Aquí solo se escribe el código de fondo. La idea básica es que el frontend fragmentará el archivo, y luego, cada vez que acceda a la interfaz de carga, pasará los parámetros al backend: el número actual de archivos y el número total de fragmentos.
Peguemos el código directamente debajo. La mayoría de los difíciles se comentan:
Subir clase de entidad de archivo:
Se puede ver que ya hay muchas funciones que necesitamos en la clase de entidad, así como atributos prácticos. Tal como la información transmitida en segundos MD5.
clase pública FileInf {
public FileInf () {}
ID de cadena pública = "";
public String pid = "";
public String pidRoot = "";
/ ** * Indica si el elemento actual es un elemento de carpeta. * /
public boolean fdTask = false;
// /// ¿Es un subarchivo en la carpeta /// </ summary>
public boolean fdChild = false;
/ ** * ID de usuario. Integrarse con sistemas de terceros. * /
public int uid = 0;
/ ** * El nombre del archivo en la computadora local * /
public String nameLoc = "";
/ ** * El nombre del archivo en el servidor. * /
public String nameSvr = "";
/ ** * La ruta completa del archivo en la computadora local. Ejemplo: D: \ Soft \ QQ2012.exe * /
public String pathLoc = "";
/ ** * La ruta completa del archivo en el servidor. Ejemplo: F: \\ ftp \\ uer \\ md5.exe * /
public String pathSvr = "";
/ ** * La ruta relativa del archivo en el servidor. Ejemplo: /www/web/upload/md5.exe * /
public String pathRel = "";
/ ** * Archivo MD5 * /
Cadena pública md5 = "";
/ ** * Longitud del archivo digitalizado. En bytes, ejemplo: 120125 * /
public long lenLoc = 0;
/ ** * Tamaño de archivo formateado. Ejemplo: 10.03MB * /
cadena pública sizeLoc = "";
/ ** * Ubicación de la reanudación del archivo. * /
desplazamiento largo público = 0;
/ ** * Tamaño subido. En bytes * /
public long lenSvr = 0;
/ ** * Porcentaje cargado. Ejemplo: 10% * /
public String perSvr = "0%";
public boolean complete = false;
public Date PostedTime = new Date ();
público booleano eliminado = falso;
/ ** * Ya sea que se haya escaneado o no, se proporciona para su uso en carpetas grandes y el escaneo comienza después de cargar las carpetas grandes. * /
público booleano escaneado = falso;
}
El primero es la lógica de recepción de datos del archivo, que es responsable de recibir los datos del bloque de archivos cargados por el control y luego escribirlos en el archivo del servidor. El control ha proporcionado la información de índice, tamaño, MD5 y longitud del bloque. Podemos manejarlo de manera flexible según nuestras necesidades, y también podemos guardar los datos del bloque de archivos en el sistema de almacenamiento distribuido.
<%
out.clear ();
Cadena uid = request.getHeader ("uid"); //
Cadena id = request.getHeader ("id");
Cadena lenSvr = request.getHeader ("lenSvr");
Cadena lenLoc = request.getHeader ("lenLoc");
Cadena blockOffset = request.getHeader ("blockOffset");
Cadena blockSize = request.getHeader ("blockSize");
Cadena blockIndex = request.getHeader ("blockIndex");
Cadena blockMd5 = request.getHeader ("blockMd5");
Cadena completa = request.getHeader ("completa");
String pathSvr = "";
// El parámetro está vacío.
