1. Antecedentes
Este artículo fue escrito la semana pasada después de que fui al salón de tecnología para escuchar Java Cache Road de iQiyi. Vamos a presentar brevemente el desarrollo de la ruta de caché de Java de iQIYI. 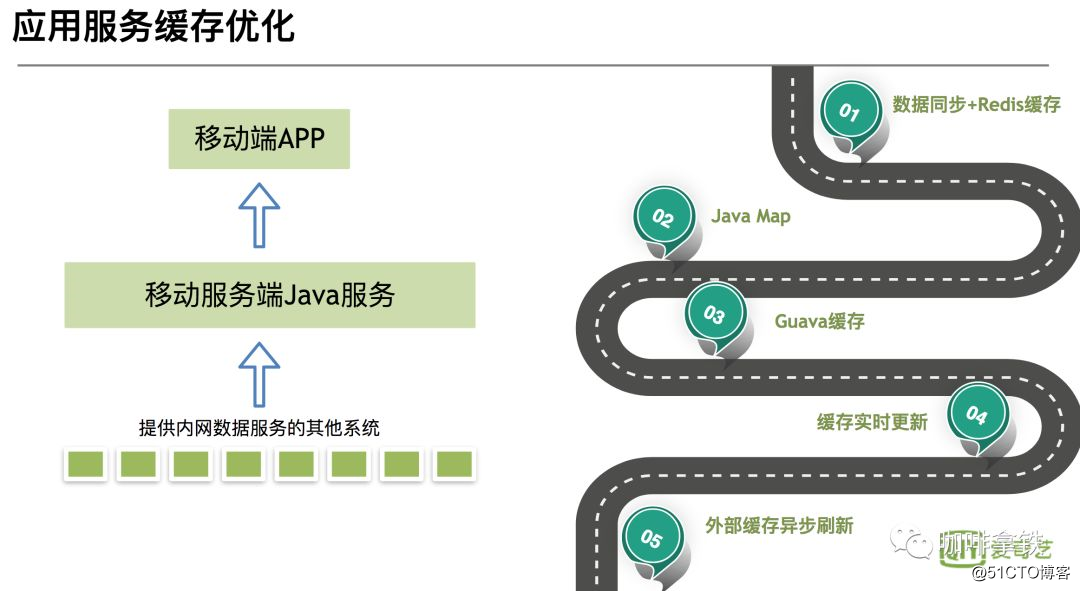
Se puede observar que la figura se divide en varias etapas:
-
La primera etapa: sincronización de datos y redis sincronizar los datos para redistribuir a
través de la cola de mensajes, y luego la aplicación Java recupera directamente la caché La ventaja de esta etapa es: debido a que se utiliza la caché distribuida, los datos se actualizan rápidamente. Las deficiencias también son obvias: confiando en la estabilidad de Redis, una vez que redis se cuelga, todo el sistema de caché no está disponible, lo que provoca una avalancha de caché y todas las solicitudes llegan a la base de datos. -
La segunda y tercera etapas: desde JavaMap hasta la caché de Guava,
la caché en proceso se usa como caché de primer nivel y redis se usa como segundo nivel. Ventajas: No se ve afectado por sistemas externos, otros sistemas aún se pueden usar si cuelgan. Desventaja: la caché en proceso no se puede actualizar en tiempo real como la caché distribuida. Debido a la memoria limitada de Java, se debe establecer el tamaño de la caché, y luego se eliminarán algunas cachés, habrá un problema de tasa de aciertos. -
La cuarta etapa: actualización de Guava Cache
Para resolver los problemas anteriores, use Guava Cache para establecer el tiempo de actualización después de escribir para actualizar. Resolvió el problema de no actualizar, pero aún no resolvió la actualización en tiempo real. - Quinta etapa: actualización de caché externa asincrónica
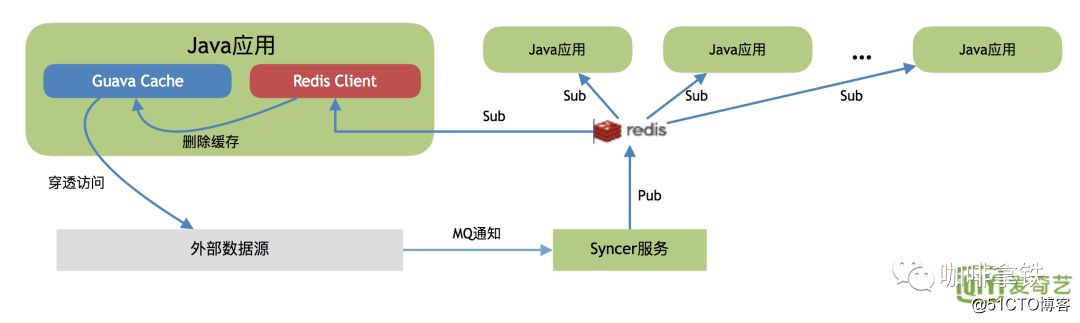
esta etapa extiende la caché de Guava, use redis como un mecanismo de notificación de cola de mensajes para informar la actualización de otras aplicaciones Java.
Aquí hay una breve introducción a las cinco etapas del desarrollo de caché de iQiyi. Por supuesto, hay algunas otras optimizaciones, como ajuste de GC, penetración de caché y algunas optimizaciones de cobertura de caché. Los estudiantes interesados pueden seguir la cuenta oficial y comunicarse conmigo para comunicarse.
2. Biblioteca de búsqueda de sociedades primitivas
Lo anterior es una ruta evolutiva de iQiyi, pero en su proceso de desarrollo general, el primer paso es generalmente sin redis, pero verificando directamente la biblioteca.
Cuando el tráfico es bajo, lo más conveniente es verificar la base de datos o leer el archivo, ya que puede cumplir plenamente con nuestros requisitos comerciales.
3. Sociedad antigua-HashMap
Cuando nuestra aplicación tiene cierta cantidad de tráfico o consulta la base de datos con mucha frecuencia, en este momento podemos sacrificar el HashMap o ConcurrentHashMap que viene con nuestro java. Podemos escribir esto en el código:
public
class
CustomerService
{
private
HashMap
<
String
,
String
>
hashMap
=
new
HashMap
<>();
private
CustomerMapper
customerMapper
;
public
String
getCustomer
(
String
name
){
String
customer
=
hashMap
.
get
(
name
);
if
(
customer
==
null
){
customer
=
customerMapper
.
get
(
name
);
hashMap
.
put
(
name
,
customer
);
}
return
customer
;
}
}Pero hay un problema al hacerlo. HashMap no puede eliminar datos y la memoria crecerá indefinidamente, por lo que hashMap se elimina rápidamente. Por supuesto, eso no significa que sea completamente inútil. Al igual que nuestra sociedad antigua, no todo está desactualizado. Por ejemplo, las virtudes tradicionales de nuestro clan chino son atemporales, como este hashMap, que se puede usar en ciertos escenarios. Como caché, cuando no se necesita el mecanismo de eliminación, por ejemplo, usamos la reflexión. Si buscamos Método y campo a través de la reflexión cada vez, el rendimiento debe ser ineficiente. En este momento, usamos HashMap para almacenarlo en caché, y el rendimiento se puede mejorar mucho.
