Resumen: Este artículo presenta dos ideas para la segmentación de bases de datos. El entendimiento popular es: "división vertical" es equivalente a "columna" cambiando a "fila" sin cambios, y "división horizontal" es equivalente a "fila" cambiando a "columna" sin cambios.
Lo más importante para la "escalabilidad" en un sistema distribuido es ser "sin estado" primero, para que pueda "escalar" horizontalmente como desee, sin preocuparse por la confusión al cambiar entre varias copias. La " Explicación detallada de preocupaciones del sistema distribuido de " sin estado " " habla de esto.
Sin embargo, incluso si se realiza la expansión horizontal, sigue siendo un "gran programa" en esencia, pero se vuelve "copiable".
Si se quiere eliminar "programas grandes", hay que "segmentar", y la idea central de "alta cohesión y bajo acoplamiento" es indispensable para hacer un buen trabajo de segmentación. Este es el tema de " Preocupaciones del sistema distribuido: explicación detallada de " alta cohesión y bajo acoplamiento " ".
Digresión: cuando se encuentra con una aplicación de un solo pedido que no se puede utilizar, el consejo universal dado por Brother Z es: primero considere "expansión" y luego "corte". Esto es lo mismo que escribir código, a menudo es más fácil "agregar" funciones nuevas que cambiar funciones antiguas.
Para la "expansión", primero considere la "expansión vertical" (agregar hardware, el dinero puede resolverlo no es un problema) y luego considere la "expansión horizontal" (transformación sin estado + implementación de múltiples nodos, esta es una operación menor).
"Rebanar" es generalmente "corte vertical" (de acuerdo con la segmentación comercial, esta es una operación importante), y ocasionalmente "corte horizontal" (de hecho, es la estratificación en una sola aplicación, como la separación frontal).
En la tercera parte de " Arquitectura Resiliente del Foco del Sistema Distribuido ", hablamos de dos modos de arquitectura comunes "débilmente acoplados", para llevar la "escalabilidad" de las aplicaciones a un nivel superior.
Todas estas son tareas a nivel de aplicación. En circunstancias normales, realizar una cirugía a nivel de aplicación, junto con el uso completo de la caché, puede ayudar al desarrollo del sistema durante mucho tiempo. En particular, la cantidad de datos no es grande, pero el escenario "CPU intensivo" con una gran cantidad de solicitudes.
Sin embargo, si el escenario de trabajo en el que te encuentras es un proyecto muy maduro con cierta escala, cuanto más lo desarrollas, siempre aparece el cuello de botella en la base de datos. Incluso habrá fenómenos como alta carga a largo plazo y tiempo de inactividad de la CPU.
En tal escenario, se debe operar la base de datos. En esta ocasión, el hermano Z vendrá a hablar con usted sobre las buenas formas de hacer que la base de datos sea "escalable".
Atractivo central
Cuando se enfrenta a una base de datos que requiere cirugía, todo el sistema a menudo ha crecido de esta manera.

Como se mencionó anteriormente, el cuello de botella en este momento a menudo se refleja en la "CPU".
Porque para la base de datos, la expansión del disco duro y la memoria es relativamente fácil, ya que se pueden usar directamente para "aumentar".
La CPU es diferente. Una vez que la CPU alcanza un pico alto, como máximo, verifique si el índice está bien hecho. Después de eso, básicamente puede simplemente mirar.
Entonces, la idea para resolver este problema naturalmente se convierte en: cómo distribuir la presión de la CPU de una base de datos a varias CPU. Incluso se puede aumentar en cualquier momento bajo demanda.
Entonces, ¿no es esto simplemente hacer "segmentación" como una aplicación? También es la encarnación de la idea de "divide y vencerás" de los sistemas distribuidos.
Dado que es una segmentación, es esencialmente lo mismo que la aplicación y también se divide en "segmentación vertical" y "segmentación horizontal".
División vertical
La segmentación vertical a veces se denomina "segmentación longitudinal".
Al igual que la aplicación, es un método de segmentación con el "negocio" como dimensión, ejecutando diferentes bases de datos comerciales en diferentes servidores de bases de datos, cada uno realizando sus propias funciones.
En general, el hermano Z sugiere que le dé prioridad a la "segmentación vertical" en lugar de la "segmentación horizontal" . Puede abrir la declaración SQL en el proyecto en cuestión a voluntad. Creo que debe haber una gran cantidad de palabras clave de "unión" y "transacción". Este tipo de operación de consulta y transacción relacionada es esencialmente una especie de "enlace relacional". Después de enfrentar la división de la base de datos, no puedes jugar .
