En Linux, hay un dicho muy popular: todo en Linux es un archivo . De hecho, en Linux, varios dispositivos pueden operarse por medio de archivos, y los archivos de dispositivos periféricos generalmente se denominan archivos de dispositivo . La comunicación de red en Linux también se logra operando descriptores de archivos de red.
En el blog anterior "Introducción a la capa de transporte" , sabemos que los dispositivos y dispositivos en Internet deben conocer las direcciones IP y los números de puerto de ambas partes. La dirección IP puede encontrar el host de comunicación y el número de puerto indica el proceso de comunicación real . Esto a menudo se conoce como comunicación de socket, socket = <IP>: <port>. En Linux, la comunicación de red también necesita esta información, que se denomina estructura de dirección de socket en el sistema Linux . En Linux, la estructura de direcciones de socket generalmente comienza con sockaddr. A continuación se presentan varias estructuras de direcciones de socket comúnmente utilizadas.
struct sockaddr {
sa_family_t sa_family;/*网络通信协议的域,和socket的第一个参数一致;常用PF_INET(AF_INET)*/
char sa_data[14];
}
struct sockaddr_in {
u8 sin_len;/*固定长度16*/
u8 sin_family; /*协议的domain*/
u16 sin_port;/*通信使用的端口号*/
struct in_addr sin_addr;/*通信使用的IP地址*/
char sin_zero[8];/*保留字段,为0*/
}
struct sockaddr_un {
sa_family_t sun_family;/*domain*/
char sun_path[UNIX_PATH_MAX];/*108的长度,保存路径*/
}
typedef unsigned short sa_family_t;
struct in_addr{
u32 s_addr;
}
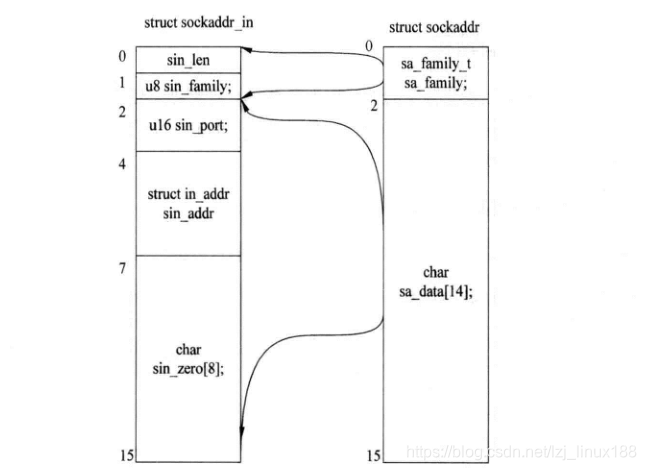
Entre ellos, struct sockaddr es una estructura general de direcciones de socket, que se puede forzar a convertir entre diferentes familias de protocolos. El tamaño de struct sockaddr y struct sockaddr_in es el mismo. La siguiente figura muestra la relación correspondiente. struct sockaddr_in es la estructura de dirección de Ethernet, y struct sockaddr_un es la estructura de dirección de la familia de protocolos del dominio Unix. Utiliza principalmente la comunicación entre procesos en el mismo host, y su velocidad será dos veces más rápida que la que usa la estructura Ethernet .
Construyendo una API de framework web
Aquí se presenta principalmente la función de cada función en la construcción del marco de la red, el código de prueba específico no se publica, mucho en línea.
Crear una función de socket de red socket ()
Todo es un archivo en Linux, es decir, puede operar el dispositivo leyendo y escribiendo archivos. Lo mismo es cierto para la comunicación de red, donde la función socket () crea una descripción de socket en el kernel y la asocia con un descriptor de archivo . La operación posterior de este descriptor de archivo puede controlar este socket de interfaz de red. Una función socket () exitosa devolverá un descriptor de archivo socket.
int socket(int domain, int type, int protocol);
El prototipo del socket es el anterior, donde el dominio se usa para establecer el dominio de la comunicación de red, y el socket de la función selecciona la familia de protocolos de comunicación en función de este parámetro. Ethernet debe usar el campo PF_INET (AF_INET y su valor son los mismos). Los valores de dominio se enumeran a continuación, y la marca roja se usa comúnmente.
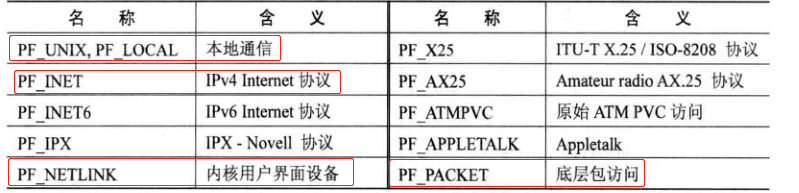
- PF_UNIX: se utiliza principalmente para la comunicación de dominio Unix, es decir, la comunicación local. Cuando se utiliza la comunicación Unix, la velocidad será el doble de rápida que otras API.
- PF_INET: comunicación IPV4, este dominio se utiliza en la mayoría de los casos.
- PF_NETLINK: se utiliza principalmente para la comunicación de enlace de red, es decir, la comunicación entre el espacio de usuario y el núcleo.
- PF_PACKET: se utiliza principalmente para acceder directamente a los datos de la tarjeta de red MAC, es decir, operar directamente la trama en la tarjeta de red.
El tipo se utiliza para establecer el tipo de comunicación de socket (es decir, protocolo), como el protocolo de transmisión de control común tipo TCP SOCK_STREAM, el protocolo de paquete de datos de usuario UDP tipo SOCK_DGRAM y el tipo de socket original SOCK_RAM. La siguiente figura es su valor opcional.