4. Sociedad moderna-LRUHashMap
En las sociedades antiguas, el problema con el que nos enfrentamos no puede ser eliminado por los datos, lo que conducirá a una expansión ilimitada de nuestra memoria, lo que obviamente es inaceptable para nosotros. Algunas personas dicen que eliminé algunos datos, lo cual no estaría bien, pero ¿cómo eliminarlo? ¿Se elimina al azar? Por supuesto que no. Solo imagina que acabas de cargar A en el caché y será eliminado la próxima vez que quieras acceder a él. Entonces accederemos a nuestra base de datos nuevamente. Entonces, ¿por qué queremos almacenar en caché?
Entonces, las personas inteligentes inventaron varios algoritmos de eliminación. Aquí están los tres FIFO, LRU, LFU comunes (hay algunos ARC, MRU interesados, puede buscar usted mismo):
- FIFO: Primero en entrar, primero en salir En este algoritmo de eliminación, el que ingrese primero al búfer será eliminado primero. Este es el más fácil, pero dará como resultado una tasa de aciertos muy baja. Imagínese si tenemos un dato de acceso muy frecuente al que se accede primero a todos los datos, y luego se accede a los que no son muy altos, entonces se accederá a nuestros primeros datos pero su frecuencia de acceso es muy alta. Exprimir.
- LRU: El algoritmo utilizado menos recientemente. En este algoritmo se evita el problema anterior, cada vez que accedamos a los datos se colocarán al final de nuestro equipo, si necesitamos eliminar datos, solo necesitamos eliminar al jefe del equipo. Pero esto todavía tiene un problema. Si hay un dato al que se accede 10,000 veces en los primeros 59 minutos de una hora (se puede ver que este es un dato caliente), no se accede a los datos en el siguiente minuto, pero hay otros accesos a datos, lo que conducirá a Nuestros datos calientes se eliminan.
- LFU: El uso menos frecuente recientemente. En este algoritmo, lo anterior se optimiza nuevamente, utilizando espacio adicional para registrar la frecuencia de uso de cada dato y luego seleccionando la frecuencia más baja para su eliminación. Esto evita el problema de que LRU no puede manejar el período de tiempo.
Las tres estrategias de eliminación se enumeran arriba. Para estas tres, el costo de implementación es mayor que uno y la tasa de aciertos también es mejor que uno. En general, la solución que elegimos es simplemente centrada, es decir, el costo de implementación no es demasiado alto y la tasa de aciertos también es aceptable ¿Cómo implementar un LRUMap? Podemos completar un LRUMap simple heredando LinkedHashMap y reescribiendo el método removeEldestEntry.
class
LRUMap
extends
LinkedHashMap
{
private
final
int
max
;
private
Object
lock
;
public
LRUMap
(
int
max
,
Object
lock
)
{
//无需扩容
super
((
int
)
(
max
*
1.4f
),
0.75f
,
true
);
this
.
max
=
max
;
this
.
lock
=
lock
;
}
/**
* 重写LinkedHashMap的removeEldestEntry方法即可
* 在Put的时候判断,如果为true,就会删除最老的
* @param eldest
* @return
*/
@Override
protected
boolean
removeEldestEntry
(
Map
.
Entry
eldest
)
{
return
size
()
>
max
;
}
public
Object
getValue
(
Object
key
)
{
synchronized
(
lock
)
{
return
get
(
key
);
}
}
public
void
putValue
(
Object
key
,
Object
value
)
{
synchronized
(
lock
)
{
put
(
key
,
value
);
}
}
public
boolean
removeValue
(
Object
key
)
{
synchronized
(
lock
)
{
return
remove
(
key
)
!=
null
;
}
}
public
boolean
removeAll
(){
clear
();
return
true
;
}
}Se mantiene una lista vinculada de entradas (objetos para clave y valor) en LinkedHashMap. En cada get o put, la nueva entrada insertada o la entrada anterior consultada se colocará al final de nuestra lista vinculada. Se puede notar que en el método de construcción, el tamaño establecido se establece en max * 1.4. En el método removeEldestEntry a continuación, solo se necesita tamaño> max para eliminar, de modo que nuestro mapa nunca alcanzará la lógica de expansión. LinkedHashMap, hemos implementado nuestro LruMap de algunas formas sencillas.
5. Sociedad moderna: caché de guayaba
En la sociedad moderna, LRUMap se ha inventado para eliminar los datos almacenados en caché, pero existen varios problemas:
- La competencia entre bloqueos es seria. Se puede ver que en mi código, el bloqueo es un bloqueo global. A nivel de método, cuando el número de llamadas es grande, el rendimiento será inevitablemente menor.
- No admite el tiempo de caducidad
- No admite actualización automática
Así que los grandes de Google no pudieron evitar inventar el caché de Guava. En el caché de Guava, puedes usarlo fácilmente como el siguiente código:
public
static
void
main
(
String
[]
args
)
throws
ExecutionException
{
LoadingCache
<
String
,
String
>
cache
=
CacheBuilder
.
newBuilder
()
.
maximumSize
(
100
)
//写之后30ms过期
.
expireAfterWrite
(
30L
,
TimeUnit
.
MILLISECONDS
)
//访问之后30ms过期
.
expireAfterAccess
(
30L
,
TimeUnit
.
MILLISECONDS
)
//20ms之后刷新
.
refreshAfterWrite
(
20L
,
TimeUnit
.
MILLISECONDS
)
//开启weakKey key 当启动垃圾回收时,该缓存也被回收
.
weakKeys
()
.
build
(
createCacheLoader
());
System
.
out
.
println
(
cache
.
get
(
"hello"
));
cache
.
put
(
"hello1"
,
"我是hello1"
);
System
.
out
.
println
(
cache
.
get
(
"hello1"
));
cache
.
put
(
"hello1"
,
"我是hello2"
);
System
.
out
.
println
(
cache
.
get
(
"hello1"
));
}
public
static
com
.
google
.
common
.
cache
.
CacheLoader
<
String
,
String
>
createCacheLoader
()
{
return
new
com
.
google
.
common
.
cache
.
CacheLoader
<
String
,
String
>()
{
@Override
public
String
load
(
String
key
)
throws
Exception
{
return
key
;
}
};
}Explicaré cómo guava cache resuelve varios problemas de LRUMap desde el principio de guava cache.
