Historial del sistema operativo
Simplemente consulte el blog: https://www.cnblogs.com/Dominic-Ji/articles/10929381.html
Tecnología multicanal
El núcleo único logra un efecto concurrente
Conocimiento requerido
-
Concurrencia
Parece que correr simultáneamente puede llamarse concurrente
-
Paralelo
Real ejecución simultánea
PD:
-
Paralelo debe considerarse concurrente
-
Las computadoras de un solo núcleo ciertamente no pueden lograr paralelismo, ¡pero pueden lograr concurrencia! ! !
Suplemento: asumimos directamente que un solo núcleo es un núcleo, y solo una persona trabaja, no tenga en cuenta la cantidad de núcleos en la CPU
Ilustración técnica multicanal
Ahorre el tiempo total dedicado a ejecutar múltiples programas
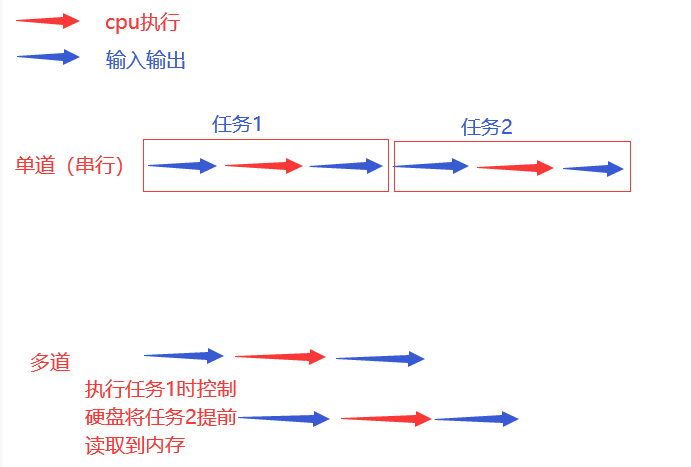
Conocimiento clave de tecnología multicanal
Multiplexación espacial y multiplexación temporal
-
Multiplexación espacial
Múltiples programas comparten un conjunto de hardware de computadora
-
Multiplexación en el tiempo
Ejemplo: lavar ropa durante 30 años, cocinar durante 50 años, agua hirviendo durante 30 años
El canal único necesita 110 segundos, los canales múltiples solo necesitan el cambio largo de tarea para ahorrar tiempo
Ejemplo: jugar un juego mientras se come y se guarda el estado
Cambiar + guardar estado
La conmutación (CPU) se divide en dos casos
1. Cuando un programa encuentra una operación de E / S, el sistema operativo privará al programa de la autoridad de ejecución de la CPU
Rol: mejora la utilización de la CPU y no afecta la eficiencia de ejecución del programa
2. Cuando Cuando un programa ocupa la CPU durante mucho tiempo, la atracción de la operación también privará al programa de la autoridad de ejecución de la CPU.
Inconvenientes: reduzca la eficiencia de ejecución del programa (tiempo original + tiempo de conmutación)
Teoría del proceso
Conocimiento requerido
La diferencia entre programa y proceso
Un programa es un montón de código que se encuentra en el disco duro. Un proceso "inactivo" indica que el programa se está ejecutando y que está "en vivo".
Programación de procesos
-
Algoritmo de programación por orden de llegada
El algoritmo de programación por orden de llegada (FCFS) es uno de los algoritmos de programación más simples, que se puede usar tanto para la programación de trabajos como para la programación de procesos. El algoritmo FCFS es más propicio para trabajos largos (procesos) que para trabajos cortos (procesos). Se puede ver que este algoritmo es adecuado para trabajos ocupados de CPU, pero no es propicio para trabajos ocupados de E / S (procesos).
- Algoritmo de programación de prioridad de trabajo corto
El algoritmo de programación de prioridad de trabajo corto (proceso) (SJ / PF) se refiere a un algoritmo que prioriza trabajos cortos o procesos cortos. Este algoritmo se puede usar tanto para la programación de trabajos como para la programación de procesos. Pero no es bueno para trabajos largos; no hay garantía de que los trabajos urgentes (procesos) se procesen de manera oportuna; solo se estima la duración del trabajo.
