Prólogo
En este capítulo, explicaremos la cola en la solución de alta concurrencia. La puesta en cola de mensajes se ha convertido gradualmente en el medio principal de comunicación interna en los sistemas de TI empresariales. Tiene una serie de funciones como bajo acoplamiento, entrega confiable, difusión, control de flujo y consistencia final, y se ha convertido en uno de los principales medios de RPC asíncrono.
Resumen del tema
- Introducción básica de la alta cola de mensajes concurrentes
- Características de la cola de mensajes
Contenido principal
1. Introducción básica de la cola de mensajes de alta concurrencia
1. Ejemplos
Después de realizar un pedido en el centro comercial, espero que el comprador pueda recibir notificaciones por SMS o correo electrónico. Hay una manera de llamar a la API para enviar SMS después de la lógica de realizar un pedido. Si el servidor tarda en responder, el cliente de SMS tiene problemas, y muchas otras razones, el comprador no puede recibir el SMS normalmente, luego continúe reintentando o renunciando directamente. ¿Qué hay de enviar? No importa cuál elija, la implementación será complicada.
¿Cómo se resuelve la cola de mensajes? Se puede decir que el proceso de envío de mensajes cortos se encapsula en un mensaje y se envía a la cola de mensajes. La cola de mensajes procesa los mensajes en la cola en un orden determinado, y en un momento determinado, se procesará el mensaje enviado por el mensaje corto. La cola de mensajes notificará a un servicio para enviar el mensaje corto. Si tiene éxito, el mensaje se procesará tan pronto como se ponga en la cola. Si algo sale mal, puede volver a poner el mensaje en la cola de mensajes y esperar el procesamiento. Si usa la cola de mensajes en el ejemplo anterior, la ventaja es desacoplar el proceso de enviar mensajes de texto desde otras funciones. Al enviar mensajes de texto, solo necesita asegurarse de que este mensaje se envíe a la cola de mensajes, y luego puede manejar otras cosas después de enviar el mensaje de texto. En segundo lugar, el diseño del sistema se ha vuelto simple, sin tener que pensar demasiado en enviar mensajes cortos en el escenario de hacer un pedido, sino que se entregó a la cola de mensajes para manejar este asunto. Y puede garantizar que el mensaje se enviará, siempre que el mensaje no se envíe correctamente, se continuará agregando a la cola de mensajes. Si hay un problema con el servicio de SMS, espere hasta que se restablezca el servicio y se pueda enviar la cola de mensajes, pero no es tan oportuno.
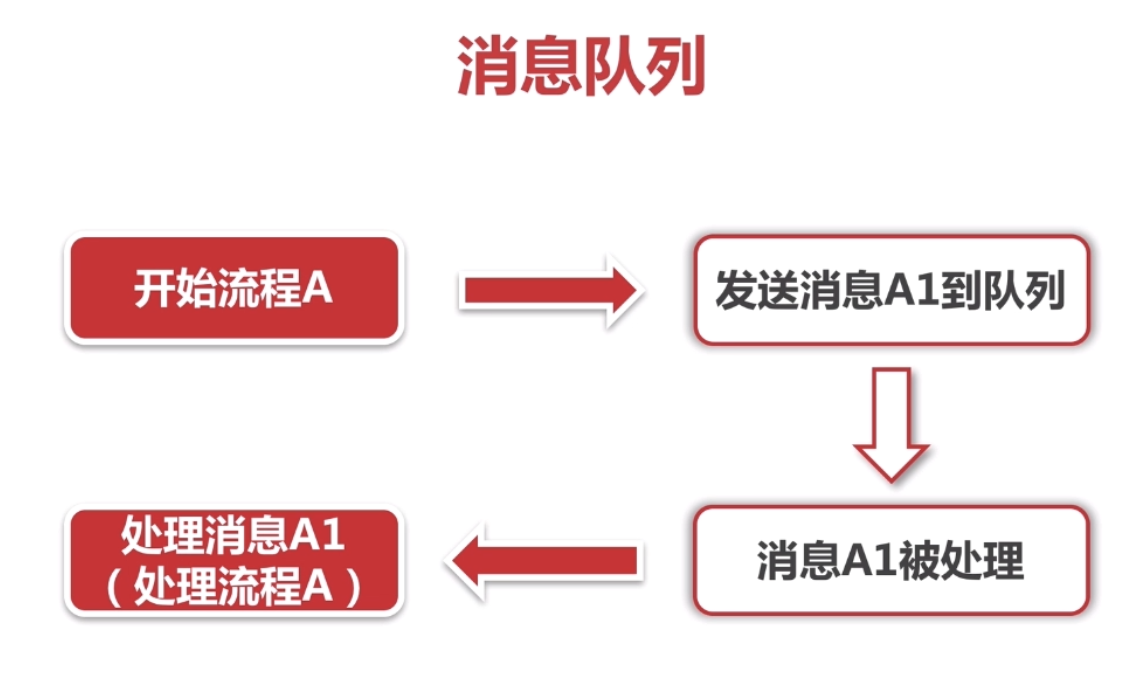
Como punto final, supongamos que después de enviar el SMS, se enviará el correo electrónico. Con la cola de mensajes, no tenemos que esperar sincrónicamente. Podemos procesar directamente en paralelo. El proceso central de hacer un pedido puede completarse más rápido. Esto puede aumentar la capacidad de procesamiento asíncrono de la aplicación, reducir o incluso imposibilitar la aparición y el fenómeno. Recuerde que cuando ingresamos el número de teléfono móvil para enviar el código de verificación en el sitio web, no podemos recibir el mensaje de texto por mucho tiempo, y el tiempo de la interfaz de SMS ha expirado. Algo salió mal cuando se envió el SMS, o la red del servidor abrió una pequeña brecha, y puede haber demasiados mensajes en la cola de mensajes durante un cierto período de tiempo para ser procesados.