5.1 Competencia de bloqueo
La caché de Guava adopta la idea similar a ConcurrentHashMap, se bloquea en segmentos y es responsable de su propia eliminación en cada segmento. En la segmentación de guayaba según un algoritmo determinado, se debe notar aquí que si hay muy pocos segmentos, la competencia sigue siendo muy seria. Si hay demasiados segmentos, se eliminará fácilmente al azar. Por ejemplo, si el tamaño es 100, dale 100 segmentos, entonces Es decir, dejar que cada dato ocupe un segmento, y cada segmento manejará el proceso de eliminación por sí mismo, por lo que se producirá una eliminación aleatoria. En la caché de guayaba, use el siguiente código para calcular cómo segmentar.
int
segmentShift
=
0
;
int
segmentCount
=
1
;
while
(
segmentCount
<
concurrencyLevel
&&
(!
evictsBySize
()
||
segmentCount
*
20
<=
maxWeight
))
{
++
segmentShift
;
segmentCount
<<=
1
;
}El segmento de cuenta anterior es nuestro número final de segmentos, lo que garantiza al menos 10 entradas por segmento. Si no se establece el parámetro concurrencyLevel, el valor predeterminado será 4 y el número final de segmentos será como máximo 4. Por ejemplo, si nuestro tamaño es 100, se dividirá en 4 segmentos y el tamaño máximo de cada segmento es 25. En la caché de guayaba, la operación de escritura se bloquea directamente. Para la operación de lectura, si los datos leídos no han expirado y están listos para ser cargados, no se requiere bloqueo. Si no se lee, se volverá a bloquear para una segunda lectura. Se requiere carga de caché, es decir, a través del CacheLoader que configuramos, lo que configuré aquí es devolver la Clave directamente, y la consulta desde la base de datos generalmente se configura en el negocio. Como se muestra abajo: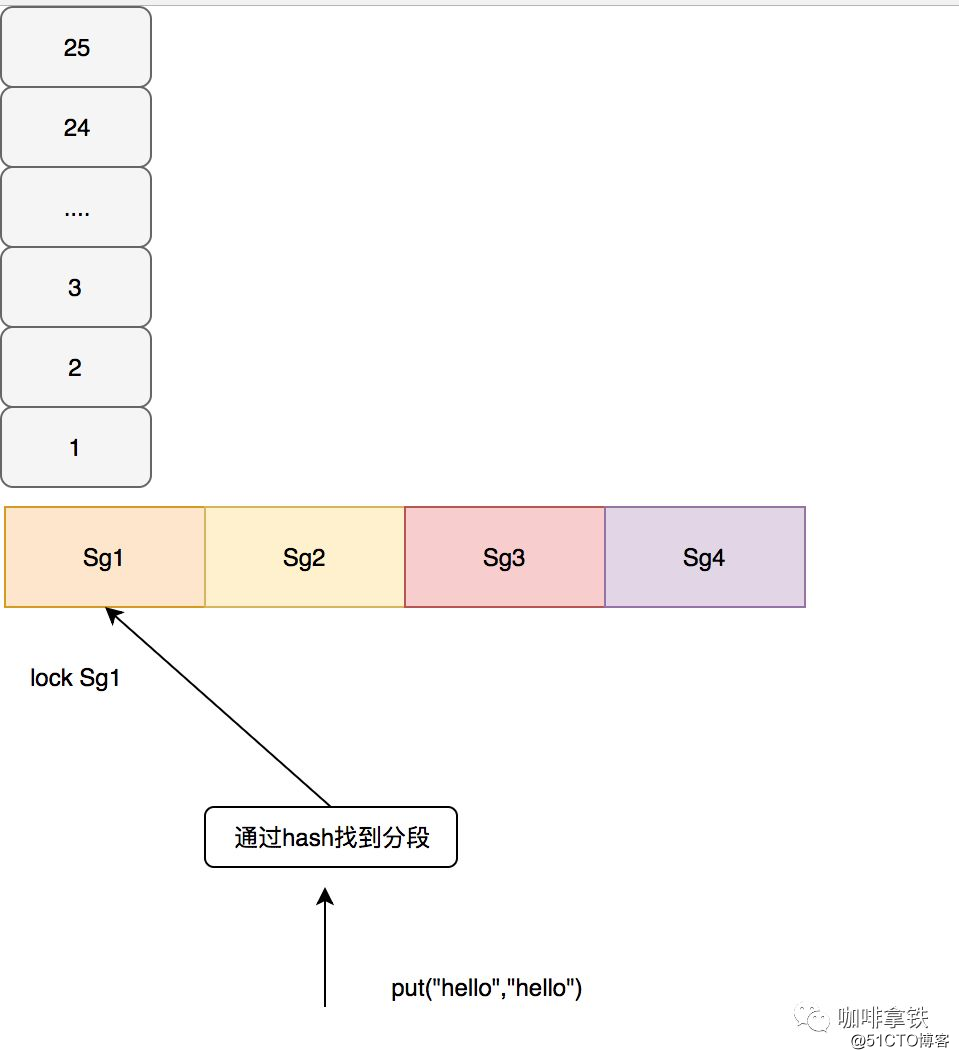
5.2 Tiempo de vencimiento
En comparación con LRUMap, hay dos tiempos de caducidad más, uno es cuánto tiempo caduca después de escribir expireAfterWrite, el otro es cuánto tiempo caduca después de leer expireAfterAccess. Lo interesante es que el Entry caducado en el caché de guayaba no caduca inmediatamente (es decir, no hay hilo de fondo que se haya estado escaneando), sino que el proceso de caducidad se realiza al leer y escribir operaciones. La ventaja de esto es evitar el background Realice bloqueos globales durante el escaneo de hilos. Mira el siguiente código:
public
static
void
main
(
String
[]
args
)
throws
ExecutionException
,
InterruptedException
{
Cache
<
String
,
String
>
cache
=
CacheBuilder
.
newBuilder
()
.
maximumSize
(
100
)
//写之后5s过期
.
expireAfterWrite
(
5
,
TimeUnit
.
MILLISECONDS
)
.
concurrencyLevel
(
1
)
.
build
();
cache
.
put
(
"hello1"
,
"我是hello1"
);
cache
.
put
(
"hello2"
,
"我是hello2"
);
cache
.
put
(
"hello3"
,
"我是hello3"
);
cache
.
put
(
"hello4"
,
"我是hello4"
);
//至少睡眠5ms
Thread
.
sleep
(
5
);
System
.
out
.
println
(
cache
.
size
());
cache
.
put
(
"hello5"
,
"我是hello5"
);
System
.
out
.
println
(
cache
.
size
());
}
输出:
4
1A partir de este resultado, sabemos que el proceso de caducidad solo se realiza cuando se coloca. Preste especial atención al concurrencyLevel (1) anterior. Establezco el segmento máximo en 1 aquí, de lo contrario, este efecto experimental no aparecerá. Como se mencionó en la sección anterior, usamos la unidad de nivel para el procesamiento de vencimiento. Se mantienen dos colas en cada segmento:
final
Queue
<
ReferenceEntry
<
K
,
V
>>
writeQueue
;
final
Queue
<
ReferenceEntry
<
K
,
V
>>
accessQueue
;writeQueue mantiene una cola de escritura. El encabezado de la cola representa los datos escritos antes y el final de la cola representa los datos escritos tarde. accessQueue mantiene la cola de acceso, como LRU, se utiliza para eliminar el tiempo de acceso, si el segmento excede la capacidad máxima, como los 25 que mencionamos anteriormente, se procesará el primer elemento de la cola de accessQueue. Eliminado.
void
expireEntries
(
long
now
)
{
drainRecencyQueue
();
ReferenceEntry
<
K
,
V
>
e
;
while
((
e
=
writeQueue
.
peek
())
!=
null
&&
map
.
isExpired
(
e
,
now
))
{
if
(!
removeEntry
(
e
,
e
.
getHash
(),
RemovalCause
.
