Pruebe un número escrito a mano personalizado
Los datos de mnist se han entrenado anteriormente y los datos de prueba también se han probado, y la tasa de precisión es de aproximadamente el 99%. Entonces, si queremos medir un número de bytes escrito a mano por nosotros mismos y ver si es exacto, cómo usar el archivo de peso caffemodel.
Probemos un número escrito a mano personalizado.
Utilice el modelo lenet_iter_10000.caffemodel para probar los archivos necesarios para un solo número escrito a mano:
(1) La imagen que se va a probar (puede dibujar usted mismo o en Internet); debe tenerse en cuenta que no importa qué formato sea, debe convertirse a 28 * Imágenes en escala de grises en blanco y negro de 28 tamaños, utilice Baidu para el método de conversión específico. Puede descargar desde este enlace si no desea convertir. Enlace de descarga: https://pan.baidu.com/s/1Ck6l7bAncK2BpcqWXG67Dg Contraseña: csig, estas imágenes están disponibles en línea Giro de vuelta.
(2) deploy.prototxt (archivo de descripción del modelo);
(3) network.caffemodel (archivo de peso del modelo), en este caso es lenet_iter_10000.caffemodel
(4) labels.txt (archivo de etiqueta), el beneficio es synset_words archivo .txt;
(5) mean.binaryproto (archivo promedio de imagen binaria);
(6) clasificación.bin (nombre del programa binario). Se usa junto con el archivo de media binario, pero diferentes modelos con diferentes archivos de media tienen diferentes archivos de media, y este archivo bin es universal, es decir, cualquier modelo puede usarse para la clasificación.
1. Prepare una imagen personalizada
Descargue la imagen en el enlace y cópiela en el directorio caffe / examples / mnist /.
2. Genere el archivo deploy.prototxt
La función del archivo deploy.prototxt es similar a la del archivo lenet_train_test.prototxt, o el primero se puede obtener cambiando el segundo. Después de familiarizarnos con los principios y métodos de generación de archivos, podemos realizar cambios en el archivo de red del prototipo de entrenamiento original. Copie una copia de lenet_train_test.prototxt en el directorio examples / mnist, modifíquelo y guárdelo para obtener deploy.prototxt de la siguiente manera:
name: "LeNet"
layer {
name:"data"
type: "Input"
top: "data"
input_param { shape: { dim: 1 dim: 1 dim: 28 dim: 28 } }
}
layer {
name:"conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
convolution_param {
num_output: 20
kernel_size: 5
stride: 1
weight_filler {
type: "xavier"
}
}
}
layer {
name:"pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name:"conv2"
type: "Convolution"
bottom: "pool1"
top: "conv2"
convolution_param {
num_output: 50
kernel_size: 5
stride: 1
weight_filler {
type: "xavier"
}
}
}
layer {
name:"pool2"
type: "Pooling"
bottom: "conv2"
top: "pool2"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name:"ip1"
type: "InnerProduct"
bottom: "pool2"
top: "ip1"
inner_product_param {
num_output: 500
weight_filler {
type: "xavier"
}
}
}
layer {
name:"relu1"
type: "ReLU"
bottom: "ip1"
top: "ip1"
}
layer {
name:"ip2"
type: "InnerProduct"
bottom: "ip1"
top: "ip2"
inner_product_param {
num_output: 10
weight_filler {
type: "xavier"
}
}
}
layer {
name:"prob"
type: "Softmax"
bottom: "ip2"
top: "prob"
}
Por supuesto, el archivo deploy.prototxt también se puede generar automáticamente mediante código. El archivo de implementación no tiene la primera capa de entrada de datos, ni la capa de Precisión final, pero al final hay una capa adicional de probabilidad Softmax.