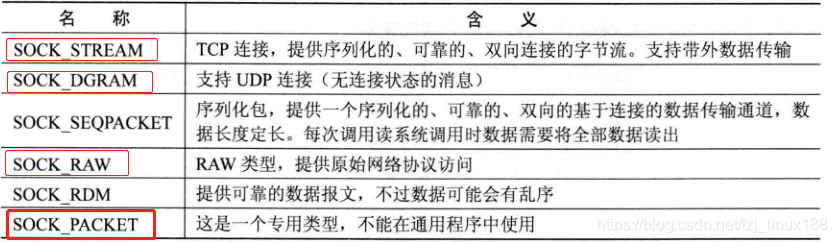
Nota: No todos los dominios de familias de protocolos implementan estos tipos de protocolos.
El tercer protocolo de parámetro de la función de socket se utiliza para especificar un tipo específico de protocolo, es decir, la expansión de tipo. Muchos protocolos a menudo tienen solo un tipo específico, por lo que solo se pueden establecer en 0 en este momento. Pero los protocolos como SOCK_RAM y SOCK_PACKET necesitan establecer este parámetro para seleccionar el tipo específico de protocolo.
Al crear un socket TCP, use socket (PF_INET, SOCK_STREAM, 0), y cuando cree UDP use socket (PF_INET, SOCK_DGRAM, 0). El proceso de creación de un socket es el siguiente.
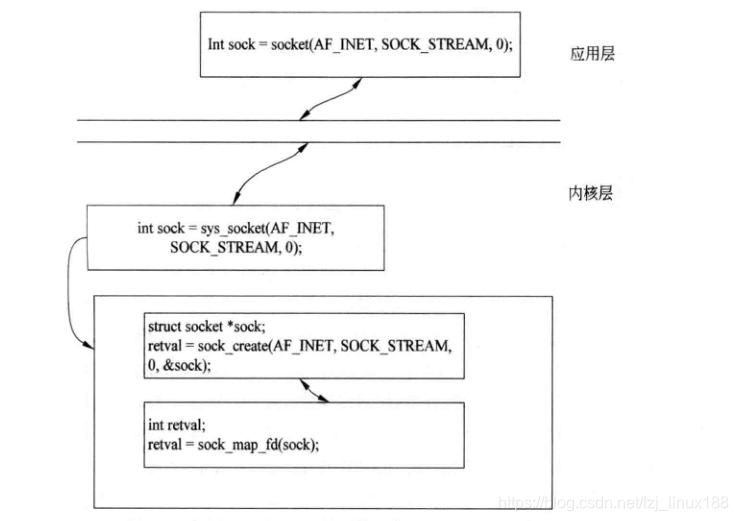
Cuando el espacio de usuario llama a socket, llamará a sys_socket () en el kernel. Su propósito principal es crear una estructura de socket de núcleo (inconsistente con la capa de aplicación), asignar recursos como colas (recibir, enviar, excepción) y copiar en operaciones y escribir de acuerdo con los parámetros. Al mismo tiempo, el socket del kernel y el descriptor de archivo también están vinculados . Finalmente, el descriptor de archivo se devuelve a la capa de aplicación. De esta manera, la estructura de socket del kernel correspondiente se puede encontrar a través del descriptor de archivo, es decir, la operación de la comunicación de red se puede realizar operando el archivo.

nota: El descriptor de archivo de socket no es diferente del descriptor de archivo general en forma. Para determinar si un descriptor de archivo es un descriptor de socket, puede obtener el modo del descriptor de archivo llamando a la función fstat () y luego cambiar el modo La parte S_IFMT se compara con el identificador S_IFSOCK. De esta manera, puede saber si un descriptor de archivo es un descriptor de socket. Puede usar el siguiente código para lograrlo.
int issockettype(int fd)
{
struct stat st;
int err = fstat(fd,&st);
if(err<0){return -1;}
if((st.st_mode & S_IFMF) == S_IFSOCK){
return 1;
}else{
return 0;
}
}
bind () se usa para vincular la estructura de direcciones
Una vez que el socket se ha establecido con éxito, el socket del kernel se puede encontrar a través del descriptor de archivo y se pueden obtener los parámetros del protocolo y las funciones de operación correspondientes. Pero en este momento, el descriptor del archivo de socket no está relacionado con la IP y el número de puerto en la red. Podemos usar bind () para vincular el descriptor de archivo a la estructura de dirección de red. Después del enlace , el descriptor de archivo de socket se asocia con la IP, el puerto y escribe la estructura de dirección de red. La función de vinculación solo se utiliza para vincular la interfaz de red del servidor en el lado del servidor, y no se puede utilizar en ningún otro lugar. El prototipo de la función es el siguiente
