Capítulo 1 Introducción
En el artículo anterior, presenté la preparación del entorno relacionado con Flink y completé el establecimiento de un entorno de desarrollo Flink simple; este artículo presenta un caso completo de extremo a extremo que cubre la informática Flink : cliente => Servicio API web = > Kafka => Flink => MySQL. Esta vez seguimos tomando Flink Table API / SQL como ejemplo y lo implementamos en docker-compose. (En el artículo solo se proporciona la parte clave del código. Para obtener el código completo, consulte el github subido por el autor).

Capítulo 2 docker-compose
2.1 Agregar archivo docker-compose.yml
version: '2'
services:
jobmanager:
image: zihaodeng/flink:1.11.1
volumes:
- D:/21docker/flinkDeploy:/opt/flinkDeploy
hostname: "jobmanager"
expose:
- "6123"
ports:
- "4000:4000"
command: jobmanager
environment:
- JOB_MANAGER_RPC_ADDRESS=jobmanager
taskmanager:
image: zihaodeng/flink:1.11.1
volumes:
- D:/21docker/flinkDeploy:/opt/flinkDeploy
expose:
- "6121"
- "6122"
depends_on:
- jobmanager
command: taskmanager
links:
- jobmanager:jobmanager
environment:
- JOB_MANAGER_RPC_ADDRESS=jobmanager
zookeeper:
container_name: zookeeper
image: zookeeper:3.6.1
ports:
- "2181:2181"
kafka:
container_name: kafka
image: wurstmeister/kafka:2.12-2.5.0
volumes:
- D:/21docker/var/run/docker.sock:/var/run/docker.sock
ports:
- "9092:9092"
depends_on:
- zookeeper
environment:
#KAFKA_ADVERTISED_HOST_NAME: kafka
HOSTNAME_COMMAND: "route -n | awk '/UG[ \t]/{print $$2}'"
KAFKA_CREATE_TOPICS: "order-log:1:1"
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
#KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://127.0.0.1:9092
#KAFKA_LISTENERS: PLAINTEXT://0.0.0.0:9092
mysql:
image: mysql:5.7
container_name: mysql
volumes:
- D:/21docker/mysql/data/db:/var/lib/mysql/
- D:/21docker/mysql/mysql-3346.sock:/var/run/mysql.sock
- D:/21docker/mysql/data/conf:/etc/mysql/conf.d
ports:
- 3306:3306
command:
--default-authentication-plugin=mysql_native_password
--lower_case_table_names=1
environment:
MYSQL_ROOT_PASSWORD: 123456
TZ: Asia/Shanghai2.2 inicio de docker-compose
$ docker-compose up -d
Comprobar funcionamiento

