Código fuente de este artículo: GitHub · haga clic aquí || GitEE · haga clic aquí
1. Mecanismo de trabajo
1. Descripción básica
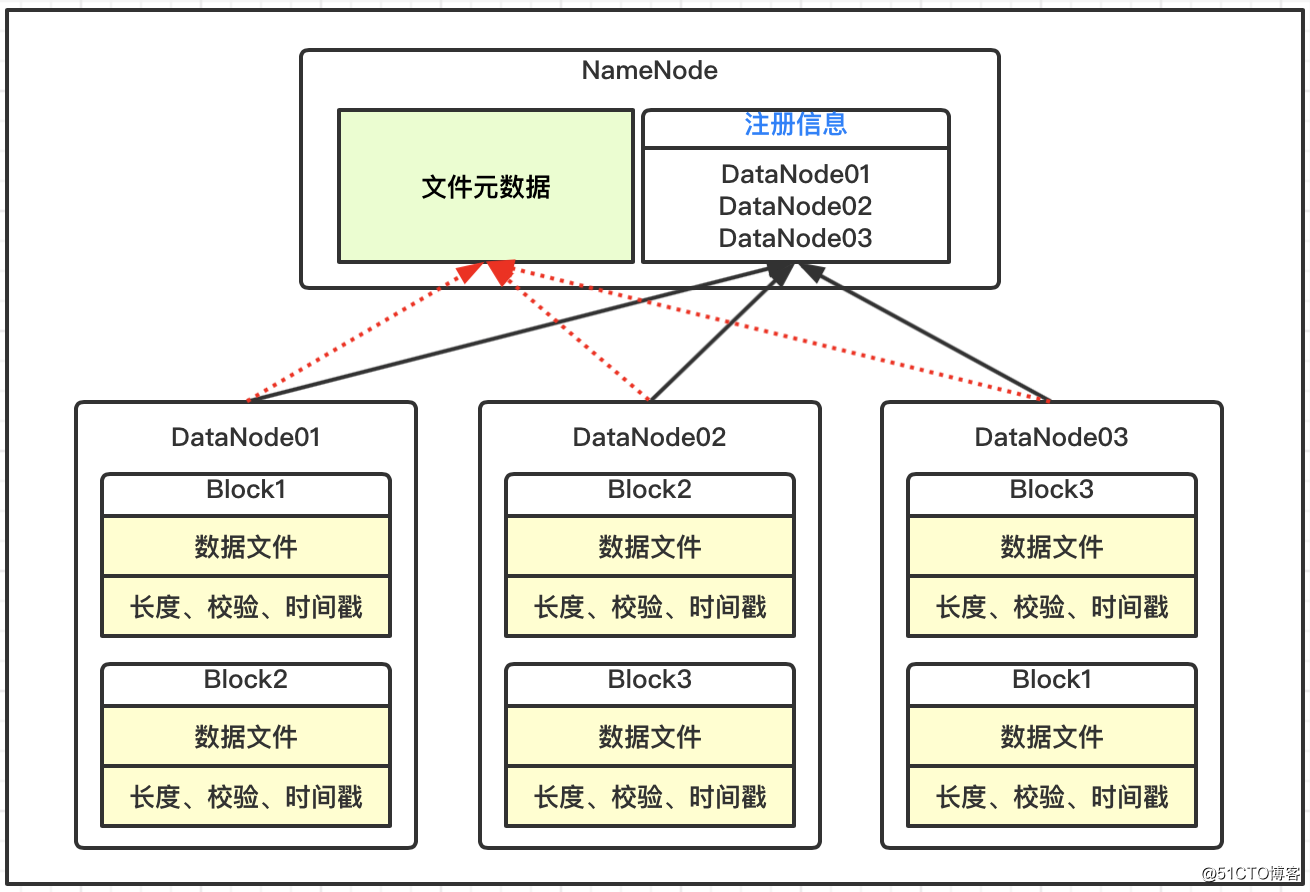
Los bloques de datos en el DataNode se almacenan en el disco en forma de archivos, incluidos dos archivos, uno es la información en sí y el otro son los metadatos del bloque de datos, incluida la longitud, la suma de comprobación y la marca de tiempo;
Después de que el DataNode se inicia, se registra con el servicio NameNode y reporta periódicamente toda la información de metadatos del bloque de datos al NameNode;
Existe un mecanismo de latido entre el DataNode y el NameNode. Cada 3 segundos, el resultado se devuelve con el comando de ejecución del NameNode al DataNode, como la replicación y eliminación de datos. Si el latido del DataNode no se recibe durante más de 10 minutos, el nodo se considera no disponible.