int bind(int sockfd, struct sockaddr*my_addr,socket_len addrlen)
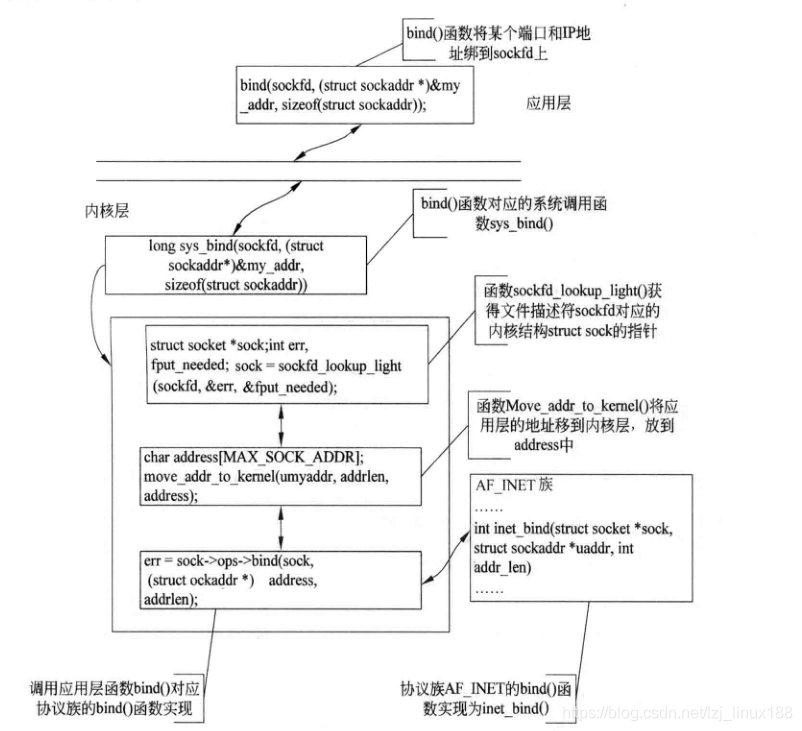
La función bind () se usa principalmente para enlazar el descriptor de archivos de red y la estructura de direcciones de red, de modo que puede usar sockfd para monitorear el estado en la red . Bind se usa a menudo en el lado del servidor, porque el servidor ha estado ejecutando el programa de servicio desde que se encendió el servidor, y no sé cuándo habrá conexión y comunicación con el cliente (procesando el lado pasivo). Por lo tanto, la función accept () se usará para establecer una conexión después del enlace en TCP; y la función recvfrom () se usará para recibir datos externos en UDP. Si no hay una dirección de red de enlace, el servidor no sabe monitorear el movimiento de la IP y el puerto. Por lo tanto, la comunicación es imposible.
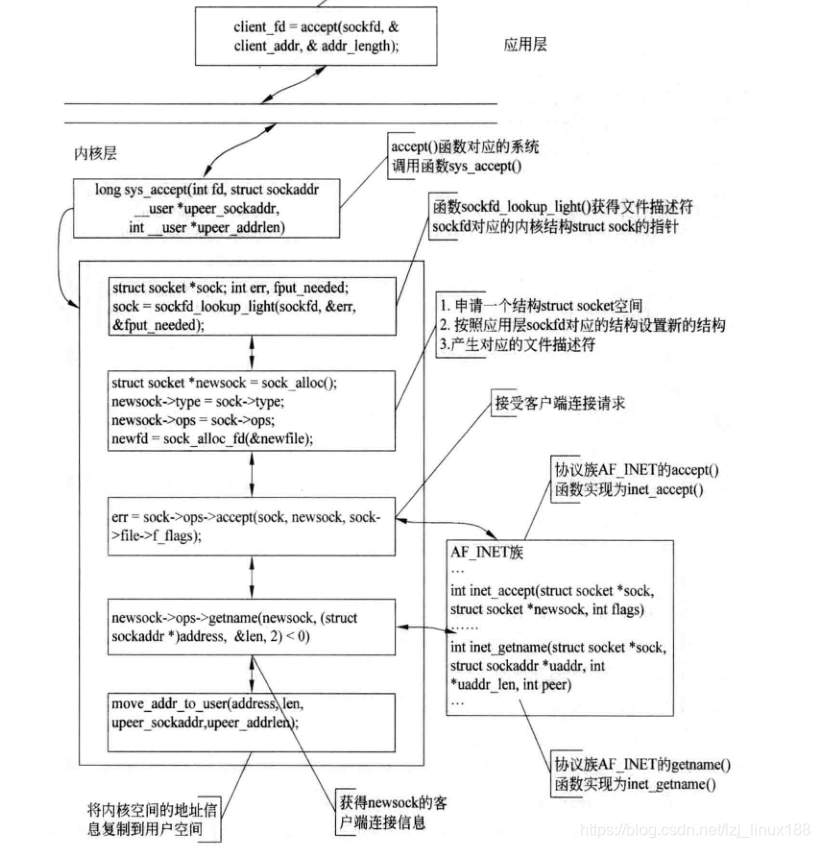
listen (), accept () supervisa el puerto local (utilizado en la comunicación TCP)
En la arquitectura C / S, después de que se ejecute el programa de servicio en el servidor, es necesario supervisar siempre la solicitud de establecimiento de conexión enviada por el cliente. Después de recibir la solicitud, las dos partes pueden comunicarse solo después de establecer la conexión. Debido a los recursos limitados en el servidor, y el servidor solo puede manejar una conexión de cliente a la vez, cuando llegan varias solicitudes de conexión de cliente al mismo tiempo, el servidor no puede procesarlas al mismo tiempo, por lo que las solicitudes de conexión de cliente que no pueden procesarse deben colocarse en la cola de espera . La longitud de la cola se especifica mediante la función listen (). La longitud de la cola no puede ser infinita debido a la influencia del sistema operativo y los recursos de hardware. Cuando se excede la longitud máxima, el núcleo usa la longitud máxima. Cuando la longitud de la cola está llena, la solicitud del cliente se perderá. La función connect () del cliente devolverá un error ECONNREFUSED . El proceso de escucha y el tipo de proceso bind () anterior, primero encuentran el zócalo del kernel correspondiente de acuerdo con el descriptor socketfd, y luego llaman a la función de escucha en socket-> ops.