En este punto, solo tiene 2 opciones.
- Descarte la lógica de "relación ***" innecesaria, que requiere ajustes comerciales para eliminar los servicios de "operación por lotes" innecesarios, o elimine las transacciones de coherencia fuerte innecesarias. Pero también sabes que debe haber algunas escenas que son infinitas.
- O "fusionar" y "asociar" y otras lógicas flotan y se reflejan en el código de la capa de lógica empresarial o incluso en la capa de aplicación.
Al final, no importa cómo elija, el cambio es un gran proyecto.
Para hacer este proyecto lo más pequeño posible y lograr un mejor rendimiento de costos, es necesario adherirse a un principio: " Evite dividir tablas estrechamente relacionadas ".
Debido a que cuanto más estrecha es la relación entre las dos tablas, mayor es la demanda de "unión" y "transacción", por lo que seguir este principio puede hacer que los mismos módulos y las empresas estrechamente relacionadas caigan en la misma biblioteca, por lo que pueden Continúe usando "unirse" y "transacción" para trabajar.
Por tanto, deberíamos dar prioridad al enfoque de "segmentación vertical".
La idea de la "segmentación vertical" es muy sencilla, en circunstancias normales, se recomienda corresponder a la aplicación segmentada uno a uno, sin más ni menos .

En el trabajo real, la "segmentación vertical" se refleja principalmente en la familiaridad de "negocios", por lo que no continuaré aquí.
Las ventajas de la "segmentación vertical" son:
1. Alta cohesión, reglas claras de división. En comparación con la "segmentación horizontal", la redundancia de datos es menor.
2. Tiene una relación 1: 1 con la aplicación, lo que es conveniente para mantener y localizar problemas. Una vez que se encuentran datos anormales en una determinada base de datos, es suficiente verificar los programas asociados de esta base de datos.
Pero esta no es una solución única, porque nadie puede predecir cómo se desarrollará la empresa en el futuro, por lo que la desventaja más obvia es que todavía existe un cuello de botella en el rendimiento para las tablas a las que se accede con mucha frecuencia o que tienen una gran cantidad de datos .
Si realmente necesita resolver este problema, debe salir de la "segmentación horizontal".
Digresión: tratar de evitar la "segmentación horizontal" sin obligarse a uno mismo. Sabrá el motivo después de leer el siguiente contenido.
A continuación, el hermano Z le dará una buena charla sobre la "segmentación horizontal", que es el tema central de este artículo.
División horizontal
Imagínese que después de hacer la "segmentación vertical", todavía encuentra una tabla con más de mil millones de datos en una base de datos.
En este momento, tienes que "dividir horizontalmente" la mesa. ¿Cómo pensarías en esto?
La línea de pensamiento que te enseñó el hermano Z es:
- Primero busque el campo "leer" de la "frecuencia más alta" .
- Observe las características del uso real de este campo (múltiples consultas por lotes o múltiples consultas únicas, si también se trata de campos relacionados de otras tablas, etc.).
- Luego elija un esquema de segmentación adecuado basado en esta característica.
¿Por qué buscar primero el campo de "lectura" de alta frecuencia?
Porque en el uso real, las operaciones de "lectura" suelen ser mucho más grandes que las operaciones de "escritura". Generalmente, debe realizar una verificación previa "leyendo" antes de "escribir", pero la "lectura" tiene su propio escenario de uso. Por lo tanto, considerando el escenario de "lectura" de mayor frecuencia, el valor generado será inevitablemente mayor .
Por ejemplo, la tabla de mil millones de datos es una tabla de pedidos y la estructura es la siguiente:
order (orderId long, createTime datetime, userId long)Primero echemos un vistazo a los diversos métodos de "segmentación horizontal", y luego podremos entender qué tipo de escena es adecuada para qué método.
Segmentación de rango
Este es un método de segmentación "continuo".
Por ejemplo, de acuerdo con la segmentación de tiempo (createTime), podemos dividirlo por año y mes, order_201901 una biblioteca, order_201902 una biblioteca, y así sucesivamente.
De acuerdo con el número de orden (orderId), puede haber una biblioteca de 100,000 a 199999, una biblioteca de 200,000 a 299999, y así sucesivamente.
La ventaja de este método de segmentación es que el tamaño de una sola tabla es controlable y no se requiere la migración de datos al expandir .
