objetivos
- Cree un clúster de servicios Rabbitmq de tres nodos para cumplir con los requisitos de alta disponibilidad
- Requiere alta disponibilidad, mantenimiento, cola de espejo y equilibrio de carga.
Componentes principales
- RabbitMQ se utiliza para almacenar y reenviar mensajes y colas de espejo,
- HAProxy se utiliza para equilibrar la carga del tráfico a rabbitmq,
- Keepalived se usa para mantener vivo HAProxy (rabbitmq también se puede mantener vivo) y proporcionar acceso VIP.
- enlace de descarga
Modelo de arquitectura
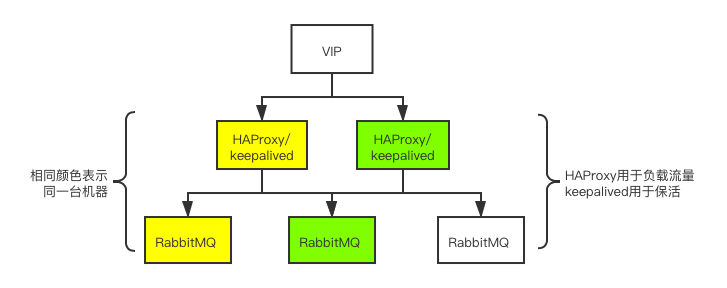
Enlace de acceso
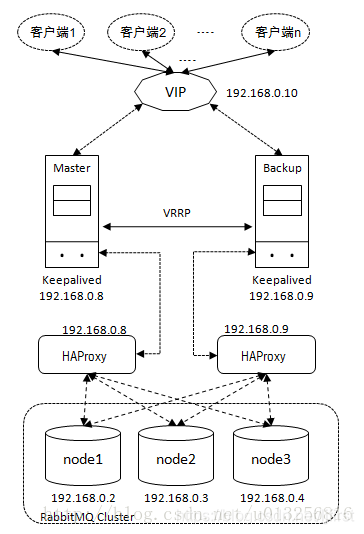
La imagen se selecciona de: Equilibrio de carga de RabbitMQ (3) -Keepalived + HAProxy para lograr un equilibrio de carga de alta disponibilidad
- El cliente establece un enlace de comunicación a través de VIP; el enlace de comunicación se enruta al HAProxy correspondiente a través del nodo Keeapled Master; HAProxy distribuye la carga a cada nodo del clúster a través de un algoritmo de equilibrio de carga.
- En circunstancias normales, la carga de las conexiones de cliente se distribuye a través de la parte izquierda de la figura.
- Cuando el nodo Keepalived Master está inactivo o HAProxy está inactivo y no se puede restaurar, entonces Backup se promueve a Master y la conexión del cliente se distribuye a través de la parte derecha de la figura.
Razones para la selección
- ¿Por qué crear una cola de mensajes de varios nodos?
单节点rabbitmq存在宕机风险,因此需要搭建三台互相备份
- ¿Cómo duplicar mensajes?
镜像其实是一种策略,首先是将三台rabbitmq设置为集群,然后开启镜像策略,使得消息传递到一个队列时,会自动拷贝到其他镜像的队列。
- Si una determinada máquina recibe demasiada presión, ¿cómo lograr el equilibrio de carga?
rabbitmq集群本身不具备负载均衡的功能,需要配合其他软件使用,比如HAProxy,同样的道理,为了防止出现宕机问题,需要在集群中配置多台HAProxy。
- Si HAProxy baja, ¿cómo se siente el otro? ¿Y cambiar la solicitud de tráfico?
HAProxy在宕机时,keepalived有保活脚本,大概意思就是发现keepalived发现HAProxy不存在,就会启动它,过三秒发现还是没启动,那就关闭它,关闭它的时候,会触发vip漂移到另外一台上。HAProxy 之间需要能够自动进行故障转移,通常的解决方案就是 KeepAlived。KeepAlived也是两台,一主一从,对外提供vip,主机宕机,从机会接管vip(具体见文末的彩蛋2)。
- En este caso, se seleccionan dos HAProxy para el equilibrio de carga. ¿El modo de carga de cada HAProxy debe cargar tres Rabbitmq, o cada uno cargar dos de ellos?
