Rastreador de Python: descargador de videos cortos multiplataforma para marcas de agua
El plan de rastreo descrito en este tutorial está finalizado y el 26 de octubre de 2020
Reitere solemnemente: La tecnología presentada en este artículo es solo para fines de aprendizaje y no debe ser atacada maliciosamente en las principales plataformas de videos cortos. Cualquier pérdida causada a los principales servidores de la plataforma de video corto es bajo su propio riesgo.
Rastreador de Python: descargador de videos cortos multiplataforma para marcas de agua
El video está comprimido, la dirección HD del video original: https://www.bilibili.com/video/BV1cr4y1w7yz/
Indique el autor y la dirección original para la reimpresión ~
Autor: West Ya Man
Perfil CSDN: West Ya Man
Direcciones de artículos: https://blog.csdn.net/qq_41707308/article/details/109293116
Caracteristicas
Este software está escrito en Python, la biblioteca de solicitudes se usa para el rastreo de datos y la interfaz GUI está escrita usando PyQt5 para agregar facilidad de uso a los usuarios comunes:
- Elimina perfectamente la marca de agua , ya no tienes que preocuparte por la marca de agua y los molestos créditos cuando recolectas videos atractivos;
- Soporte multiplataforma , soporte para Douyin, Kuaishou, Weishi, Pippi Funny, que cubre software de video pequeño comúnmente utilizado por la mayoría de los usuarios;
- El diseño de la interfaz GUI brindará una experiencia rápida y fácil de usar, y Xiaobai también la usará;
- Un aumento de la función de visualización de la barra de progreso , puede ver visualmente el proceso de ejecución del programa;
- Tome varios subprocesos y obtenga el rastreo de datos para evitar la interfaz de animación suspendida;
Desglose de cada plataforma
Douyin
Primero obtenga el enlace para compartir, abra un video en Douyin (todos los videos compartidos pueden usar el mismo método), seleccione el botón de compartir en la esquina inferior derecha y haga clic en el enlace de copia.
Cómo obtener el enlace:
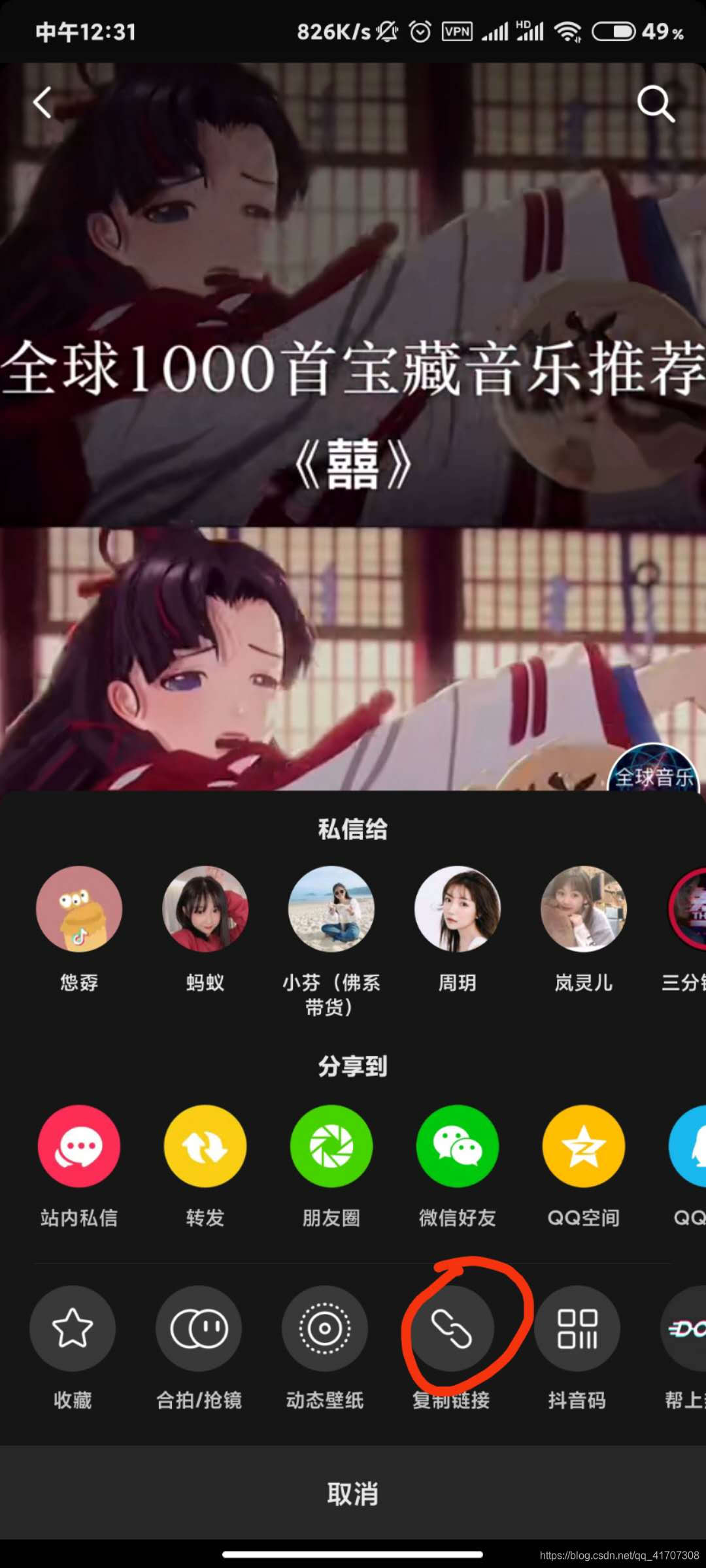
Copiar link:

Al mirar el enlace copiado, puede encontrar que no solo hay una dirección URL en el enlace, sino también algunos símbolos de texto. Por lo tanto, el primer paso es extraer la dirección URL y el nombre del archivo contenido en el enlace copiado:
def compile_name_url(url_text):
# 正则匹配分享链接,获取链接非空字符前的几个字符作为文件名
video_name = re.match(r'\S*', url_text)
if video_name:
video_name = video_name.group()
print(video_name)
# 正则匹配分享链接,获取链接
first_url = re.search(r'https://v.douyin.com/.*?/', url_text)
if first_url:
first_url = first_url.group()
print('第一次url==》', first_url)
return first_url, video_name
Copie el enlace al navegador y capture los datos del análisis del paquete de datos: puede encontrar que el enlace de video de destino requerido está en los datos json devueltos en la tercera imagen, y solo necesita obtener el campo correspondiente.



Sin embargo, las cosas no son tan simples como pensamos. Después de tomar el enlace, la URL obtenida se copia directamente en el navegador. El resultado aún tiene una marca de agua (como se muestra en la figura siguiente). Si observa detenidamente la dirección URL, encontrará el campo playwm y wm Es la abreviatura de marca de agua, que es marca de agua. Si vuelve a visitar después de eliminar wm, obtendrá una dirección sin marca de agua. ¡Eso es!

Código:
def first_request(first_url):
headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'sec-fetch-dest': 'document',
'sec-fetch-moe': 'navigate',
'sec-fetch-site': 'none',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Linux; Android 5.0; SM-G900P Build/LRX21T) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4195.1 Mobile Safari/537.36'
}
response = requests.get(first_url, headers=headers)
print('第二次url==》', response.url) # 获取第一次重定向后的url
# 截取第二次请求需要的参数
content = re.search(r'\d\d*\d', response.url).group()
params = {
"item_ids": content}
return params
def second_request(params):
response = requests.get('https://www.iesdouyin.com/web/api/v2/aweme/iteminfo/', params=params)
result = response.json() # 获得第二次请求的json,并从json中查找第三次请求需要的url
# print(result)
second_url = result['item_list'][0]['video']['play_addr']['url_list'][0]
play_url = re.sub(r'playwm', 'play', second_url)
print('第三次url==》', play_url)
return play_url
trabajador rápido
La plataforma Kuaishou es más sencilla, de la misma forma que para obtener enlaces:
Cómo obtener el enlace:

Copiar link:

Extraiga la URL y el nombre del video de la misma manera que TikTok. No repetiré el código aquí y comenzaré a analizar directamente el contenido de la solicitud de enlace:


El texto devuelto contiene un video sin marca de agua, y el nombre también es obvio "srcNoMark" (sin recurso de marca de agua), solo haga una solicitud directamente a esta URL. ¡Podemos disfrutar del canto de la señorita Ai Bei! ! !
Código:
def second_request(second_url):
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Cookie': 'did=web_209e6a4e64064f659be838aca3178ec1; didv=1603355622000',
'Host': 'c.kuaishou.com',
'Sec-Fetch-Dest': 'document',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'none',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Linux; Android 5.0; SM-G900P Build/LRX21T) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4195.1 Mobile Safari/537.36'
}
response = requests.get(second_url, headers=headers)
content = response.text
video_url = re.search(r'"srcNoMark":"https://txmov2.a.yximgs.com/.*?\"', content).group()[13:-1]
print(video_url)
return video_url
Microvisión
La misma rutina, primero obtenga el enlace:
Cómo obtener el enlace:

Cómo obtener el enlace:

A continuación, copie el enlace al navegador y capture el paquete para analizarlo. Se puede encontrar que la dirección URL donde se encuentra el video está almacenada en un archivo json solicitado. Luego descubrí que esta es una solicitud de publicación con parámetros, que deben ser analizados en la página web.


