Aprendizaje semi-supervisado (SSL) SOTA ha sido actualizado por Google una y otra vez, comenzando desde MixMatch, a UDA y ReMixMatch en el mismo período, y luego a FixMatch en 2020.
Estos cuatro artículos sobre aprendizaje semi-supervisado profundo comienzan a partir de los dos aspectos de regularización de consistencia y minimización de entropía:
- Regularización de consistencia: consistencia, inyectando ruido en la imagen de entrada o en la capa intermedia, la salida del modelo debe mantenerse tan constante o aproximada como sea posible.
- minimización de entropía: minimice la entropía La entropía del modelo en datos sin etiquetar debe minimizarse tanto como sea posible. La pseudo etiqueta también utiliza implícitamente la minimización de entropía.
Regularización de consistencia
Para cada instancia no etiquetada, la regularización de consistencia requiere que la salida de dos ruidos inyectados aleatoriamente sea aproximada.
Para la regularización de la consistencia, cómo inyectar ruido y cómo calcular la aproximación es la diferencia entre cada método. El ruido de inyección puede ser a través del modelo en sí (como el abandono) o agregando ruido (como el ruido gaussiano), o mediante el aumento de datos; el método de cálculo de consistencia puede ser L2, divergencia KL, entropía cruzada
Minimización de entropía
MixMatch, UDA y ReMixMatch usan la minimización de la entropía indirectamente a través del afilado de la temperatura, mientras que FixMatch usa la minimización de la entropía indirectamente a través de la etiqueta Pseudo. O puede considerarse que la minimización de entropía se usa siempre que se obtenga mediante la obtención de etiquetas artificiales de datos no etiquetados y luego se entrene de acuerdo con métodos de aprendizaje supervisados (como la pérdida de entropía cruzada). La minimización de la entropía se puede lograr calculando la pérdida y la regularización de la coherencia de la parte de datos sin etiquetar.
Tanto la nitidez de temperatura como la pseudoetiqueta obtienen etiquetas artificiales de datos sin etiquetar. Cuando la temperatura = 0 del primero, los dos son iguales. La pseudo etiqueta es más simple que el afilado de la temperatura porque hay un hiperparámetro de temperatura menos.
Si no utiliza la minimización de entropía, el afilado de temperatura y la pseudoetiqueta son realmente innecesarios, y solo necesita inyectar aleatoriamente la instancia de ruido sin etiquetar dos veces para aproximar la salida para garantizar la regularización de la consistencia.
En otras palabras, obtener etiquetas artificiales para datos sin etiquetar puede hacer que la entropía se minimice y la regularización de la consistencia a través de una pérdida.
结合 Regularización de consistencia 和 Minimización de entropía
En términos generales, los datos no etiquetados en el aprendizaje semi-supervisado utilizarán todos los conjuntos de datos de entrenamiento, es decir, las muestras etiquetadas también se utilizarán como muestras no etiquetadas.
En el aprendizaje semi-supervisado, se dan todas las etiquetas de los datos etiquetados, mientras que las etiquetas de los datos no etiquetados no se conocen. Entonces, cómo obtener la etiqueta artificial de datos sin etiquetar, las prácticas de MixMatch, UDA, ReMixMatch y FixMatch son más o menos diferentes:
- MixMatch: predicciones de predicción de K promedio de aumento débil (como desplazamiento y volteo), y luego se agudizan la temperatura;
- UDA: una predicción de aumento débil, y luego agudización de la temperatura;
- ReMixMatch: una predicción de aumento débil, luego alineación de distribución y finalmente agudización de la temperatura;
- FixMatch: una predicción de aumento débil, y luego one-hot obtiene la etiqueta rígida.
Con las etiquetas artificiales, podemos entrenar de una manera supervisada de aprendizaje. Esta forma de pensar utiliza la minimización de la entropía. Desde la perspectiva de la regularización de la consistencia de los datos no etiquetados, necesitamos inyectar diferentes ruidos para hacer que las predicciones de los datos no etiquetados sean consistentes con sus etiquetas artificiales.
