Este artículo es el primero de una serie de artículos sobre programación Java de baja latencia. Después de leer este artículo, dominará los siguientes conceptos:
¿Qué es la latencia y por qué debería preocuparse por la latencia como desarrollador?
¿Cómo describir el retraso y qué significa el porcentaje en los datos?
¿Qué causa el retraso?
Sin más preámbulos, comencemos.
1. ¿Qué es el retraso y por qué es importante?
La demora se puede definir simplemente como el tiempo que lleva realizar una operación.
"Operación (operación)" es un término amplio, aquí me refiero al comportamiento que vale la pena medir en el sistema de software y la ejecución del comportamiento en un momento determinado.
Por ejemplo, en una aplicación web típica, la operación puede ser enviar una consulta desde un navegador y ver los resultados de la búsqueda; en una aplicación de negociación, puede ser una herramienta de negociación financiera que envía automáticamente una instrucción de compra y venta al intercambio después de recibir un cambio de precio. Generalmente, cuanto más breve sea la operación, mayor será el beneficio para el usuario. Los usuarios prefieren las aplicaciones de red que no necesitan esperar. En retrospectiva, la mayor ventaja de Google sobre otros motores de búsqueda de su época es su rápida experiencia de búsqueda. Cuanto más rápido reaccione el sistema de comercio a los cambios del mercado, mayor será la probabilidad de éxito en el comercio. Cientos de empresas comerciales están obsesionadas con hacer de su motor comercial el sistema de latencia más baja de Wall Street y, por lo tanto, obtener una ventaja competitiva.
¡No es exagerado decir que en áreas de alto riesgo, reducir la latencia puede determinar el éxito o el fracaso de una empresa!
2. ¿Cómo describir el retraso?
Cada operación tiene un retraso y cien operaciones tienen cien retrasos. Por lo tanto, un solo indicador como "operaciones / segundo" o "segundos / operación" no se puede usar para describir el retraso del sistema, porque solo se puede usar para describir una sola ejecución de una operación.
A primera vista, el retraso se puede definir como el promedio de todas las operaciones similares. No es buena idea.
¿Hay algún problema con el promedio? Considere la siguiente imagen:
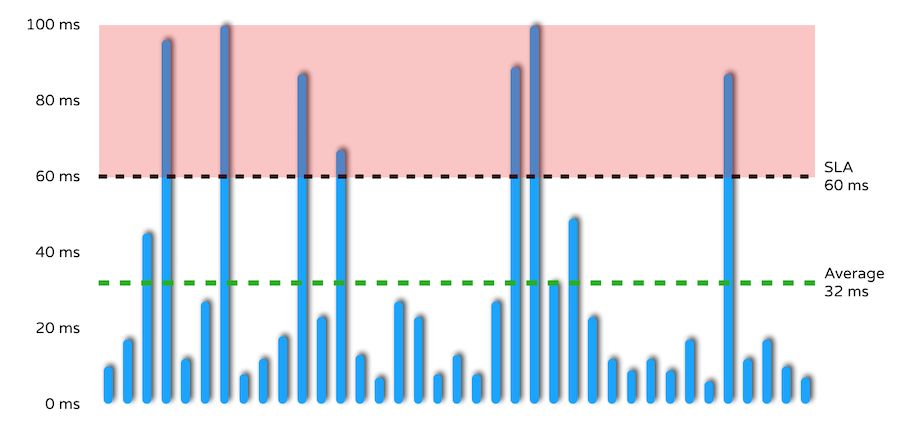
Hay varios objetivos de SLA (en realidad 7) que tienen un grado de operación superior a 60 milisegundos, pero el tiempo de respuesta promedio está dentro del rango de SLA. Una vez que se adopta el tiempo de respuesta promedio, se ignorarán todos los valores atípicos en el área roja. Sin embargo, los valores atípicos ignorados son precisamente los datos más importantes para los ingenieros de software, es decir, problemas de rendimiento del sistema a los que se debe prestar atención y resolver. Para empeorar las cosas, los problemas ocultos detrás de estos datos a menudo ocurren en entornos de producción reales.
También vale la pena señalar que, de hecho, muchos resultados de la medición de retardo pueden ser como se ve en la figura anterior, y ocasionalmente se pueden ver algunos valores atípicos serios al azar. El retraso nunca sigue la distribución normal, la distribución gaussiana o la distribución de Poisson, es más probable que sea un retraso de distribución multimodal. De hecho, esta es la razón por la que no es válido usar la desviación estándar o la media para discutir el retraso.
La demora se describe mejor en porcentaje.
¿Qué es un percentil? Considere un conjunto de números, el percentil n (donde `0 <n <100`) lo divide en dos partes, la parte inferior contiene n% de los datos y la parte superior contiene (100-n) % Los datos. Por lo tanto, la suma de las dos partes de los datos es 100%.
Por ejemplo, 50% significa que la mitad está por debajo del 50% y la otra mitad está por encima del 50%. El término más conocido para los porcentajes es la mediana.