2. Duración personalizada
Mediante el archivo de configuración hdfs-site.xml, modifique la duración del tiempo de espera y el latido. La unidad de heartbeat.recheck.interval es milisegundos y la unidad de dfs.heartbeat.interval es segundos.
<property>
<name>dfs.namenode.heartbeat.recheck-interval</name>
<value>600000</value>
</property>
<property>
<name>dfs.heartbeat.interval</name>
<value>6</value>
</property>3. El nuevo nodo está en línea
Los nodos de la máquina actual son hop01, hop02, hop03, y sobre esta base se agrega un nuevo nodo hop04.
Los pasos básicos
Obtenga el entorno hop04 basado en el clon del nodo de servicio actual;
Modificar la configuración básica de Centos7 y eliminar los archivos de registro y datos;
Inicie DataNode para asociarse al clúster;
4. Configuración de varios directorios
La configuración sincroniza los servicios en el clúster, formateados para iniciar hdfs y yarn, y los archivos cargados para la prueba.
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///${hadoop.tmp.dir}/dfs/data01,file:///${hadoop.tmp.dir}/dfs/data02</value>
</property>Configuración de dos listas en blanco y negro
1. Configuración de la lista blanca
Configure la lista blanca y distribuya la configuración al servicio de clúster;
[root@hop01 hadoop]# pwd
/opt/hadoop2.7/etc/hadoop
[root@hop01 hadoop]# vim dfs.hosts
hop01
hop02
hop03Configure hdfs-site.xml, que se distribuye al servicio de clúster;
<property>
<name>dfs.hosts</name>
<value>/opt/hadoop2.7/etc/hadoop/dfs.hosts</value>
</property>Actualizar NameNode
[root@hop01 hadoop2.7]# hdfs dfsadmin -refreshNodesActualizar ResourceManager
[root@hop01 hadoop2.7]# yarn rmadmin -refreshNodes2. Configuración de lista negra
Configure la lista negra y distribuya la configuración al servicio de clúster;
[root@hop01 hadoop]# pwd
/opt/hadoop2.7/etc/hadoop
[root@hop01 hadoop]# vim dfs.hosts.exclude
hop04Configure hdfs-site.xml, que se distribuye al servicio de clúster;
<property>
<name>dfs.hosts.exclude</name>
<value>/opt/hadoop2.7/etc/hadoop/dfs.hosts.exclude</value>
</property>Actualizar NameNode
[root@hop01 hadoop2.7]# hdfs dfsadmin -refreshNodesActualizar ResourceManager
[root@hop01 hadoop2.7]# yarn rmadmin -refreshNodes3. Archivo de archivos
1. Descripción básica
Las características del almacenamiento HDFS son adecuadas para archivos grandes con datos masivos, si cada archivo es muy pequeño, se generará una gran cantidad de información de metadatos, ocupando demasiada memoria, y se volverá lenta cuando interactúen NaemNode y DataNode.
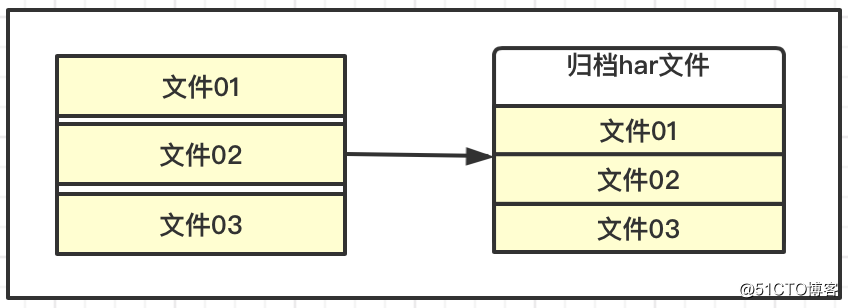
HDFS puede archivar y almacenar algunos archivos pequeños, que pueden entenderse como almacenamiento comprimido, lo que reduce el consumo de NameNode y reduce la carga de interacción. Al mismo tiempo, también permite el acceso a archivos pequeños archivados para mejorar la eficiencia general.