EXPIRED
))
{
throw
new
AssertionError
();
}
}
while
((
e
=
accessQueue
.
peek
())
!=
null
&&
map
.
isExpired
(
e
,
now
))
{
if
(!
removeEntry
(
e
,
e
.
getHash
(),
RemovalCause
.
EXPIRED
))
{
throw
new
AssertionError
();
}
}
}Lo anterior es el proceso de procesamiento de entradas caducadas en caché de guayaba. Verá las dos colas a la vez y las eliminará si caducan. Generalmente, el procesamiento de Entradas caducadas se puede llamar antes y después de nuestra operación de colocación, o cuando encontramos que ha caducado al leer los datos, y luego realizar el procesamiento caducado de todo el segmento, o llamarlo durante la segunda operación de lectura lockGetOrLoad.
void
evictEntries
(
ReferenceEntry
<
K
,
V
>
newest
)
{
///... 省略无用代码
while
(
totalWeight
>
maxSegmentWeight
)
{
ReferenceEntry
<
K
,
V
>
e
=
getNextEvictable
();
if
(!
removeEntry
(
e
,
e
.
getHash
(),
RemovalCause
.
SIZE
))
{
throw
new
AssertionError
();
}
}
}
/**
**返回accessQueue的entry
**/
ReferenceEntry
<
K
,
V
>
getNextEvictable
()
{
for
(
ReferenceEntry
<
K
,
V
>
e
:
accessQueue
)
{
int
weight
=
e
.
getValueReference
().
getWeight
();
if
(
weight
>
0
)
{
return
e
;
}
}
throw
new
AssertionError
();
}Lo anterior es el código cuando expulsamos Entry, podemos ver que accessQueue está expulsando el encabezado de la cola. La estrategia de desalojo generalmente se llama cuando cambian los elementos del segmento, como operaciones de inserción, operaciones de actualización y operaciones de carga de datos.
5.3 Actualización automática
La operación de actualización automática es relativamente simple de implementar en la caché de guayaba. Puede verificar directamente si cumple con las condiciones de actualización y actualización.
5.4 Otras características
Hay algunas otras características en la caché de Guava:
Referencia fantasma
En la caché de Guava, tanto la clave como el valor se pueden configurar para referencias virtuales. Hay dos colas de referencia en el segmento:
final
@Nullable
ReferenceQueue
<
K
>
keyReferenceQueue
;
final
@Nullable
ReferenceQueue
<
V
>
valueReferenceQueue
;Estas dos colas se utilizan para registrar las referencias que se reciclan, cada una de las cuales registra el hash de cada Entrada reciclada, de modo que después del reciclaje, la Entrada anterior se puede eliminar mediante el valor de hash en esta cola.
Eliminar oyente
En la caché de guayaba, cuando se eliminan algunos datos, pero no sabe si están desactualizados, expulsados o reciclados debido al objeto fantasma referenciado. En este momento, puede llamar a este método removeListener (oyente RemovalListener) para agregar un oyente para el monitoreo de eliminación de datos, que se puede usar para el registro o algún otro procesamiento, que se puede usar para el análisis de eliminación de datos.
Todos los motivos de ser eliminados quedan registrados en RemovalCause: eliminados por el usuario, reemplazados por el usuario, caducados, expulsados de la colección, eliminados por tamaño.
Resumen de caché de guayaba
Lea atentamente el código fuente de la caché de guayaba y resuma, en realidad es un mapa LRU con buen rendimiento y una rica API. El desarrollo de la caché de iQiyi también se basa en esto, que a través del desarrollo secundario de la caché de guayaba, puede actualizar la caché entre los servicios de aplicaciones java.
6. Al futuro-cafeína
La función de la caché de guayaba es realmente muy poderosa y satisface las necesidades de la mayoría de las personas, pero es esencialmente una capa de encapsulación LRU, por lo que palidece en comparación con muchos otros algoritmos de eliminación mejores. El caché de cafeína implementa W-TinyLFU (una variante del algoritmo LFU + LRU). La siguiente es una comparación de las tasas de aciertos de diferentes algoritmos: 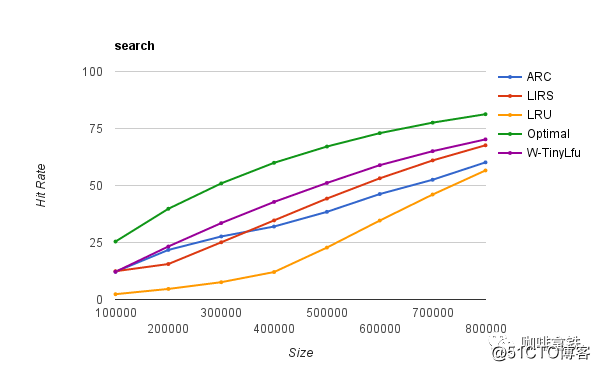
Óptimo es la tasa de aciertos más ideal, y LRU es de hecho un hermano menor en comparación con otros algoritmos. Y nuestro W-TinyLFU es el más cercano a la tasa de aciertos ideal. Por supuesto, no solo la tasa de aciertos de la cafeína es mejor que la caché de guayaba, sino también la caché de guayaba en términos de rendimiento de lectura y escritura. 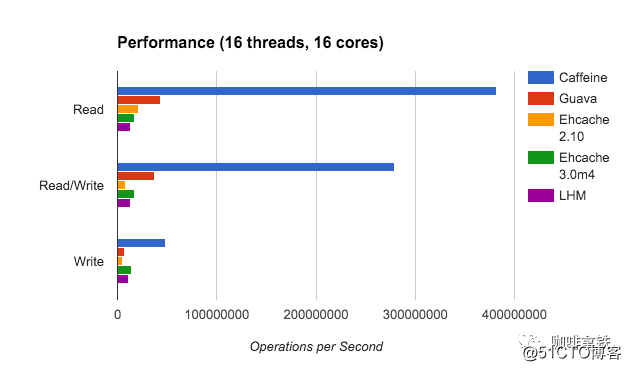
En este momento, debes preguntarte por qué la cafeína es tan increíble. No te preocupes, te lo diré lentamente.
