导语
自从喵先生之前给小白讲了HDFS的故事,小白听的意犹未尽,整天缠着喵先生,想让他再继续讲讲hadoop框架内另外一个比较重要的MapReduce计算框架是啥。
目录
- MapReduce 是什么
- MapReduce 的原理
1 MapReduce 是什么
喵先生说:"MapReduce是hadoop的一个计算框架,说直白点就是hdfs负责存储,那么像其他统计、计算之类的事情就会交给MapReduce来做,分为map过程和reduce过程。
Map 过程是拆解,比如说有辆红色的小汽车,有一群工人,把它拆成零件了,这就是Map"
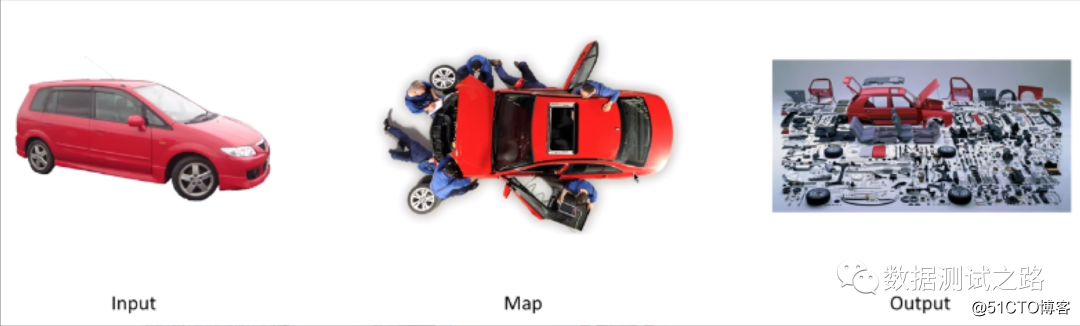
Reduce 过程是组合,我们有很多汽车零件,还有很多其他各种装置零件,把他们一阵拼装,变成变形金刚,这就是Reduce。

小白听了:"这么听起来,感觉挺形象的,那么具体的map过程和reduce过程是如何。"
"且听我慢慢给你讲解",喵先生咽了咽口水。
2 MapReduce 的原理
喵先生说:"首先我们来看下面的数据————学生的信息记录表"

- 我们可以过滤出性别为1的数据;
- 可以将性别字段中1转换成男且0转换成女;
- 也可以将字段地址展开;
以上的过程就是map:以一条记录为单位做映射(过滤/转换/展开)
小白说:"我感觉map的原理跟mysql的语法好像啊,select * from student where sex=1,都是对数据进行1条1条的处理."
喵先生:"嗯,孺子可教,我们来继续看看reduce过程:我们想统计出学习各专业共有多少名同学时,需要将python、java、c进行分组,以这样的一组为单位进行统计计算。"
以上的过程就是reduce:以组为单位进行计算
Xiaobai dijo: "¿No es este el principio de grupo por en mysql, las estadísticas se basan en el grupo",
agregó el Sr. Meow: "La idea es similar a la del grupo por de mysql"
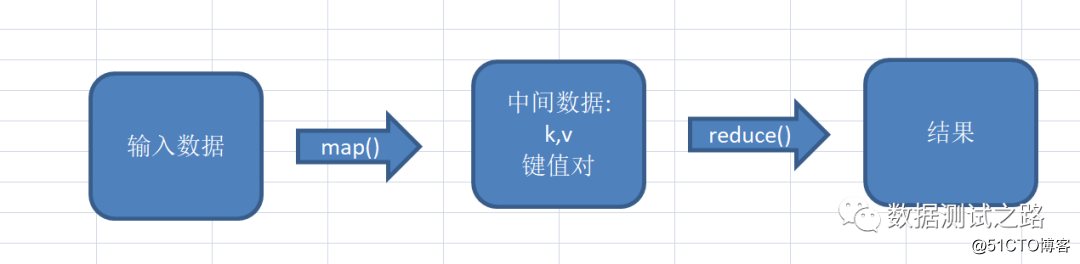
Finalmente Sr. maullido continuar concluyó: "los datos de entrada se realiza de acuerdo a una correspondencia de unidades de datos (método de mapa), y luego pares de valores kv salidas, como una unidad de entrada de un grupo a reducir la salida final calculado."
Aprender el blanco Continúe preguntando: "Bueno, entiendo el proceso general de mapreduce, ¿cómo obtiene datos de hdfs y cómo interactúan entre sí?"
