de numa_miss es relativamente alto, indica que la estrategia de asignación debe ajustarse, como vincular el proceso a la CPU especificada para mejorar la tasa de aciertos de la memoria.
En Linux con la compatibilidad con NUMA habilitada, Kernel no migrará la memoria de tareas de un nodo NUMA a otro nodo NUMA.
Una vez que se inicia el proceso, no se migrará el nodo NUMA donde se encuentra. Para optimizar el rendimiento al máximo, en la programación normal, el núcleo de la CPU también utilizará el núcleo local al que se puede acceder de forma local tanto como sea posible durante todo el ciclo de vida del proceso. El nodo NUMA permanece sin cambios.
Una vez que la carga de un nodo NUMA excede el umbral de otro nodo (25% por defecto), se considera que la carga debe reducirse en este nodo. Para diferentes estructuras NUMA y diferentes condiciones de carga, el sistema ve la migración de una tarea retrasada. Similar al algoritmo de copa con fugas. En este caso, se producirá el acceso remoto a la memoria.
Existen diferentes estructuras topológicas entre nodos NUMA, y el acceso entre diferentes nodos tendrá un concepto de distancia, que se puede comprobar con numactl -H.
4, nodo NUMA
numactl [--interleave nodes] [--preferred node] [--membind nodes] [--cpunodebind nodes] [--physcpubind cpus] [--localalloc] command
--interleave = nodes, -i nodos se utilizan para establecer el modo de asignación de intercalado de memoria.Cuando el sistema asigna espacio de memoria para varios nodos, se asignará a varios nodos en un método de distribución de sondeo. Si el nodo de destino entre los numerosos nodos de memoria de asignación intercalados actuales no puede asignar el espacio de memoria correctamente, el espacio de memoria será asignado por otros nodos.
--membind = nodes, -m nodos asignan espacio de memoria del nodo especificado. Si el nodo no tiene suficiente espacio de memoria, la operación de asignación fallará.
--cpunodebind = nodos, -N nodos se utilizan para vincular procesos al nodo de la CPU.
--physcpubind, -C cpus se usa para vincular el proceso al núcleo de la CPU.
--localalloc, -l Inicia el proceso y asigna memoria en el nodo de CPU actual.
--preferred = node se utiliza para especificar el nodo que asigna preferentemente espacio de memoria. Si no se puede asignar espacio en el nodo, se asignará desde otros nodos. numactl --cpubind=0 --membind=0 python paramnumactl --show
El mecanismo actual de NUMA numactl --hardware
muestra cuántos nodos están disponibles en el sistema actual. numactl [--huge] [--offset offset] [--shmmode shmmode] [--length length] [--strict]
Crear segmento de memoria compartida