if (StringUtils.isBlank (uid)
|| StringUtils.isBlank (id)
|| StringUtils.isBlank (blockOffset))
{
XDebug.Output ("el parámetro es nulo");
regreso;
}
// Comprueba que tenemos una solicitud de carga de archivos
boolean isMultipart = ServletFileUpload.isMultipartContent (solicitud);
FileItemFactory factory = new DiskFileItemFactory ();
ServletFileUpload upload = nuevo ServletFileUpload (fábrica);
Lista de archivos = nulo;
tratar
{
archivos = upload.parseRequest (solicitud);
}
catch (FileUploadException e)
{// Error al analizar los datos del archivo
out.println ("error de lectura de datos de archivo:" + e.toString ());
regreso;
}
FileItem rangeFile = null;
// Obtenga todos los archivos cargados
Iterator fileItr = files.iterator ();
// Recorrer todos los archivos
while (fileItr.hasNext ())
{
// obtener el archivo actual
rangeFile = (FileItem) fileItr.next ();
if (StringUtils.equals (rangeFile.getFieldName (), "pathSvr"))
{
pathSvr = rangeFile.getString ();
pathSvr = PathTool.url_decode (pathSvr);
}
}
verificación booleana = falso;
Cadena msg = "";
String md5Svr = "";
long blockSizeSvr = rangeFile.getSize ();
if (! StringUtils.isBlank (blockMd5))
{
md5Svr = Md5Tool.fileToMD5 (rangeFile.getInputStream ());
}
verificar = Integer.parseInt (blockSize) == blockSizeSvr;
si (! verificar)
{
msg = "error de tamaño de bloque sizeSvr:" + blockSizeSvr + "sizeLoc:" + blockSize;
}
if (verifique &&! StringUtils.isBlank (blockMd5))
{
verificar = md5Svr.equals (blockMd5);
si (! verifique) msg = "error de bloque md5";
}
si (verificar)
{
// Guardar datos de bloque de archivo
FileBlockWriter res = new FileBlockWriter ();
// Solo se crea el primer bloque
if (Integer.parseInt (blockIndex) == 1) res.CreateFile (pathSvr, Long.parseLong (lenLoc));
res.write (Long.parseLong (blockOffset), pathSvr, rangeFile);
up6_biz_event.file_post_block (id, Integer.parseInt (blockIndex));
JSONObject o = new JSONObject ();
o.put ("mensaje", "ok");
o.put ("md5", md5Svr);
o.put ("offset", blockOffset); // Posición de desplazamiento de bloque basada en archivo
msg = o.toString ();
}
rangeFile.delete ();
out.write (mensaje);
%>
Sección de inicialización de archivo
<%
out.clear ();
WebBase web = nueva WebBase (pageContext);
Id. De cadena = web.queryString ("id");
Cadena md5 = web.queryString ("md5");
String uid = web.queryString ("uid");
String lenLoc = web.queryString ("lenLoc"); // El tamaño del archivo digitalizado. 12021
String sizeLoc = web.queryString ("sizeLoc"); // El tamaño del archivo formateado. 10MB
Devolución de llamada de cadena = web.queryString ("devolución de llamada");
Cadena pathLoc = web.queryString ("pathLoc");
pathLoc = PathTool.url_decode (pathLoc);
// El parámetro está vacío.
if (StringUtils.isBlank (md5)
&& StringUtils.isBlank (uid)
&& StringUtils.isBlank (sizeLoc))
{
out.write (devolución de llamada + "({\" valor \ ": nulo})");
regreso;
}
FileInf fileSvr = nuevo FileInf ();
fileSvr.id = id;
fileSvr.fdChild = false;
fileSvr.uid = Integer.parseInt (uid);
fileSvr.nameLoc = PathTool.getName (pathLoc);
fileSvr.pathLoc = pathLoc;
fileSvr.lenLoc = Long.parseLong (lenLoc);
fileSvr.sizeLoc = sizeLoc;
fileSvr.deleted = false;
fileSvr.md5 = md5;
fileSvr.nameSvr = fileSvr.nameLoc;
// Todos los archivos individuales se almacenan en uuid / file
PathBuilderUuid pb = new PathBuilderUuid ();
fileSvr.pathSvr = pb.genFile (fileSvr.uid, fileSvr);
fileSvr.pathSvr = fileSvr.pathSvr.replace ("\\", "/");
DBConfig cfg = new DBConfig ();
DBFile db = cfg.db ();
FileInf fileExist = new FileInf ();
boolean exist = db.exist_file (md5, fileExist);
// El mismo archivo ya existe en la base de datos, y hay progreso de carga, luego use esta información directamente
if (existe && fileExist.lenSvr> 1)
{
fileSvr.nameSvr = fileExist.nameSvr;
fileSvr.pathSvr = fileExist.pathSvr;
fileSvr.perSvr = fileExist.perSvr;
fileSvr.lenSvr = fileExist.lenSvr;
fileSvr.complete = fileExist.complete;
db.Add (fileSvr);
// Evento desencadenante
up6_biz_event.file_create_same (fileSvr);
} // Este archivo no existe
más
{
db.Add (fileSvr);
// Evento desencadenante
up6_biz_event.file_create (fileSvr);
FileBlockWriter fr = nuevo FileBlockWriter ();
fr.CreateFile (fileSvr.pathSvr, fileSvr.lenLoc);
}
Gson gson = nuevo Gson ();
Cadena json = gson.toJson (fileSvr);
json = URLEncoder.encode (json, "UTF-8"); // Codificación, para evitar confusiones chinas
json = json.replace ("+", "% 20");
json = devolución de llamada + "({\" valor \ ": \" "+ json +" \ "})"; // devuelve datos en formato jsonp.