La función accept () es crear un nuevo socket para registrar la información del cliente después de establecer la conexión. Una vez que la función tiene éxito, se devuelve el descriptor de archivo del cliente y se puede obtener información como la IP, el puerto y el tipo del cliente a través de parámetros. Al comunicarse con el cliente, debe usar el descriptor de socket del cliente recién conectado. El proceso es el siguiente:
Conéctese a la función de conexión de red de destino ()
Una vez que el cliente establece el socket, no es necesario realizar operaciones como el enlace de direcciones. Puede iniciar una solicitud de establecimiento de conexión directamente al servidor. La función para conectarse al servidor es conectar. Para establecer una conexión con el servidor, debe especificar la estructura de dirección del servidor y el descriptor de archivo del cliente. Una vez que la conexión se haya establecido correctamente, puede usar este descriptor de socket para comunicarse con el servidor. Cuando la cola de solicitud de establecimiento de conexión en el servidor está llena, esta función devuelve un código de error de tipo ECONNREFUSED . El proceso de llamada de la función es el siguiente:
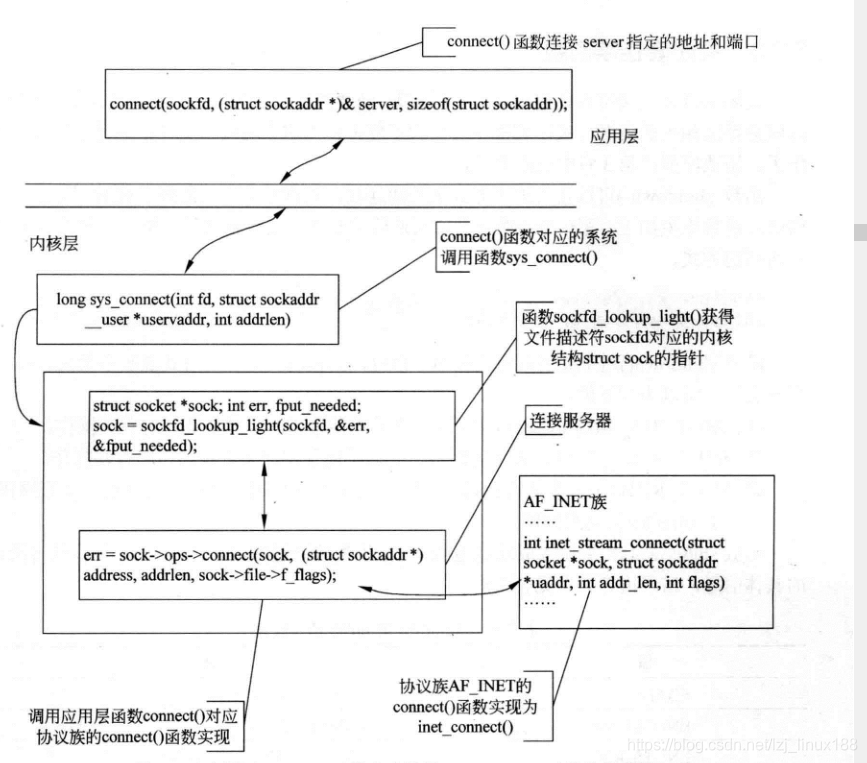
De lo anterior, podemos ver que la serie posterior de funciones (como vincular, escuchar, aceptar, conectar, etc.) se basan en el descriptor de archivo sockfd creado por socket (), y el socket del kernel correspondiente se puede encontrar a través del descriptor de archivo. Y las operaciones (función de operación) en el socket en el kernel especificarán el método de operación del protocolo específico de acuerdo con el parámetro socket ().
función de cierre
Cuando finaliza la comunicación, puede usar la función close () para cerrar sockfd. close () lanzará el recurso de calcetín correspondiente y el descriptor de archivo en el kernel. En la comunicación de red, también puede usar la función de apagado para cerrar la comunicación, que puede ser SHUT_RD (lectura de corte), SHUT_WR (escritura de corte), SHUT_RDWR (lectura y escritura están cerradas, y cierre equivalente).
Orden de bytes de red y procesamiento de conversión de dirección IP
Dado que puede haber un problema de correspondencia de orden de bytes entre los datos transmitidos por la red y los datos locales, el problema de orden de bytes debe tratarse en la programación de la red. A continuación se presentan algunas funciones relacionadas con la endianidad y una breve introducción a la endianidad.
El orden de bytes se genera debido al diferente orden de almacenamiento de memoria de la CPU y el sistema operativo para las variables de varios bytes , y se divide en almacenamiento big-endian y little-endian. El orden de bytes little-endian almacena el byte bajo en la dirección inicial de la dirección de memoria que representa la variable; el orden de bytes big-endian almacena el byte alto en la dirección inicial de la dirección de memoria que representa la variable.
Debido a las grandes diferencias en el host, el orden de bytes del host no se puede unificar, pero para las variables transmitidas en la red, sus valores deben tener una representación unificada. El orden de bytes de red se refiere al método de representación de variables de varios bytes durante la transmisión de red, y el orden de bytes de red utiliza el método de representación de orden de bytes big-endian . Las funciones principales en Linux son las siguientes:
#include <arpa/inet.h>
uint32_t htonl(uint32_t hostlong);
uint16_t htons(uint16_t hostshort);
uint32_t ntohl(uint32_t netlong);
uint16_t ntohs(uint16_t netshort);
La variable que pasa la función es una variable que necesita convertirse, y el valor de retorno es el valor convertido; la regla de denominación de la función es == "orden de bytes" a "orden de bytes" y "tipo de variable" ==, h significa que host es el host, n representa la red, es decir, el orden de bytes de la red, l representa la variable de tipo largo; s representa la variable de tipo corto . Al programar, debe llamar a la función de conversión de orden de bytes para convertir el orden de bytes del host al orden de bytes de la red. Los puertos y las direcciones IP de la red deben reemplazarse primero y luego asignarse a la estructura de direcciones correspondiente.