Sr. Meow: "Sí, Xiaobai, parece que estás bastante avanzado. Echemos un vistazo al diagrama de interacción de mapreduce, mapreduce se divide en 4 pasos "
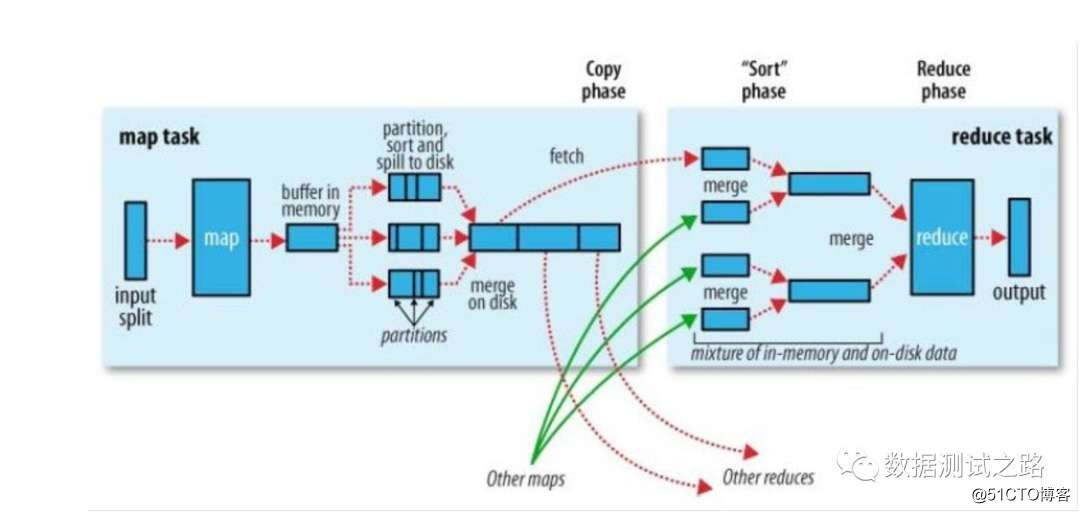
Dividido en 4 pasos:
- La tarea de mapa utiliza la división para obtener datos en hdfs, una división corresponde a un método de mapa y genera datos de formato de partición, valor y clave
- La tarea de mapa coloca los datos recuperados en la memoria, particiona y clasifica los datos.
- La tarea de reducción ahora conoce la partición donde se encuentra la clave y extrae los datos de la partición de archivo correspondiente (dfs).
- Y calcule los datos de salida finales.
"¿Por qué el mapa no obtiene los datos directamente de hdfs, tiene que usar split para obtenerlos en el medio?" Xiaobai se rascó la cabeza y miró al Sr.
Meow. El Sr. Meow asintió y le dijo a Xiaobai: "Esta pregunta es muy buena. El tamaño predeterminado de split es igual a hdfs. Uno de los bloques de bloques mide aproximadamente 64M, pero el tamaño de la división se puede ajustar para hacer frente a diferentes tipos de cálculo.
Cuando ejecutamos CPU-bound (computación intensiva), podemos configurar la división para que sea más pequeña, y múltiples divisiones corresponden a 1 bloque. Esto puede aumentar la velocidad de cálculo.
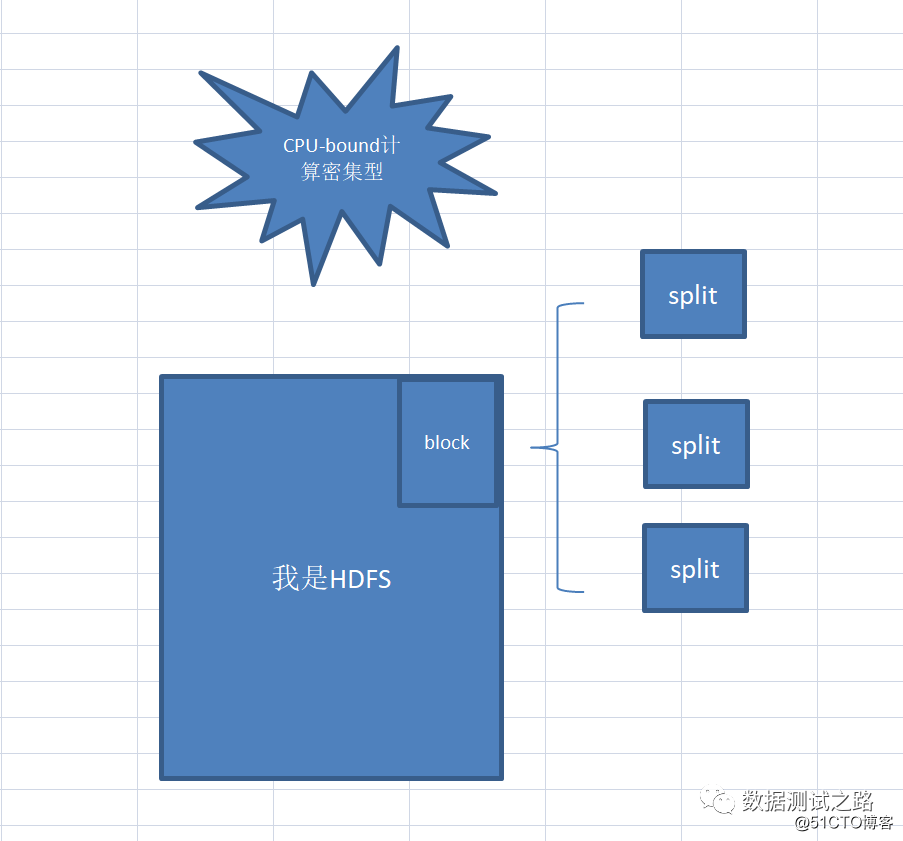
Cuando ejecutamos IO-bound (IO-intensivo), la división se puede establecer un poco más grande, y 1 división corresponde a N bloques de bloques, lo que puede mejorar la eficiencia de la lectura y escritura de IO.