2. Beneficios
1. Completó con éxito un proceso de desacoplamiento asíncrono . Al enviar SMS, solo asegúrese de ponerlo en la cola de mensajes y luego haga lo siguiente. Una transacción solo se preocupa por el proceso esencial y debe depender de otras cosas, pero cuando no es tan importante, puede notificarse sin esperar el resultado. Cada miembro no tiene que ser influenciado por otros miembros, pero puede ser más independiente y solo se puede contactar a través de un contenedor simple.
Para nuestro sistema de pedidos, después de que el pago final del pedido sea exitoso, es posible que deba enviar puntos SMS al usuario, pero este no es el proceso central de nuestro sistema. Si la velocidad del sistema externo es lenta (por ejemplo, la velocidad de la puerta de enlace de SMS no es buena), el tiempo del proceso principal será mucho más largo. El usuario ciertamente no quiere hacer clic para pagar durante varios minutos antes de ver el resultado. Entonces solo necesitamos informar al sistema de SMS que "hemos pagado con éxito", y no tenemos que esperar a que termine el procesamiento.
3. Escenarios de aplicación.
Hay muchos escenarios en los que se pueden usar las colas de mensajes
La característica principal es el procesamiento asincrónico, y el propósito principal es reducir el tiempo de respuesta de la solicitud y el desacoplamiento. Por lo tanto, el escenario de uso principal es colocar operaciones que requieren mucho tiempo y que no requieren resultados de retorno inmediatos (sincrónicos) como mensajes en la cola de mensajes.
En el escenario de uso, por ejemplo:
suponga que el usuario se registra en su software, y el servidor realizará estas operaciones después de recibir la solicitud de registro del usuario:
- Verifique el nombre de usuario y otra información, si no hay problema agregará un registro de usuario en la base de datos
- Si se registra por correo electrónico, se le enviará un correo electrónico de registro exitoso y el registro del teléfono móvil enviará un SMS
- Analice la información personal del usuario para recomendarle algunas personas de ideas afines en el futuro, o recomendarlo a esas personas
- Enviar a los usuarios una notificación del sistema con instrucciones
Espera ...
Pero para el usuario, la función de registro solo necesita el primer paso, siempre que el servidor almacene la información de su cuenta en la base de datos, puede iniciar sesión para hacer lo que quiere hacer. En cuanto a otras cosas, ¿tengo que completarlas todas en esta solicitud? ¿Vale la pena que el usuario pierda el tiempo esperando que lidie con estas cosas que no son importantes para él? Por lo tanto, después de completar el primer paso, el servidor puede colocar otras operaciones en la cola de mensajes correspondiente y luego devolver inmediatamente los resultados del usuario, y la cola de mensajes realiza estas operaciones de forma asincrónica.