El código deploy.py es el siguiente;
# -*- coding: utf-8 -*-
from caffe import layers as L,params as P,to_proto
root='/root/caffe/'
deploy=root+'examples/mnist/deploy.prototxt' #文件保存路径
def create_deploy():
#少了第一层,data层
conv1=L.Convolution(name='conv1',bottom='data', kernel_size=5, stride=1,num_output=20, pad=0,weight_filler=dict(type='xavier'))
pool1=L.Pooling(conv1,name='pool1',pool=P.Pooling.MAX, kernel_size=2, stride=2)
conv2=L.Convolution(pool1, name='conv2',kernel_size=5, stride=1,num_output=50, pad=0,weight_filler=dict(type='xavier'))
pool2=L.Pooling(conv2, name='pool2', pool=P.Pooling.MAX, kernel_size=2, stride=2)
fc3=L.InnerProduct(pool2, name='ip1',num_output=500,weight_filler=dict(type='xavier'))
relu3=L.ReLU(fc3, name='relu1',in_place=True)
fc4 = L.InnerProduct(relu3, name='ip2',num_output=10,weight_filler=dict(type='xavier'))
#最后没有accuracy层,但有一个Softmax层
prob=L.Softmax(fc4, name='prob')
return to_proto(prob)
def write_deploy():
with open('deploy.prototxt', 'w+') as f:
f.write('name:"LeNet"\n')
f.write('layer {\n')
f.write('name:"data"\n')
f.write('type:"Input"\n')
f.write('top:"data"\n')
f.write('input_param { shape : {')
f.write('dim:1 ')
f.write('dim:1 ')
f.write('dim:28 ')
f.write('dim:28 ')
f.write('} } }\n\n')
f.write(str(create_deploy()))
if __name__ == '__main__':
write_deploy()
3. network.caffemodel (archivo de peso del modelo)
network.caffemodel se ha generado durante el entrenamiento, en este caso es el archivo lenet_iter_10000.caffemodel.
4. Generar archivo de etiqueta labels.txt
Cree un nuevo archivo txt en el directorio actual y asígnele el nombre synset_words.txt, el contenido dentro es el contenido de la imagen de nuestro mnist de entrenamiento, hay diez números del 0 al 9, luego creamos un archivo de etiqueta con el siguiente contenido :

5. Genere el archivo mean.binaryproto binario mean
Los archivos mean se dividen en archivos mean binarios y archivos mean del tipo python.
El autor de caffe nos proporciona un archivo compute_image_mean.cpp para calcular la media, que se coloca en la carpeta de herramientas bajo el directorio raíz de caffe, y ejecuta el siguiente comando para generar el archivo binario mean.binaryproto mean.
build/tools/compute_image_mean \
examples/mnist/mnist_train_lmdb \
examples/mnist/mean.binaryproto
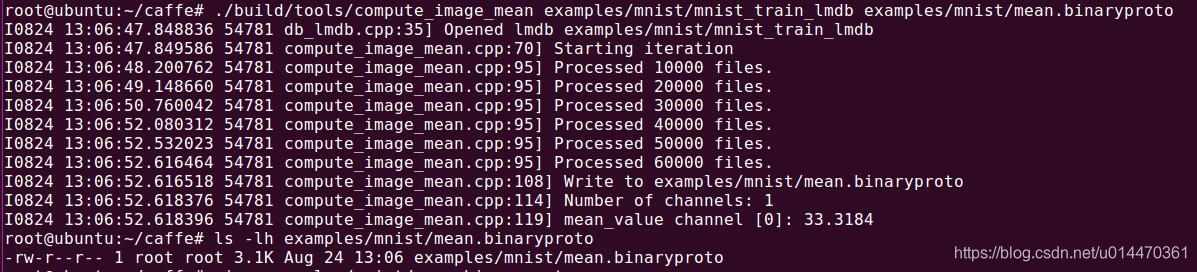
6. Utilice el programa binario
class.bin para probar . Hay una carpeta cpp_classification en la carpeta de ejemplo, ábrala y hay un archivo cpp llamado clasificación. Este es el cálculo hacia adelante que nos proporciona caffe llamando a la red de clasificación. Interfaz para resultados de clasificación. Este es el archivo que obtendrá la clasificación.bin en el comando.