Solo los datos binarios pueden reconocerse en la computadora, y los datos de 32 bits, como las direcciones IP, son particularmente inconvenientes para la memoria y la escritura. La gente separará las direcciones IP de 8 y 8 bits para facilitar la memoria, lo que a menudo se denomina decimal con puntos, como 192.168.1.123. Esto es más fácil de recordar. También hay funciones correspondientes en Linux para convertir entre direcciones IP de cadena y direcciones binarias . Las funciones más utilizadas en Linux son las siguientes:
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
int inet_aton(const char *cp, struct in_addr *inp);
in_addr_t inet_addr(const char *cp);
in_addr_t inet_network(const char *cp);
char *inet_ntoa(struct in_addr in);
struct in_addr inet_makeaddr(in_addr_t net, in_addr_t host);
in_addr_t inet_lnaof(struct in_addr in);
in_addr_t inet_netof(struct in_addr in);
struct in_addr{
unsigned long int s_addr;/*IP地址*/
}
const char *inet_ntop(int af, const void *src,
char *dst, socklen_t size);
int inet_pton(int af, const char *src, void *dst);
- La función inet_aton () convierte la dirección IP del tipo de cadena decimal punteada almacenada en cp en una dirección IP binaria y la guarda en inp.
- inet_addr () convierte la dirección IP del tipo de cadena decimal punteada almacenada en cp en una dirección IP binaria, que se expresa en orden de bytes de red
- inet_network () convierte la dirección IP del tipo de cadena decimal punteada almacenada en cp en una dirección IP binaria, y la dirección IP se expresa en orden de bytes de red. Donde cp puede tener forma abcd, forma abc o forma ab.
- La función inet_ntoa () es la inversa de la conversión inet_aton (), convirtiendo la dirección IP binaria en una dirección IP de cadena de 4 segmentos decimal con puntos. Esta área de memoria es estática, por lo que las conversiones múltiples guardan los últimos datos.
- La función inet_makeaddr () combina la dirección de red y la dirección de host del orden de bytes del host en una dirección IP de orden de bytes de la red
- La función inet_lnaof () devuelve la parte del host de la dirección IP.
- La función inet_netof () devuelve la parte de red de la dirección IP.
Conversión entre dirección IP y nombre de dominio
En el uso real, el nombre de dominio del host a menudo se usa, y su dirección IP rara vez se usa. Después de todo, la memoria de nombres de dominio es más conveniente. Los nombres de dominio como www.baidu.com y www.google.com serán mucho más convenientes de recordar que sus direcciones IP decimales punteadas. Sin embargo, las API en la programación de sockets se basan en direcciones IP, por lo que debe realizar la conversión entre el nombre de dominio del host y la dirección IP. Este es el servicio DNS (sistema de nombres de dominio), que sirve como traducción entre el nombre de dominio del host y la dirección IP.