O bien, hay un caso en el que hay una gran cantidad de usuarios que registran su software al mismo tiempo, sin importar cuán alta sea la concurrencia, la solicitud de registro comienza a tener algunos problemas, como la interfaz de correo no puede soportar, o la gran cantidad de cálculos al analizar la información llena la CPU, lo que aparecerá Aunque los registros de datos de los usuarios se agregaron rápidamente a la base de datos, se bloquearon al enviar correos electrónicos o analizar información, lo que resultó en un aumento significativo en el tiempo de respuesta de la solicitud, e incluso en un tiempo de espera, que era un poco poco económico. Ante esta situación, estas operaciones generalmente se colocan en la cola de mensajes (modelo de consumidor productor), la cola de mensajes se procesa lentamente y la solicitud de registro se puede completar rápidamente, sin afectar el uso del usuario de otras funciones.
Segundo, las características de la cola de mensajes.
1. Cuatro características
- Sin relación con el negocio: solo distribuye mensajes
- FIFO (primero en entrar, primero en salir): primera entrega, primera llegada
- Tolerancia a desastres: adición y eliminación dinámica de nodos y persistencia de mensajes
- Rendimiento: mayor rendimiento y mejor eficiencia de comunicación interna del sistema
2. ¿Por qué necesitas una cola de mensajes?
- La velocidad o estabilidad de [producción] y [consumo] son inconsistentes.
3. Beneficios de la cola de mensajes
-
Desacoplamiento empresarial : es el problema más esencial resuelto por la cola de mensajes. El llamado desacoplamiento es un proceso que se preocupa por el núcleo de una cosa y necesita depender de otros sistemas, pero no es tan importante. Se puede notificar sin esperar el resultado. En otras palabras, el modelo basado en mensajes se refiere a la notificación más que al procesamiento. Por ejemplo, hay un centro de productos dentro de una plataforma de viaje. El centro de productos está conectado a múltiples fuentes de datos, como la estación principal, el fondo móvil y la cadena de suministro turístico. El flujo descendente está conectado al sistema de visualización, como el sistema de recomendación y el sistema API. Cuando los datos aguas arriba cambian, En ese momento, si no usa las colas de mensajes, inevitablemente necesitará llamar a la interfaz para actualizar los datos. Esto depende de la estabilidad y el poder de procesamiento de la interfaz del centro de productos. Sin embargo, como un centro de productos para el turismo, tal vez solo para el suministro de turismo propio. El éxito de la actualización del centro de productos de la cadena es su preocupación. Para los sistemas externos, como las compras grupales, el éxito de la actualización del centro de productos no es responsabilidad del fracaso. Solo deben asegurarse de que se les notifique cuando la información cambie. Para el flujo descendente, puede haber una serie de requisitos, como actualizar el índice y la memoria caché. Para el centro de productos, estas no son las responsabilidades. Para decirlo sin rodeos, si extraen datos regularmente, también pueden asegurarse de que los datos se actualicen, pero el tiempo real no es tan fuerte, pero si el método de interfaz se utiliza para actualizar los datos, obviamente es demasiado pesado para el centro de productos, y solo uno necesita ser liberado en este momento. La notificación de cambio de ID de producto es más razonable para ser procesada por el sistema posterior. Tomemos otro ejemplo: para el sistema de pedidos, después de que el pago final del pedido sea exitoso, es posible que tengamos que enviar una notificación de mensaje de texto al usuario, pero en realidad ya no es el proceso central del sistema. Si la velocidad del sistema externo es lenta, como la velocidad de la puerta de enlace de SMS no es buena Luego, el tiempo del proceso principal será mucho más largo, el usuario ciertamente no quiere hacer clic para ver el resultado después de unos minutos, luego solo tenemos que notificar al sistema de SMS que hemos pagado con éxito, solo envía una notificación por SMS, no tiene que ser Espere a que termine de procesarse antes de finalizar.
-
Consistencia final : la consistencia final se refiere al estado de los dos sistemas que permanecen consistentes, ya sea exitosos o fallidos. Por supuesto, hay un límite de tiempo, cuanto más rápido, mejor en teoría, pero de hecho, bajo varias condiciones anormales, puede haber un cierto retraso para alcanzar el estado final consistente, pero el estado de los últimos dos sistemas es el mismo.