6.1W-TinyLFU
Ya he dicho de qué se trata el LFU tradicional. En LFU, siempre que la distribución de probabilidad de los patrones de acceso a los datos permanezca sin cambios con el tiempo, la tasa de aciertos puede llegar a ser muy alta. Aquí sigo tomando iQIYI como ejemplo. Por ejemplo, salió un nuevo drama y usamos LFU para almacenarlo en caché. Este nuevo drama ha sido accedido cientos de millones de veces en los últimos días, y esta frecuencia de acceso también está registrada en nuestro LFU. Cientos de millones de veces. Pero los nuevos dramas siempre estarán desactualizados. Por ejemplo, los primeros episodios de este nuevo programa están desactualizados después de un mes, pero su tráfico es demasiado alto. Otros programas de televisión no pueden eliminar este nuevo programa en absoluto, así que aquí Este modelo tiene limitaciones. Entonces, han aparecido varias variantes de LFU, basadas en el período de tiempo para decaer, o la frecuencia en un cierto período de tiempo. El mismo LFU también usa espacio adicional para registrar la frecuencia de cada acceso a los datos, incluso si los datos no están en la caché, deben registrarse, por lo que el espacio adicional que debe mantenerse es grande.
Imagine que creamos un hashMap para este espacio de mantenimiento, y cada elemento de datos se almacenará en este hashMap. Cuando la cantidad de datos es particularmente grande, el hashMap será particularmente grande.
Volviendo a LRU, nuestro LRU no es tan inútil, LRU puede lidiar muy bien con situaciones de tráfico repentino porque no necesita acumular frecuencia de datos.
Entonces, W-TinyLFU combina LRU y LFU, así como algunas características de otros algoritmos.
6.2 Registro de frecuencia
Lo primero que se debe hablar es el problema de la grabación de frecuencias, el objetivo que queremos conseguir es utilizar un espacio limitado para registrar la frecuencia de acceso que cambia con el tiempo. Usamos Count-Min Sketch para registrar nuestra frecuencia de visitas en W-TinyLFU, y esto también es una variante del filtro Bloom. Como se muestra en la siguiente figura: 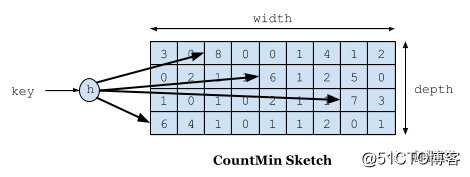
Si necesitamos registrar un valor, necesitamos hash a través de múltiples algoritmos hash y luego agregar +1 al registro del algoritmo hash correspondiente. ¿Por qué necesitamos múltiples algoritmos hash? Dado que se trata de un algoritmo de compresión, habrá conflictos. Por ejemplo, creamos una matriz Long y calculamos la posición hash de cada dato. Por ejemplo, Zhang San y Li Si, ambos pueden tener el mismo valor hash. Por ejemplo, si ambos son 1, la posición de Long [1] aumentará la frecuencia correspondiente. Zhang San visita 10,000 veces y Li Si visita 1 vez, y Long [ 1] Esta ubicación es 10: 1. Si toma la tasa de entrevista de Li Si, se sacará como 101, pero Li Si solo visitó una vez. Para resolver este problema, usamos múltiples El algoritmo hash puede entenderse como un concepto de matrices bidimensionales largas [] []. Por ejemplo, en el primer algoritmo, Zhang San y Li Si entran en conflicto, pero en el segundo y tercer algoritmos, hay una alta probabilidad de que no entren en conflicto, como una El algoritmo tiene una probabilidad de colisión de alrededor del 1% y la probabilidad de que los cuatro algoritmos choquen entre sí es del 1% elevado a la cuarta potencia. A través de este modelo, cuando tomamos la tasa de acceso de Li Si, tomamos el número de veces que Li Si tiene la frecuencia más baja entre todos los algoritmos. Entonces su nombre es Count-Min Sketch.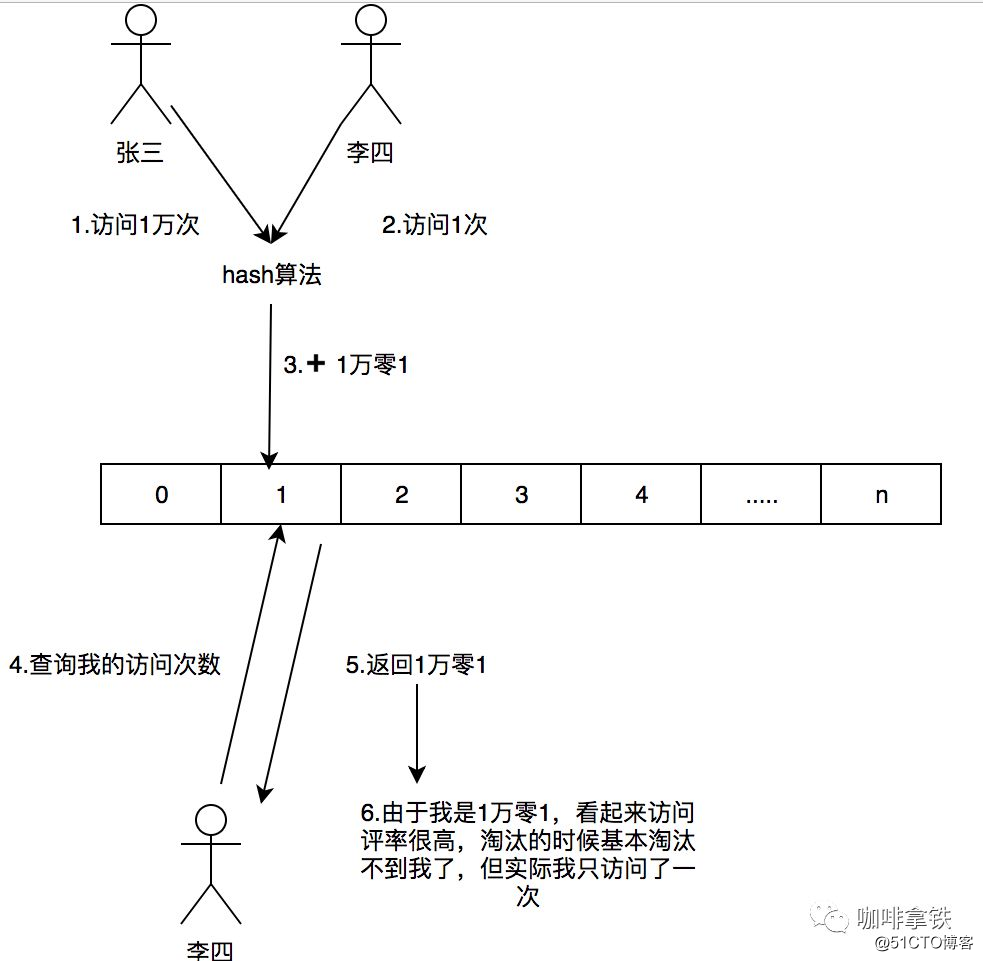
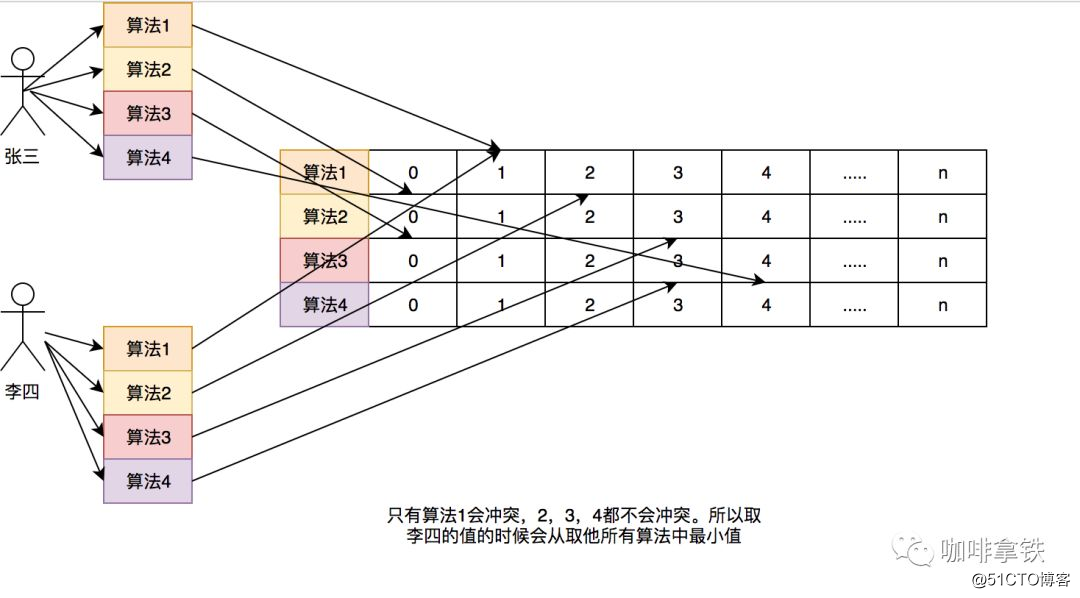
Aquí hay una comparación con el anterior. Un ejemplo simple: si un hashMap registra esta frecuencia, si tengo 100 datos, entonces este HashMap debe almacenar 100 frecuencias de acceso de estos datos. Incluso si la capacidad de mi caché es 1, debido a las reglas de Lfu, debo registrar la frecuencia de acceso de los 100 datos. Si hay más datos, grabaré más.
