Este artículo es el segundo de una serie de "Trilogía DataSource de Flink". El artículo anterior "Una de la Trilogía DataSource de Flink: API directa" aprendió la API de StreamExecutionEnvironment para crear un DataSource. Lo que quiero practicar hoy es el conector incorporado de Flink Es decir, la posición del cuadro rojo en la siguiente figura. Estos conectores se pueden usar a través del método addSource de StreamExecutionEnvironment:
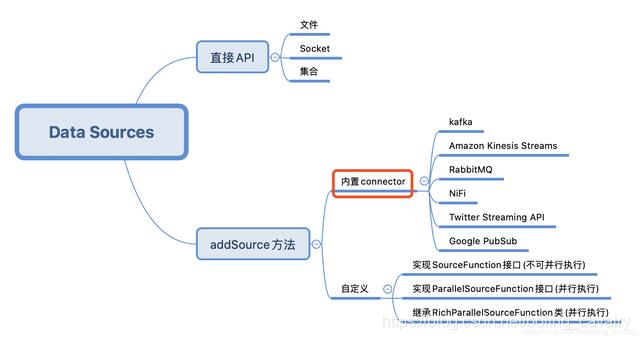
el combate real de hoy elige a Kafka como fuente de datos para operar, primero intenta recibir y procesar mensajes de cadena, luego recibe mensajes JSON y revierte el JSON En una instancia de bean;
Enlace del artículo de la trilogía DataSource de Flink
- "Una de la trilogía DataSource de Flink: API directa"
- "Trilogía DataSource de Flink, segunda parte: conector incorporado"
- "Trilogía de DataSource de Flink, tercera parte: personalización"
Descarga del código fuente
Si no desea escribir código, puede descargar el código fuente de toda la serie desde GitHub. La dirección y la información del enlace se muestran en la siguiente tabla (https://github.com/zq2599/blog_demos):
| El nombre | Enlace | Observaciones |
|---|---|---|
| Página de inicio del proyecto | https://github.com/zq2599/blog_demos | La página de inicio del proyecto en GitHub |
| dirección del repositorio de git (https) | https://github.com/zq2599/blog_demos.git | La dirección del almacén del código fuente del proyecto, protocolo https |
| dirección de repositorio de git (ssh) | [email protected]: zq2599 / blog_demos.git | La dirección del almacén del código fuente del proyecto, protocolo ssh |
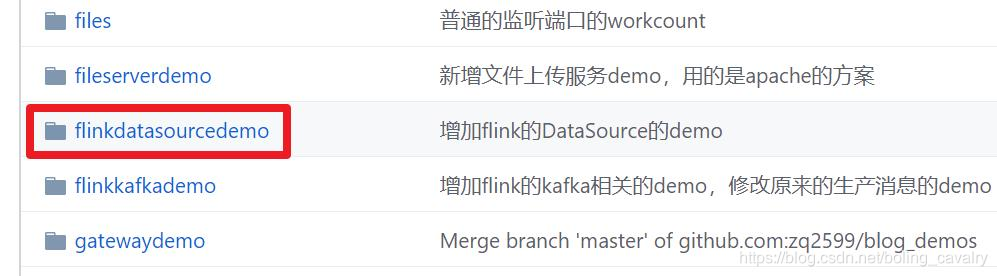
Hay varias carpetas en este proyecto git. La aplicación de este capítulo se encuentra en la carpeta flinkdatasourcedemo , como se muestra en el cuadro rojo a continuación:
Entorno y versión
El entorno y la versión de este combate real son los siguientes:
- JDK: 1.8.0_211
- Fuerte : 1.9.2
- Maven: 3.6.0
- Sistema operativo: macOS Catalina 10.15.3 (MacBook Pro de 13 pulgadas, 2018)
- IDEA: 2018.3.5 (Ultimate Edition)
- Kafka : 2.4.0
- Zookeeper : 3.5.5
Asegúrate de que el contenido anterior esté listo antes de poder continuar el combate real;
Flink coincide con la versión Kafka
- El oficial de Flink hizo una descripción detallada de la versión coincidente de Kafka, la dirección es: https://ci.apache.org/projects/flink/flink-docs-stable/dev/connectors/kafka.html
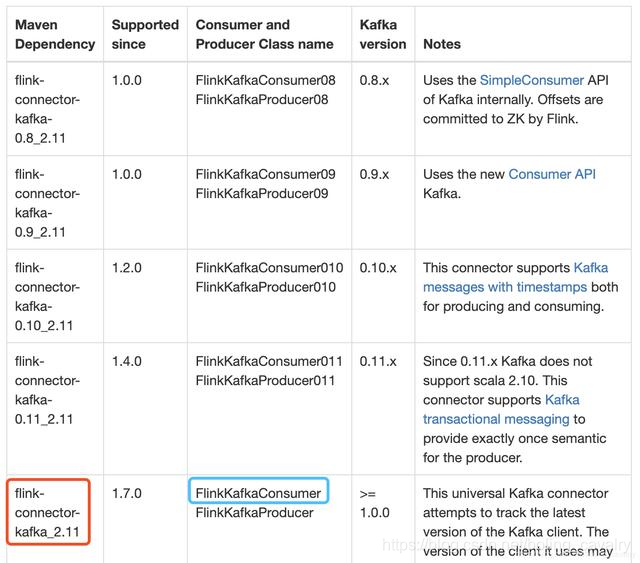
- La atención se centra en el conector Kafka universal mencionado oficialmente, que se lanzó desde Flink 1.7 y se puede usar para Kafka 1.0.0 o superior:

- El cuadro rojo en la imagen a continuación es la biblioteca de la que depende mi proyecto, y el cuadro azul es la clase utilizada para conectar Kafka. Los lectores pueden encontrar la biblioteca y la clase adecuadas en la tabla según su versión de Kafka:
Procesamiento real de mensajes de cadena
- Cree un tema llamado test001 en kafka, consulte el comando:
./kafka-topics.sh \
--create \
--zookeeper 192.168.50.43:2181 \
--replication-factor 1 \
--partitions 2 \
--topic test001
- Continúe usando el proyecto flinkdatasourcedemo creado en el capítulo anterior, abra el archivo pom.xml y agregue las siguientes dependencias:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.11</artifactId>
<version>1.10.0</version>
</dependency>
- Se agregó la clase Kafka240String.java, que se utiliza para conectarse al intermediario y realizar la operación WordCount en el mensaje de cadena recibido:
package com.bolingcavalry.connector;
import com.bolingcavalry.Splitter;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import java.util.Properties;
import static com.sun.tools.doclint.Entity.para;
public class Kafka240String {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//设置并行度
env.setParallelism(2);
Properties properties = new Properties();
//broker地址
properties.setProperty("bootstrap.servers", "192.168.50.43:9092");
//zookeeper地址
properties.setProperty("zookeeper.connect", "192.168.50.43:2181");
//消费者的groupId
properties.setProperty("group.id", "flink-connector");
//实例化Consumer类
FlinkKafkaConsumer<String> flinkKafkaConsumer = new FlinkKafkaConsumer<>(
"test001",
new SimpleStringSchema(),
properties
);
//指定从最新位置开始消费,相当于放弃历史消息
flinkKafkaConsumer.setStartFromLatest();
//通过addSource方法得到DataSource
DataStream<String> dataStream = env.addSource(flinkKafkaConsumer);
//从kafka取得字符串消息后,分割成单词,统计数量,窗口是5秒
dataStream
.flatMap(new Splitter())
.keyBy(0)
.timeWindow(Time.seconds(5))
.sum(1)
.print();
env.execute("Connector DataSource demo : kafka");
}
}
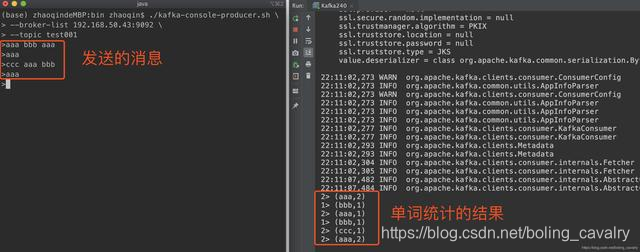
- Asegúrese de que se haya creado el tema de kafka, ejecute Kafka240, la función de consumir mensajes y contar palabras es normal:
- Se ha completado el combate real de recibir mensajes de cadena kafka, luego intente mensajes en formato JSON;
Procesamiento de mensajes JSON de combate real
- El mensaje en formato JSON que se aceptará a continuación se puede deserializar en una instancia de bean y se utilizará la biblioteca JSON. Elegí gson;
- Agregue dependencia gson en pom.xml:
<dependency>
<groupId>com.google.code.gson</groupId>
<artifactId>gson</artifactId>
<version>2.8.5</version>
</dependency>
- Agregue la clase Student.java, este es un Bean ordinario, solo dos campos de id y nombre:
package com.bolingcavalry;
public class Student {
private int id;
private String name;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
- Agregue la clase StudentSchema.java, que es una implementación de la interfaz DeserializationSchema. Se utiliza al deserializar JSON en una instancia de Student:
ackage com.bolingcavalry.connector;
import com.bolingcavalry.Student;
import com.google.gson.Gson;
import org.apache.flink.api.common.serialization.DeserializationSchema;
import org.apache.flink.api.common.serialization.SerializationSchema;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import java.io.IOException;
public class StudentSchema implements DeserializationSchema<Student>, SerializationSchema<Student> {
private static final Gson gson = new Gson();
/**
* 反序列化,将byte数组转成Student实例
* @param bytes
* @return
* @throws IOException
*/
@Override
public Student deserialize(byte[] bytes) throws IOException {
return gson.fromJson(new String(bytes), Student.class);
}
@Override
public boolean isEndOfStream(Student student) {
return false;
}
/**
* 序列化,将Student实例转成byte数组
* @param student
* @return
*/
@Override
public byte[] serialize(Student student) {
return new byte[0];
}
@Override
public TypeInformation<Student> getProducedType() {
return TypeInformation.of(Student.class);
}
}
- Se agrega la nueva clase Kafka240Bean.java, que se utiliza para conectar el intermediario, convertir el mensaje JSON recibido en una instancia de Estudiante y contar el número de apariciones de cada nombre. La ventana aún es de 5 segundos:
package com.bolingcavalry.connector;
import com.bolingcavalry.Splitter;
import com.bolingcavalry.Student;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import java.util.Properties;
public class Kafka240Bean {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//设置并行度
env.setParallelism(2);
Properties properties = new Properties();
//broker地址
properties.setProperty("bootstrap.servers", "192.168.50.43:9092");
//zookeeper地址
properties.setProperty("zookeeper.connect", "192.168.50.43:2181");
//消费者的groupId
properties.setProperty("group.id", "flink-connector");
//实例化Consumer类
FlinkKafkaConsumer<Student> flinkKafkaConsumer = new FlinkKafkaConsumer<>(
"test001",
new StudentSchema(),
properties
);
//指定从最新位置开始消费,相当于放弃历史消息
flinkKafkaConsumer.setStartFromLatest();
//通过addSource方法得到DataSource
DataStream<Student> dataStream = env.addSource(flinkKafkaConsumer);
//从kafka取得的JSON被反序列化成Student实例,统计每个name的数量,窗口是5秒
dataStream.map(new MapFunction<Student, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(Student student) throws Exception {
return new Tuple2<>(student.getName(), 1);
}
})
.keyBy(0)
.timeWindow(Time.seconds(5))
.sum(1)
.print();
env.execute("Connector DataSource demo : kafka bean");
}
}
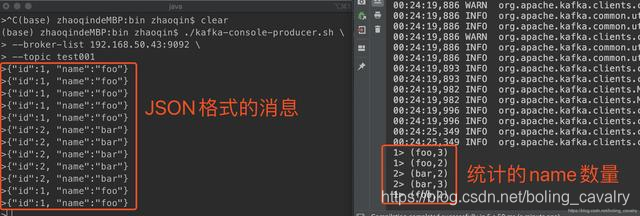
- Durante la prueba, debe enviar cadenas de formato JSON a kafka, y Flink contará el número de cada nombre:
en este punto, se completa la batalla real del conector incorporado. En el próximo capítulo, trabajaremos juntos para personalizar DataSource ;