Hay algunas colas de mensajes en la industria para la "consistencia máxima", como Notify (Ali) y QMQ (Where to go), etc. La intención original del diseño es para notificaciones altamente confiables en el sistema de transacción.
Para comprender la coherencia final con el proceso de transferencia de un banco, la necesidad de la transferencia es simple: si el sistema A deduce dinero con éxito, el sistema B debe agregar dinero con éxito. De lo contrario, retrocedan juntos como si nada hubiera pasado.
Sin embargo, hay muchos posibles accidentes en este proceso:(1) A deduce dinero con éxito y no llama a la interfaz B plus money.
(2) Un dinero deducido con éxito. Aunque la llamada a la interfaz B plus money fue exitosa, la excepción de la red causó un tiempo de espera al obtener el resultado final.
(3) A deduce el dinero con éxito, B no agrega dinero, A quiere revertir el dinero deducido, pero A la máquina no funciona.
Se puede ver que realmente no es tan fácil hacer esto aparentemente simple. Desde un punto de vista técnico, todos los problemas comunes de coherencia entre JVM son:
(1) Fuerte consistencia, transacciones distribuidas, pero el aterrizaje es demasiado difícil y el costo es demasiado alto, no hay una introducción más específica aquí, quiero conocer Baidu.
(2) La consistencia final es principalmente mediante "grabación" y "compensación". Antes de hacer todas las cosas inciertas, primero registre las cosas y luego haga las cosas inciertas. El resultado puede ser: éxito, fracaso o incertidumbre. "Incierto" (como el tiempo de espera) puede ser equivalente al fracaso . Si tiene éxito, puede borrar las cosas registradas. Para fallas e incertidumbres, puede confiar en tareas cronometradas y otros métodos para volver a comprometer todas las cosas fallidas hasta que tenga éxito.
Volviendo al ejemplo anterior, cuando el sistema deduce con éxito dinero de A, el sistema registra la "notificación" en B en la biblioteca (para garantizar la mayor confiabilidad, el sistema puede notificar al sistema B que agregue dinero y deduzca dinero con éxito. Las cosas se mantienen en una transacción local. Si la notificación es exitosa, el registro se elimina. Si la notificación falla o es incierta, confiamos en una tarea programada para informarnos compensatoriamente hasta que actualicemos el estado al correcto. Cabe señalar que el diseño de colas de mensajes como Kafka tiene la posibilidad de perder mensajes a nivel de diseño. Por ejemplo, el parpadeo regular puede causar la pérdida de mensajes. Incluso si solo pierde una milésima parte del mensaje, la empresa utiliza otros Los medios también deben garantizar que los resultados sean correctos. -
Difusión : una de las funciones básicas de la cola de mensajes es la difusión. Si no hay una cola de mensajes, cada vez que accede una nueva parte comercial, debemos depurar conjuntamente la nueva interfaz. Con la cola de mensajes, solo debemos preocuparnos de si el mensaje se entrega a la cola. En cuanto a quién quiere suscribirse, es un asunto posterior, lo que sin duda reduce en gran medida la carga de trabajo del desarrollo y la depuración conjunta.
-
Acelerar : supongamos que todavía necesitamos enviar correo. Con la cola de mensajes, no necesitamos esperar sincrónicamente. Podemos procesar directamente en paralelo, y las tareas principales pueden completarse más rápido. Mejore la capacidad de procesamiento asincrónico del sistema empresarial. Es casi imposible aparecer y descubrir elefantes.