Las desventajas también son obvias: en general, cuanto más cercano es el tiempo o mayor es el número de serie, más "nuevos" son los datos, por lo que la frecuencia y probabilidad de acceso son mayores que los datos "antiguos". Causará que la presión se concentre principalmente en la nueva biblioteca, y cuanto más largo sea el historial, más inactiva estará la biblioteca .
Segmentación de hash
Al contrario de la "segmentación de rango", este es un método de segmentación "discreto".
Su ventaja es que resuelve las deficiencias de la "segmentación de rangos". Los nuevos datos se distribuyen a cada nodo, evitando la concentración de presión en unos pocos nodos .
Del mismo modo, las desventajas son contrarias a las ventajas de la "segmentación del alcance". Una vez que se lleva a cabo la expansión secundaria, la migración de datos inevitablemente estará involucrada . Debido a que el algoritmo Hash es fijo, a medida que cambia el algoritmo, cambia la distribución de datos.
En la mayoría de los casos, nuestro algoritmo hash se puede realizar mediante una simple operación de "módulo". Se parece a esto:
Si se divide en 11 bibliotecas, la fórmula es orderId% 10.
100000% 10 = 0, asignado a db0.
100001% 10 = 1, asignado a db1.
....
100010% 10 = 0, asignado a db0.
100011% 10 = 1, asignado a db1.
De hecho, en algunos escenarios, podemos usar la generación de ID personalizada (consulte el artículo anterior, " Una medicina esencial en el sistema distribuido: generación de números de documentos únicos globales ") para lograr ambos a través de la segmentación hash Generar datos de puntos de disipación de calor puede reducir la dependencia de tablas globales para ubicar datos específicos.
Por ejemplo, agregue la mantisa de userId a orderId para lograr el efecto de un resultado de módulo igual de orderId y userId. Dejame darte un ejemplo:
El userId de un usuario es 200004. Si se toma una mantisa de 4 bits, aquí es 4, representado por 0100.
Luego, generamos los primeros 60 dígitos de orderId a través de un algoritmo de identificación personalizado y agregamos 0100 en la parte posterior.
Por lo tanto, los resultados de orderId% 10 y userId% 10 son los mismos.
Por supuesto, no es fácil agregar otros factores además de userId. Es decir, se puede admitir una dimensión adicional sin aumentar la tabla global.
La tabla global se menciona dos veces, entonces, ¿qué es una tabla global?
Tabla global
Este método es para guardar la clave de partición utilizada como base para la segmentación y la identificación de cada dato específico correspondiente a una biblioteca o tabla separada. Por ejemplo, para agregar una tabla como esta:
1 nodeId orderId
2 01 100001
3 02 100002
4 01 100003
5 01 100004...
6 ...De esta forma, es cierto que la mayoría de los datos específicos se distribuyen en diferentes servidores, pero esta tabla global le dará a la gente la sensación de que "la forma no está dispersa".
Debido a que no es posible ubicar directamente en qué servidor se encuentran los datos requeridos cuando se solicitan datos, cada operación debe consultar primero esta tabla global para saber dónde se almacenan los datos específicos.
El efecto secundario de este modelo "centralizado" es que los cuellos de botella y los riesgos se transfieren a esta tabla global. Sin embargo, la lógica es simple.
Bien, entonces, ¿cómo elegir estos esquemas de segmentación?
El consejo de Brother Z es que si los datos calientes no son una escena particularmente concentrada, se recomienda utilizar primero la "segmentación de rango"; de lo contrario, elija las otras dos .
Al elegir los otros dos, cuanto mayor sea la cantidad de datos, más inclinado a elegir la segmentación Hash . Debido a que este último es mejor que el primero en términos de usabilidad y rendimiento generales, el costo de implementación es mayor.
La "segmentación horizontal" realmente puede "expandirse infinitamente", pero existen sus correspondientes inconvenientes.
1) La consulta por lotes, la paginación, etc. necesitan hacer más trabajo adicional. Especialmente cuando hay varios campos de alta frecuencia en una tabla para dónde, ordenar por o agrupar por.
2) Las reglas de división no son tan claras como la "división vertical".
Entonces , digamos una "tontería" más: no hay un plan perfecto sino un plan adecuado, que debe seleccionarse en combinación con escenarios específicos . (Le invitamos a plantear sus dudas en el área de mensajes y discutir con el hermano Z)
Cómo implementar
Cuando implementa específicamente la "segmentación horizontal", puede moverse en dos niveles, el nivel de "superficie" o el nivel de "biblioteca".
mesa
Las tablas se dividen en la misma base de datos, los nombres de las tablas son order_0, order_1, order_2 .....