2. Proceso de operación
Crea dos directorios
# 存放小文件
[root@hop01 hadoop2.7]# hadoop fs -mkdir -p /hopdir/harinput
# 存放归档文件
[root@hop01 hadoop2.7]# hadoop fs -mkdir -p /hopdir/haroutputSubir archivo de prueba
[root@hop01 hadoop2.7]# hadoop fs -moveFromLocal LICENSE.txt /hopdir/harinput
[root@hop01 hadoop2.7]# hadoop fs -moveFromLocal README.txt /hopdir/harinputOperación de archivo
[root@hop01 hadoop2.7]# bin/hadoop archive -archiveName output.har -p /hopdir/harinput /hopdir/haroutputVer archivos de almacenamiento
[root@hop01 hadoop2.7]# hadoop fs -lsr har:///hopdir/haroutput/output.har
De esta manera, se pueden eliminar los bloques de archivos pequeños originales.
Desarchivar archivos
# 执行解除
[root@hop01 hadoop2.7]# hadoop fs -cp har:///hopdir/haroutput/output.har/* /hopdir/haroutput
# 查看文件
[root@hop01 hadoop2.7]# hadoop fs -ls /hopdir/haroutputCuarto, el mecanismo de la papelera de reciclaje.
1. Descripción básica
Si la función de papelera de reciclaje está habilitada, los archivos eliminados se pueden restaurar dentro de un tiempo específico para evitar la eliminación accidental de datos. La implementación específica dentro de HDFS es iniciar un subproceso en segundo plano más vacío en el NameNode. Este subproceso administra y monitorea específicamente los archivos debajo de la papelera de reciclaje del sistema. Los archivos que se colocan en la papelera de reciclaje y exceden su ciclo de vida se eliminarán automáticamente.
2. Encienda la configuración
Esta configuración debe sincronizarse con todos los servicios del clúster;
[root@hop01 hadoop]# vim /opt/hadoop2.7/etc/hadoop/core-site.xml
# 添加内容
<property>
<name>fs.trash.interval</name>
<value>1</value>
</property>fs.trash.interval = 0, significa que el mecanismo de la papelera de reciclaje está deshabilitado y = 1 significa que está habilitado.
Cinco, dirección de código fuente
GitHub·地址
https://github.com/cicadasmile/big-data-parent
GitEE·地址
https://gitee.com/cicadasmile/big-data-parentLectura recomendada: sistema de programación de acabado
| Número de serie | nombre del proyecto | Dirección de GitHub | Dirección GitEE | Recomendado |
|---|---|---|---|---|
| 01 | Java describe patrones de diseño, algoritmos y estructuras de datos | GitHub · haga clic aquí | GitEE · Haga clic aquí | ☆☆☆☆☆ |
| 02 | Fundamentos Java, concurrencia, orientado a objetos, desarrollo web | GitHub · haga clic aquí | GitEE · Haga clic aquí | ☆☆☆☆ |
| 03 | Explicación detallada del caso del componente básico del microservicio SpringCloud | GitHub · haga clic aquí | GitEE · Haga clic aquí | ☆☆☆ |
| 04 | Caso completo de arquitectura de microservicio SpringCloud | GitHub · haga clic aquí | GitEE · Haga clic aquí | ☆☆☆☆☆ |
| 05 | Comenzando con la aplicación básica de SpringBoot framework a avanzada | GitHub · haga clic aquí | GitEE · Haga clic aquí | ☆☆☆☆ |
| 06 | SpringBoot framework integra y desarrolla middleware común | GitHub · haga clic aquí | GitEE · Haga clic aquí | ☆☆☆☆☆ |
| 07 | Caso básico de gestión de datos, distribución, diseño de arquitectura | GitHub · haga clic aquí | GitEE · Haga clic aquí | ☆☆☆☆☆ |
| 08 | Grandes series de datos, almacenamiento, componentes, informática y otros marcos | GitHub · haga clic aquí | GitEE · Haga clic aquí | ☆☆☆☆☆ |