Este artículo es la parte final de la serie "CDH + Kylin Trilogy", primero revise brevemente el contenido anterior:
- "CDH + Kylin Trilogy One: Preparación" : prepare la máquina, el script y el paquete de instalación;
- "CDH + Kylin Trilogy Part Two: Implementación y configuración" : Complete la implementación de CDH y Kylin, y realice las configuraciones relacionadas en la página de administración;
Ahora que Hadoop y Kylin están listos, practiquemos la demostración oficial de Kylin;
Ajuste de parámetros de hilo
Después de establecer los parámetros de memoria de Yarn, Yarn debe reiniciarse para que surta efecto; de lo contrario, las tareas enviadas por Kylin no se ejecutarán debido a limitaciones de recursos;
Acerca de la demostración oficial de Kylin
- La siguiente figura es parte del script de demostración oficial (create_sample_tables.sql), que crea una tabla Hive basada en datos HDFS:
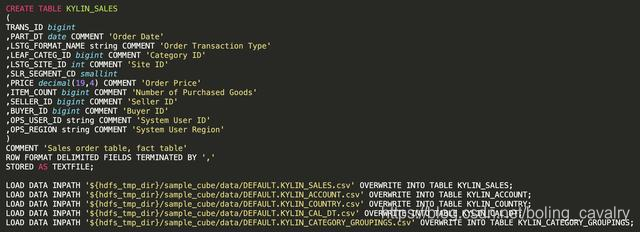
