Directorio de artículos
Introducción
Las cadenas son el tipo de Java más utilizado en nuestro proceso de codificación diario. Los idiomas en varias regiones del mundo son diferentes, incluso si se usa Unicode, se adoptarán diferentes métodos de codificación, como UTF-8, UTF-16, UTF-32, etc., debido a los diferentes formatos de codificación.
¿Qué problemas encontraremos en el proceso de usar la codificación de caracteres y cadenas? Vamos a ver.
Utilice caracteres incompletos codificados de longitud variable para crear cadenas
El carácter de almacenamiento subyacente [] de String en Java está codificado en UTF-16.
Tenga en cuenta que después de JDK9, el almacenamiento subyacente de String se ha convertido en byte [].
StringBuilder y StringBuffer todavía usan char [].
Por lo tanto, cuando usamos las clases InputStreamReader, OutputStreamWriter y String para la lectura, escritura y construcción de cadenas, necesitamos involucrar la conversión de UTF-16 y otras codificaciones.
Echemos un vistazo a los problemas que pueden surgir al convertir de UTF-8 a UTF-16.
Primero mire la codificación UTF-8:
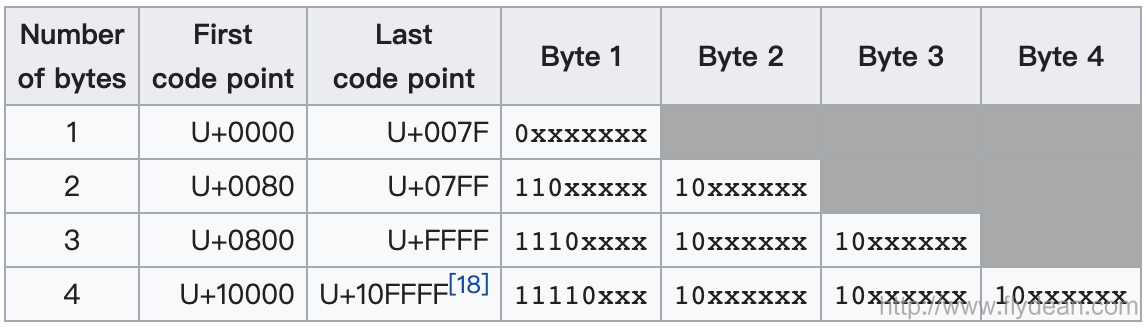
UTF-8 usa de 1 a 4 bytes para representar el carácter correspondiente, mientras que UTF-16 usa 2 o 4 bytes para representar el carácter correspondiente.
¿Qué problemas pueden surgir en la conversión?
public String readByteWrong(InputStream inputStream) throws IOException {
byte[] data = new byte[1024];
int offset = 0;
int bytesRead = 0;
String str="";
while ((bytesRead = inputStream.read(data, offset, data.length - offset)) != -1) {
str += new String(data, offset, bytesRead, "UTF-8");
offset += bytesRead;
if (offset >= data.length) {
throw new IOException("Too much input");
}
}
return str;
}
En el código anterior, leemos un byte de Stream y lo convertimos en String cada vez que leemos un byte. Obviamente, UTF-8 es una codificación de longitud variable.Si se lee parte del código UTF-8 durante el proceso de lectura de bytes, la cadena construida será incorrecta.
Necesitamos hacer lo siguiente:
public String readByteCorrect(InputStream inputStream) throws IOException {
Reader r = new InputStreamReader(inputStream, "UTF-8");
char[] data = new char[1024];
int offset = 0;
int charRead = 0;
String str="";
while ((charRead = r.read(data, offset, data.length - offset)) != -1) {
str += new String(data, offset, charRead);
offset += charRead;
if (offset >= data.length) {
throw new IOException("Too much input");
}
}
return str;
}
Usamos InputStreamReader, el lector convertirá automáticamente los datos leídos en char, lo que significa que se convertirá automáticamente de UTF-8 a UTF-16.
Entonces no habrá problemas.
char no puede representar todo Unicode
Como char se codifica con UTF-16, para UTF-16, U + 0000 a U + D7FF y U + E000 a U + FFFF, los caracteres de este rango se pueden representar directamente mediante un char.
Pero para U + 010000 a U + 10FFFF, usa dos caracteres en el rango de 0xD800-0xDBFF y 0xDC00-0xDFFF.
En este caso, la combinación de dos caracteres es interesante y un solo carácter no tiene significado.
Considere el siguiente de nuestros métodos subString. La intención original de este método es encontrar la posición de la primera no letra de la cadena de entrada y luego interceptar la cadena.
public static String subStringWrong(String string) {
char ch;
int i;
for (i = 0; i < string.length(); i += 1) {
ch = string.charAt(i);
if (!Character.isLetter(ch)) {
break;
}
}
return string.substring(i);
}
En el ejemplo anterior, sacamos los caracteres char de la cadena uno por uno para compararlos. Si encuentra un carácter en el rango de U + 010000 a U + 10FFFF, puede obtener un error al pensar erróneamente que el carácter no es una letra.
