1. Estructura de datos
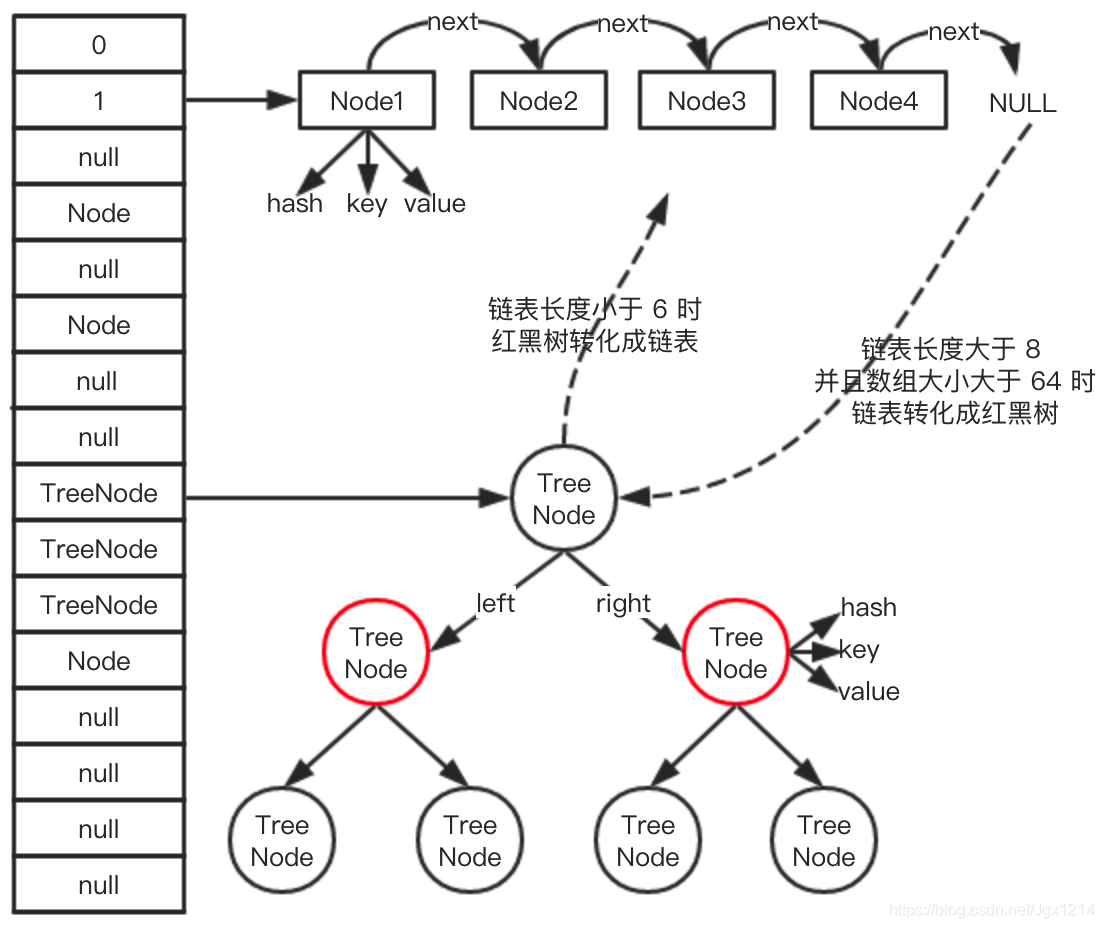
Como se muestra en la figura anterior, la estructura de datos subyacente de HashMap es principalmente matriz + lista enlazada + árbol rojo-negro. Cuando la longitud de la lista vinculada es mayor o igual a 8, la lista vinculada se convertirá en un árbol rojo-negro, y cuando el tamaño del árbol rojo-negro sea menor o igual a 6, el árbol rojo-negro se convertirá en una lista vinculada. En el lado izquierdo de la figura se encuentra la estructura de matriz de HashMap. Los elementos de la matriz pueden ser un solo Nodo, una lista vinculada o un árbol rojo-negro. Por ejemplo, la posición del índice de matriz 2 es una lista vinculada y la posición del índice 9 corresponde a Los que son árboles rojos y negros.
