1. El número de bytes ocupados por caracteres chinos
Código ASCII:
Las letras inglesas (sin distinción entre mayúsculas y minúsculas) ocupan un byte
Los caracteres chinos ocupan dos bytes
La secuencia de números binarios, como unidad digital en la computadora , es generalmente un número binario de 8 bits, convertido a decimal. El valor mínimo es 0 y el valor máximo es 255. Por ejemplo, un código ASCII es un byte.
Codificación UTF-8:
Caracteres ingleses iguales a un byte
Chino (incluido el tradicional) tres bytes
Codificación Unicode:
Inglés dos bytes
Chino (incluido el tradicional) dos bytes
2. Prueba
public static void main (String [] args) { char c1 = '早' ; System.out.println (c1); char c2 = 'z' ; System.out.println (c2); }
Principios de
z
El tipo char puede almacenar un carácter chino, porque la codificación utilizada en Java es Unicode (no se selecciona una codificación específica, el número del carácter en el conjunto de caracteres se usa directamente), un tipo char ocupa 2 bytes (16 bits), por lo que puede poner uno Chino
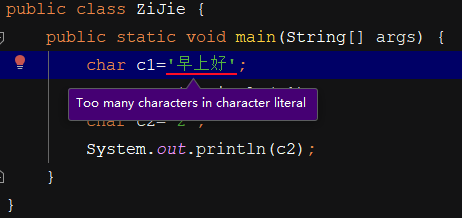
Una variable de tipo char informará un error al almacenar dos o tres caracteres chinos
3. Conversión de codificación
El uso de Unicode significa que los caracteres tienen diferentes expresiones dentro y fuera de la JVM. Ambos son Unicode dentro de la JVM. Cuando este carácter se transfiere de la JVM al exterior (por ejemplo, almacenado en el sistema de archivos), se requiere conversión de codificación. Por lo tanto, hay secuencias de bytes y secuencias de caracteres en Java, y secuencias de conversión que convierten entre secuencias de caracteres y secuencias de bytes, como InputStreamReader y OutputStreamReader. Estas dos clases son clases de adaptador entre secuencias de bytes y secuencias de caracteres. Tarea de conversión de código