out.write (json);%>
El primer paso: obtener RandomAccessFile, objeto de clase de archivo de acceso aleatorio
El segundo paso: llame al método getChannel () de RandomAccessFile para abrir el canal de archivos FileChannel. Esta lógica se puede optimizar. Si hay una necesidad de almacenamiento distribuido en el futuro, se puede cambiar a almacenamiento distribuido para reducir la presión en un solo servidor.
clase pública FileBlockWriter {
public FileBlockWriter () {}
public void CreateFile (String pathSvr, long lenLoc)
{
tratar
{
Archivo ps = nuevo archivo (pathSvr);
PathTool.createDirectory (ps.getParent ());
RandomAccessFile raf = new RandomAccessFile (pathSvr, "rw");
raf.setLength (lenLoc); // corrección: crea el archivo en su tamaño original
raf.close ();
} catch (IOException e) {
// TODO Bloque de captura generado automáticamente
e.printStackTrace ();
}
}
escritura pública vacía (desplazamiento largo, String pathSvr, bloque FileItem)
{
tratar
{
InputStream stream = block.getInputStream ();
byte [] datos = nuevo byte [(int) block.getSize ()];
stream.read (datos);
stream.close ();
RandomAccessFile raf = new RandomAccessFile (pathSvr, "rw");
raf.seek (desplazamiento);
raf.write (datos);
raf.close ();
} catch (IOException e) {
// TODO Bloque de captura generado automáticamente
e.printStackTrace ();
}
}
}
Paso 3: Obtenga el número actual de bloques y calcule el último desplazamiento del archivo
Paso 4: Obtenga la matriz de bytes del bloque de archivos actual, que se utiliza para obtener la longitud de bytes del archivo
Paso 5: Use el método map () del File File de la clase FileChannel para crear un buffer de byte directo MappedByteBuffer
Paso 6: Coloque la matriz de bytes de bloque en el búfer en la posición actual mappedByteBuffer.put (byte [] b);
Paso 7: Libere el búfer
Paso 8: compruebe si el archivo está completamente cargado

Escaneo de carpetas

Clase de generación de ruta de almacenamiento
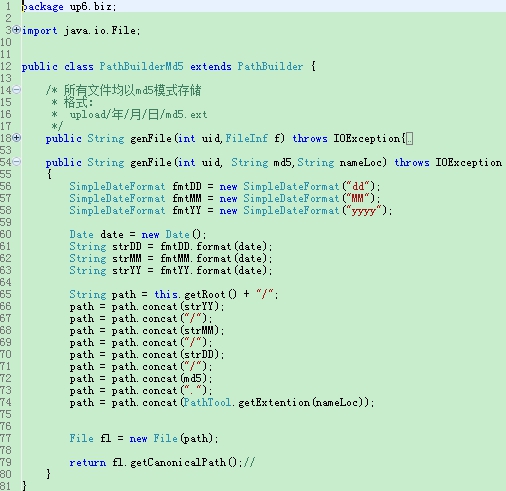
Bueno, esto se acabó. Si tiene alguna pregunta o crítica, los comentarios y mensajes privados son bienvenidos. Vamos a crecer juntos y aprender juntos.
Finalmente, pon una imagen de efecto
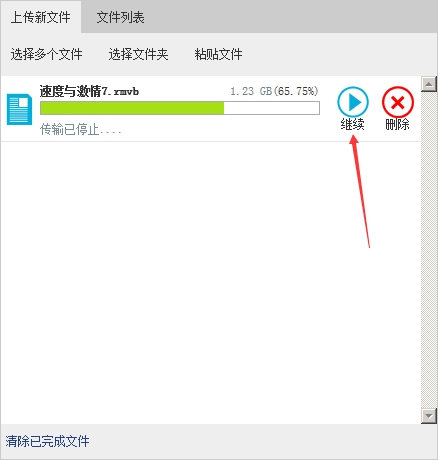
La lógica del código de fondo es casi la misma, y actualmente es compatible con MySQL, Oracle, SQL. Antes de usar, debe configurar la base de datos, puede consultar este artículo que escribí: http://blog.ncmem.com/wordpress/2019/08/07/java carga y descarga de archivos enormes /
Bienvenido a unirse al grupo para discutir: 374992201