- Se puede ver en el script que KYLIN_SALES es la tabla de hechos, el otro es la tabla de dimensiones, y KYLIN_ACCOUNT y KYLIN_COUNTRY están relacionados, por lo que el modelo de dimensión se ajusta al Esquema de copo de nieve;
Importar datos de muestra
- SSH al servidor CDH
- Cambiar a la cuenta hdfs: su-hdfs
- Ejecute el comando de importación: $ {KYLIN_HOME} /bin/sample.sh
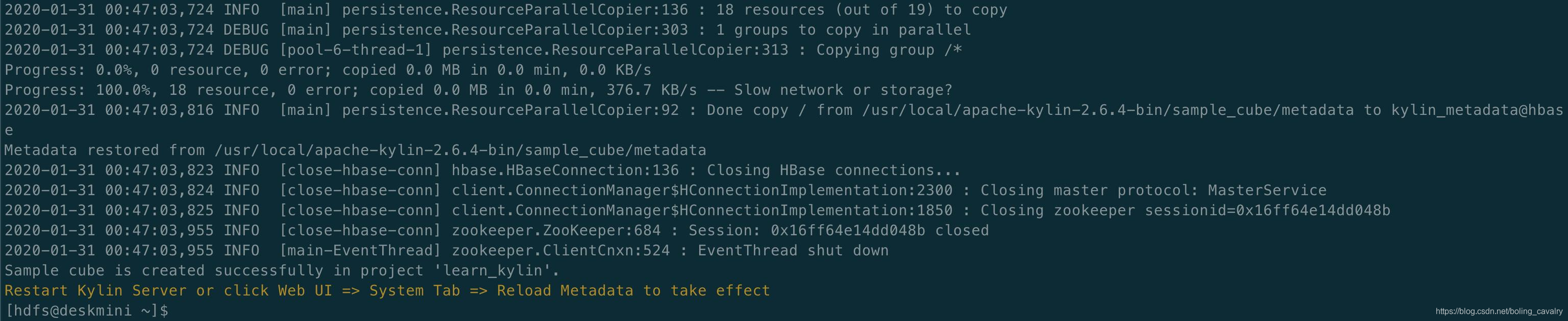
- La importación es exitosa y la salida de la consola es la siguiente:
Verificar los datos
- Verifique los datos y ejecute Beeline para ingresar al modo de sesión ( Hive recomienda oficialmente usar Beeline en lugar de Hive CLI):

- En el modo de sesión beeline, ingrese la URL del enlace :! Connect jdbc: hive2: // localhost: 10000 , siga las instrucciones para ingresar los hdfs de la cuenta e ingrese la contraseña directamente:
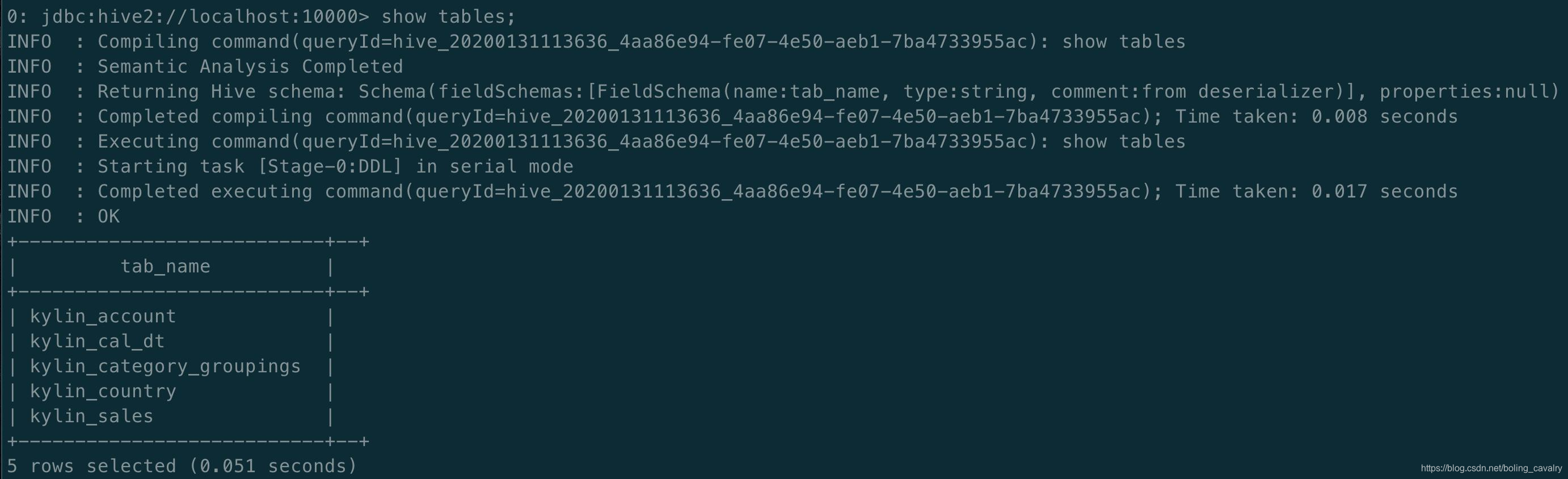