Primero vuelva a la primera solicitud para averiguar si hay parámetros. Después de una observación cuidadosa, se encuentra que el parámetro requerido feedid es en realidad parte de un enlace, por lo que debe cambiar la estrategia de rastreo y obtener el enlace primero. Después de obtener los parámetros, continúe con el siguiente paso para obtener el video.

Código:
def compile_name_url(url_text):
video_name = re.findall(r'(\w*)', url_text)
feedid = re.findall(r'feed/(\w*)', url_text)
if video_name and feedid:
video_name = video_name[0]
feedid = feedid[0]
return feedid, video_name
def first_request(feedid):
headers = {
'accept': 'application/json',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'content-length': '84',
'content-type': 'application/json',
'cookie': 'RK=BuAQ1v+yV3; ptcz=6f7072f84fa03d56ea047b407853df6a5375d719df1031ef066d11b09fb679e4; pgv_pvi=8434466816; pgv_pvid=1643353500; tvfe_boss_uuid=3b10306bf3ae662b; o_cookie=1074566721; pac_uid=1_1074566721; ied_qq=o1074566721; LW_sid=k1Y5n9s3Y0K866h7P246v4k6o8; LW_uid=u1v5i9V3p0L806m7R226s4W7F1; eas_sid=J1p5G9s3A0h8Z6c7l2a6x4E7w7; iip=0; ptui_loginuin=1074566721; person_id_bak=5881015637151283; person_id_wsbeacon=5920911274348544; wsreq_logseq=341295039',
'origin': 'https://h5.weishi.qq.com',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'user-agent': 'Mozilla/5.0 (Linux; Android 5.0; SM-G900P Build/LRX21T) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4195.1 Mobile Safari/537.36',
'x-requested-with': 'XMLHttpRequest'
}
rejson = {
'datalvl': "all",
'feedid': feedid,
'recommendtype': '0',
'_weishi_mapExt': '{}'
}
first_url = 'https://h5.weishi.qq.com/webapp/json/weishi/WSH5GetPlayPage'
response = requests.post(first_url, headers=headers, json=rejson)
result = response.json()
video_url = result['data']['feeds'][0]['video_url']
return video_url
Pippi gracioso
En el mismo paso, obtenga el enlace primero.
Cómo obtener el enlace:

Copiar link:

Observando la cadena compartida, podemos ver que el nombre del video no se agrega esta vez, y los nombres de todos los videos solo se pueden obtener del contenido solicitado. Primero coloque el enlace en el navegador para analizar los datos.


Esta vez también encontré que esta es una solicitud de publicación, y también requiere parámetros. En vista de la experiencia de Weishi, verifiqué cuidadosamente el enlace para compartir original. Como era de esperar, los dos parámetros modificados están ocultos en el enlace. Simplemente obtenga los parámetros pid y mid, y luego inicie una solicitud para obtener el video.

Código:
def compile_name_url(url_text):
headers = {
'Host': 'share.ippzone.com',
'Origin': 'http://share.ippzone.com',
'Referer': url_text,
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36 Edg/84.0.522.52'
}
mid = re.findall(r'mid=(\d*)', url_text)
pid = re.findall(r'pid=(\d*)', url_text)
if mid and pid:
mid = int(mid[0])
pid = int(pid[0])
parmer = {
'mid': mid,
'pid': pid,
'type': 'post'
}
url = 'http://share.ippzone.com/ppapi/share/fetch_content'
r = requests.post(url, headers=headers, json=parmer)
result=r.json()
video_name = result['data']['post']['content'].replace(' ', '')
video_url = result['data']['post']['videos'][str(result['data']['post']['imgs'][0]['id'])]['url']
return video_url, video_name
para resumir
Esta es la primera vez que escribes un blog como principiante en programación. Es posible que la escritura no sea lo suficientemente buena o clara. Es un intercambio y un intercambio puramente técnico. El contenido compartido es solo para aprender e investigar, y no se permiten ataques maliciosos en los principales servidores de plataformas de video.
Finalmente, espero que todos reimpriman por favor indique la fuente ~
Autor: West Ya Man
Perfil CSDN: West Ya Man
Direcciones de artículos: https://blog.csdn.net/qq_41707308/article/details/109293116