Utilice el siguiente comando para comenzar a probar una imagen digital personalizada:
./build/examples/cpp_classification/classification.bin \
examples/mnist/deploy.prototxt \
examples/mnist/lenet_iter_10000.caffemodel \
examples/mnist/mean.binaryproto \
examples/mnist/synset_words.txt \
examples/mnist/picture/0.0.jpg
Resultado de la prueba: Se
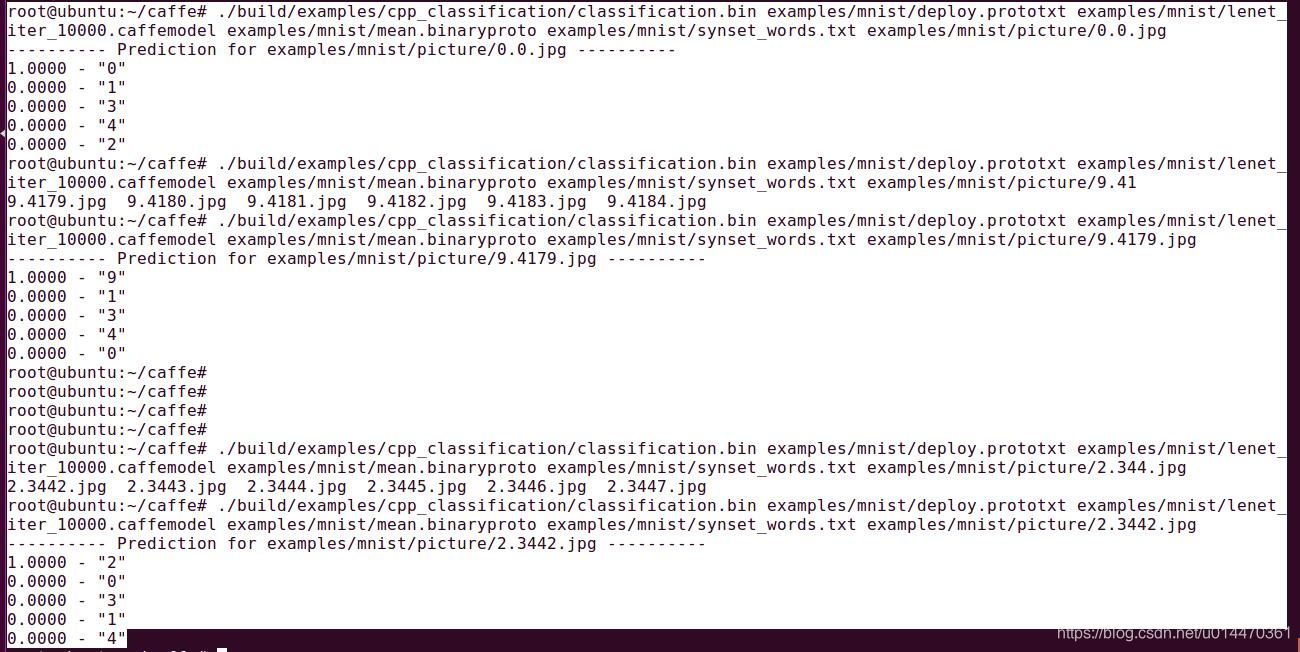
puede ver que la salida de etiqueta 0 en la prueba 0 corresponde a 1,0000, la salida de etiqueta 9 en la prueba 9 corresponde a 1,0000 y la salida de etiqueta 2 en la prueba 2 corresponde a 1,0000. El resultado sigue siendo muy preciso.
Dibujar gráfico de pérdidas
En el proceso del último entrenamiento mnist, se imprimieron continuamente cierta velocidad de entrenamiento, tasa de aprendizaje, valor de pérdida, etc. Entonces, ¿existe un formato de imagen que pueda reflejar de manera más intuitiva la tendencia de pérdida y precisión durante el proceso de entrenamiento?
