El contenido de los reptiles es difícil y difícil, simple y simple, ¡depende de la solicitud de todos! ¡Escribí dos programas de reptiles, y es como compartir mi viaje! Después de todo, ¡quiero hacer IA y CTF!
El primero es el producto en bruto después de unos días de aprender a gatear, y simplemente rastreó la lista de música QQ (se siente irregular)
Del mismo modo, la ruta técnica principal se realiza mediante el método request-bs4, que proporciona soporte técnico a través de solicitudes de importación y desde la importación de bs4 BeautfulSoup
La URL que utilicé es: url = "http://www.9ku.com/music/sshot.htm Una lista de sitios web de terceros
Hablar es fácil. Enséñame el código
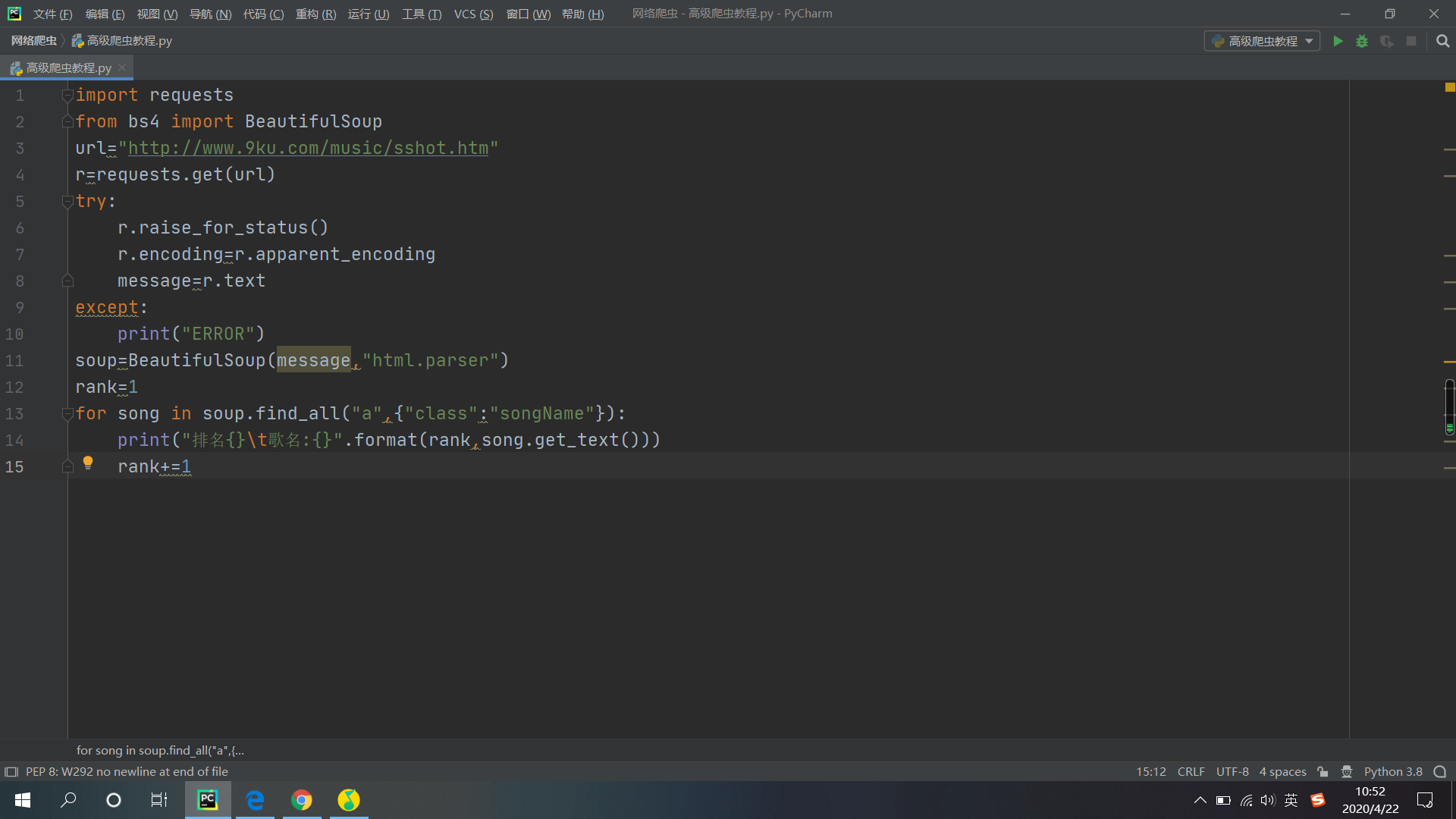
Usando el marco básico mencionado en MOOC como base, aquí obtengo un pequeño resumen, si desea obtener el contenido de texto debajo de una etiqueta, ¡puede usar Tag.get_text () para obtener el contenido de texto!