En Count-Min Sketch, permítanme hablar directamente sobre la implementación en cafeína (en la clase FrequencySketch). Si su tamaño de caché es 100, generará una matriz larga cuyo tamaño es la potencia más cercana de 2 a 100. , Que es 128. Y esta matriz registrará nuestra frecuencia de acceso. En cafeína, la frecuencia regular máxima es 15, 15 bits binarios 1111, 4 bits en total y el tipo largo es 64 bits. Entonces, cada tipo Long puede poner 16 algoritmos, pero la cafeína no hace esto. Solo usa cuatro algoritmos hash. Cada tipo Long se divide en cuatro secciones, y cada sección almacena las frecuencias de los cuatro algoritmos. La ventaja de esto es que puede reducir aún más los conflictos de Hash. El hash original de tamaño 128 se convierte en 128X4.
La estructura de un Long es la siguiente: 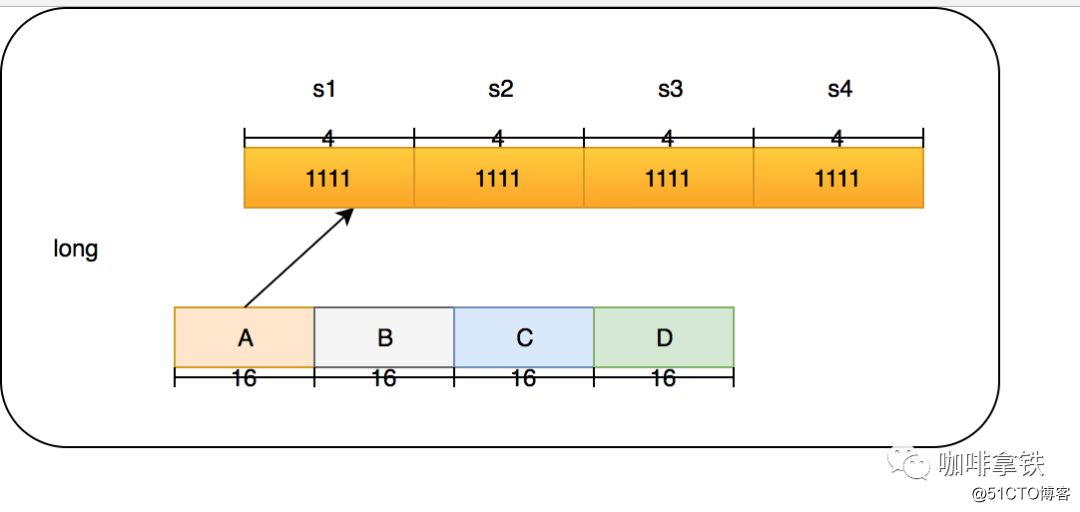
Nuestros 4 segmentos se dividen en A, B, C y D, que los llamaré más adelante. Llamo a los cuatro algoritmos en cada segmento s1, s2, s3 y s4. Aquí tiene un ejemplo: ¿Qué debo hacer si quiero agregar una frecuencia digital para acceder a 50? Usamos size = 100 como ejemplo aquí.
- Primero, determine en qué segmento está el hash de 50. A través de hash & 3, se debe obtener un número menor que 4. Si hash & 3 = 0, entonces está en el segmento A.
- Utilice otro algoritmo hash para hash el 50 hash para obtener la posición de la matriz larga. Suponga que el algoritmo s1 se usa para obtener 1, el algoritmo s2 es 3, el algoritmo s3 es 4 y el algoritmo s4 es 0.
- Luego realice +1 en la posición s1 en la sección A de largo [1], que se conoce como 1As1 más 1, luego 3As2 más 1, 4As3 más 1 y 0As4 más 1.