En esta sección, docker-compose está listo, y será muy conveniente iniciar el entorno de trabajo más tarde, a continuación, comience a preparar el programa correspondiente.
Capítulo 3 Creación de un proyecto WebApi
3.1 Crear proyecto de interfaz WebApi (Restful API)
Use springboot para crear rápidamente un proyecto de API. El autor aquí usa el formato de interfaz Restful Api; parte del código es el siguiente (consulte el github del autor para obtener el código completo).
Cree una interfaz de publicación para que el cliente llame
@RestController
@RequestMapping("/order")
public class OrderController {
@Autowired
private Sender sender;
@PostMapping
public String insertOrder(@RequestBody Order order) {
sender.producerKafka(order);
return "{\"code\":0,\"message\":\"insert success\"}";
}
}Cree una clase de remitente y envíe datos a Kafka
public class Sender {
@Autowired
private KafkaTemplate<String,String> kafkaTemplate;
private static Random rand = new Random();
public void producerKafka(Order order){
order.setPayTime(String.valueOf(new Timestamp(System.currentTimeMillis()+ rand.nextInt(100))));//EventTime
kafkaTemplate.send("order-log", JSON.toJSONString(order));
}
}
Capítulo 4 Creación de trabajos Flink
Aquí, Flink Table API / SQL se utiliza para implementar un cálculo de ventana de caída: los datos leídos en Kafka se escriben en MySQL después de resumir el cálculo de la ventana.
public class Kafka2MysqlByEnd2End {
public static void main(String[] args) throws Exception {
// Kafka source
String sourceSQL="CREATE TABLE order_source (\n" +
" payTime VARCHAR,\n" +
" rt as TO_TIMESTAMP(payTime),\n" +
" orderId BIGINT,\n" +
" goodsId INT,\n" +
" userId INT,\n" +
" amount DECIMAL(23,10),\n" +
" address VARCHAR,\n" +
" WATERMARK FOR rt as rt - INTERVAL '2' SECOND\n" +
" ) WITH (\n" +
" 'connector' = 'kafka-0.11',\n" +
" 'topic'='order-log',\n" +
" 'properties.bootstrap.servers'='kafka:9092',\n" +
" 'format' = 'json',\n" +
" 'scan.startup.mode' = 'latest-offset'\n" +
")";
//Mysql sink
String sinkSQL="CREATE TABLE order_sink (\n" +
" goodsId BIGINT,\n" +
" goodsName VARCHAR,\n" +
" amount DECIMAL(23,10),\n" +
" rowtime TIMESTAMP(3),\n" +
" PRIMARY KEY (goodsId) NOT ENFORCED\n" +
" ) WITH (\n" +
" 'connector' = 'jdbc',\n" +
" 'url' = 'jdbc:mysql://mysql:3306/flinkdb?characterEncoding=utf-8&useSSL=false',\n" +
" 'table-name' = 'good_sale',\n" +
" 'username' = 'root',\n" +
" 'password' = '123456',\n" +
" 'sink.buffer-flush.max-rows' = '1',\n" +
" 'sink.buffer-flush.interval' = '1s'\n" +
")";
// 创建执行环境
EnvironmentSettings settings = EnvironmentSettings
.newInstance()
.useBlinkPlanner()
.inStreamingMode()
.build();
//TableEnvironment tEnv = TableEnvironment.create(settings);
StreamExecutionEnvironment sEnv = StreamExecutionEnvironment.getExecutionEnvironment();
//sEnv.setRestartStrategy(RestartStrategies.fixedDelayRestart(3, Time.of(1, TimeUnit.SECONDS)));
//sEnv.enableCheckpointing(1000);
//sEnv.setStateBackend(new FsStateBackend("file:///tmp/chkdir",false));
StreamTableEnvironment tEnv= StreamTableEnvironment.create(sEnv,settings);
Configuration configuration = tEnv.getConfig().getConfiguration();
//设置并行度为1
configuration.set(CoreOptions.DEFAULT_PARALLELISM, 1);
//注册souuce
tEnv.executeSql(sourceSQL);
//注册sink
tEnv.executeSql(sinkSQL);
//UDF 在作业中定义UDF
tEnv.createFunction("exchangeGoods", ExchangeGoodsName.class);
String strSQL=" SELECT " +
" goodsId," +
" exchangeGoods(goodsId) as goodsName, " +
" sum(amount) as amount, " +
" tumble_start(rt, interval '5' seconds) as rowtime " +
" FROM order_source " +
" GROUP BY tumble(rt, interval '5' seconds),goodsId";
//查询数据 插入数据
tEnv.sqlQuery(strSQL).executeInsert("order_sink");
//执行作业
tEnv.execute("统计各商品营业额");
}
}
Capítulo 5 Creación de tablas de bases de datos MySQL
5.1 Construir una biblioteca
mysql> create database flinkdb;5.2 Crear una tabla
mysql> create table good_sale(goodsId bigint primary key, goodsName varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci, amount decimal(23,10), rowtime timestamp);Nota: la clave principal es la misma que la clave principal definida por el flink job ddl. La clave principal se define en el flink ddl, y el conector está en el modo upsert (Flink decidirá si insertar una nueva fila o actualizar una fila existente de acuerdo con la clave principal para garantizar la idempotencia), si no La definición es modo de adición (modo de inserción de inserción, si la clave principal entra en conflicto, la inserción fallará).
En este punto, se han preparado el entorno y el código y luego se comienza a ejecutar la verificación.
Capítulo 6 Ejecución de trabajos
6.1 Verificación de depuración local
6.1.1 Iniciar el clúster
Usando el método del Capítulo 2, inicie nuestro entorno de clúster preparado:
$ docker-compose up -d 
6.1.2 Iniciar trabajo
Inicie el proyecto WebApi y el proyecto de trabajo Flink en IDEA local .
6.1.3 Iniciar una solicitud
Aquí se utiliza una herramienta http para simular que el cliente inicie una solicitud y envíe datos en formato json:

6.1.4 Ver el estado de ejecución de los trabajos de flink
Ver el registro directamente en la consola de IDEA

6.1.5 Ver resultados
Ver los resultados en MySQL

En este paso, puede ver que el trabajo depurado por el IDE local ha extraído con éxito los datos de la fuente y, después del cálculo de flink, los datos se escriben en MySQL. A continuación, completaremos el envío del trabajo al clúster para que se ejecute.
6.2 Verificación del funcionamiento del clúster
6.2.1 Embalaje
Empaquetado del paquete jar del proyecto WebAPI
Vaya al directorio lotemall-webapi (proyecto WebApi del autor) para ejecutar el comando de empaquetado
mvn clean package -DskipTestsPrepare el Dockerfile y colóquelo en el mismo directorio que el paquete jar. Ejecute el siguiente comando para crear imágenes
$ docker build -t lotemall-webapi .Empaque el paquete del tarro de trabajo de Flink
Vaya al directorio flink-kafka2mysql (proyecto de trabajo de Flink del autor) para ejecutar el comando de empaquetado
Tenga en cuenta que debido a que enviamos al contenedor para su uso, la IP de configuración de la conexión de origen y receptor debe cambiarse del host local original al nombre del contenedor
mvn clean package -DskipTestsColoque el paquete jar empaquetado en el directorio de montaje de Docker

6.2.2 Iniciar el clúster
Usando el método del Capítulo 2, inicie nuestro entorno de clúster preparado:
$ docker-compose up -d
6.2.3 Iniciar proyecto WebAPI
Ejecute el comando docker run para iniciar el proyecto WebAPI
$ docker run --link kafka:kafka --net flink-online_default -e TZ=Asia/Shanghai -d -p 8090:8080 lotemall-webapi6.2.4 Ejecutar trabajo de Flink
Ingrese al contenedor flink jobmanager y ejecute el trabajo
$ docker exec -it flink-online_jobmanager_1 /bin/bash
$ bin/flink run -c sql.Kafka2MysqlByEnd2End /opt/flinkDeploy/flink-kafka2mysql-0.0.1.jar -dO envíe el paquete del jar del trabajo a través de la interfaz web

Después de enviar el trabajo, verifique la interfaz web de Flink, puede ver que el trabajo que enviamos ha comenzado a ejecutarse

6.2.5 Iniciar una solicitud
También use la herramienta http para simular que el cliente inicie una solicitud y envíe datos en formato json:

6.2.6 Ver el estado de ejecución de los trabajos de Flink
Envíe al clúster para que se ejecute, puede ver directamente el estado de ejecución del trabajo en la interfaz web de Flink

