Para las estadísticas del indicador de tráfico del sitio web, generalmente se puede dividir en las siguientes dimensiones
- Cuente las visitas a la página por día
- Cuente el número de visitantes únicos por día (por recuento)
- Cuente el número de sesiones independientes por día
- Estadísticas por región de visitantes
- Dirección IP del visitante de estadísticas
- Análisis de la página por origen
Después de recopilar los indicadores anteriores, puede analizar la situación general del sitio web por período de tiempo
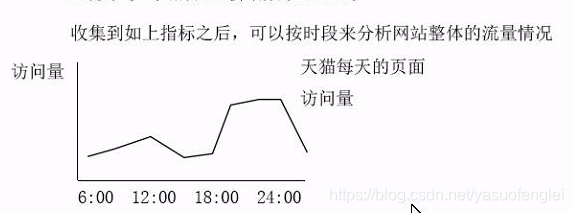
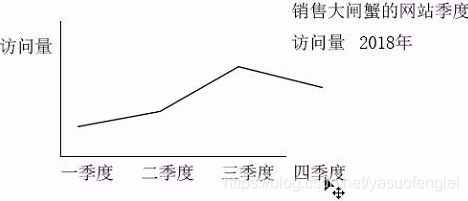
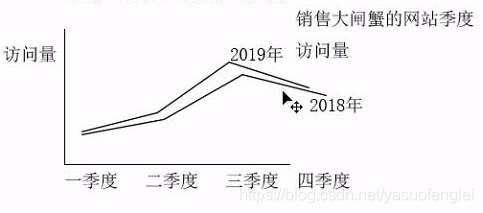
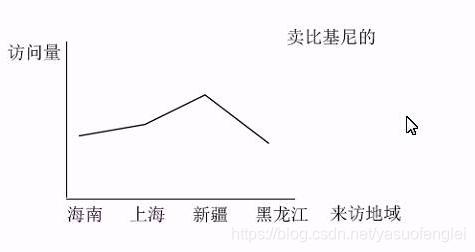
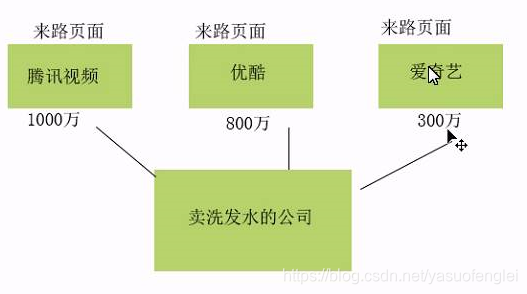
Los indicadores estadísticos de este proyecto se resumen a continuación
- PV, visitas a la página. El usuario hace clic en la página una vez, incluso si es un PV, la operación de actualización también se cuenta. Contaremos el PV total en un día.
- UV, el número de visitantes únicos. Por recuento, contaremos cuántos usuarios diferentes visitan el sitio en un día. Idea de procesamiento: cuando un usuario visita un sitio web, el fondo generará una identificación de usuario (uvid) para el usuario y luego guardará el uvid en la cookie del navegador del usuario, y la información de uvid se llevará la próxima vez que el usuario lo visite. Entonces, este indicador realmente cuenta cuántos uvid diferentes hay en un día.
- VV, el número de sesiones independientes (Sesión). Cuente el número de sesiones diferentes en un día, y las condiciones para generar una nueva sesión: 1. Cierre el navegador y ábralo nuevamente, se generará una nueva sesión. 2 Después del período de tiempo de espera de la operación de la sesión (generalmente media hora), se generará una nueva sesión. Idea de implementación: cuando se genera una nueva sesión, el fondo generará una identificación de sesión (ssid) para esta sesión y luego la almacenará en una cookie. Entonces, contar VV es en realidad contar cuántos ssids diferentes hay en un día.
- BR, tasa de rebote de la página (sesiones rebotadas / sesiones totales de VV). Fuera de sesión se refiere a una sesión que genera solo un comportamiento de acceso. Por lo tanto, el indicador BR puede medir la excelencia del sitio web. Cuanto mayor sea el índice, menor será el atractivo para los usuarios y es necesario mejorarlo.
- NewCust, el número de nuevos usuarios. Si un usuario de hoy nunca ha aparecido en los datos históricos, este usuario se cuenta como un nuevo usuario. Cuente el número de uvid hoy que no ha aparecido en los datos históricos.
- NewIp, agregue el número de IP. Cuente el número de ips que no han aparecido hoy en los datos históricos.
- AvgDepp, profundidad media de la sesión. AvgDeep = Profundidad total de acceso a la sesión / número total de sesiones (VV). Entre ellos, la profundidad total de acceso a la sesión = la suma de la profundidad de acceso de cada sesión y la profundidad de acceso de cada sesión = cuántas direcciones URL diferentes se accede.