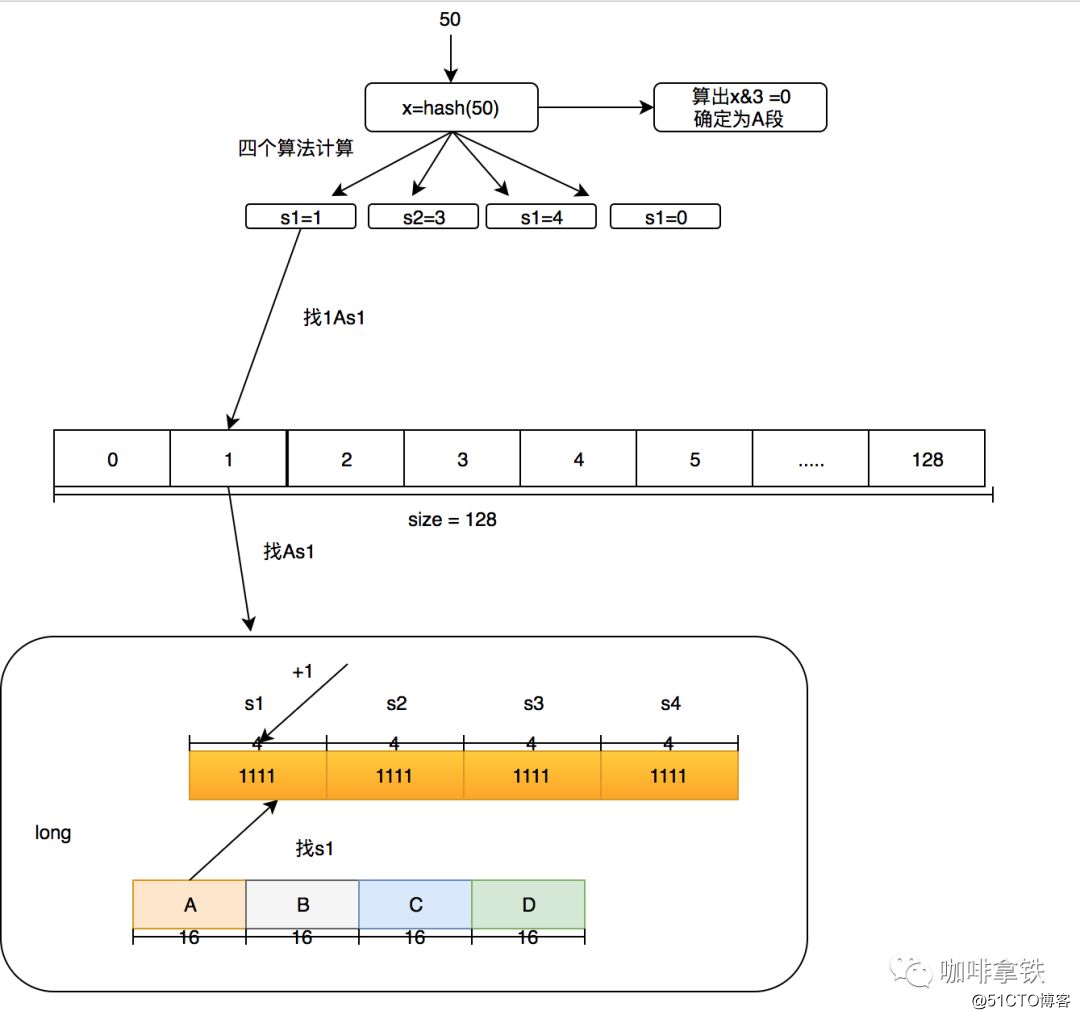
En este momento, algunas personas se preguntarán si la frecuencia máxima de 15 es demasiado pequeña. Está bien. En este algoritmo, por ejemplo, si el tamaño es igual a 100, si se aumenta globalmente 1000 veces, se dividirá globalmente por 2 atenuación. Después de la atenuación, puede continuar aumentando. Este algoritmo ha sido probado en el documento W-TinyLFU para adaptarse mejor Frecuencia de acceso durante el período de tiempo.
6.2 Rendimiento de lectura y escritura
En guava cache dijimos que sus operaciones de lectura y escritura se mezclan con el procesamiento de tiempo de caducidad, es decir, también se pueden realizar operaciones de eliminación en una operación Put, por lo que su rendimiento de lectura y escritura se verá afectado en cierta medida, puedes ver la figura de arriba. La cafeína hizo explotar el caché de guayaba en operaciones de lectura y escritura. Principalmente porque en la cafeína, las operaciones sobre estos eventos se realizan de forma asincrónica. Él envía los eventos a la cola. La estructura de datos de la cola aquí es RingBuffer. Si no está seguro, puede leer este artículo. ¿Sigue utilizando BlockingQueue? Lea este artículo para obtener más información sobre Disruptor. Luego, a través del ForkJoinPool.commonPool () predeterminado, o configure el grupo de subprocesos usted mismo, tome la operación de cola y luego realice las siguientes operaciones de eliminación y expiración.
Por supuesto, existen diferentes colas de lectura y escritura, en cafeína se considera que hay muchas más lecturas de caché que escrituras, por lo que para las operaciones de escritura todos los hilos comparten un Ringbuffer.
Para operaciones de lectura con más frecuencia que operaciones de escritura, para reducir aún más la competencia, está equipado con un RingBuffer para cada hilo: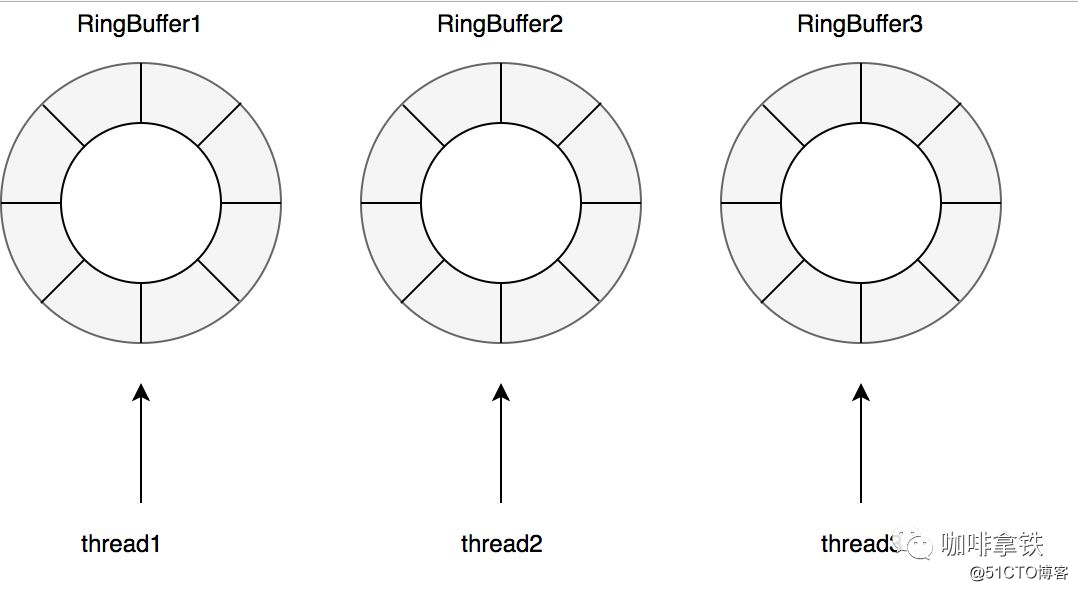
6.3 Estrategia de eliminación de datos
Todos los datos de la cafeína están en ConcurrentHashMap, que es diferente del caché de guayaba, que implementa una estructura similar a ConcurrentHashMap por sí mismo. Hay tres colas de LRU a las que hacen referencia los registros de cafeína:
-
Cola de Eden: se especifica en cafeína que solo puede ser% 1 de la capacidad de la caché. Si size = 100, el tamaño efectivo de esta cola es igual a 1. Lo que se registra en esta cola son los datos recién llegados, lo que evita que se elimine el tráfico en ráfagas debido a que antes no había frecuencia de acceso. Por ejemplo, si se lanza un nuevo drama, no tiene frecuencia de acceso al principio, para evitar que sea eliminado por otras cachés después de que se lance y se una a esta área. La zona de Edén, la zona más cómoda y confortable, es difícil de eliminar por otros datos aquí.