Código fuente
public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable {
//初始容量为16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
//最大容量
static final int MAXIMUM_CAPACITY = 1 << 30;
//负载因子默认值
static final float DEFAULT_LOAD_FACTOR = 0.75f;
//桶上的链表长度大于等于8时,链表转化成红黑树
static final int TREEIFY_THRESHOLD = 8;
//桶上的红黑树大小小于等于6时,红黑树转化成链表
static final int UNTREEIFY_THRESHOLD = 6;
//当数组容量大于64时,链表才会转化成红黑树
static final int MIN_TREEIFY_CAPACITY = 64;
//记录迭代过程中HashMap结构是否发生变化,如果有变化,迭代时会fail-fast
transient int modCount;
//HashMap的实际大小,可能不准(因为当拿到这个值的时候,可能该值又发生了变化)
transient int size;
//存放数据的数组
transient Node<K,V>[] table;
/**
* 扩容的门槛,有两种情况
* 如果初始化时,给定数组大小的话,通过tableSizeFor方法计算,数组大小永远接近于2的幂次方,例如给定初始化大小19,实际上初始化大小为32,为2的5次方
* 如果是通过resize方法进行扩容,大小 = 数组容量 * 0.75
*/
int threshold;
//链表的节点
static class Node<K,V> implements Map.Entry<K,V> {
//红黑树的节点
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
......}
}
Análisis de código fuente
- HashMap permite valores nulos, a diferencia de HashTable, que no es seguro para subprocesos.
- El valor predeterminado del factor de carga (factor de carga) es 0,75, que es el valor calculado al equilibrar la pérdida de tiempo y espacio. Un valor más alto reducirá la sobrecarga de espacio (la expansión se reduce, el tamaño de la matriz crece más lento), pero aumenta el costo de búsqueda (hash El conflicto aumenta, la longitud de la lista enlazada se hace más larga) y la condición para que no haya expansión es que la capacidad de la matriz> el tamaño / factor de carga de la matriz requerido.
- Si el HashMap necesita almacenar una gran cantidad de datos, se recomienda que la capacidad inicial del HashMap sea lo suficientemente grande al principio para evitar el impacto en el rendimiento causado por la expansión.
- HashMap no es seguro para subprocesos. Se puede bloquear externamente o mediante el método synchronizedMap de Collections para lograr la seguridad de subprocesos. La implementación de synchronizedMap agrega un bloqueo sincronizado a cada método.
- En el proceso iterativo, si se modifica la estructura de HashMap, fallará rápidamente.
2. Recién
agregado A continuación se muestra el código fuente de la clave y el valor recién agregados.
Código fuente
public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable {
//入参hash为通过hash算法计算出来的值
//入参onlyIfAbsent为boolean类型,默认为false,表示即使key已经存在了,仍然会用新值覆盖原来的值,
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) {
//n表示数组的长度,i为数组索引下标,p为i位置的节点
Node<K,V> [] tab; Node<K,V> p;
int n, i;
//如果数组为空,使用resize方法初始化
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//如果当前索引位置为空,直接在当前索引位置上生成新的节点
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
//如果当前索引位置有值,即常说的hash冲突
else {
//e为当前节点的临时变量
Node<K,V> e;
K k;
//如果key的hash和值都相等,直接把当前下标位置的Node值赋值给临时变量
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
//如果是红黑树,使用红黑树的方式新增
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
//如果是链表,把新节点放到链表的尾端
else {
//自旋
for (int binCount = 0; ; ++binCount) {
//e = p.next表示从头开始,遍历链表
//p.next == null表明p是链表的尾节点
if ((e = p.next) == null) {
//把新节点放到链表的尾部
p.next = newNode(hash, key, value, null);
//当链表的长度大于等于8时,链表转红黑树
if (binCount >= TREEIFY_THRESHOLD - 1)
treeifyBin(tab, hash);
break;
}
//链表遍历过程中,发现有元素和新增的元素相等,结束循环
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
//更改循环的当前元素,使p在遍历过程中一直往后移动
p = e;
}
}
//e != null说明新节点的新增位置已经找到
if (e != null) {
V oldValue = e.value;
//当onlyIfAbsent为false时,才会覆盖原值
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
//返回老值
return oldValue;
}
}
++modCount;
//如果HashMap的实际大小大于扩容的门槛,开始扩容
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
}
Análisis de código fuente
- Primero juzgue si la matriz vacía está inicializada, si no, inicialícela.