负载均衡三台。满足极端情况下的高可用。
- En caso de que un Rabbitmq falle, ¿HAProxy aún le enviará mensajes y hará que el mensaje se pierda?
HAProxy的.cfg文件中定义的有健康检查机制,参数fall在指定多少次不成功的健康检查后,认为该服务宕掉了。配置文件中:server node3 hadoop003:5672 check inter 5000 rise 2 fall 3 weight 1,这里的rise 2 fall 3 就是用于判断死活的。haproxy健康检查rabbitmq,keepalived的ha_check.sh脚本检测haproxy
- Si keepalived se cuelga, ¿cómo funciona otro keepalived?
这个问题我没有仔细研究,应该是两台keepalived互相有心跳保活,主机宕机,从机会立刻抢占vip.
Proceso de construcción simple
- El primer paso: instalar RabbitMQ en diferentes máquinas virtuales
- Paso 2: Verifique la instalación exitosa de RabbitMQ
- Paso 3: Cree la cola de espejo de RabbitMQ
- Paso 4: establezca las reglas de duplicación de RabbitMQ y verifique
- Paso 5: Construye HAProxy
- Paso 6: Operaciones relacionadas con los permisos de HAProxy
- Paso 7: Construya Keepalived
- Paso 8: Operaciones relacionadas con los permisos de mantenimiento
- Paso 9: pruebe el impacto en la entrega de mensajes en diferentes situaciones de tiempo de inactividad
Proceso de construcción detallado
- El primer paso: instalar RabbitMQ en diferentes máquinas virtuales
# 安装rabbitmq之前的依赖erlang和socat
rpm -ivh erlang-22.0.7-1.el7.x86_64.rpm
yum -y install socat
rpm -ivh rabbitmq-server-3.7.17-1.el7.noarch.rpm
# 启动服务 和 设置开机自启
service rabbitmq-server start
chkconfig rabbitmq-server on
# 新增用户并授权,第三句的 / 表示在vhost ”/“ 上的permission
rabbitctl add_user username password
rabbitctl set_user_tags username administrator
rabbitctl set_permissions -p / username ".*" ".*" ".*"
- Paso 2: Verifique la instalación exitosa de RabbitMQ
# 配置rabbitmq的浏览器插件
rabbitmq-plugins enable rabbitmq_management
# 在浏览器输入 IP:15672 输入用户名和密码 登录验证是否成功
# 点击浏览器中admin模块,看一下权限是否正确
- Paso 3: Cree la cola de espejo de RabbitMQ.
# 保持三台机器的.erlang.cookie一致,通过find / -iname .erlang.cookie 全局搜,然后copy到其他两台的root下,一般在/var/lib/rabbitmq/下可以找到,scp到其他两台上
scp xx/.erlang.cookie root@IP:/root/
# 分别在各自节点的/etc/hosts下设置相同的配置信息(copy),然后重启机器
IP1 hostname1
IP2 hostname2
IP3 hostname3
# 后台启动方式
rabbitmq-server -detached #说明:该命令会同时启动 Erlang 虚拟机和 RabbitMQ 应用服务。而后文用到的 rabbitmqctl start_app 只会启动 RabbitMQ 应用服务, rabbitmqctl stop_app 只会停止 RabbitMQ 服务
# 集群模式,设置镜像队列,下面四句话分别在三台机器上执行,只有主机需要改成内存运行模式,才运行第三句的--ram
rabbitmqctl stop_app # 1.停止服务
rabbitmqctl reset # 2.重置状态
# 3.节点加入,rabbit@hadoop001是集群的名字,请起的响亮点
rabbitmqctl join_cluster --ram rabbit@hadoop001
rabbitmqctl start_app # 4.启动服务
# 查看镜像队列状态
rabbitmqctl cluster_status
-
Paso 4: establezca las reglas de duplicación de RabbitMQ y verifique
# 设置policy
rabbitmqctl set_policy ha-all "^" '{"ha-mode":"all"}'
# 验证
任意选取一台Rabbitmq登陆,创建一个队列,然后去其他两台看看,该队列是否存在
- Paso 5: Construye HAProxy
# 找个文件夹解压
tar -zxvf haproxy-2.0.3.tar.gz
# 编译,其中TARGET=Linux26 是通过uname -a 来查看Linux内核版本的,我的版本是31,PREFIX的地址自己指定
make TARGET=Linux31 PREFIX=/usr/app/haproxy-2.0.3
make install PREFIX=/usr/app/haproxy-2.0.3
# haproxy.cfg是haproxy的配置文件,需要自己创建,然后去网上找别人写好的配置文件,启动的时候可能会引起报错,解决不了的直接删除
touch haproxy.cfg #这个文件后续会用于启动haproxy,位置最好放在haproxy/conf下,haproxy文件就是刚才的PREFIX指定的位置。