-
Cola de libertad condicional: se llama cola de libertad condicional. En esta cola, sus datos están relativamente fríos y se eliminarán pronto. El tamaño efectivo es el tamaño menos edén menos protegido.
- Cola protegida: En esta cola, puede estar seguro de que no será eliminado por el momento, pero no se preocupe, si no hay datos en la cola de Libertad Condicional o los datos protegidos están llenos, también se enfrentará a la vergonzosa situación de eliminación. Por supuesto, si desea convertirse en esta cola, debe visitar el período de prueba una vez y se promoverá a la cola protegida. El tamaño efectivo es (tamaño menos eden) X 80%. Si tamaño = 100, será 79.
Las tres colas están relacionadas de la siguiente manera: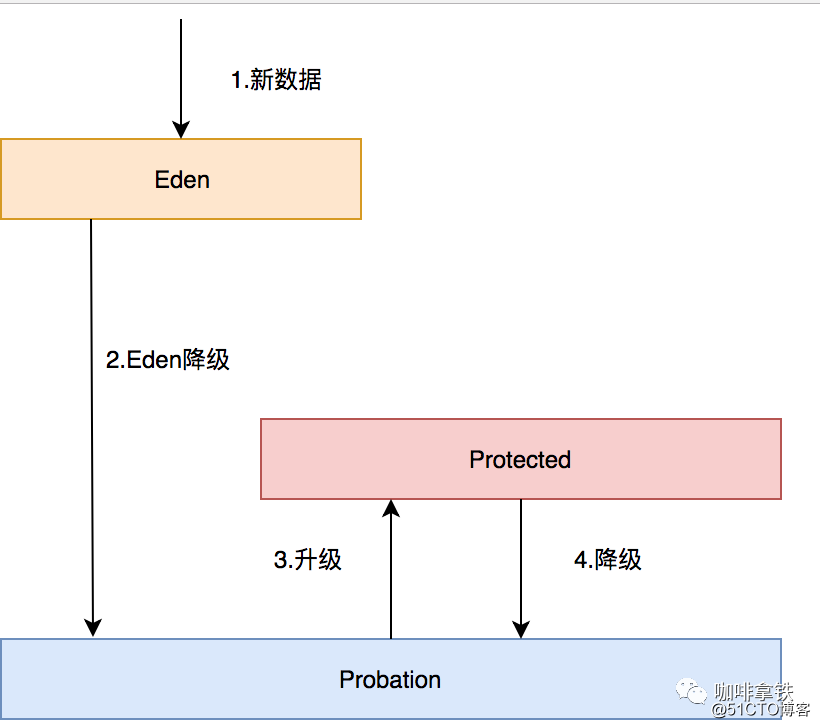
- Todos los datos nuevos irán a Eden.
- El Edén está lleno, eliminado al período de prueba.
- Si se accede a uno de los datos en período de prueba, estos datos se actualizan a Protegido.
- Si Protegido está completo, continuará siendo degradado a Probatoria.
Cuando se produzca la eliminación de datos, se eliminará del período de prueba y el líder del equipo de datos en esta cola se llamará la víctima. Este líder del equipo debe ser el primero en ingresar. De acuerdo con el algoritmo de la cola LRU, en realidad debería ser eliminado. Eliminado, pero aquí sólo se le puede llamar víctima. Esta cola es una cola de libertad condicional, y el representante está a punto de ejecutarlo. Aquí, el final del equipo será eliminado y llamado candidatos, también llamados *** ers. Aquí, la víctima hará un PK con la víctima, y los siguientes juicios se pueden hacer a partir de los datos de frecuencia registrados en nuestro Count-Min Sketch:
- Si la persona asesina es mayor que la víctima, entonces la víctima es directamente eliminada.
- Si la persona *** <= 5, entonces la persona *** se elimina directamente. Esta lógica se explica en sus notas:
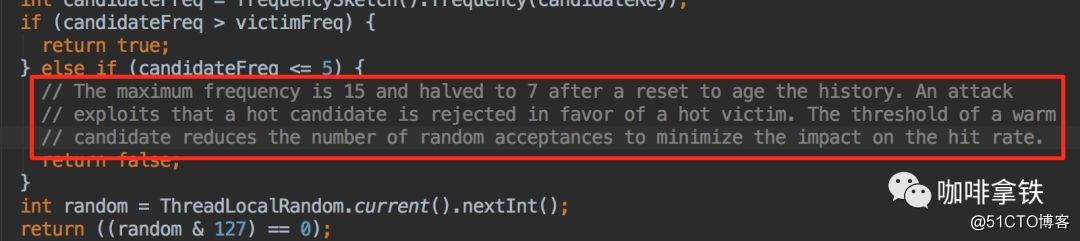
cree que establecer un umbral de calentamiento aumentará la tasa de aciertos general. - En otros casos, se eliminará de forma aleatoria.
6.4 Cómo utilizar
Para los jugadores que están familiarizados con Guava, si están preocupados por los costos de cambio, entonces tienen que preocuparse por eso por completo. La api de Caffeine se basa en la api de Guava, y pueden encontrar que es básicamente lo mismo.
public
static
void
main
(
String
[]
args
)
{
Cache
<
String
,
String
>
cache
=
Caffeine
.
newBuilder
()
.
expireAfterWrite
(
1
,
TimeUnit
.
SECONDS
)
.
expireAfterAccess
(
1
,
TimeUnit
.
SECONDS
)
.
maximumSize
(
10
)
.
build
();
cache
.
put
(
"hello"
,
"hello"
);
}Por cierto, cada vez más marcos de código abierto han abandonado la caché de Guava, como Spring5. En los negocios, yo mismo he comparado el caché de guayaba y la cafeína y finalmente elegí la cafeína, que también tiene buenos resultados en línea. Así que no se preocupe porque la cafeína es inmadura y nadie la usa.
7. Finalmente
Este artículo habla principalmente sobre la ruta de almacenamiento en caché de iQiyi y una historia del almacenamiento en caché local (desde la antigüedad hasta el futuro), así como los principios básicos de cada tipo de almacenamiento en caché. Por supuesto, no es suficiente usar bien la caché, como la forma en que la caché local se actualiza sincrónicamente después de cambios en otros lugares, caché distribuida, caché multinivel, etc. Más adelante se escribirá una sección para presentar cómo hacer un buen uso de la caché. Para conocer los principios de la caché de guayaba y la cafeína, también me tomaré un tiempo para escribir el análisis del código fuente de estos dos más adelante. Si los amigos interesados pueden seguir la cuenta pública para revisar los artículos actualizados por primera vez.
Finalmente, haga un anuncio. Si cree que este artículo tiene un artículo para usted, puede seguir mi cuenta pública técnica. Recientemente, el autor ha recopilado muchos de los últimos videos de materiales de aprendizaje y materiales de entrevistas, y puede recibirlos después de prestar atención. Su atención y reenvío son El mayor apoyo para mí, O (∩_∩) O