- AvgTime, el tiempo medio de acceso a la sesión. AvgTime = Duración total del acceso a la sesión / número total de sesiones (VV). Entre ellos, la duración total de la sesión = la suma de la duración de cada sesión.
Podemos contar la marca de tiempo cuando se abre la página y calcular el tiempo total de acceso de cada sesión. Pero en un entorno de producción, el valor teórico calculado es menor que el valor real porque no se puede obtener el tiempo de permanencia de la última página.
Cuente la duración total de cada sesión, a saber: Max TimeStamp-Min TimeStamp.
Punto de enterramiento y recolección de datos

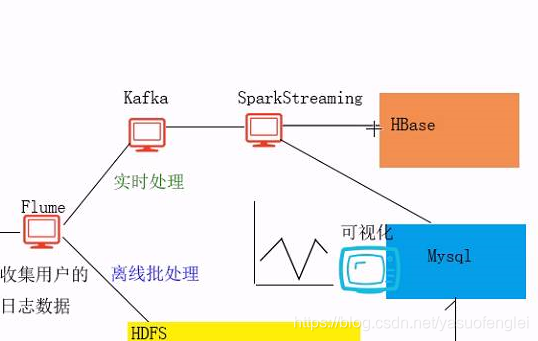
Estructura del proyecto
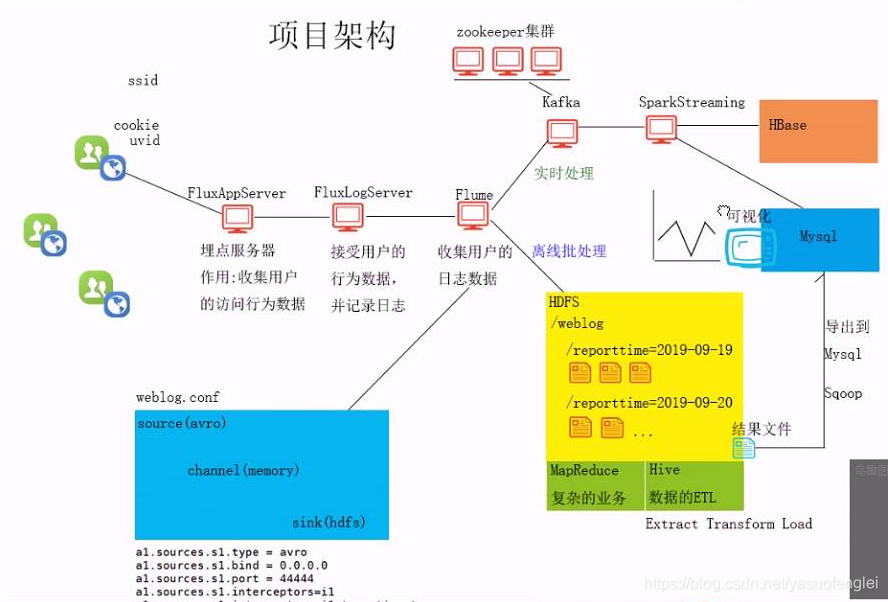
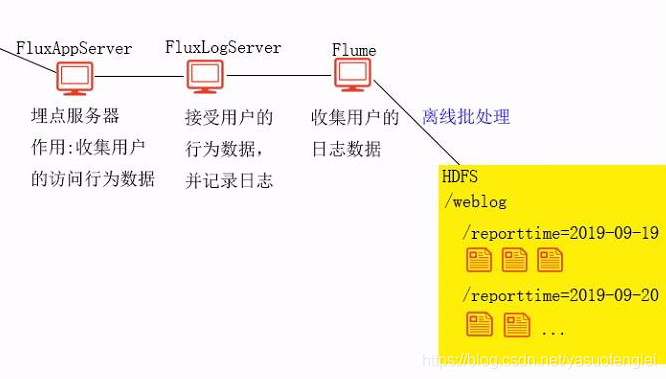
El procesamiento por lotes sin conexión puede usar: MapReduce,
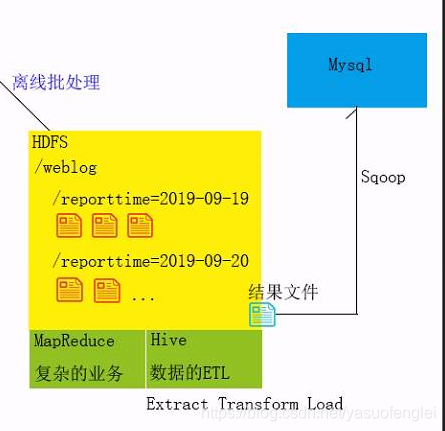
archivos de resultados ETL (Extraer transformación de carga) de datos de Hive se exportan a la base de datos. Realice visualización de datos. El front-end extrae datos de la base de datos.

