Hace algún tiempo, un compañero de clase encontró un problema al escribir SQL: dos conexiones SQL parecían ser iguales, pero el número de ellas era diferente. La razón es que la condición where después de la conexión izquierda filtra los datos, reduciendo los datos. Las dos piezas de sql son las siguientes:
select count(1)
from (select *
from KXAPP.I_CASH_LOAN_WHITELIST_C2_V_NEW b
where b.BG_DT < '20180820'
and b.EN_DT >= '20180904') gh
left join (select *
from KXAPP.I_CASH_LOAN_WISH_SCORE
where busi_dt = '20180820') hg
on gh.loan_no = hg.loan_noselect count(1)
from KXAPP.I_CASH_LOAN_WHITELIST_C2_V_NEW b
left join KXAPP.I_CASH_LOAN_WISH_SCORE c
on b.loan_no = c.loan_no
where b.BG_DT < '20180820'
and b.EN_DT >= '20180904'
and busi_dt = '20180820') hg
A primera vista, parece que no hay diferencia entre las dos secciones de sql. El primero es buscar primero la subtabla a través de la condición y luego vincular; el segundo es vincular primero y luego filtrar después de pasar la condición. Después de las estadísticas, se encuentra que la cantidad de datos en la parte superior es mayor que en la parte inferior.
De hecho, estos dos vínculos son diferentes. En el primer modo de enlace, la tabla principal es gh; en el segundo modo de enlace, la tabla principal es b. La razón por la que la cantidad de datos en el segundo método de enlace es menor que en el primer método de enlace es que donde se agrega después del enlace para filtrar los resultados del enlace.
Aquí hay un ejemplo para ilustrar:
La estructura de la Tabla A es la siguiente:
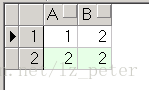
La estructura de la Tabla B es la siguiente:
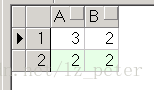
select *
from (select 1 as a, 2 as b
from dual
union all
select 2 as a, 2 as b from dual) a
left join (select 3 as a, 2 as b
from dual
union all
select 2 as a, 2 as b from dual) b
on a.a = b.a
and b.a = 1;
select *
from (select 1 as a, 2 as b
from dual
union all
select 2 as a, 2 as b from dual) a
left join (select 3 as a, 2 as b
from dual
union all
select 2 as a, 2 as b from dual) b
on a.a = b.a
where b.a = 1;