# 启动:就是用haproxy/sbin/haproxy去启动刚才的配置文件
/usr/app/haproxy-2.0.3/sbin/haproxy -f /usr/app/haproxy-2.0.3/conf/haproxy.cfg # 启动报错见下方的 《haproxy安装过程中的坑》
- Paso 6: Operaciones y verificación de los permisos de HAProxy
# HAproxy设置开机自启【源码包安装方式是没有启动脚本的,是能通过命令的方式进行启动和关闭,什么都不会输出,只能通过netstat 的方式进行验证】
#将HAProxy服务启动脚本放置到/etc/init.d/,启动脚本见下方【HAProxy服务启动脚本】
cp haproxy /etc/init.d/
chkconfig --add haproxy
chkconfig --list haproxy
service haproxy start|restart|stop|status
# 验证
浏览器输入IP:8100/stats 就可以看见haproxy的界面 #stats是你在haproxy.cfg的lister起的名字
- Script de inicio del servicio HAProxy
- Foso durante la instalación de haproxy
# 启动报错
解决办法:先看报错信息中的数字,它对应哪一行出错,然后去配置文件中,要么删除要么修改,具体可以见下面的链接:HAProxy实战搭建
# 访问ip:8100/stats空页面:
解决办法:修改bind 为 0.0.0.0:8080
# 出现:Proxy 'monitor(就是你起的lister名)': in multi-process mode, stats will be limited to process assigned to the current request
解决办法:修改:nbproc=1
-
Paso 7: Construya Keepalived
#解压
tar -zxvf keepalived-2.0.18.tar.gz
cd keepalived-2.0.18
#安装keepalived的相关依赖
yum -y install libnl libnl-devel
#--prefix是指定安装路径,没有的话会帮你创建,/usr/app/是路径,也可以安装在/etc/local
./configure --prefix=/usr/app/keepalived-2.0.18
#编译
make && make install #这一步可能会报错,需要你安装gcc或者openssl-devel,甚至涉及到换yum源,需要你yum repolist all. yum clean all. yum makecache. yum install -y gcc-c++ tcl. yum install -y openssl-devel.
#进行环境配置,Keepalived 默认会从 /etc/keepalived/keepalived.conf 路径读取配置文件,所以需要将安装后的配置文件拷贝到该路径
make /etc/keepalived
#/usr/app选择自己的安装路径,keepalived.conf的配置见下面的链接
cp /usr/app/keepalived-2.0.18/etc/keepalived/keepalived.conf /etc/keepalived/
#将所有 Keepalived 脚本拷贝到 /etc/init.d/ 目录下:
#编译目录中的脚本,/usr/software/是之前你安装tar包的地方
cp /usr/software/keepalived-2.0.18/keepalived/etc/init.d/keepalived /etc/init.d/
#安装目录中的脚本
cp /usr/app/keepalived-2.0.18/etc/sysconfig/keepalived /etc/sysconfig/
cp /usr/app/keepalived-2.0.18/sbin/keepalived /usr/sbin/
- Paso 8: Operaciones relacionadas con los permisos de mantenimiento
#加入系统:
chmod +x /etc/init.d/keepalived
chkconfig --add keepalived 或者 chkcoonfig keepalived on
#设置/取消开机自动启动
systemctl enable/disable keepalived.service
#启动/停止
systemctl start/stop keepalived.service
#haproxy的存活情况的判断脚本,记住这个路径,需要写入到keepalived.conf中
chmod +x /etc/keepalived/haproxy_check.sh
#查看keepalived状态
service keepalived status 或者 systemctl status keepalived.service
- Pit durante la instalación mantenida
- El permiso del archivo de configuración keepalived solo puede ser 644; de lo contrario, se informará un error
- El archivo de configuración keepalived.conf y el script keepalived haproxy_check.sh utilizados para monitorear la supervivencia de haproxy pueden hacer referencia a este documento: Cree un clúster de alta disponibilidad RabbitMQ basado en HAProxy + KeepAlived
Programa de prueba
-
Programa de prueba:
- Solución 1: En las siguientes circunstancias, visite VIP: 15672 para ver si puede iniciar sesión en el lado del navegador de rabbitmq.