-
Reducción de picos y control de flujo : para solicitudes que no requieren procesamiento en tiempo real, cuando la cantidad de concurrencia es particularmente grande, primero puede almacenar en caché en la cola de mensajes y luego enviarlas al servicio correspondiente para su procesamiento. Imagine que upstream y downstream tienen diferentes capacidades de procesamiento para las cosas. Por ejemplo, no es una cosa mágica que el front-end web resista decenas de millones de solicitudes por segundo, solo agregue un poco más de máquinas y luego construya algunos equipos de equilibrio de carga LVS y Nginx. Sin embargo, el poder de procesamiento de la base de datos es muy limitado. Incluso con el uso de SSD más sub-base de datos y sub-tabla, el poder de procesamiento de una sola máquina todavía está en 10,000 niveles. Debido a consideraciones de costo, no podemos esperar que el número de máquinas de base de datos se ponga al día con el front-end. Este problema también existe entre el sistema y el sistema. Por ejemplo, debido al efecto de placa corta, la velocidad del sistema de mensajes cortos está atascada en la puerta de enlace (cientos de solicitudes por segundo), y la concurrencia con el extremo frontal no es un orden de magnitud. Sin embargo, si el usuario recibe el mensaje de texto aproximadamente medio minuto por la noche, generalmente no hay problema. Si no hay una cola de mensajes, los esquemas complejos como la negociación y las ventanas deslizantes entre los dos sistemas no son imposibles. Sin embargo, el crecimiento exponencial de la complejidad del sistema inevitablemente lo almacenará aguas arriba o aguas abajo, y se enfrentará a una serie de problemas como el tiempo y la congestión. Y siempre que haya una brecha en el poder de procesamiento, se necesita desarrollar un conjunto de lógica separado para mantener este conjunto de lógica. Por lo tanto, es una forma relativamente común de utilizar el sistema intermedio para volcar el contenido de comunicación de los dos sistemas y procesar estos mensajes cuando el sistema posterior tiene la capacidad de procesar estos mensajes. Con todo, la cola de mensajes no es una panacea. Para aquellos que requieren fuertes garantías de transacción y son sensibles al retraso, RPC es superior a las colas de mensajes. Para cosas que son irrelevantes o muy importantes para otros pero que no están tan preocupadas por usted, puede usar la cola de mensajes para hacerlo. Las colas de mensajes que admiten la coherencia eventual se pueden usar para manejar escenarios de "transacciones distribuidas" donde la latencia no es tan sensible y puede ser una mejor forma de procesamiento que las transacciones distribuidas voluminosas. Cuando haya una brecha en las capacidades de procesamiento de los sistemas ascendentes y descendentes, use las colas de mensajes como un "embudo" general. Cuando el flujo descendente sea capaz de procesar, distribúyalo nuevamente. Si hay muchos sistemas posteriores preocupados por las notificaciones enviadas por su sistema, use la cola de mensajes con decisión.
4. Ejemplo de cola de mensajes
(1) Aquí solo apuntamos a Kafka y RabbitMQ como ejemplos
- Kafka
- RabbitMQ
...
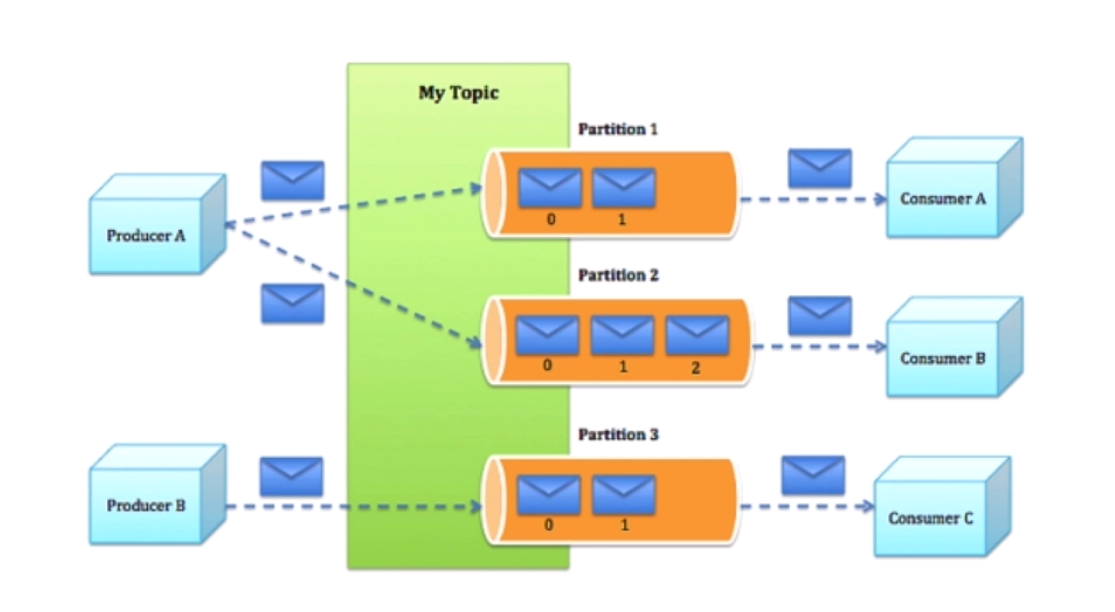
(2) Kafka es un proyecto Apache, un sistema de colas de mensajes de publicación y suscripción distribuido y de alto rendimiento, en varios idiomas.