- Use el comando show tables para ver la tabla de colmena actual, que se ha creado:
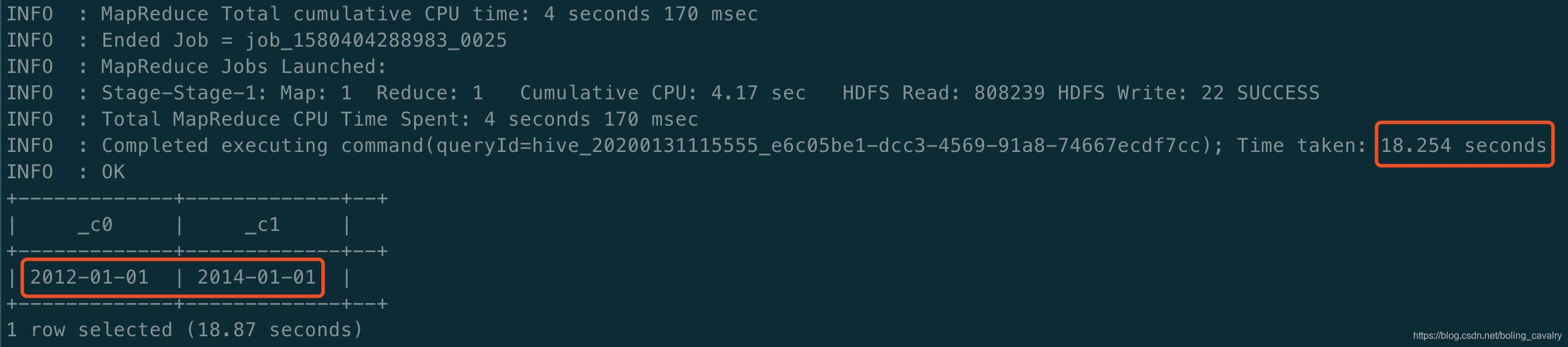
- Averiguar el orden de los tiempos más próximas y más, de vuelta cuando el cubo se utiliza para construir, ejecutar SQL: el min SELECT (PART_DT), máx (PART_DT) de kylin_sales; y visible primeros 2012-01-01 , la última 2014-01- 01 , la consulta completa tomó 18.87 segundos :
Construir cubo:
Una vez completada la preparación de datos, se puede construir el Cubo Kylin:
- Inicie sesión en la página web de Kylin: http://192.168.50.134:7070/kylin
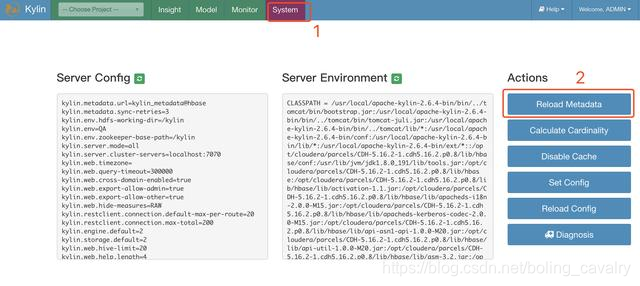
- Cargue metadatos, como se muestra a continuación:
- Como se muestra en el cuadro rojo a continuación, los datos se cargan correctamente:
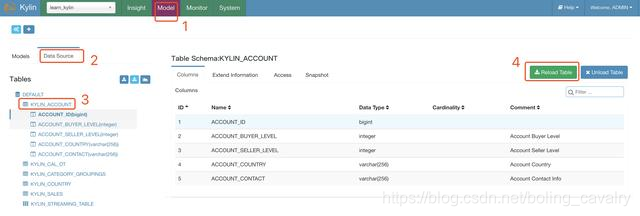
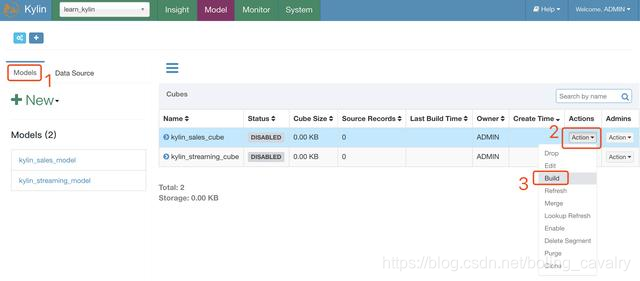
- Puede ver la tabla de hechos y la tabla de dimensiones en la página Modelo. Las operaciones en la siguiente figura pueden crear una tarea MapReduce y calcular la cardinalidad de cada columna de la tabla de dimensiones KYLIN_ACCOUNT:
- Vaya a la página Yarn (puerto 8088 del servidor CDH), como se muestra en la figura a continuación, puede ver que se está ejecutando una tarea de tipo MapReduce:
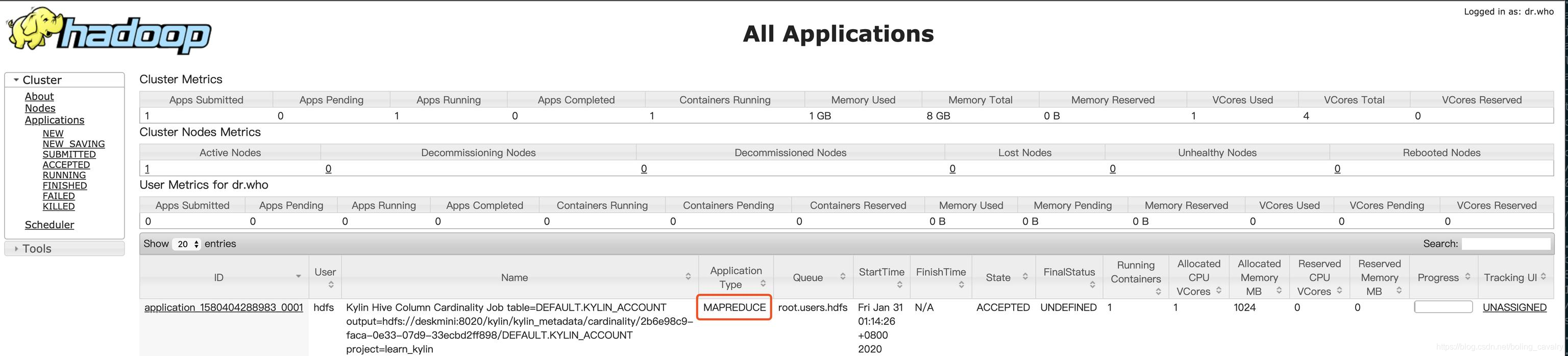
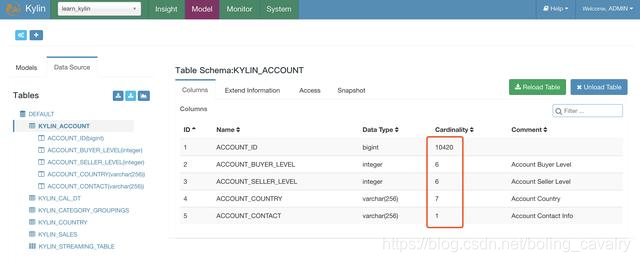
- La tarea anterior se puede completar pronto (más de 10 segundos). En este momento, actualice la página Kylin. Se puede ver que los datos de Cardinalidad de la tabla KYLIN_ACCOUNT se han calculado (el número de ACCOUNT_ID obtenidos por la consulta de la colmena es de 10000, pero el valor de Cardinalidad en la siguiente figura es 10420. El cálculo utiliza el algoritmo aproximado de HyperLogLog, que no es exacto con el valor exacto, y la cardinalidad de los otros cuatro campos es consistente con el resultado de la consulta de Hive):
- Luego, comienza a construir Cube:
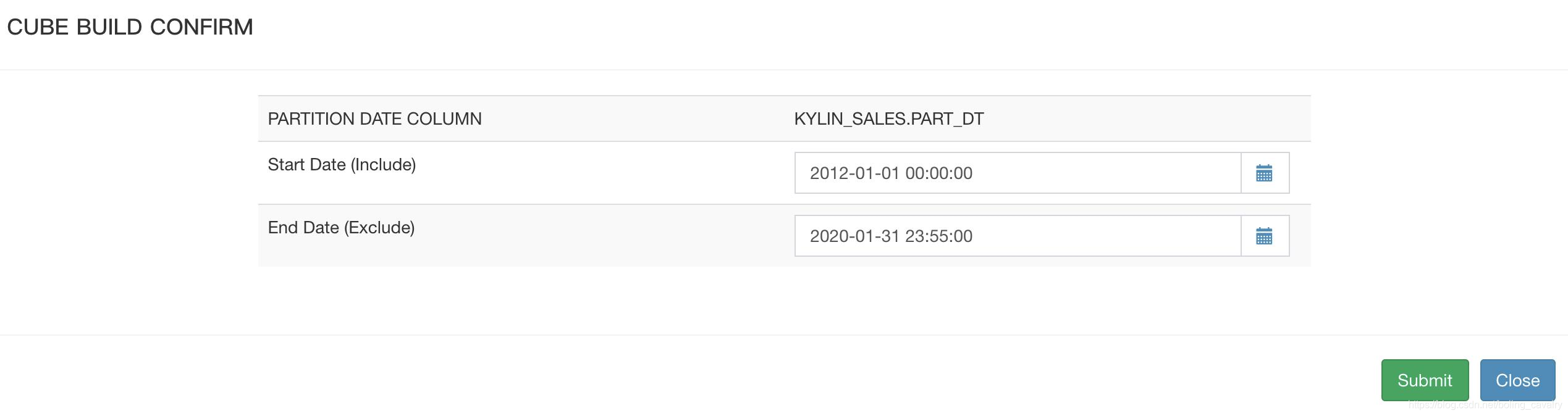
- rango de fechas, justo Colmena resultado de la consulta 2012-01-01 a 01/01/2014 , nota que el plazo exceda 01/01/2014:
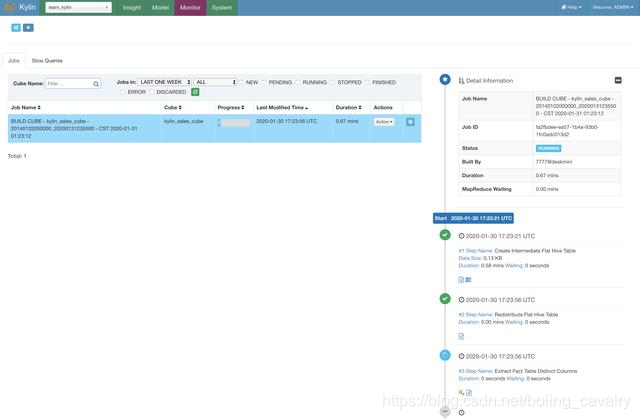
- El progreso se puede ver en la página Monitor:
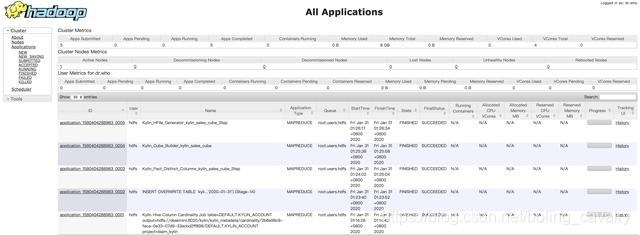
- Vaya a la página Yarn (puerto 8088 del servidor CDH), puede ver las tareas correspondientes y el uso de recursos:
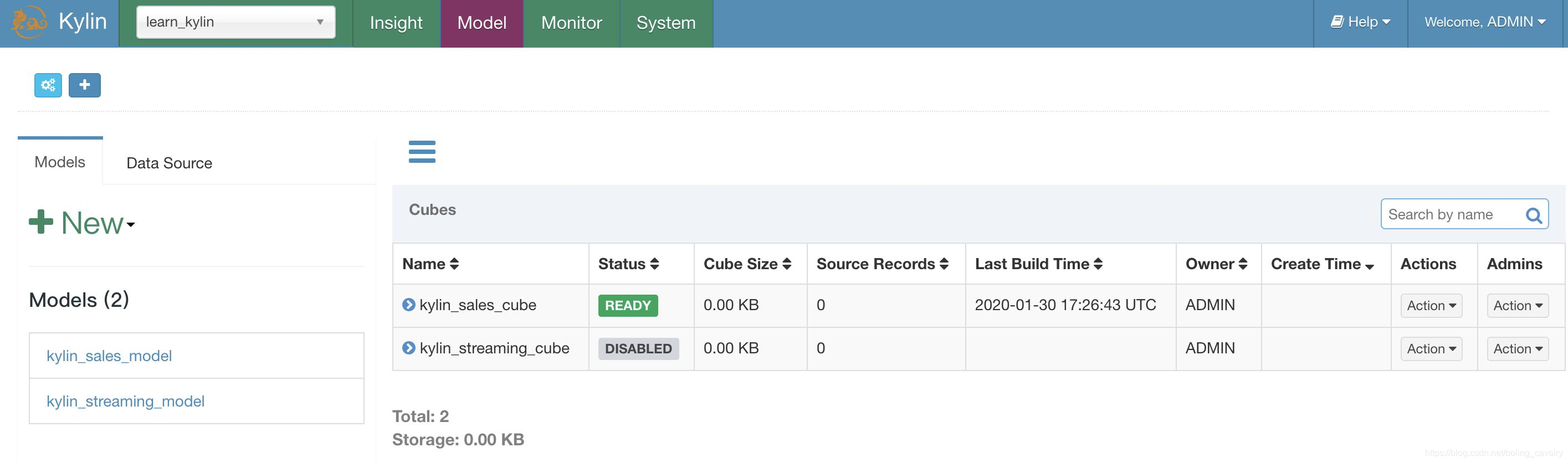
- Una vez completada la compilación, aparecerá el ícono listo:
Consultas
- Primero intente consultar el tiempo más temprano y más reciente de la transacción. El tiempo necesario para ejecutar esta consulta en Hive es de 18.87 segundos . Como se muestra en la figura a continuación, los resultados son consistentes y el tiempo es de 0.14 segundos :

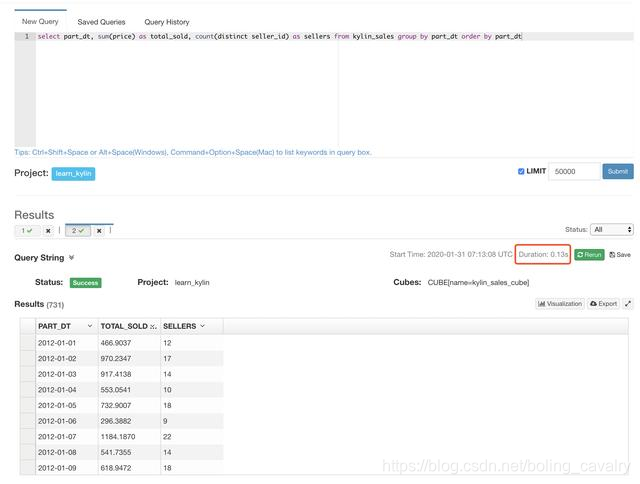
- El siguiente SQL es un ejemplo oficial de Kylin que se usa para comparar el tiempo de respuesta.