- Solución 2: En las siguientes situaciones, envíe mensajes a rabbitmq para ver si hay algún error en la entrega del mensaje.
-
Situación de prueba:
- Escenario 1: Desactive el servicio rabbitmq en una máquina determinada
- Escenario 2: Desactive el servicio rabbitmq en dos máquinas
- Escenario 3: cierre el servicio haproxy en una máquina determinada
- Escenario 4: Desactive el servicio keepalived en una máquina determinada
- Escenario 5: Apague el servicio haproxy + keepalived en una máquina al mismo tiempo
- Escenario 6: Apague haproxy en una máquina y mantenga el servicio activo en otra máquina al mismo tiempo
- Escenario 7: Apague una máquina de este tipo (también contiene el servicio rabbitmq + haproxy + keepalived)
- Escenario 8: Apague estas dos máquinas (una contiene los servicios rabbitmq + haproxy + keepalived al mismo tiempo, y la otra contiene solo rabbitmq)
-
Resultados de la prueba:
- Opción 1: Todos pasaron
- Opción 2: para ser probado junto con RabbitMQ para lograr el 100% de entrega de mensajes
-
Huevo de Pascua 1:
- Consulte el script de instalación completo: declaraciones de instalación de middleware comunes
-
Huevo de Pascua 2:
- Al hacer la prueba 1, utilicé el inicio de sesión del navegador para consultar, pero descubrí que cuando rabbitmq1 estaba inactivo, el navegador no podía acceder, pensé que haproxy no funcionaba, de hecho, el archivo de configuración de haproxy solo configuró 5672. Pero no configuré el puerto de 15672. O cambié el plan en lugar de probar el navegador y usé la prueba de enlace de código, o agregué reglas de escucha de reenvío de puerto 15672 en haproxy.cfg y agregué el siguiente contenido al archivo .cfg:
# 绑定配置
listen rabbitmq_browser
# 注意此处的15671,你也可以用任何不冲突的端口,然后浏览器访问vip:15671就可以了
bind :15671
# 注意此处的http
mode http
# 采用加权轮询的机制进行负载均衡
balance roundrobin
# RabbitMQ 集群节点配置
server 节点名 hadoop001:15672 check inter 5000 rise 2 fall 3 weight 1
server node2 hadoop002:15672 check inter 5000 rise 2 fall 3 weight 1
server node3 hadoop003:15672 check inter 5000 rise 2 fall 3 weight 1
- Huevo de Pascua 3:
- Durante la prueba, usé systemctl stop Haproxy.server y service Haproxy stop para apagar Haproxy, pero cuando verifiqué el estado con service Haproxy status, encontré que todavía se estaba ejecutando. Pensé que el comando no era válido o instalé un Haproxy falso.
- La razón real es: el script ha_check.sh que configuré en keepalived seguirá verificando Haproxy y reiniciará Haproxy una vez que no se encuentre. Si el sueño aún falla durante tres segundos, detenga el servicio y luego otros componentes de keepalived encontrarán Cuando se cierre el servicio detectado, se notificará al otro Haproxy de respaldo para que comience a asumir el rol de protagonista.
- Hay un parámetro de estado en el archivo de configuración keepalived. Por lo general, el artículo recomienda configurar el maestro como maestro y el esclavo como respaldo. Se recomienda configurarlo como respaldo aquí. En este caso, el maestro se inicia primero. Cuando ocurre una deriva VIP, el maestro original El inicio no se desviará de nuevo, lo que reducirá la fluctuación de la red.
- Durante la prueba, usé systemctl stop Haproxy.server y service Haproxy stop para apagar Haproxy, pero cuando verifiqué el estado con service Haproxy status, encontré que todavía se estaba ejecutando. Pensé que el comando no era válido o instalé un Haproxy falso.