- Si el valor se puede encontrar directamente a través del hash de la clave, salte a 6; de lo contrario, salte a 3.
- Si el hash entra en conflicto, hay dos soluciones, lista vinculada o árbol rojo-negro.
- Si se trata de una lista vinculada, repita de forma recursiva y agregue nuevos elementos al final de la cola.
- Si es un árbol rojo-negro, llame al nuevo método del árbol rojo-negro.
- Después de agregar con éxito el nuevo elemento a través de 2, 4 y 5, juzgue si es necesario sobrescribirlo de acuerdo con onlyIfAbsent.
- Determine si necesita ampliar la capacidad, si necesita ampliar la capacidad, ampliar la capacidad o finalizar el nuevo proceso de adición.
3. Nueva adición de la lista
vinculada La adición de la lista vinculada es relativamente simple, agregar el nodo actual al final de la lista vinculada es lo mismo que la implementación de la adición de LinkedList. Cuando la longitud de la lista vinculada es mayor o igual a 8, la lista vinculada en este momento se convertirá en un árbol rojo-negro. El método de conversión es treeifyBin. Este método tiene un juicio. Cuando la longitud de la lista vinculada es mayor o igual a 8, y el tamaño de toda la matriz es mayor que 64, se convertirá. Se convierte en un árbol rojo-negro. Cuando el tamaño de la matriz es inferior a 6, solo activará la expansión y no se convertirá en un árbol rojo-negro.
Durante la entrevista, suelo preguntar por qué es 8, porque la complejidad de tiempo de la consulta de la lista enlazada es O (n), y la complejidad de la consulta del árbol rojo-negro es O (log (n)). Cuando no hay muchos datos en la lista enlazada, es más rápido usar la lista enlazada para recorrer. Solo cuando haya más datos en la lista enlazada se transformará en un árbol rojo-negro. Sin embargo, el árbol rojo-negro ocupa el doble del espacio de la lista enlazada, considerando el tiempo de conversión y la pérdida de espacio, es necesario definir el valor límite de la conversión. Al diseñar este valor límite, consulte la función de probabilidad de distribución de Poisson, y la probabilidad de acierto de cada longitud de la lista vinculada se muestra a continuación.
* 0: 0.60653066
* 1: 0.30326533
* 2: 0.07581633
* 3: 0.01263606
* 4: 0.00157952
* 5: 0.00015795
* 6: 0.00001316
* 7: 0.00000094
* 8: 0.00000006
Cuando la longitud de la lista vinculada es 8, la probabilidad de ocurrencia es 0.00000006, que es menos de uno en diez millones. Por lo tanto, en circunstancias normales, la longitud de la lista vinculada no puede llegar a 8, y una vez que llega a 8, debe haber un problema con el algoritmo hash. , Entonces, en este caso, para que HashMap aún tenga un mayor rendimiento de consulta, deje que la lista vinculada en un árbol rojo-negro. Cuando utilice HashMap, casi nunca encontrará una situación en la que la lista enlazada se transforme en un árbol rojo-negro. Después de todo, la probabilidad es sólo uno en diez millones.
4. Nuevo
árbol rojo-negro A continuación se muestra el código fuente del proceso de nuevo nodo del árbol rojo-negro.