 Ver la marca de agua generada
Ver la marca de agua generada
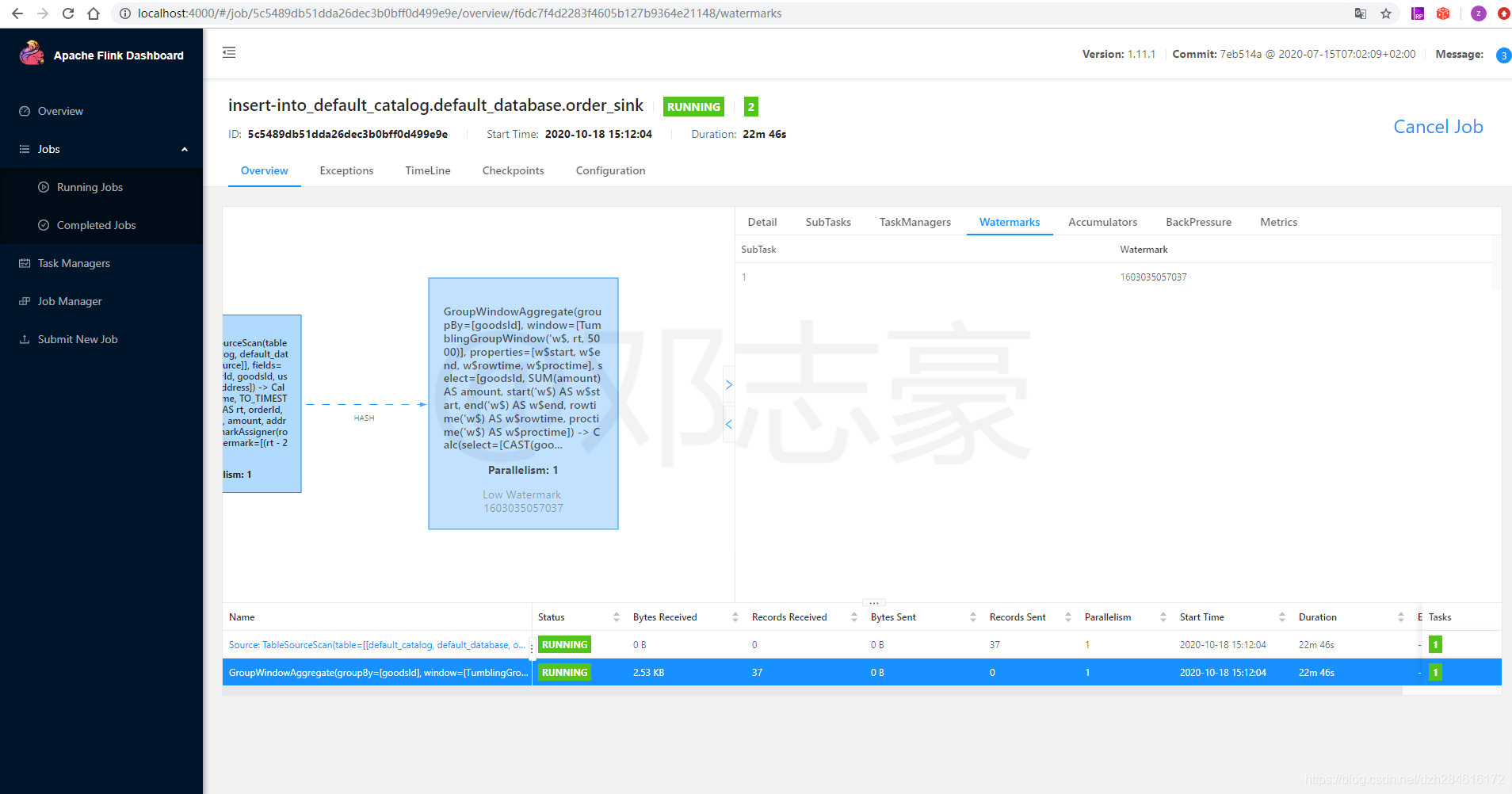
6.2.7 Ver resultados
Ver los resultados en MySQL

El registro cuyo GoodsName es "cake" en la primera línea es el resultado del cálculo de Flink en este grupo.
En resumen , este artículo presenta la implementación conveniente de clústeres mediante docker-compose y completa un caso completo de informática de flujo Flink.