configuración de canal
a1.sources = s1
a1.channels = c1
a1.sinks = k1
a1.sources.s1.type = avro
a1.sources.s1.bind = 0.0.0.0
a1.sources.s1.port = 44444
a1.sources.s1.interceptors=i1
a1.sources.s1.interceptors.i1.type=timestamp
a1.channels.c1.type = memory
#配置flume的通道容量,表示最多1000个Events事件。在生产环境 ,建议在5万-10万
a1.channels.c1.capacity = 1000
#批处理大小,生产环境建议在1000以上。(capacity和transactionCapacity )这两个参数决定了Flume的吞吐能力
a1.channels.c1.transactionCapacity = 100
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path=hdfs://hadoop01:9000/weblog/reporttime=%Y-%m-%d
//按时间周期滚动生成一人和。生产环境,建议在1小时及以上。避免生成大量小文件。
a1.sinks.k1.hdfs.rollInterval=30
#按文件大小滚动生成新文件。默认是1kb。如果是0,表示不按此条件滚动
a1.sinks.k1.hdfs.rollSize=0
#按文件中行数滚动。默认是10行
a1.sinks.k1.hdfs.rollCount=0
#Flume在HDFS生成文件时的格式,1默认格式是二进制格式。2DataStream
a1.sinks.k1.hdfs.fileType=DataStream
a1.sources.s1.channels = c1
a1.sinks.k1.channel =c1
启动 flume
… / bin / flume-ng agent -n a1 -c… / conf / -f weblog.conf -Dflume.root.logger = INFO, consola
Hive para el procesamiento de datos sin conexión
- Cree una tabla de totales (tabla externa + tabla de partición). Cargue y administre todos los datos de campo, como url, nombre de url, color ... etc.
- Agregar información de partición a la tabla de totales
- Establezca una mesa de limpieza (mesa interna) para limpiar los campos comerciales útiles.
- Inserte los datos de campo limpios de la tabla general en la tabla limpia.
- Establecer una tabla de negocios para almacenar varios indicadores después de las estadísticas, el pv, uv, vv de este proyecto ...
- Declaración de construcción de tabla total:
crear flujo de tabla externo (cadena de url, cadena de nombre de url, cadena de título, cadena de chset, cadena de scr, cadena de columna, cadena de LG, cadena de je, cadena de ec, cadena de fv, cadena de cn, cadena de referencia, cadena de uagent, cadena de stat_uv, cadena de stat_ss, cip string) PARTITIONED BY (reportTime string) campos delimitados por formato de fila terminados por '|' ubicación '/ weblog';
- Mesa de limpieza de datos
crear tabla dataclear (reporttime string, url string, urlname string, uvid string, ssid string, sscount string, sstime string, cip string) campos delimitados por formato de fila terminados por '|';
Insertar datos de limpieza
insertar datos de tabla de sobrescritura
seleccionar reporttime, url, urlname, stat_uv, split (stat_ss, " ") [0], split (stat_ss, " ") [1], split (stat_ss, "_") [2], cip de flux ;
- Crear mesa de negocios
crear tabla tongji (cadena reportTime, pv int, uv int, vv int, br double, newip int, newcust int, avgtime double, avgdeep double) campos delimitados por formato de fila terminados por '|';
- La declaración de datos de inserción de tabla estadística final:
inserte la tabla de sobrescritura tongji seleccione '2019-09-19', tab1.pv, tab2.uv, tab3.vv, tab4.br, tab5.newip, tab6.newcust, tab7.avgtime, tab8.avgdeep from (seleccione count ( ) como pv de dataclear donde reportTime = '2019-09-19') como tab1, (seleccione count (distinto uvid) como uv de dataclear donde reportTime = '2019-09-19') como tab2, (seleccione count (distinto ssid) como vv de dataclear donde reportTime = '2019-09-19') como tab3, (seleccione round (br_taba.a / br_tabb.b, 4) como br de (seleccione count () como de (seleccione ssid de dataclear donde reportTime = '2019-09-19' grupo por ssid con count (ssid) = 1) como br_tab) como br_taba, (seleccione count (ssid distinto) como b de dataclear donde reportTime = '2019-09-19') como br_tabb) como tab4, (seleccione count (distinto dataclear.cip) como newip de dataclear donde dataclear.reportTime = '2019-09-19' y cip no en (seleccione dc2.cip de dataclear como dc2 donde dc2.reportTime <'2019-09-19')) como tab5, (seleccione count (distinto dataclear.uvid) como newcust de dataclear donde dataclear.reportTime = '2019-09-19' y uvid no en (seleccione dc2.uvid de dataclear como dc2 donde dc2.reportTime <'2019-09-19')) como tab6, (seleccione round (avg (atTab.usetime), 4) como avgtime de (seleccione max (sstime) - min (sstime ) como tiempo de uso de dataclear donde reportTime = '2019-09-19' group by ssid) as atTab) as tab7, (seleccione round (avg (deep),4) como avgdeep from (seleccione count (nombre de URL distinto) como deep from dataclear donde reportTime = '2019-09-19' group by ssid) as adTab) as tab8;