- Método de rotación de intervalo de tiempo + cola de comentarios de varios niveles
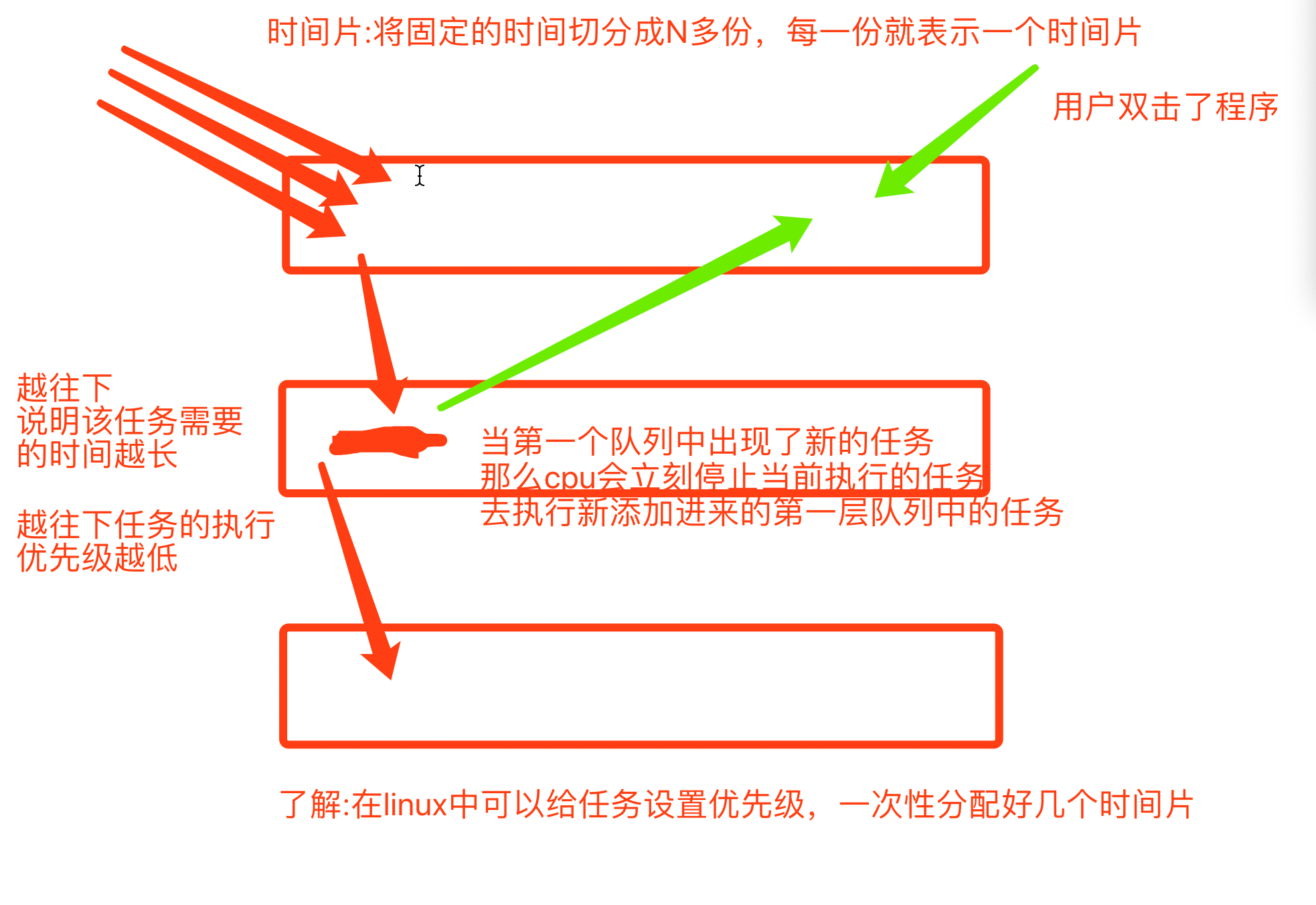
Diagrama de tres estados del proceso en ejecución

Dos pares de conceptos importantes.