Puede resolver el problema del exceso de datos de una sola tabla, pero no puede resolver el problema de la carga de la CPU. Por tanto, cuando la CPU no tiene mucha presión, pero debido a que la tabla es demasiado grande, la ejecución de las operaciones SQL es lenta, puede elegir este método.
Biblioteca
En este momento, el nombre de la tabla puede permanecer sin cambios, todos llamados order, pero divididos en 10 bibliotecas. Entonces es db0-user db1-user db2-user .......
Hablamos de este modelo en el apartado anterior, así que no diré más.
Mesa + Biblioteca
También es posible dividir la base de datos y la tabla, por ejemplo, primero dividir 10 bibliotecas y luego dividir cada biblioteca 10 tablas.
Esta es en realidad la idea de la indexación secundaria, el primer posicionamiento se realiza a través de la biblioteca para reducir cierto consumo de recursos.
Por ejemplo, primero divida la base de datos por año y luego divida la tabla por mes. De esta manera, si los datos que deben obtenerse son solo de meses pero no de años, podemos realizar operaciones de agregación en una sola biblioteca para completarlos, sin involucrar operaciones entre bases de datos.
Sin embargo, no importa de qué manera elijas proceder, aún enfrentarás los siguientes dos problemas más o menos y no escaparás.
- Unión entre bases de datos.
- Operación global de agregación o clasificación.
La mejor manera de resolver el primer problema es cambiar su pensamiento de programación . Intente reflejar algo de lógica, relaciones, restricciones, etc. en el código de la aplicación y evite hacer estas cosas en SQL por conveniencia.
Después de todo, el código se puede escribir como "sin estado" y se puede extender en cualquier momento, pero SQL sigue a los datos, y los datos son "estado", lo que naturalmente no conduce a la expansión.
Por supuesto, la segunda mejor opción es que también puede trabajar con tablas globales redundantes. De esta manera, es una gran prueba para el trabajo de "consistencia de datos" Además, también cuesta una gran cantidad de recursos de almacenamiento.
La solución al segundo problema es convertir la agregación o clasificación original en dos operaciones . El recorrido de múltiples nodos se puede realizar de manera "paralela".
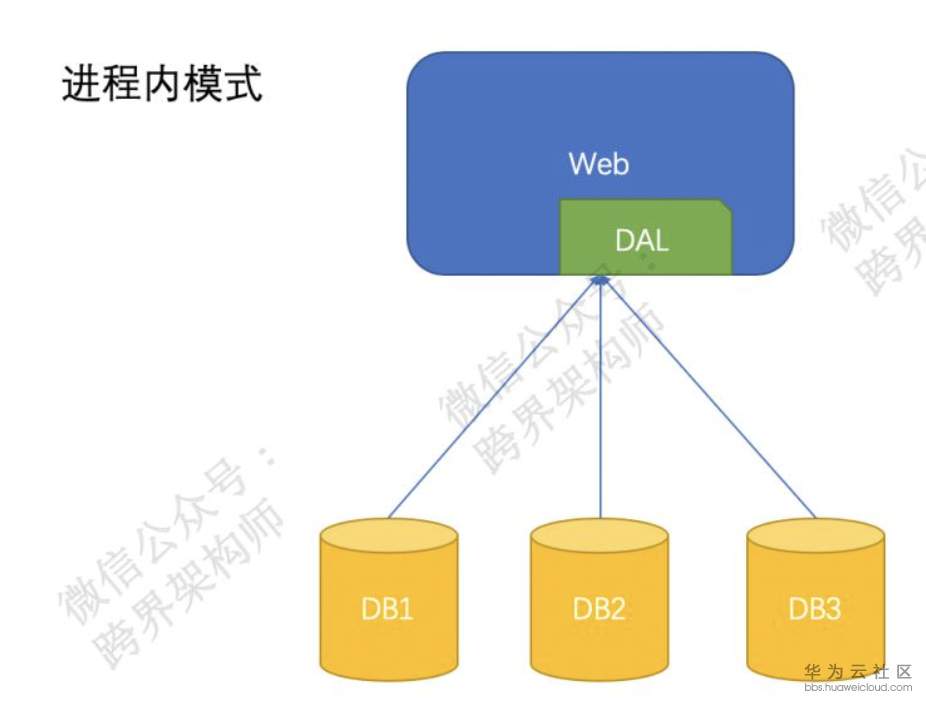
Entonces, ¿cómo lo usa el programa después de la segmentación de datos? Esto se puede dividir en dos modos, "en proceso" y "fuera de proceso".