MixMatch, UDA, ReMixMatch y FixMatch utilizan el aumento de datos para cambiar las muestras de entrada para inyectar ruido. La diferencia es el método específico y la fuerza del aumento de datos:
- MixMatch: un aumento débil obtiene predicción, que es lo mismo que el entrenamiento supervisado normal, excepto que la pérdida no etiquetada usa L2;
- UDA: un fuerte aumento (RandAugment) obtiene predicción;
- ReMixMatch: el aumento fuerte múltiple (CTAugment) obtiene predicciones y luego participa en el cálculo de la pérdida sin etiquetar, es decir, una instancia sin etiquetar y un paso se calculan después de múltiples mejoras;
- FixMatch: Un fuerte aumento (RandAugment o CTAugment) obtiene predicción.
A partir de UDA y ReMixMatch, un fuerte aumento introdujo capacitación semi-supervisada. UDA utiliza el método de aumento fuerte de RandAugment propuesto por el autor, y ReMixMatch propone un CTAugment. FixMatch utilizó el fuerte aumento utilizado en UDA y ReMixMatch.
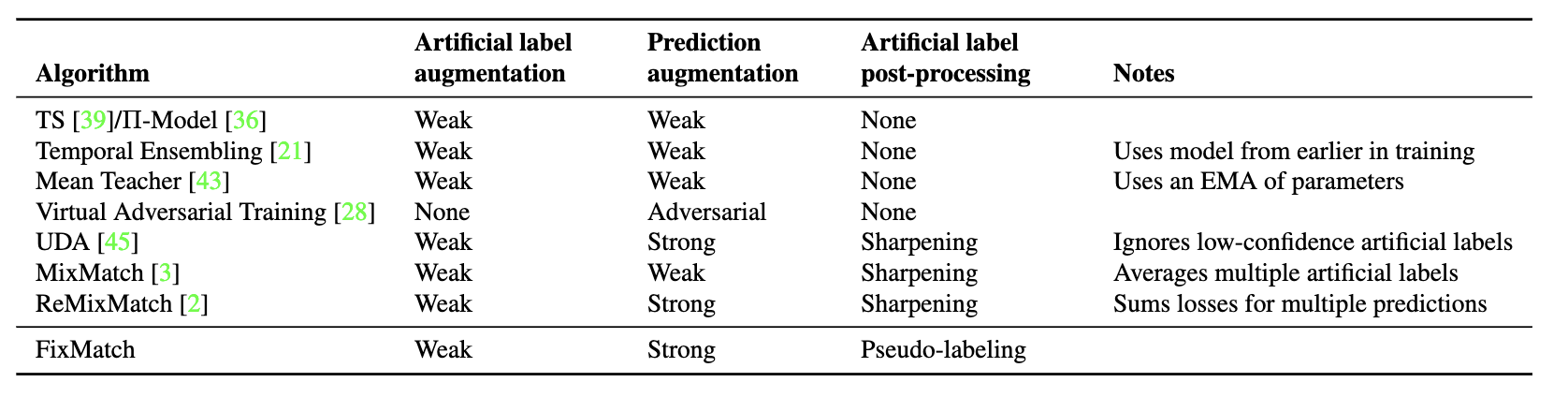
Por la pérdida de la parte de datos sin etiquetar:
- MixMatch: pérdida de L2 2
- UDA : KL divergencia ;
- ReMixMatch: entropía cruzada (incluida la pérdida de rotación auto supervisada y la pérdida sin etiquetar previa a la mezcla sin mezcla);
- FixMatch: entropía cruzada con umbral.