-
Síncrono y asíncrono
"" "Describe la forma en que se envía la tarea". "
Sincronización: después de enviar la tarea, espera el resultado de la tarea in situ. No se hace nada durante el proceso de espera (seco, etc.)
La sensación a nivel del programa es que está atascado
asíncrono: después de la presentación del trabajo, hay lugar para esperar tareas regresan directamente los resultados para hacer otras cosas
cómo las tareas consiguen los resultados de mi presentación?
El resultado devuelto de la tarea será procesado automáticamente por un mecanismo de devolución de llamada asíncrono.
- Bloqueo sin bloqueo
"" "Ejecución en marcha descripción del" "" bloqueo: bloqueo de estado de no-bloqueo: estado de listo, estado de funcionamiento al estado ideal: debemos dejar que nuestra escritura del código siempre en el estado de listo se enciende entre el estado y funcionamiento
Combinación de los conceptos anteriores: la combinación más eficiente es el bloqueo asíncrono sin bloqueo
Dos formas de iniciar el proceso.
de multiprocesamiento Importación Proceso de Importación Tiempo DEF tarea (nombre): Imprimir ( ' % S Correr es ' % nombre) el time.sleep ( 3. ) Imprimir ( ' % S Over es ' % nombre) SI el __name__ == ' __main__ ' : # 1 crear un objeto el proceso p = (target = de tareas, args = ( ' Jason ' ,)) # tipo de contenedor, incluso si hay sólo un elemento de sugerencia de utilizar una coma # 2 abierta proceso p.start () # indicar al sistema operativo para ayudarle a crear un proceso para asíncrono de impresión ( ' principal ' ) # heredó segundo camino a la clase de multiprocesamiento Importación Proceso de Importación Tiempo clase MyProcess (Proceso): DEF RUN ( Ser): Imprimir ( ' Hola BF chica ' ) del time.sleep ( . 1 ) Imprimir ( ' ¡Fuera! ' ) SI el __name__ == '__main__ ' : p = MyProcess () p.start () print ( ' 主' )
Resumen
Crear un proceso es solicitar un espacio de memoria en la memoria y arrojar el código que debe ejecutarse. Un proceso corresponde a un espacio de memoria separado en la memoria. Múltiples procesos corresponden a múltiples espacios de memoria independientes en la memoria . Datos entre procesos y procesos predeterminados En este caso, es imposible interactuar directamente. Si desea interactuar, puede usar herramientas y módulos de terceros.
método de unión
Unirse es dejar que el proceso principal espere a que el código del subproceso termine de ejecutarse antes de continuar. No afecta la ejecución de otros procesos secundarios.
de multiprocesamiento importación Proceso de importación tiempo def tarea (nombre, n): print ( ' % s se está ejecutando ' % nombre) time.sleep (n) de impresión ( ' % s ya ha pasado ' % nombre) si __name__ == ' __main__ ' : # p1 = Proceso (target = task, args = ('jason', 1)) # p2 = Process (target = task, args = ('egon', 2)) # p3 = Process (target = task , args = ('tanque', 3)) #start_time = time.time () # p1.start () # p2.start () # p3.start () # Simplemente dígale al sistema operativo que cree un proceso # # time.sleep (50000000000000000000) # # p.join () # El proceso principal espera a que el proceso hijo p termine de ejecutarse antes de continuar. # P1.join () # p2.join () # p3.join () start_time = time.time () p_list = [] para i en el rango (1, 4 ): p = Proceso (target = tarea, args = ( ' proceso hijo% s ' % i, i)) p.start () p_list.append (p) para pen p_list: p.join () print ( ' 主' , time.time () - start_time)
Aislamiento de datos entre procesos.
de multiprocesamiento importación Proceso de dinero = 100 def de tareas (): mundial dinero # 局部修改全局 dinero = 666 print ( ' 子' , dinero) si __name__ == ' __main__ ' : p = Proceso (target = tarea ) p.start () p.join () print (dinero)