¿Qué GETHOSTBYNAME y funciones gethostbyaddr pueden obtener información para un host . La función gethostbyname obtiene la información del host por el nombre del host, y la función gethostbyaddr obtiene la información del host por la dirección IP.
#include <netdb.h>
extern int h_errno;
struct hostent *gethostbyname(const char *name);
#include <sys/socket.h> /* for AF_INET */
struct hostent *gethostbyaddr(const void *addr,
socklen_t len, int type);
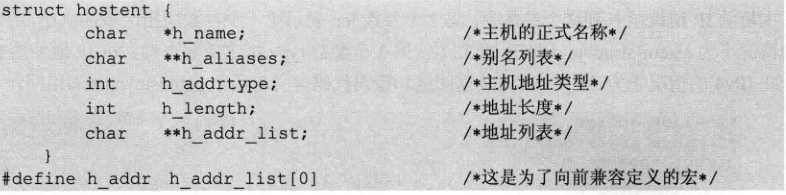
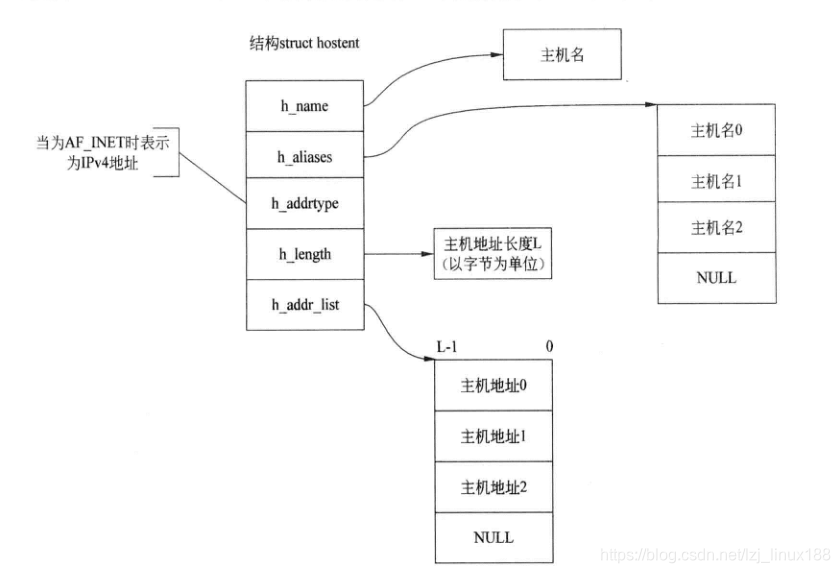
Ambas funciones pueden devolver cierta información del host, y su estructura se muestra en la figura anterior. h_name es el nombre oficial del host, como www.baidu.com, donde h_length es la longitud de la dirección IP, que es 4 para IPv4, es decir, 4 bytes. En la lista de direcciones IP de host almacenadas en h_addr_list, cada longitud es Es h_length, y el final de la lista es un puntero NULL. La relación es la siguiente:
Función de procesamiento de nombre de protocolo
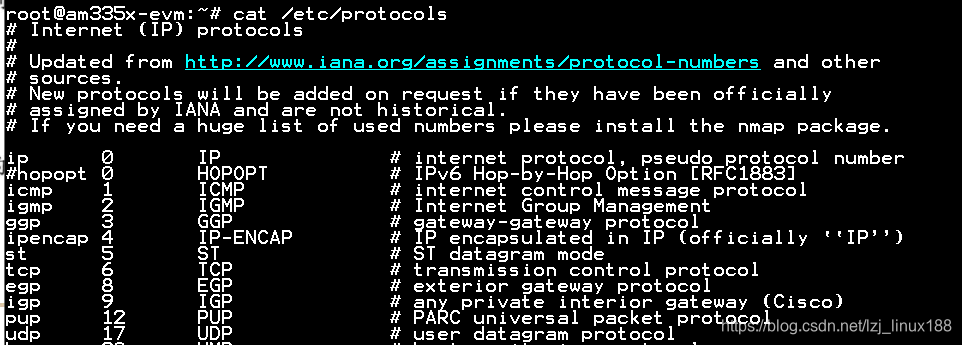
Para facilitar la operación, Linux proporciona un conjunto de funciones para consultar valores y nombres de protocolos. A continuación se presentan brevemente funciones relacionadas, métodos de uso y precauciones. Las funciones de operación en Linux son las siguientes: Estas funciones operan en los registros del archivo / etc / protocolos .
#include <netdb.h>
struct protoent *getprotoent(void);/*从协议文件中读取一行*/
struct protoent *getprotobyname(const char *name);/*从协议文件中找到匹配项*/
struct protoent *getprotobynumber(int proto);/*按照协议类型的值获取匹配项*/
void setprotoent(int stayopen);/*设置协议文件打开状态*/
void endprotoent(void);/*关闭协议文件*/
El contenido en el archivo / etc / protocol es como se muestra en la siguiente figura, que registra el nombre, el valor y el alias del protocolo. La estructura protoent de struct se define en Linux para describir esta información.

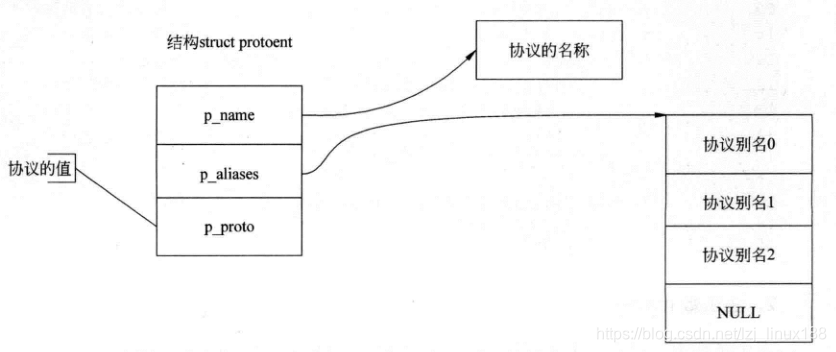
p_name es un puntero al nombre del protocolo, p_aliases es un puntero a la lista de alias, el alias de protocolo es una cadena y p_proto es el valor del protocolo.
Antes de leer la información en el archivo / etc / protocol, debe abrir este archivo con anticipación y llamar a la función setprotoent (). Cuando el parámetro es 1, siempre está abierto. Una vez completada la operación, llame a endprotoent () para cerrar.
La función getprotobyname () se utiliza para obtener la información del nombre del protocolo especificado. Se utilizará al acceder a los datos del socket sin procesar IP. Dado que la creación del socket sin procesar IP requiere especificar el protocolo, estos valores no los recordamos. Esta función obtiene。
Proceso de comunicación TCP / UDP
Los modos de comunicación en la red incluyen principalmente C / S, B / S, P2P y otros modos, entre los cuales se utiliza principalmente C / S. A continuación se explica el modo de comunicación C / S. La capa de transporte se puede dividir en dos tipos: comunicación TCP y comunicación UDP. La construcción de los marcos de comunicación TCP y UDP se describe a continuación.