Diagrama de estructura
Caracteristicas
- Rápido y duradero. La capacidad de persistencia del mensaje se proporciona de una manera con una complejidad de tiempo de O (1), y el rendimiento de acceso de la complejidad de tiempo constante puede garantizarse incluso para datos por encima del nivel de terabytes.
- Alto rendimiento Incluso en máquinas comerciales muy baratas, puede lograr la transmisión de más de 100K mensajes por segundo en una sola máquina. Es un sistema completamente distribuido, su agente, productor y consumidor (consulte la terminología básica) son nativos, admiten automáticamente el equilibrio de carga distribuido y automático, y admite la carga paralela de datos de Hadoop.
- Admite la partición de mensajes entre servidores Kafka y el consumo distribuido, al tiempo que garantiza la transmisión secuencial de mensajes dentro de cada partición.
- También es compatible con el procesamiento de datos fuera de línea y el procesamiento de datos en tiempo real.
- Escalar horizontalmente: admite la expansión horizontal en línea.
Terminología básica
- Intermediario: el clúster de Kafka contiene uno o más servidores, que se denominan intermediarios.
- Tema: Cada mensaje publicado en el clúster Kafka tiene una categoría, que se llama Tema. (Físicamente, los mensajes de diferentes temas se almacenan por separado. Aunque lógicamente, los mensajes de un tema se almacenan en uno o más intermediarios, pero los usuarios solo necesitan especificar el tema del mensaje para producir o consumir datos sin tener que preocuparse de dónde se almacenan los datos)
- Partición: la partición es un concepto físico, cada tema contiene una o más particiones.
- Productor: responsable de publicar mensajes al agente Kafka.
- Consumidor: un consumidor de mensajes, un cliente que lee mensajes del agente Kafka.
- Grupo de consumidores: cada consumidor pertenece a un grupo de consumidores específico (puede especificar el nombre del grupo para cada consumidor, si no especifica el nombre del grupo, pertenece al grupo predeterminado).
(3) A continuación, echemos un vistazo a RabbitMQ.
Diagrama de estructura
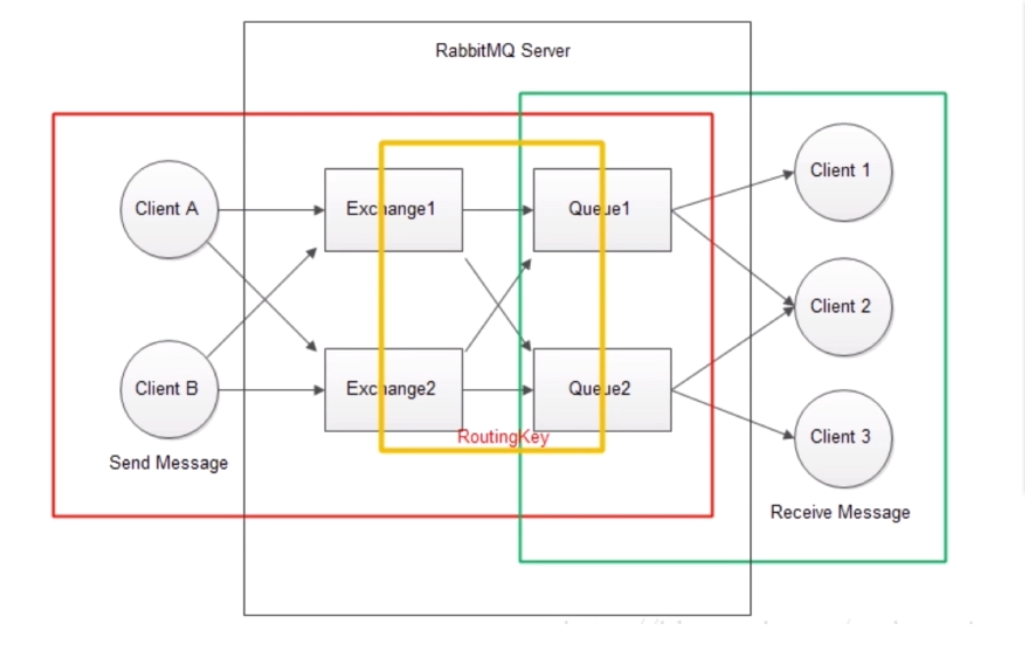
Definición básica en RabbitMQ
Servidor RabbitMQ : proporciona un procesamiento de mensajes del productor al consumidor.