CPU-bound(计算密集型):
假设有一道数学题,题干只有一行字,
读题花费1秒,解题需要1个月才能解出来,
这样就是CPU-bound。(CPU利用率几乎100%)。IO bound(IO密集型):
假设有一道数学题,题干有史记那么厚,
读完花费2个月,问题只是让你回答1+1=?,
这样就是I/O-bound。(CPU IDLE状态)。小白总结到:“split原来可以控制map的并行度,决定了到底启用多少个map任务,一个split对一个map方法,输出k,v,p键值对”
“这里为什么要将输出的kv键值对放到内存里呢,虽然内存速度是硬盘的10万倍,但最终数据不也会写到磁盘上吗,这不等于脱了裤子放屁吗?”小白着急的问题,
“嗯,词粗理不粗,这里放map输出的kv键值对放100M的内存中,还做了一件重要的事情————那就是对k,v,p数据进行排序,将分区p下的数据放到一起,并且同一个分区下的k进行了排序,方便后面的reduce是做 归并排序。”喵先生解释道。
“你慢点呢,我都听得懵了,举个例子呢”
“那就看看下面的例子吧,统计java\python\mysql出现的次数”喵先生迅速的画了一张图
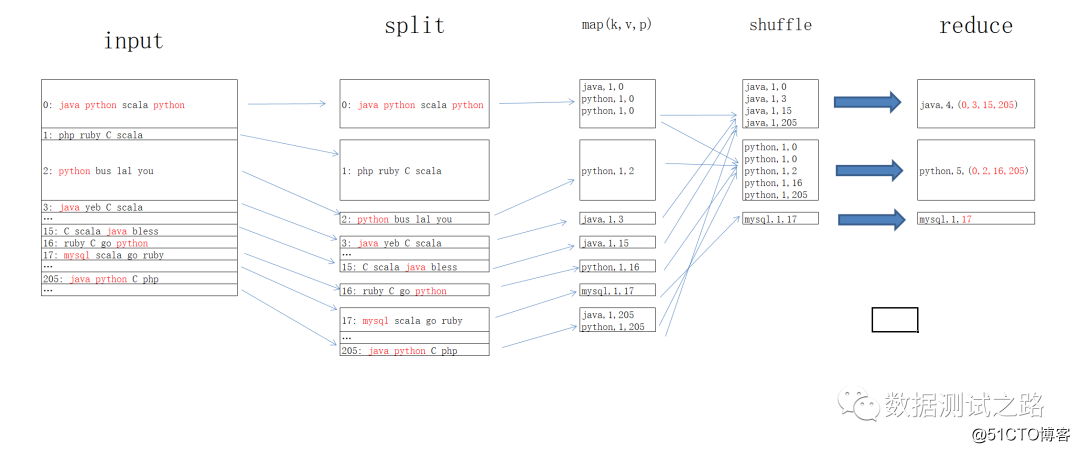
imput阶段:hdfs的block块上存有java、python、mysql的存储文件位置
split阶段:使用split对hdfs上的文件进行切块,其中文件分区0、2、3、15、16、17、205上存有java\python\mysql的信息,
map阶段:将每个分区上的含有java\python\mysql信息的数据进行kvp键值对输出,例:java,1,0 代表0号分区下存有java信息1次
shuffle阶段:在内存中对同一组数据进行排序,例:java出现在0、3、15、205分区上,
reduce阶段:最终reduce任务根据shffle阶段输出的排序,到指定的的文件分区上获取到对应的文件。
“真神奇,看来内存中的排序还真重要,有效减少了文件读取的次数,一次读取多次取数,对应的处理速度也加快了”小白恍然大悟到。
"还有个问题,我看上面的例子中key的数量是3个(java\python\mysql)对应的reduce的任务数也是3个,是不是key的数量就等于reduce的数量?"小白问道,
“观察的挺仔细的呀,reduce的数量是由程序员代码里面控制的,但key的数量也不完全等于reduce的数量,你想想万一key有10万个呢?那么reduce数量需要10万个吗?肯定没那么多资源,所以一般是根据具体服务器资源中reduce执行器的数量决定的。”喵先生补充到。
"另外还需要注意的是,如果key的数据量分布不均匀的话,可能会出现数据倾斜的问题,假如2个key————1个男,1个女,男数据量有10T,女的数据就只有1G,这样的话进行,系统遵循reduce处理同一个key时会将同一个key被分到同一个reduce执行器下,那么这样的话一个reduce执行器就会处理10T的数据,另一个reduce执行器处理1G数据,这就照成了数据倾斜。"喵先生继续补充到。
”怎么解决呢数据倾斜呢“,小白问道
”那就下盘给你说啦~“
更多的干货在,微信公众号【数据猿温大大】
关注 获取 hadoop 官方权威指南