Comunicación TCP
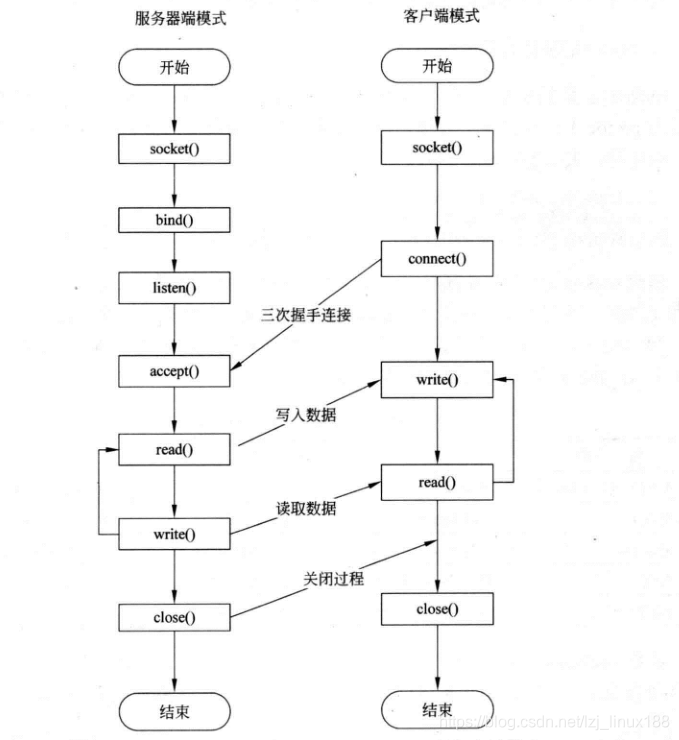
El proceso de comunicación TCP es relativamente simple y no se presentará aquí.
Comunicación UDP
Debido a que UDP es un protocolo de comunicación sin conexión y poco confiable, su arquitectura de programación sigue siendo muy diferente de TCP. La comunicación UDP no necesita establecer una conexión, por lo que no es necesario conectar (), escuchar (), aceptar () y otras funciones. El proceso de programación es el siguiente:
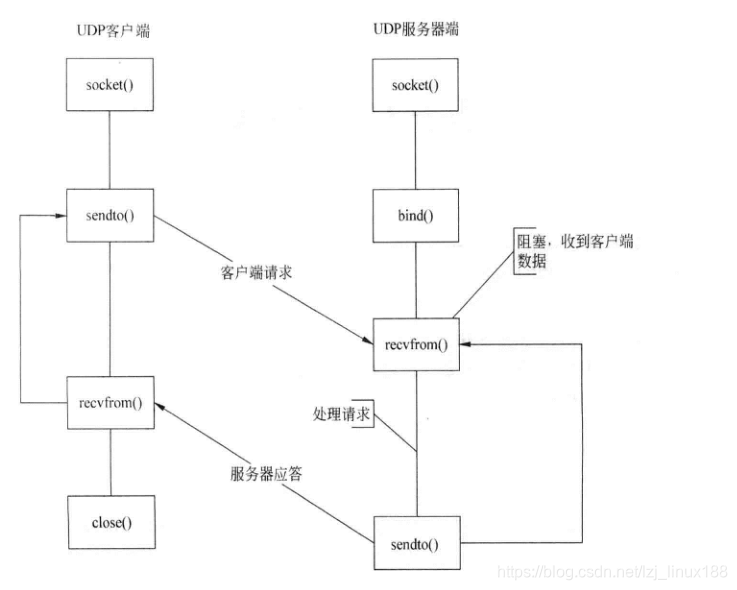
UDP crea un descriptor de archivo de socket, la función utilizada es socket (), cuando los parámetros y la comunicación TCP son muy diferentes. tipo usa SOCK_DGRAM. El enlace del puerto de escucha es el mismo que TCP, y los miembros de la estructura de direcciones se completan y luego se enlazan. Uso interactivo de sendto, recvfrom y otras funciones. El protocolo de comunicación UDP no tiene un proceso de establecimiento de conexión, por lo que cuando se utiliza recvfrom, puede recibir datos enviados por diferentes remitentes, y puede usar parámetros para obtener la información de estructura de dirección (IP, puerto, tipo, etc.).
El prototipo de recvfrom es el siguiente, donde src_addr se usa para guardar la información de estructura de dirección del remitente. El flujo de funciones es el siguiente:
ssize_t recvfrom(int sockfd, void *buf, size_t len, int flags, struct sockaddr *src_addr, socklen_t *addrlen);
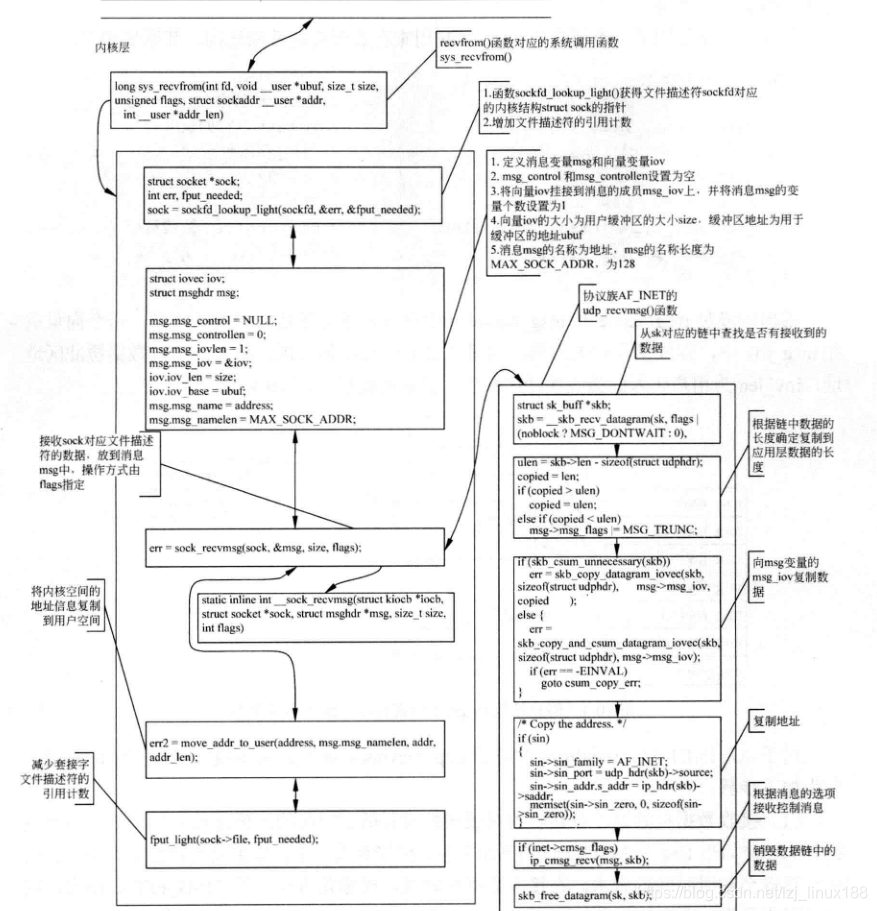
- Encuentra el socket del kernel correspondiente al descriptor de archivo
- Cree una estructura de mensaje y empaquete el puntero del búfer de direcciones y el puntero del búfer de datos del espacio del usuario en la estructura del mensaje
- Encuentre los datos correspondientes en la cadena de datos correspondiente en el descriptor del archivo de socket y copie los datos en el mensaje
- Destruya los datos en la cadena de datos, copie los datos en el espacio de la capa de aplicación y reduzca el recuento de referencias del descriptor de archivos. El
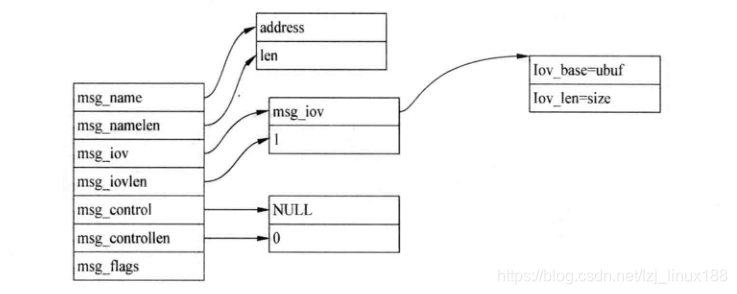
espacio del kernel usa la estructura de mensajes msghdr para almacenar todas las estructuras de datos.