El "proceso" se puede realizar en el marco de acceso DAL empaquetado, en el marco ORM o en el controlador de la base de datos. Soluciones conocidas de este modelo como Ali's tddl.

"Fuera de proceso" es el modelo proxy. Las soluciones más conocidas para este modelo son mycat, cobar, atlas, etc., y relativamente más, porque este modelo tiene "baja intrusión" para las aplicaciones y parece "una base de datos" ". Sin embargo, debido a la comunicación de red adicional, habrá más pérdida de rendimiento.
Viejas reglas, permítanme compartir algunas de las mejores prácticas.
Mejores prácticas
Primero, comparta dos consejos para la segmentación de datos sin detener la máquina. Echemos un vistazo a un ejemplo de implementación del método hash para la segmentación horizontal.
Al realizar la segmentación por primera vez, puede utilizar el nodo recién agregado como una copia del nodo original en forma de "maestro-esclavo" para una sincronización completa en tiempo real.

Luego elimine los datos que no le pertenecen sobre esta base. (Por supuesto, no hay nada de malo en no eliminarlo, solo ocupa más espacio)
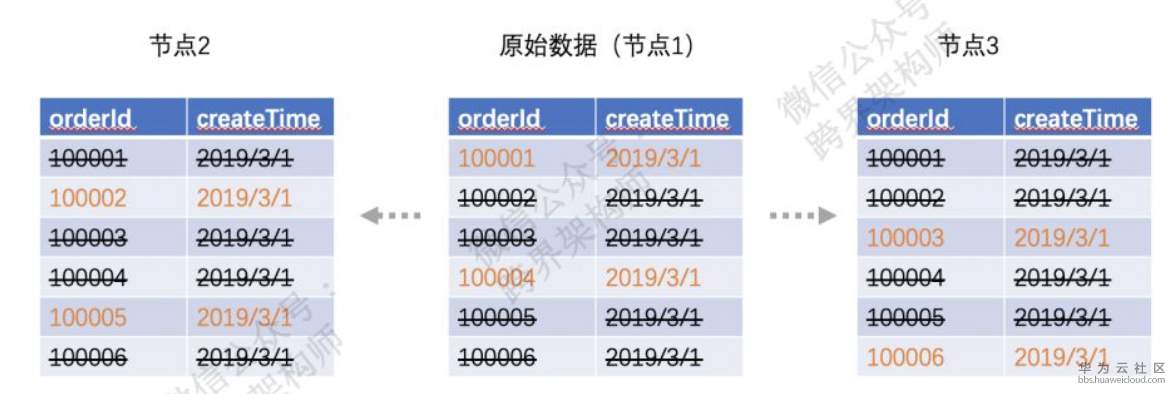
De esta forma, no hay tiempo de inactividad.
En segundo lugar, a medida que pasa el tiempo, si el seguimiento no se puede mantener y se necesita una segunda segmentación, podemos optar por utilizar un múltiplo de 2 para expandir.
De esta forma, la migración de datos se vuelve muy simple, solo se requiere una migración parcial, y la idea es la misma que la segmentación por primera vez.

Por supuesto, si el método de segmentación seleccionado es "segmentación de rango", no habrá problemas en la segunda segmentación y los datos se ejecutarán naturalmente en el último nodo. Por ejemplo, si dividimos la tabla por año y mes. Los datos de marzo de 2019 caen naturalmente en la tabla de xxxx_201903.
En este punto, Brother Z todavía quiere enfatizar particularmente que si no puede dividir y tratar de no dividir, primero puede usar una solución como "separación de lectura-escritura" para tratar los problemas que enfrenta primero .
Si realmente desea realizar la segmentación, primero debe "segmentación vertical" y luego considerar la "segmentación horizontal" .
En términos generales, considerando en este orden, el desempeño de costos es mejor.
para resumir
Bueno, resumamos.
Esta vez, primero les presentaré dos ideas para la segmentación de bases de datos. Las dos formas de pensar se entienden generalmente: "división vertical" es igual a "columna" que cambia a "fila" sin cambios, y "división horizontal" es igual a "fila" que cambia a "columna" sin cambios.
Luego me concentré en los tres métodos de implementación de "segmentación horizontal" y las ideas de implementación específicas.
Finalmente, les compartí una experiencia práctica.
Espero inspirarte.
Artículos relacionados:
-
Explicación detallada del enfoque del sistema distribuido de `` apátridas ''
-
Explicación detallada del enfoque del sistema distribuido de `` alta cohesión y bajo acoplamiento ''
Haga clic para seguir y conocer la nueva tecnología de Huawei Cloud por primera vez ~