Por supuesto que los hay, necesita escribir un programa de Pyton loss.py. Consulte un ejemplo en Internet:
# -*- coding: utf-8 -*-
import numpy as np #导入numpy库并命名为np,numpy支持大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库。
import matplotlib.pyplot as plt #导入matplotlib.pyplot库并命名为plt,Matplotlib 是 Python 的绘图库。 matplotlib可与 NumPy 一起使用,提供了一种有效的 MatLab 开源替代方案
import sys,os #导入sys模块,sys模块包含了与Python解释器和它的环境有关的函数;导入os模块,os模块里面有环境变量的映射关系,目录等
caffe_root = '/root/caffe'
sys.path.insert(0,caffe_root+'python') #sys.path为一个列表,用insert直接插到首位,插入python的环境变量
import caffe
caffe.set_mode_cpu() #设置caffe cpu运行模式
solver = caffe.SGDSolver('/root/caffe/examples/mnist/lenet_solver.prototxt')
# 执行完上面的语句以后,网络的相应的权值与偏置会根据我们的定义进行赋值的
niter=1000 #迭代1000次
test_interval = 200 #200次测试一次
train_loss = np.zeros(niter) #1维,大小为1000的数组
#np.zeros返回一个给定形状和类型的用0填充的数组,本例为array([ 0, 0, 0, 0, 0 ......]),长度是1000
test_acc = np.zeros(int(np.ceil(niter / test_interval)))#1维,大小为5的数组
#np.ceil() 计算大于等于该值的最小整数,本例niter / test_interval,np.ceil(5)是5
for it in range(niter):
solver.step(1)
# solver.net.forward() , solver.test_nets[0].forward() 和 solver.step(1) 区别和作用。
#三个函数都是将批量大小(batch_size)的图片送到网络,
#solver.net.forward() 和 solver.test_nets[0].forward() 是将batch_size个图片送到网络中去,只有前向传播(Forward Propagation,BP),solver.net.forward()作用于训练集,solver.test_nets[0].forward() 作用于测试集,一般用于获得测试集的正确率。
#solver.step(1) 也是将batch_size个图片送到网络中去,不过 solver.step(1) 不仅有FP,而且还有反向传播(Back Propagation,BP)!这样就可以更新整个网络的权值(weights),同时得到该batch的loss。
train_loss[it] = solver.net.blobs['loss'].data # 获取每一次迭代的loss值
solver.test_nets[0].forward(start='conv1') #表示从conv1开始,这样的话,data层不用传新的数据了。
if it % test_interval == 0:
acc=solver.test_nets[0].blobs['accuracy'].data #获取test_interval整数倍时的准确率
#solver.net.blobs为一个字典的数据类型,里面的key值为各个layer 的名字,value为caffe的blob块
print 'Iteration',it,'testing...','accuracy:',acc
test_acc[it // test_interval] = acc # //是整除运算符,取整数部分
print test_acc
_,ax1= plt.subplots()
ax2= ax1.twinx()#matplotlib:次坐标轴ax2=ax1.twinx(),产生一个ax1的镜面坐标
ax1.plot(np.arange(niter),train_loss)
ax2.plot(test_interval * np.arange(len(test_acc)),test_acc,'r')
ax1.set_xlabel('iteration')
ax1.set_ylabel('train loss')
ax2.set_ylabel('test accuracy')
plt.savefig("mnist_loss.png")
plt.show()
Vea arriba para un análisis detallado del programa loss.py.
Ejecutar dibujo
python loss.py
Después de ejecutar loss.py, comencé a entrenar, aquí entrené 1000 veces y realicé una prueba 200 veces.
La curva de pérdidas es la siguiente:
eog mnist_loss.png
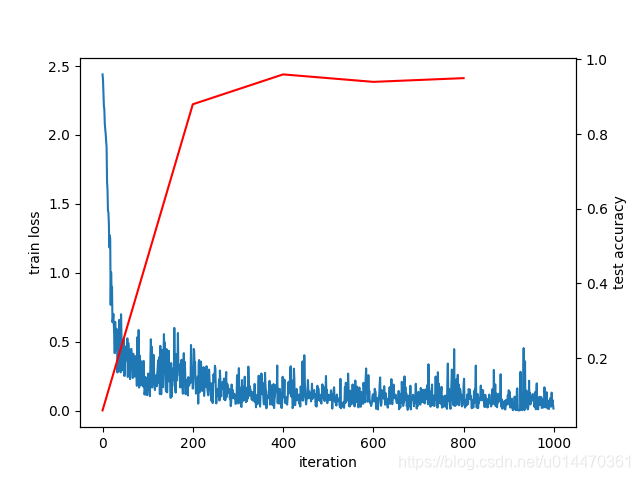
Como se muestra en la figura anterior, se puede ver que a medida que aumenta el número de entrenamiento, la pérdida muestra una oscilación convergente gradual, el valor de pérdida muestra una tendencia a la baja y la tasa de precisión aumenta continuamente.
Observaciones:
_, ax1 = plt.subplots () ¿Por qué hay _ al principio de esta oración, estos dos caracteres, no los entendí después de verificar la información, si lo sabe, hágamelo saber ~