select part_dt, sum(price) as total_sold, count(distinct seller_id) as sellers from kylin_sales group by part_dt order by part_dt;
- La consulta de Kylin tarda 0,13 segundos :
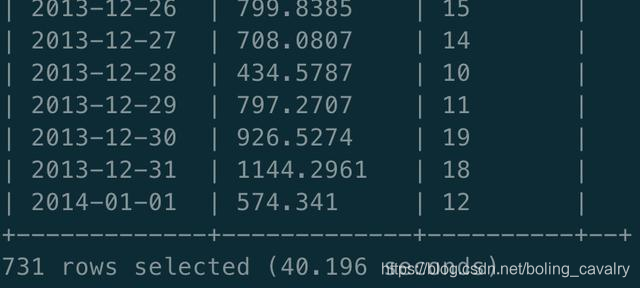
- Consulta de la colmena, el resultado es el mismo, tarda 40.196 segundos :
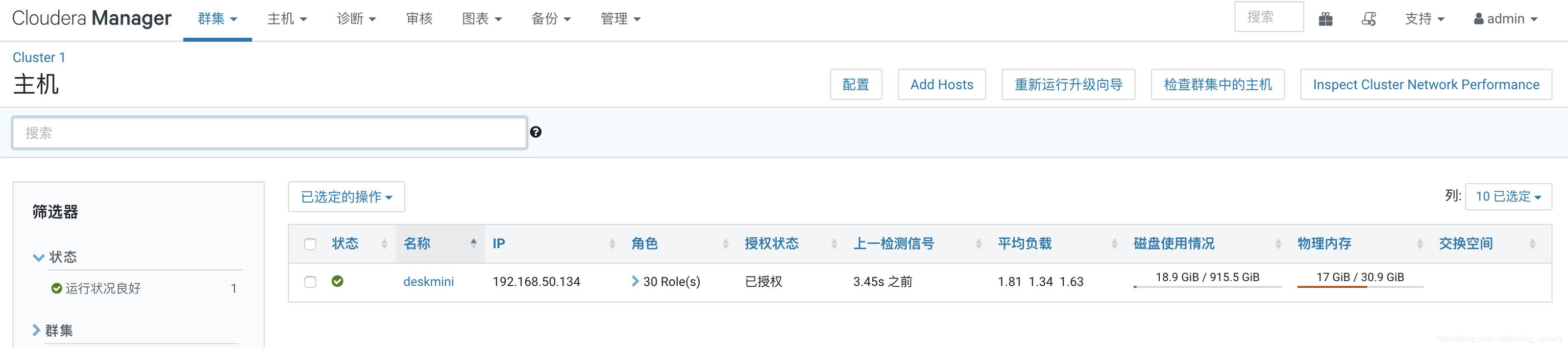
- Finalmente, echemos un vistazo al uso de los recursos. Durante la construcción del Cubo, se utilizan 18G de memoria:
en este punto, CDH + Kylin se completa desde la implementación hasta la experiencia. La serie "CDH + Kylin Trilogy" también ha terminado. Espero que este artículo te pueda dar alguna referencia.