Démosle algunos ejemplos de medición de latencia. El 90% de retraso es de 75 milisegundos, lo que significa que 90 de las 100 operaciones tienen un retraso de como máximo 75 milisegundos, mientras que las operaciones restantes, es decir, 100-90 = 10, tienen un retraso de al menos 75 milisegundos.
Si agrega más, el 98% del retraso es de 170 milisegundos, lo que significa que 2 de cada 100 operaciones tienen un retraso de 170 milisegundos o más.
Si agrega más, el 99% de la demora es de 313 milisegundos, lo que significa que 1 de cada 100 operaciones tiene una demora mayor que otras operaciones.
De hecho, muchos sistemas exhiben características tales que incluso un aumento porcentual de latencia aumentará significativamente.
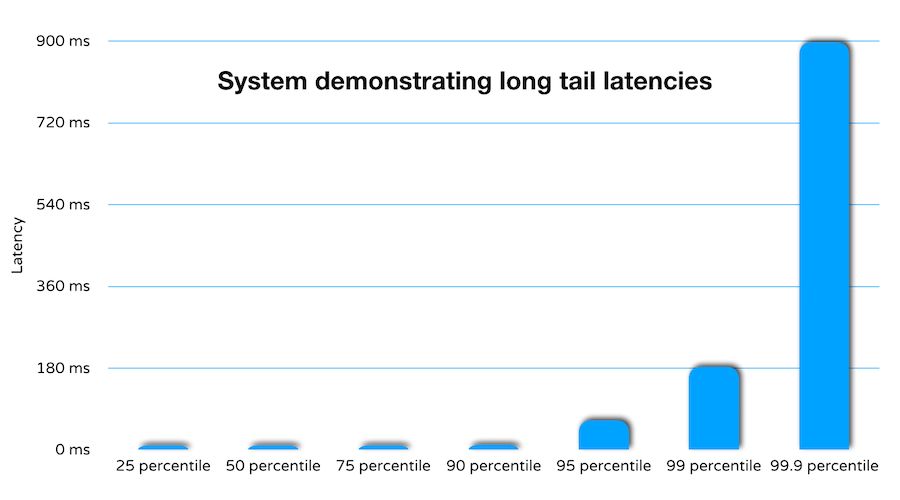
¿Por qué preocuparse por los retrasos prolongados? Quiero decir, si solo 1 de cada 100 operaciones tiene una latencia alta, ¿el rendimiento del sistema no es lo suficientemente bueno?
Bueno, para tener una impresión intuitiva, imagina la siguiente escena. Para un sitio web popular, el 90% se retrasa 1 segundo, el 95% se retrasa 2 segundos y el 99% se retrasa 25 segundos. Suponiendo que todas las páginas del sitio web tienen más de 1 millón de visitas diarias, eso significa que una determinada página se cargará más de 10,000 veces en más de 25 segundos. En este momento, el usuario puede cerrar el navegador con un bostezo y pasar a otras cosas, en peor situación se quejará con sus amigos y familiares de la mala experiencia. Ningún negocio en línea puede permitirse retrasos tan prolongados.
3. ¿Qué causó el retraso?
La respuesta más corta es: ¡todo es posible!
El retardo "jitter" producirá formas únicas y valores atípicos aleatorios, que se pueden atribuir a las siguientes cosas:
Interrupción de hardware
Latencia de red / E / S
Suspensión del programa de gestión
Actividades del sistema operativo, como reconstrucción de estructuras internas, limpieza de búferes, etc.
Cambio de contexto
Se detuvo la recolección de basura
Estos eventos suelen ser aleatorios y no siguen una distribución normal.
Además, desde un nivel superior, el funcionamiento del programa Java:
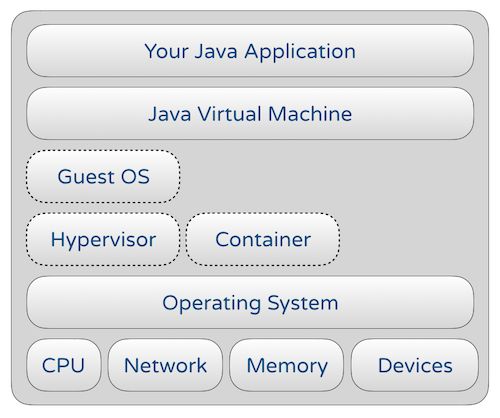
(Los hipervisores y contenedores son opcionales para hardware bare metal, pero están estrechamente relacionados con la latencia en entornos virtualizados o en la nube)
La reducción de la latencia está estrechamente relacionada con los siguientes factores:
Arquitectura de CPU / caché / memoria
Arquitectura y diseño de JVM
Programación de aplicaciones: simultaneidad, algoritmos de estructura de datos y almacenamiento en caché
Protocolo de red, etc.
Cada capa de la figura anterior es muy compleja, lo que aumenta en gran medida los conocimientos y las habilidades profesionales necesarios para la optimización del rendimiento, y es también la razón por la que se debe considerar en todo momento la racionalidad de costos y tiempos.
¡Pero es por eso que la ingeniería de rendimiento es tan interesante!
Nuestro desafío es mantener la latencia de la aplicación a un nivel razonablemente bajo para cada operación requerida.
¡fácil de decir difícil de hacer!