Podemos modificarlo así:
public static String subStringCorrect(String string) {
int ch;
int i;
for (i = 0; i < string.length(); i += Character.charCount(ch)) {
ch = string.codePointAt(i);
if (!Character.isLetter(ch)) {
break;
}
}
return string.substring(i);
}
Usamos el método codePointAt de cadena para devolver el punto de código Unicode de la cadena, y luego usamos el punto de código para determinar isLetter.
Preste atención al uso de Locale
Para lograr el soporte de internacionalización, java introdujo el concepto de Locale y, debido a Locale, provocará cambios inesperados en el proceso de conversión de cadenas.
Considere el siguiente ejemplo:
public void toUpperCaseWrong(String input){
if(input.toUpperCase().equals("JOKER")){
System.out.println("match!");
}
}
Lo que esperamos es inglés. Si el sistema establece Locale en otros idiomas, input.toUpperCase () puede obtener resultados completamente diferentes.
Afortunadamente, toUpperCase proporciona un parámetro de configuración regional, podemos modificarlo así:
public void toUpperCaseRight(String input){
if(input.toUpperCase(Locale.ENGLISH).equals("JOKER")){
System.out.println("match!");
}
}
Del mismo modo, DateFormat también tiene problemas:
public void getDateInstanceWrong(Date date){
String myString = DateFormat.getDateInstance().format(date);
}
public void getDateInstanceRight(Date date){
String myString = DateFormat.getDateInstance(DateFormat.MEDIUM, Locale.US).format(date);
}
Cuando comparamos cadenas, debemos considerar la influencia de la configuración regional.
Formato de codificación en lectura y escritura de archivos
Cuando usamos InputStream y OutputStream para escribir archivos, debido a que es binario, no hay problema de conversión de codificación.
Pero si usamos Reader y Writer para apuntar a archivos, debemos considerar la cuestión de la codificación de archivos.
Si el archivo está codificado en UTF-8 y usamos UTF-16 para leerlo, definitivamente habrá problemas.
Considere el siguiente ejemplo:
public void fileOperationWrong(String inputFile,String outputFile) throws IOException {
BufferedReader reader = new BufferedReader(new FileReader(inputFile));
PrintWriter writer = new PrintWriter(new FileWriter(outputFile));
int line = 0;
while (reader.ready()) {
line++;
writer.println(line + ": " + reader.readLine());
}
reader.close();
writer.close();
}
Queremos leer el archivo fuente e insertar el número de línea en el nuevo archivo, pero no consideramos el problema de codificación, por lo que puede fallar.
Podemos modificar el código anterior de la siguiente manera:
BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream(inputFile), Charset.forName("UTF8")));
PrintWriter writer = new PrintWriter(new OutputStreamWriter(new FileOutputStream(outputFile), Charset.forName("UTF8")));
Al forzar la especificación del formato de codificación, se garantiza la corrección de la operación.
No codifique datos que no sean caracteres como una cadena
A menudo tenemos el requisito de codificar datos binarios en una cadena y luego almacenarlos en la base de datos.
El binario está representado por Byte, pero a partir de nuestra introducción anterior, podemos saber que no todos los Bytes se pueden representar como caracteres. Si el Byte que no se puede expresar como carácter se convierte en caracteres, pueden surgir problemas.
Mira el siguiente ejemplo:
public void convertBigIntegerWrong(){
BigInteger x = new BigInteger("1234567891011");
System.out.println(x);
byte[] byteArray = x.toByteArray();
String s = new String(byteArray);
byteArray = s.getBytes();
x = new BigInteger(byteArray);
System.out.println(x);
}
En el ejemplo anterior, convertimos BigInteger en número de bytes (secuencia big-endian) y luego convertimos el número de bytes en String. Finalmente, la cadena se convierte a BigInteger.
Primero mira los resultados:
1234567891011
80908592843917379
Encontró que ninguna conversión fue exitosa.
Aunque String puede recibir el segundo parámetro e ingresar la codificación de caracteres, las codificaciones de caracteres admitidas actualmente en Java son: ASCII, ISO-8859-1, UTF-8, UTF-8BE, UTF-8LE, UTF-16, estos. String también es big-endian por defecto.
¿Cómo modificar el ejemplo anterior?
public void convertBigIntegerRight(){
BigInteger x = new BigInteger("1234567891011");
String s = x.toString(); //转换成为可以存储的字符串
byte[] byteArray = s.getBytes();
String ns = new String(byteArray);
x = new BigInteger(ns);
System.out.println(x);
}
Primero podemos convertir BigInteger en una cadena representable usando el método toString, y luego convertirlo.
También podemos usar Base64 para codificar la matriz de bytes sin perder ningún carácter, como se muestra a continuación:
public void convertBigIntegerWithBase64(){
BigInteger x = new BigInteger("1234567891011");
byte[] byteArray = x.toByteArray();
String s = Base64.getEncoder().encodeToString(byteArray);
byteArray = Base64.getDecoder().decode(s);
x = new BigInteger(byteArray);
System.out.println(x);
}
El código de este artículo:
aprender-java-base-9-to-20 / tree / master / security
Este artículo se ha incluido en http://www.flydean.com/java-security-code-line-string/
¡La interpretación más popular, los productos secos más profundos, el tutorial más conciso y muchos consejos que no sabes te esperan para descubrir!
Bienvenido a prestar atención a mi cuenta oficial: "programa esas cosas", conoce tecnología, ¡conocerte mejor!