Intercambio : envíe mensajes a la cola mientras recibe mensajes del editor.
Los productores solo pueden enviar mensajes para intercambiar. El intercambio es responsable de enviar mensajes a las colas. El mensaje de Procuder Publish ingresa al intercambio. Exchange procesará el mensaje recibido de acuerdo con la clave de enrutamiento, determinará si el mensaje debe enviarse a la cola especificada o a varias colas, o simplemente ignorará el mensaje. Estas reglas están definidas por el tipo de intercambio (tipo de intercambio). Los tipos principales son directo, tema, encabezados y fanout. Use diferentes tipos para diferentes escenarios.
La cola también está vinculada por las claves de enrutamiento. El conmutador coincidirá con precisión con la clave de enlace y la clave de enrutamiento para determinar a qué cola se debe distribuir el mensaje.
Cola : cola de mensajes. Reciba el mensaje del intercambio, y luego lo saque el consumidor. El intercambio y la cola pueden ser uno a uno o uno a muchos, y su relación está vinculada por routingKey.
Productor : Cliente A y B, productor, la fuente del mensaje, el mensaje debe enviarse al intercambio. En lugar de ir directamente a la cola.
Consumidor : los clientes del cliente 1, 2, 3 reciben mensajes directamente de la cola para consumo, en lugar de recibir mensajes del intercambio por consumo.
(4) Kafka y rabbitmq usan springboot como ejemplo. Para simplificar el contenido, los dos ejecutan la prueba al mismo tiempo.
Para la instalación de kafka en Windows, consulte: https://www.jianshu.com/p/d64798e81f3b
Arquitectura del paquete

KafkaReceiver.java
import lombok.extern.slf4j.Slf4j;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Component;
/**
* 接收端
*/
@Component
@Slf4j
public class KafkaReceiver {
@KafkaListener(topics={TopicConstants.TEST})
public void receive(ConsumerRecord<?,?> record){
log.info("record:{}",record);
}
}
KafkaSender.java
import com.google.gson.Gson;
import com.google.gson.GsonBuilder;
import com.practice.mq.Message;
import lombok.extern.slf4j.Slf4j;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.stereotype.Component;
import javax.annotation.Resource;
import java.util.Date;
/**
* 发送端
*/
@Component
@Slf4j
public class KafkaSender {
@Resource
private KafkaTemplate<String,String> kafkaTemplate;
private Gson gson = new GsonBuilder().create();
public void send(String msg) {
Message message = new Message();
message.setId(System.currentTimeMillis());
message.setMsg(msg);
message.setSendTime(new Date());
log.info("send Message:{}",message);
kafkaTemplate.send(TopicConstants.TEST,gson.toJson(message));
}
}
TopicConstants.java
public interface TopicConstants {
//定义一下我们需要使用Topic的字符串
String TEST = "test";
String MESSAGE = "message";
}
QueuesContants.java
public interface QueuesConstants {
String TEST="test";
String MESSAGE="message";
}
RabbitMQClient.java
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.stereotype.Component;
import javax.annotation.Resource;
@Component
public class RabbitMQClient {
@Resource
private RabbitTemplate rabbitTemplate;
public void send(String message){
//发送到指定队列
rabbitTemplate.convertAndSend(QueuesConstants.TEST,message);
}
}
RabbitMQServer.java
import org.springframework.amqp.core.Queue;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class RabbitMQConfig {
@Bean
public Queue queue(){
//定义好要发送的队列
return new Queue(QueuesConstants.TEST);
}
}
Message.java
import lombok.Data;
import java.util.Date;