Msg_name y msg_namelen se usan para almacenar la información relacionada con la dirección del remitente , Y el mensaje se almacena en msg_iov, base es la dirección del búfer de datos de recepción pasado en el espacio del usuario, y len es la longitud del búfer de recepción pasado por el usuario.
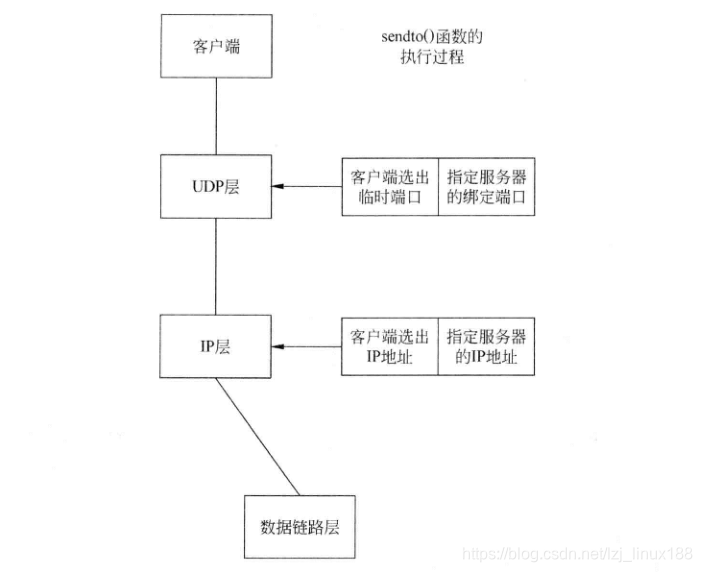
Enviar datos en UDP básicamente utiliza la función sendto, el prototipo es el siguiente. Como UDP no establece una conexión, la información de estructura de dirección del destino debe completarse en el parámetro dest_addr. Si el socket no está vinculado a la dirección IP local y al puerto durante la transmisión, se completará automáticamente en la pila de protocolos de red, como se muestra en la figura:
ssize_t sendto(int sockfd, const void *buf, size_t len, int flags,const struct sockaddr *dest_addr, socklen_t addrlen);
El protocolo UDP no garantiza la calidad del servicio para la transmisión, por lo que pueden ocurrir problemas tales como pérdida de paquetes, desorden, control de flujo e interfaces de red salientes durante la transmisión. Para la pérdida de mensajes y el mensaje fuera de servicio, puede usar el método TCP. Marque el número de secuencia del mensaje en UDP. Después de recibir el mensaje UDP, devuelve un acuse de recibo para decirle al remitente que se ha recibido. Si el mensaje de confirmación no se recibe dentro del tiempo especificado, se considera que el mensaje se ha perdido y retransmitido; y Los mensajes desordenados se pueden recuperar de acuerdo con el número de secuencia en el mensaje.
El uso de sendto y recvfrom en la comunicación UDP puede comunicarse fácilmente con cada host. Al usar estas dos funciones, puede especificar / obtener la información de estructura de dirección de la otra parte. La función de conexión también se puede usar en UDP. Después del uso, el descriptor de socket y la estructura de dirección de red se vincularán (el enlace es de la otra parte). Después del enlace, no puede usar sendto y recvfrom. Solo puede usar las funciones de lectura / escritura o enviar / recv.El uso de la función connect () en el protocolo UDP solo significa que se determina la dirección de la otra parte, y la función de vinculación solo vincula la dirección local y el puerto para recibir。