Por supuesto, no es imposible usar expresiones regulares
El código clave es el siguiente: print (re.search (">. * <", Str (canción)). Group ()), pero al hacerlo, los corchetes angulares izquierdo y derecho no serán muy hermosos
El resultado final es el siguiente (parcial):
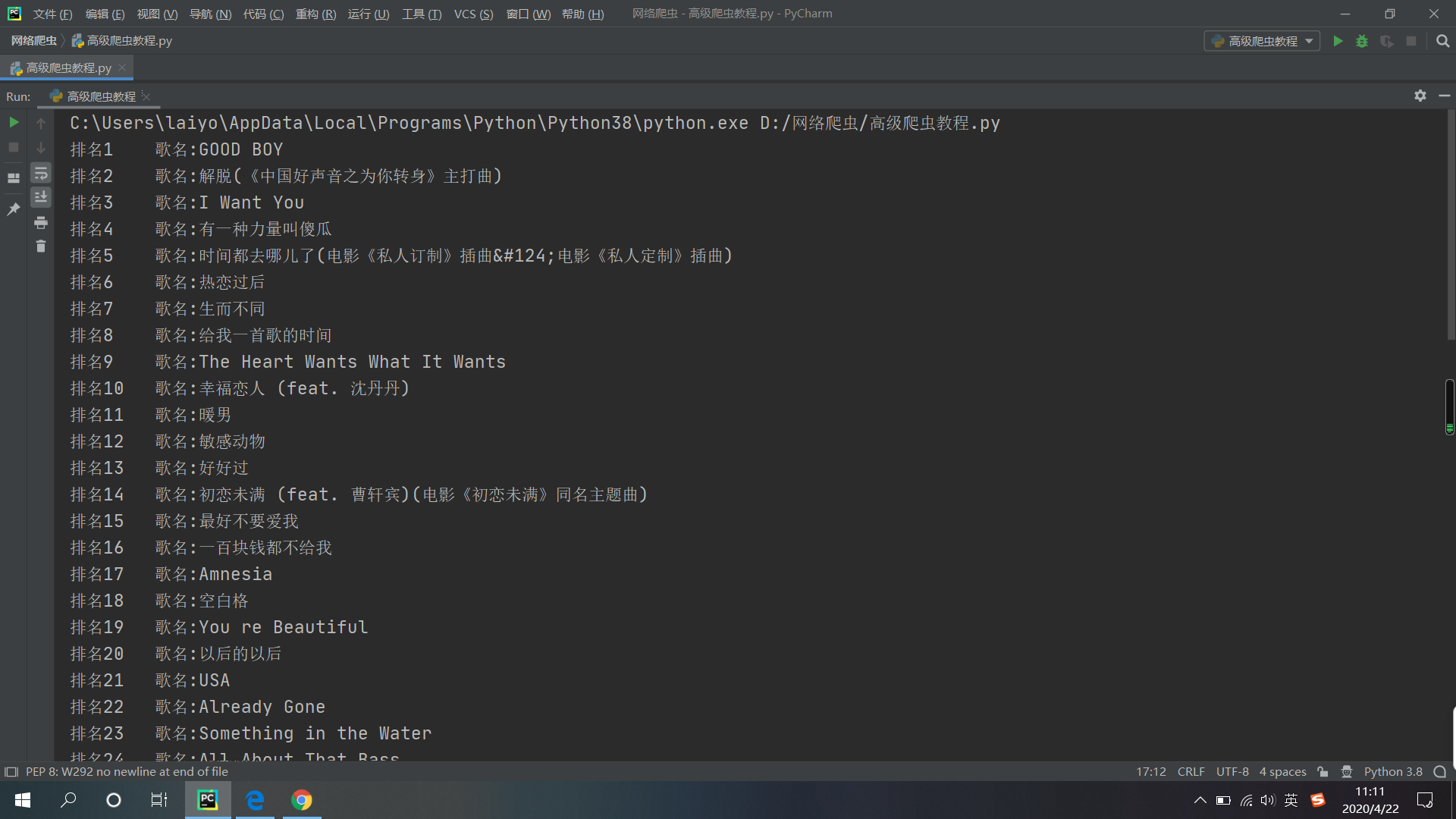
Aunque el rastreador está hecho, ¡no parece tan bueno! Entonces, con la versión 2.0, solo un pequeño cambio, el principio sigue siendo el mismo, esta vez arrastrándose es Kugou
El código es un poco largo, lo puse en GitHub, puedes criticar y corregir
https://gist.github.com/A-Huge-Cat/911a4f1d10721d33f9e0f2f0d2c8a78d (por primera vez, no sé si puedo acceder, si no puede, déjeme un mensaje)