@Data
public class Message {
private Long id;
private String msg;
private Date sendTime;
}
MQController.java
import com.practice.mq.kafka.KafkaSender;
import com.practice.mq.rabbitmq.RabbitMQClient;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.ResponseBody;
import javax.annotation.Resource;
@Controller
@RequestMapping("/mq")
public class MQController {
@Resource
private RabbitMQClient rabbitMQClient;
@Resource
private KafkaSender kafkaSender;
@RequestMapping("/send")
@ResponseBody
public String send(){
String message = "message";
rabbitMQClient.send(message);
kafkaSender.send(message);
return "success";
}
}
Dependencias de Maven utilizadas (aquí combinadas con springboot)
<!--kafka-->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<!--Gson-->
<dependency>
<groupId>com.google.code.gson</groupId>
<artifactId>gson</artifactId>
<version>2.7</version>
</dependency>
<!-- rabbitmq依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>
configuración de application.properties
#============== kafka ===================
# 指定kafka server的地址,集群配多个,中间,逗号隔开
spring.kafka.bootstrap-servers=127.0.0.1:9092
spring.kafka.consumer.group-id=test
#=============== provider =======================
# 写入失败时,重试次数。当leader节点失效,一个repli节点会替代成为leader节点,此时可能出现写入失败,
# 当retris为0时,produce不会重复。retirs重发,此时repli节点完全成为leader节点,不会产生消息丢失。
spring.kafka.producer.retries=0
# 每次批量发送消息的数量,produce积累到一定数据,一次发送
spring.kafka.producer.batch-size=16384
# produce积累数据一次发送,缓存大小达到buffer.memory就发送数据
spring.kafka.producer.buffer-memory=33554432
#procedure要求leader在考虑完成请求之前收到的确认数,用于控制发送记录在服务端的持久化,其值可以为如下:
#acks = 0 如果设置为零,则生产者将不会等待来自服务器的任何确认,该记录将立即添加到套接字缓冲区并视为已发送。在这种情况下,无法保证服务器已收到记录,并且重试配置将不会生效(因为客户端通常不会知道任何故障),为每条记录返回的偏移量始终设置为-1。
#acks = 1 这意味着leader会将记录写入其本地日志,但无需等待所有副本服务器的完全确认即可做出回应,在这种情况下,如果leader在确认记录后立即失败,但在将数据复制到所有的副本服务器之前,则记录将会丢失。
#acks = all 这意味着leader将等待完整的同步副本集以确认记录,这保证了只要至少一个同步副本服务器仍然存活,记录就不会丢失,这是最强有力的保证,这相当于acks = -1的设置。
#可以设置的值为:all, -1, 0, 1
spring.kafka.producer.acks=1
# 指定消息key和消息体的编解码方式
spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializer
spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer
El navegador ejecuta la consola " http://127.0.0.1:8090/mq/send"
para imprimir
rabbitmq :
...
2020-04-19 02:09:12.040 INFO 31676 --- [nio-8090-exec-1] com.practice.mq.kafka.KafkaSender : send Message:Message(id=1587233352040, msg=message, sendTime=Sun Apr 19 02:09:12 GMT+08:00 2020)
2020-04-19 02:09:12.048 INFO 31676 --- [cTaskExecutor-1] com.practice.mq.rabbitmq.RabbitMQServer : message:message
2020-04-19 02:09:12.054 INFO 31676 --- [nio-8090-exec-1] o.a.k.clients.producer.ProducerConfig : ProducerConfig values:
kafka :
...
2020-04-19 02:09:12.070 INFO 31676 --- [nio-8090-exec-1] o.a.kafka.common.utils.AppInfoParser : Kafka version : 2.0.0
2020-04-19 02:09:12.070 INFO 31676 --- [nio-8090-exec-1] o.a.kafka.common.utils.AppInfoParser : Kafka commitId : 3402a8361b734732
2020-04-19 02:09:12.076 INFO 31676 --- [ad | producer-1] org.apache.kafka.clients.Metadata : Cluster ID: i1-NXUmvQRyaT-E27LPozQ
2020-04-19 02:09:12.106 INFO 31676 --- [ntainer#0-0-C-1] com.practice.mq.kafka.KafkaReceiver : record:ConsumerRecord(topic = test, partition = 0, offset = 5, CreateTime = 1587233352082, serialized key size = -1, serialized value size = 73, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = {"id":1587233352040,"msg":"message","sendTime":"Apr 19, 2020 2:09:12 AM"})
OK, entonces el simple ejemplo de estas dos colas ha terminado.