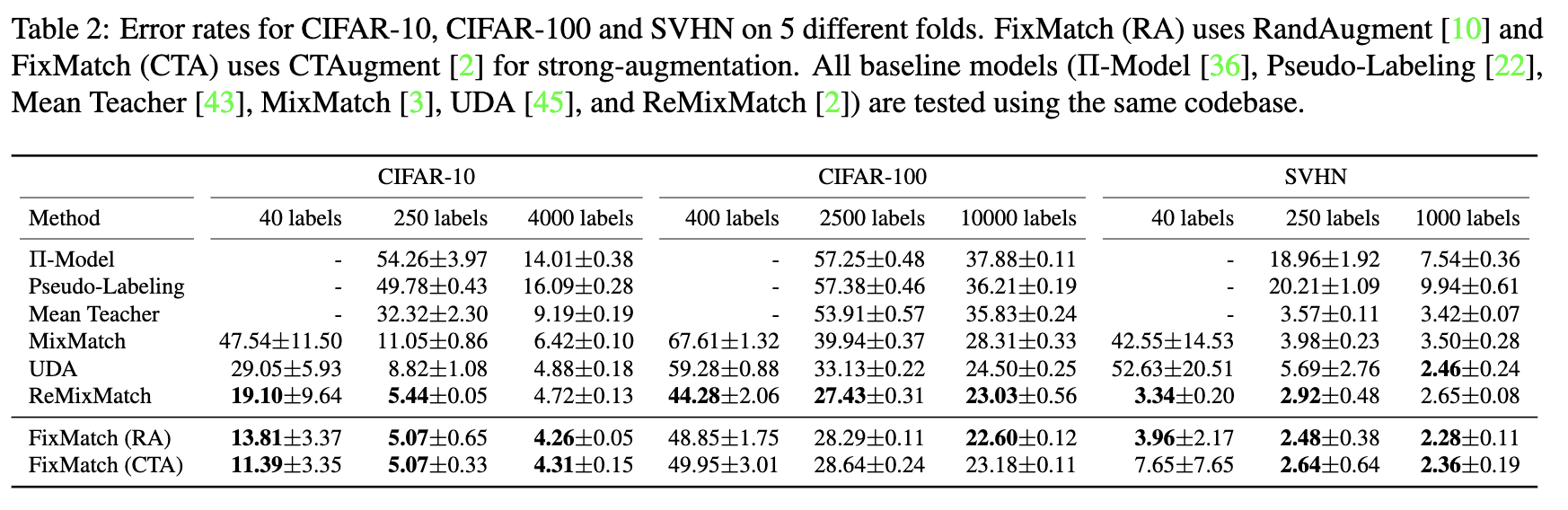
FixMatch: simplificando SSL con consistencia y confianza
FixMatch simplifica MixMatch, UDA y ReMixMatch, y luego obtiene mejores resultados:
- Primero, el afilado de la temperatura se reemplaza por una pseudo etiqueta, que es una simplificación;
- En segundo lugar, FixMatch establece un umbral para calcular la pérdida no etiquetada para instancias sin etiqueta donde la confianza de la predicción excede el umbral al calcular la pérdida no etiquetada, de modo que el peso de la pérdida no etiquetada se puede arreglar, que es la segunda simplificación.
Referencias
[1] Berthelot, D., Carlini, N., Goodfellow, I., Papernot, N., Oliver, A., Raffel, C. (2019). MixMatch: un enfoque holístico para el aprendizaje semi-supervisado arXiv https://arxiv.org/abs/1905.02249
[2] Berthelot, D., Carlini, N., Cubuk, E., Kurakin, A., Sohn, K., Zhang, H., Raffel, C. (2019). ReMixMatch: Aprendizaje semi-supervisado con alineación de distribución y anclaje de aumento arXiv https://arxiv.org/abs/1911.09785
[3] Xie, Q., Dai, Z., Hovy, E., Luong, M., Le, Q . (2019). Aumento de datos sin supervisión para el entrenamiento de coherencia arXiv https://arxiv.org/abs/1904.12848
[4] Sohn, K., Berthelot, D., Li, C., Zhang, Z., Carlini, N., Cubuk, E., Kurakin, A., Zhang, H., Raffel, C. (2020) . FixMatch: Simplificando el aprendizaje semi-supervisado con consistencia y confianza arXiv https://arxiv.org/abs/2001.07685