Código fuente
public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable {
//入参h为key的hash值
final TreeNode<K,V> putTreeVal(HashMap<K,V> map, Node<K,V>[] tab,int h, K k, V v) {
Class<?> kc = null;
boolean searched = false;
//找到根节点
TreeNode<K,V> root = (parent != null) ? root() : this;
//自旋
for (TreeNode<K,V> p = root;;) {
int dir, ph; K pk;
//p的hash值大于h,说明p在h的右边
if ((ph = p.hash) > h)
dir = -1;
//p的hash值小于 h,说明p在h的左边
else if (ph < h)
dir = 1;
//判断要放进去的key在当前树中是否已存在(通过equals来判断)
else if ((pk = p.key) == k || (k != null && k.equals(pk)))
return p;
//自定义的Comparable不能用hashcode比较,需要用compareTo
else if ((kc == null &&
//得到key的Class类型,如果key没有实现Comparable就是null
(kc = comparableClassFor(k)) == null) ||
//当前节点pk和入参k不等
(dir = compareComparables(kc, k, pk)) == 0) {
if (!searched) {
TreeNode<K,V> q, ch;
searched = true;
if (((ch = p.left) != null &&
(q = ch.find(h, k, kc)) != null) ||
((ch = p.right) != null &&
(q = ch.find(h, k, kc)) != null))
return q;
}
dir = tieBreakOrder(k, pk);
}
TreeNode<K,V> xp = p;
//找到和当前hashcode值相近的节点(当前节点的左右子节点其中一个为空即可)
if ((p = (dir <= 0) ? p.left : p.right) == null) {
Node<K,V> xpn = xp.next;
//生成新的节点
TreeNode<K,V> x = map.newTreeNode(h, k, v, xpn);
//把新节点放在当前子节点为空的位置上
if (dir <= 0)
xp.left = x;
else
xp.right = x;
//当前节点和新节点建立父子、前后关系
xp.next = x;
x.parent = x.prev = xp;
if (xpn != null)
((TreeNode<K,V>)xpn).prev = x;
/**
* balanceInsertion对红黑树进行着色或旋转,以达到更高的查找效率,着色或旋转的几种场景如下
* 着色:新节点总是为红色。如果新节点的父亲是黑色,则不需要重新着色,如果父亲是红色,那么必须通过重新着色或者旋转的方法,再次达到红黑树的5个约束条件
* 旋转:父亲是红色,叔叔是黑色时,进行旋转
* 如果当前节点是父亲的右节点,则进行左旋
* 如果当前节点是父亲的左节点,则进行右旋
*/
//moveRootToFront方法是把算出来的root放到根节点上
moveRootToFront(tab, balanceInsertion(root, x));
return null;
}
}
}
}
Análisis de código fuente
- En primer lugar, juzgue si el nuevo nodo ya existe en el árbol rojo-negro. Hay dos formas de juzgar. Si el nodo no implementa la interfaz Comparable, use iguales para juzgar. Si el nodo implementa la interfaz Comparable, use compareTo para juzgar.
- Si el nodo recién agregado ya está en el árbol rojo-negro, regrese directamente. Si no lo está, juzgue si el nodo recién agregado está a la izquierda oa la derecha del nodo actual, el valor de la izquierda es pequeño y el valor de la derecha es grande.
- Gire los pasos recursivos 1 y 2, hasta que el nodo izquierdo o derecho del nodo actual esté vacío, deje de girar y el nodo actual sea el nodo padre del nuevo nodo.
- Coloque el nuevo nodo en la posición vacía a la izquierda o derecha del nodo actual y establezca la relación de nodo padre-hijo para el nodo actual.
- Realice la coloración y rotación, y el proceso finaliza.
5. La búsqueda de
HashMap se divide principalmente en dos pasos. El primer paso es ubicar la posición del índice de la matriz de acuerdo con el algoritmo hash. Equals determina si el nodo actual es la clave a buscar. Si es así, regrese directamente; de lo contrario, continúe con el segundo paso. El segundo paso es determinar si el nodo actual tiene un nodo siguiente y, de ser así, si es un tipo de lista vinculada o un tipo de árbol rojo-negro. Siga los diferentes tipos de métodos de búsqueda de lista enlazada y árbol rojo-negro respectivamente. El código fuente clave de la búsqueda de lista enlazada es el siguiente.
//采用自旋方式从链表中查找key
do {
//如果当前节点hash等于key的hash,并且equals相等,当前节点即是要找的节点
//当hash冲突时,通过equals方法来比较key是否相等
if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k))))
return e;
//否则,把当前节点的下一个节点拿出来继续寻找
} while ((e = e.next) != null);